
- 1nltk.data.load()应用及其要注意的事项_[nltk_data] downloading package punkt to /root/nlt
- 2【LorMe云讲堂】土壤-根际微生物组与作物高产高效
- 3Ubuntu20.04安装pytorch(包括安装Anaconda和虚拟环境配置以及安装包spikingjelly)
- 4如何成为一名精通云计算的程序员
- 5教你5步学会用Llama2:我见过最简单的大模型教学_llama2 如何训练
- 6计算机视觉新巅峰,微软&牛津联合提出MVSplat登顶3D重建
- 7探索Grok:马斯克旗下AI公司的革命性产品解读
- 8「数学」- 手撸 Newton插值法 C++
- 9WinHex使用方法详解
- 10Java spring boot 项目和python flask项目 开启 https 请求_flask keystore
flink-sql所有语法详解-1.14_flinksql 博客文档
赞
踩
1. 版本说明
本文档内容基于flink-1.14.x,其他版本的整理,请查看本人博客的 flink 专栏其他文章。
2. 概览
本章节描述了 Flink 所支持的 SQL 语言,包括数据定义语言(Data Definition Language,DDL)、数据操纵语言(Data Manipulation Language,DML)以及查询语言。Flink 对 SQL 的支持基于实现了 SQL 标准的 Apache Calcite。
本页面列出了目前 Flink SQL 所支持的所有语句:
- SELECT (Queries)
- CREATE TABLE, DATABASE, VIEW, FUNCTION
- DROP TABLE, DATABASE, VIEW, FUNCTION
- ALTER TABLE, DATABASE, FUNCTION
- INSERT
- DESCRIBE
- EXPLAIN
- USE
- SHOW
- LOAD
- UNLOAD
2.1. 数据类型
请参考专门描述该主题的页面数据类型。
通用类型与(嵌套的)复合类型 (如:POJO、tuples、rows、Scala case 类) 都可以作为行的字段。
复合类型的字段任意的嵌套可被 值访问函数 访问。
通用类型将会被视为一个黑箱,且可以被 用户自定义函数 传递或引用。
对于 DDL 语句而言,我们支持所有在 数据类型 页面中定义的数据类型。
注意: SQL查询不支持部分数据类型(cast 表达式或字符常量值)。如:STRING, BYTES, RAW, TIME(p) WITHOUT TIME ZONE, TIME(p) WITH LOCAL TIME ZONE, TIMESTAMP(p) WITHOUT TIME ZONE, TIMESTAMP(p) WITH LOCAL TIME ZONE, ARRAY, MULTISET, ROW.
2.2. 保留关键字
虽然 SQL 的特性并未完全实现,但是一些字符串的组合却已经被预留为关键字以备未来使用。如果你希望使用以下字符串作为你的字段名,请在使用时使用反引号将该字段名包起来(如 value, count )。
A, ABS, ABSOLUTE, ACTION, ADA, ADD, ADMIN, AFTER, ALL, ALLOCATE, ALLOW, ALTER, ALWAYS, AND, ANY, ARE, ARRAY, AS, ASC, ASENSITIVE, ASSERTION, ASSIGNMENT, ASYMMETRIC, AT, ATOMIC, ATTRIBUTE, ATTRIBUTES, AUTHORIZATION, AVG, BEFORE, BEGIN, BERNOULLI, BETWEEN, BIGINT, BINARY, BIT, BLOB, BOOLEAN, BOTH, BREADTH, BY, BYTES, C, CALL, CALLED, CARDINALITY, CASCADE, CASCADED, CASE, CAST, CATALOG, CATALOG_NAME, CEIL, CEILING, CENTURY, CHAIN, CHAR, CHARACTER, CHARACTERISTICS, CHARACTERS, CHARACTER_LENGTH, CHARACTER_SET_CATALOG, CHARACTER_SET_NAME, CHARACTER_SET_SCHEMA, CHAR_LENGTH, CHECK, CLASS_ORIGIN, CLOB, CLOSE, COALESCE, COBOL, COLLATE, COLLATION, COLLATION_CATALOG, COLLATION_NAME, COLLATION_SCHEMA, COLLECT, COLUMN, COLUMN_NAME, COMMAND_FUNCTION, COMMAND_FUNCTION_CODE, COMMIT, COMMITTED, CONDITION, CONDITION_NUMBER, CONNECT, CONNECTION, CONNECTION_NAME, CONSTRAINT, CONSTRAINTS, CONSTRAINT_CATALOG, CONSTRAINT_NAME, CONSTRAINT_SCHEMA, CONSTRUCTOR, CONTAINS, CONTINUE, CONVERT, CORR, CORRESPONDING, COUNT, COVAR_POP, COVAR_SAMP, CREATE, CROSS, CUBE, CUME_DIST, CURRENT, CURRENT_CATALOG, CURRENT_DATE, CURRENT_DEFAULT_TRANSFORM_GROUP, CURRENT_PATH, CURRENT_ROLE, CURRENT_SCHEMA, CURRENT_TIME, CURRENT_TIMESTAMP, CURRENT_TRANSFORM_GROUP_FOR_TYPE, CURRENT_USER, CURSOR, CURSOR_NAME, CYCLE, DATA, DATABASE, DATE, DATETIME_INTERVAL_CODE, DATETIME_INTERVAL_PRECISION, DAY, DEALLOCATE, DEC, DECADE, DECIMAL, DECLARE, DEFAULT, DEFAULTS, DEFERRABLE, DEFERRED, DEFINED, DEFINER, DEGREE, DELETE, DENSE_RANK, DEPTH, DEREF, DERIVED, DESC, DESCRIBE, DESCRIPTION, DESCRIPTOR, DETERMINISTIC, DIAGNOSTICS, DISALLOW, DISCONNECT, DISPATCH, DISTINCT, DOMAIN, DOUBLE, DOW, DOY, DROP, DYNAMIC, DYNAMIC_FUNCTION, DYNAMIC_FUNCTION_CODE, EACH, ELEMENT, ELSE, END, END-EXEC, EPOCH, EQUALS, ESCAPE, EVERY, EXCEPT, EXCEPTION, EXCLUDE, EXCLUDING, EXEC, EXECUTE, EXISTS, EXP, EXPLAIN, EXTEND, EXTERNAL, EXTRACT, FALSE, FETCH, FILTER, FINAL, FIRST, FIRST_VALUE, FLOAT, FLOOR, FOLLOWING, FOR, FOREIGN, FORTRAN, FOUND, FRAC_SECOND, FREE, FROM, FULL, FUNCTION, FUSION, G, GENERAL, GENERATED, GET, GLOBAL, GO, GOTO, GRANT, GRANTED, GROUP, GROUPING, HAVING, HIERARCHY, HOLD, HOUR, IDENTITY, IMMEDIATE, IMPLEMENTATION, IMPORT, IN, INCLUDING, INCREMENT, INDICATