
- 1restTemplate.postForObject传参
- 2QT UDP数据传输_qt中sudp传输xml文件
- 3SpringCloud入门:Eureka服务注册与发现(二)_spring cloud 使用eureka
- 4winform C#键盘钩子(Hook)拦截器,屏蔽键盘深入解析_winform扫码枪键盘钩子
- 510几个国内AI大模型,让你的工作学习效率翻倍!_道和顺icchat
- 6前后端实时数据通信
- 7Windows如何远程连接服务器?Linux服务器如何远程登录?远程连接服务器命令_windows连接远程服务器命令端口
- 8Ext JS Data Package_sencha extjs5.x 的数据包data package讲解
- 9uniapp组件之tab选项卡滑动切换_uniapp tab
- 10post请求传递多个类型的参数_post请求传多个参数
Flink 流批一体在模型特征场景的使用
赞
踩
摘要:本文整理自B站资深开发工程师张杨老师在 Flink Forward Asia 2023 中 AI 特征工程专场的分享。内容主要为以下四部分:
- 模型特征场景
- 流批一体
- 性能优化
- 未来展望
一、 模型特征场景
以下是一个非常简化并且典型的线上实时特征和样本的生产过程。

前面是一个 Show 和 Click ,也就是点击展现实时流,数据上报到 kafka 后在 Flink 里面进行 Join,计算完再输出到 Kafka 。再进入下一个 Flink 任务进行特征计算和样本生成,最后再输出到 Kafka 供给模型实时训练使用。目前B站大部分推荐链路的实时数据架构,基本都是这样。Kafka 的中间数据,全部都会 dump 到 Hive 或者到 Iceberg 里面去,如果要算历史的特征样本或者模型冷启动,离线侧会用 Spark 做类似的一个计算存储到 Hive 里面去,供给模型离线训练使用。
上面的链路主要对应着线上生产场景,下面的则对应着模型调研以及冷启动场景,两条链路一定是长期都存在的。

这样做会出现的一些常见问题:
-
双链路开发架构的问题
用户既要学习 Spark 又要学 Flink 。尤其是 Flink 里面很多语法和现在的 Spark 稍微有些不一样。大部分开发同学都是从离线的模型转到实时。那它其实是有比较高的学习成本,或者是比较高的转换成本。 -
计算一致性
很多 SQL 看起来虽然是一样的但是计算结果会有微小的差别,比如 Flink 支持 ANSI SQL 标准,但 Spark 我们当前版本不完全支持。用户可能离线调研时发现特征效果很好,实时一上生产后发现效果不佳,这种情况挺常见的,一番排查最终发现是自带的算子 UDF 行为不一样所引起的,需要一直在这个层面做各种兼容调整,这样其实是比较痛苦的。 -
长期运维
另外就是在特征计算库的开发,在计算引擎层面就是 UDF。我们有一些纯 Java 的 UDF ,也有一些带 JNI 的 UDF,在 Spark、Flink 引擎上都分别实现了。但是在长期看,比如说算某天说我要升级 UDF 依赖的 Tensorflow,这个对 Linux 内核版本要求也比较高,整个计算引擎依赖的环境就要跟着变化。如果是多引擎,那多引擎都要去做基础环境的升级,这个风险其实就非常大了。在我们的业务场景里,这个其实常常遇到,是个很大痛点。
二、流批一体
基于上面背景,我们采用了流批一体的方案来解决当前的问题。我们目前使用的 Flink 1.15 版本,它已经是一个比较成熟的版本。如果用 Flink 来替代 Spark 的离线场景,那实际上前面讲的问题对用户来说,都是可以解决的。

这个是基本的架构,用户的 Adhoc 或者 ETL 通过 Client 提交到 Flink 集群,资源调度我们支持 Yarn 和 K8S 。Shuffle 架构前期是使用了Flink Remote Shuffle,目前现在已经迁移到 Celeborn。最终的结果数据是写到 Kafka 或者 Hive 来支持机器学习或者一些业务分析的应用。

以下是我们对接流批一体所做的具体工作:
- 基于 Flink 1.15的版本,打通了公司内部所有的 Adhoc/ETL 调度引擎的入口,包括针对算法同学依赖的 CLI 的提交。打通现有离线体系的好处不言而喻,Flink 能立即无缝对接到当前的离线生态,我们只需要专注于引擎本身的开发。
- 第二个是支持 Flink 任务运行在实时的 k8s 或者离线的 Yarn 资源池里。目前实时的一个重要工作就是逐步迁移到 K8S,离线当前还是以 Yarn为主。
- 第三个对于实时链路,是有多种存储的,流批一体意味着批也要支持多存储。比如说实时它可能 Redis 用的比较多,离线可能大部分都是用 Hive 就可以。所以在流批一体上,这些各种 Flink 的 Connector 都对 Batch 场景进行了优化。因为在实际的使用过程中,会发现不优化的话有很多很多小问题,这个后面会大概讲一下。
- 最后一个就是协助业务迁移。目前商业化和AI推荐相当一部分的特征计算或者调研,都已经逐渐迁到 Flink Batch 上去了。

以下是语法层面我们做的一些细节点。
- 第一个就是支持 Hive Module,主要是兼容 HIVE UDF,这样既方便 Batch场 景使用,Streaming 场景收益也比较大。对于大部分用户来说,它从离线模型升级到实时模型,可能很多 UDF 尤其是系统的 UDF,是不需要去做重复的开发。
- 第二个是特征流批业务,把用户经常使用的语法进行支持。在做离线特征计算的时候,用户很常用某种语法,实时没有或者不好用,我们也都做了相应的优化。比如业务经常会用 Add Jar 来加实施资源。
- 第三个在实际使用过程中发现,对于用户来说,很多UDF流批行为也是稍微不一样的。部分UDF流批行为进行区分,不同模式需求不同,如 Now 函数 Streaming 场景是非 Deterministic,但是我们在 Batch 场景下,用户的期望是 Deterministic 的。我们做了兼容,根据版本自动会选择自己的行为,这个是语法或者 UDF 上一些很小的细节带来的一些坑。
接下来就是 Connector 的优化,也就是流批模式的兼容改造。
-
Streaming 延迟敏感,Batch 吞吐优先,默认参数大多根据 Streaming 场景定制,根据模式自适应。其实 Streaming 场景是一个延迟敏感的。大部分在线上实时流对延迟是比较敏感的。比如说他的特征计算或样本生成,写到 Kafka 里面可能配的 Count 是100条就写入,或者超时100毫秒就写出去。但是在把这个配置直接拿到批场景去使用,这个配置数值就太低了。
-
Streaming 里一些 Static 单例连接的优化,如果没有开 Restart 功能,那么在实时场景下算子的生命周期大部分场景下都是一致。Batch 场景下 Task 的生命周期是完全不一样的,算子完成后如果直接粗暴的关闭单例就会有问题。其实 Streaming 里面这种做法也是不合理的,只是 Batch 会放大这个问题,我们在这方面也是做了优化。

第三个就是做了流批的错峰资源的利用。因为流业务主要运行在 K8S 集群上,所以做 Flink 的批也希望运行在 K8S 上。K8S 上是流批共享调度器,流和批任务的行为差别还挺大的,批任务的资源占用大头 ETL 都是在晚上,白天相对资源占用较少。但是流任务完全相反,白天用的比较满,晚上用的比较少。流批天然就是错峰资源占用,因此我们也建议用户可以把一些比较占资源的补数的任务丢到半夜运行,这样能比较充分的利用资源。
但是实际白天的时候,流批还是会有一些竞争,无法完全避免。我们整个方案是基于公司内部的一个混部框架,就是在同一套 K8s 集群上,会有两套资源视图,一个是在线资源视图,他会看到所有的机器资源。另一个是混部资源视图,能看到那些剩余资源,但是这个视图的优先级是比较低的,在资源紧张的情况下会驱逐任务。比如说在线机器是 100% 资源视图,在线业务实际占用了 30% 资源,那剩下的 70% 资源可以被混部资源视图看到,两个资源视图配合两个调度器来进行调度。
下面这是一个效果,这是前段时间截图的。

图上可以看到 2 点到 6 点左右,流占用的资源是非常少的,但是这个时候批占用的资源是很大的,错峰的资源能被批利用起来。在白天的话其实批资源使用也不低,这是业务特性,可以看到机器的资源利用率大概是70%左右。因为我们设置的保护阈值在 80% 左右,如果流业务吃不到 80% 资源,剩下的都是可以被批作业占用。
除此之外,最近还做了一个事情,就是把 flink 升到了 JDK17。因为我们发现混部之后,资源瓶颈好像不在 CPU 了而是在内存了,对于低版本的 Java 进程来说,它的内存消耗是刚性的,不是很利于混部。在 JDK12 之后 Jvm 的 GC 支持了向操作系统进行内存返还,在流计算这样的大数据场景,我们觉得对性能的要求也没有高到要去考虑内存分配效率的这个程度,因此我们把 Flink 运行环境进行到了 JDK17,也开启了内存返还的功能。
从上线的数据来看,整个集群的内存节省是超过 15% ,能比较好的提升资源的利用。
三、 性能优化
接下来我们来看一下框架层面做的性能优化。
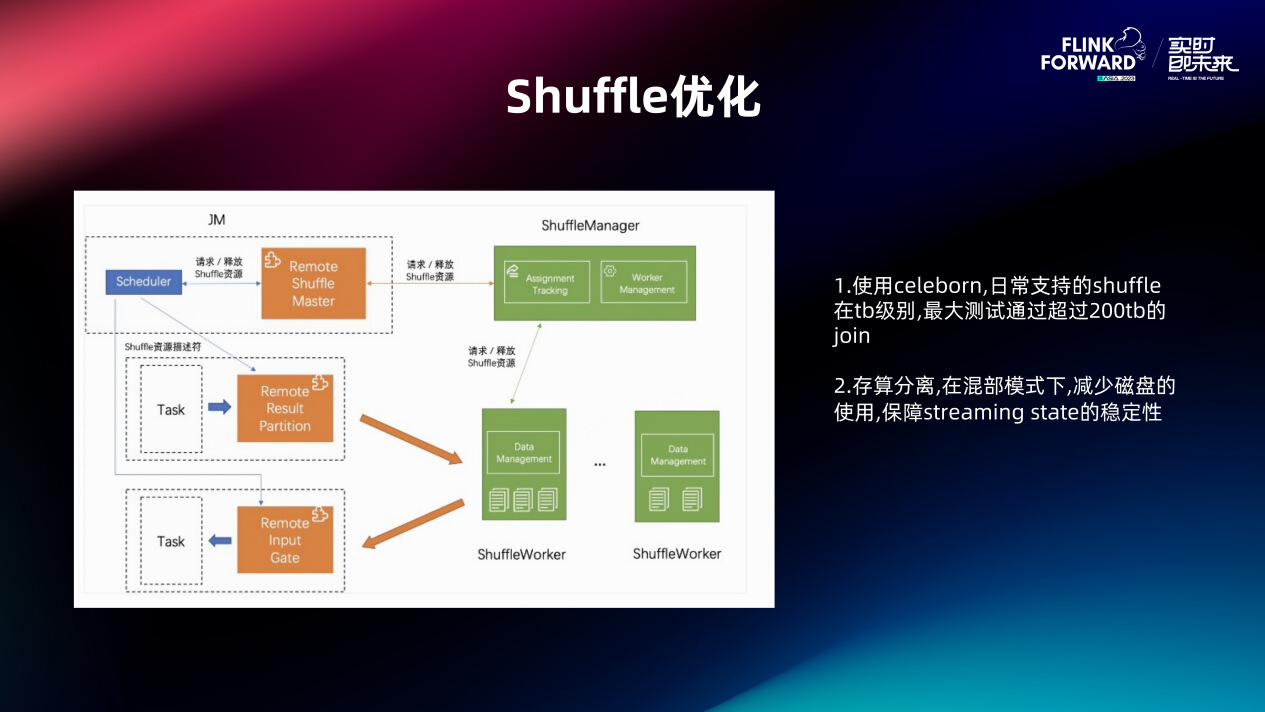
首先就是 Shuffle 的优化,业务的使用过程中,shuffle 操作是比较常见的。我们最开始用的 Flink Netty Shuffle,发现稳定性比较差,本地磁盘的 IO 压力很大,算子资源占用也比较多。我们调研下业界的一些方案,切换到了 Apache Celeborn Shuffle ,我们在80台物理机,单机 14tb 的 SSD 存储的集群上,测试存储超过200T的 Shuffle 任务,性能上看很稳定。做这个事情还有一个好处就是存算分离,前面说了我们是流批混部的架构。Streaming 本身就是存算一体的,那把批再放上来,如果它也是一个存算一体的架构,这个其实对磁盘的争抢会非常激烈,那只能做 IO 的 Cgroup 或者分盘管理,但是这个其实运维成本很高。实际上 Streaming 这块我们目前也在做 Tiered Storage,社区应该也有这个规划。我们希望在 Flink 计算上把本地的存储放到远程去,这样的话,计算的 Scala 的能力会更大。
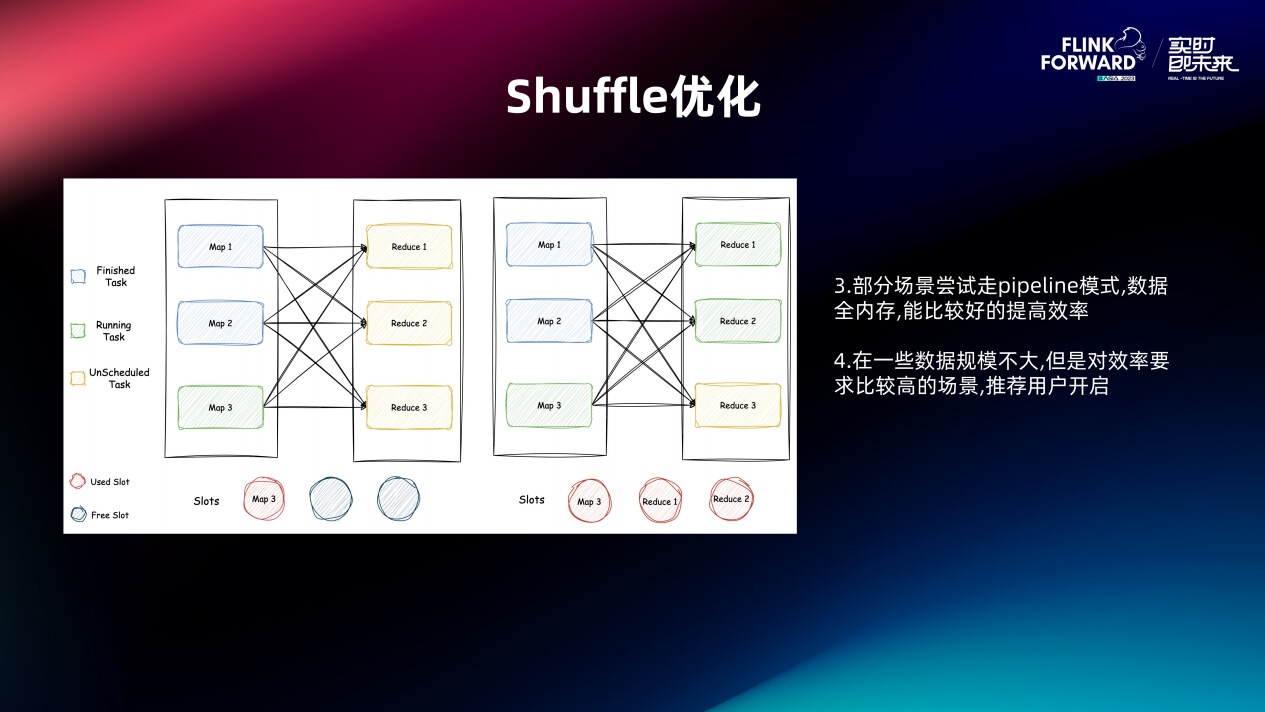
然后 Shuffle 优化的第二个点就是在部分场景尝试走 Pipeline 的模式。社区其实有一个 Hybrid 模式,介于上面两者之间,但是这个功能我们测试下来会有死锁的问题,最新的版本应该是解决了。在 Pipeline 模式下,数据是不会落盘,目前我们测下来,比如说几百G或者两三个T的场景还是能比较好的提升效率,它的效率整个来说我们是和 Presto 做一些对标,比会差一点但没有差特别多。所以这种场景我们也在推荐用户走这个 Pipeline 模式。
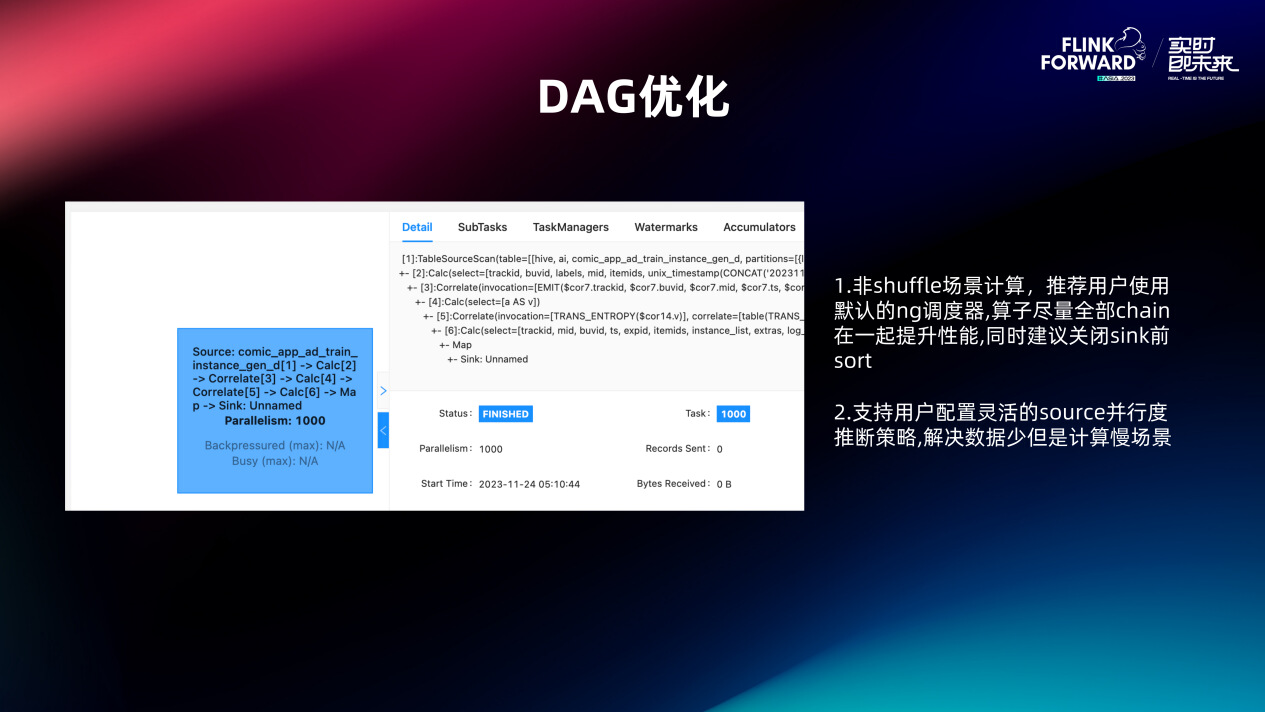
如图就是一些 DAG 的优化。直接切到 Flink 批上去之后,其实发现可能会有很多无用的 Shuffle。比如 Source 读完数据再做个 Map 计算,在这两个算子之间会加一层 Shuffle,其实完全没有必要。
很多的一些非 Shuffle 的场景,我们实际上都是推荐用户走默认的 NG 调度器。算子我们是尽量能够全部 chain 在一起的,包括 Sink 默认的 Sort 我们也关闭了,这样实际上计算上看到这个 DAG 其实就是从头串到尾的,效率非常高。
但是在有些场景下,比如说 Source 的数据不大但是计算压力非常大。比如说有些特征计算比较复杂,需要调一些 Tensorflow 库导致算起来比较慢,我们也是支持配这些灵活的策略,例如 Source 我要把它分开来,后面的计算可以做的更多,这个目前也是可以的。
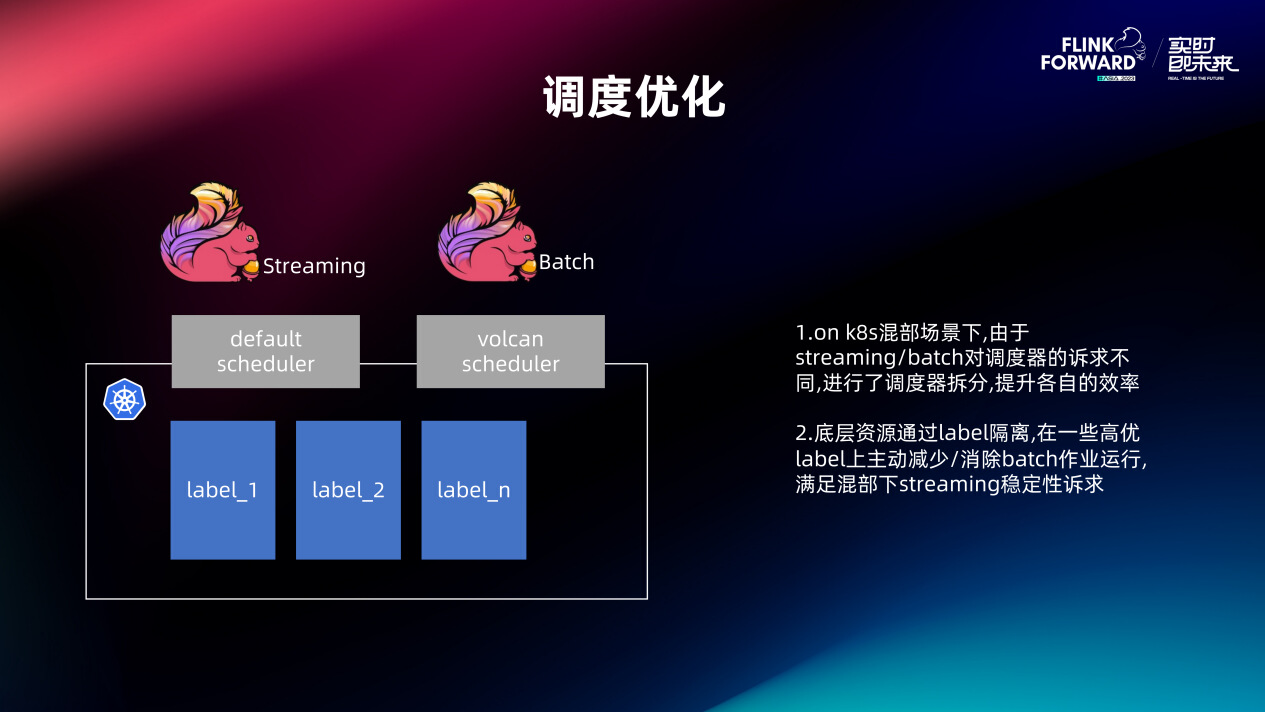
最后一个是调度层面的优化。
我们前面也说到我们采用的一个资源池下面的流批混部,错峰使用资源。调度器层面也出现了一些问题,Streaming 和 Batch 对调度器的诉求其实不同的。Streaming 是 Long Running 的,Container 调度的频率其实相对的是比较低的,吞吐要求不是很高。但是 Batch 任务不是,任务频繁运行,每次执行都是几百上千个 Container 申请,在资源紧张的情况下,它可能运行周期内也会一直持续的来申请 Container。早期我们共用一个调度器,发现 Batch 任务比较多的时候,Streaming 任务是没法申请到 Container 的,都堵在调度器线程里面。所以我们需要进行调度器的拆分, Streaming 业务我们还是用 K8s 默认的 Default Scheduler,Batch 则是换到了目前大部分公司都会选用的 Volcano 调度器。
在底层资源上,Streaming 业务采用了 K8S 的 Label 隔离,也就是物理层面隔离。但是在 Batch,我们实际上是通过 Volcano 的一些 Capacity 来进行限制,来保证整个的资源弹性。前面也说过,混部资源的优先级会比较低,在 Streaming 业务申请资源的情况下,如果整体资源不足,Batch 业务会被驱逐。
四、未来展望

-
探索更多特征场景的流批一体。目前还有部分算子例如 Interval Join 等还没办法做到流批一体,技术上难度也比较大。这两天听了一些 Apache Paimon 的分享,发现也可以试试看能不能从存储层面解决这个问题。
-
第二个就是 DAG/Shuffle 优化,提升特征样本计算性能。我们和 Spark 或者 Presto 进行了一些对比之后,目前1.15版本在一些细节的地方效果没有那么好,还有比较大的提升空间。
-
最后一个是 Flink 支持更多引擎的 UDF。业务也希望我们支持除了 Hive 还有像 Presto/Spark 这些引擎独有的 UDF 。有些纯粹的离线模型也想逐渐实时化,这个也是当前主要的迁移成本之一。

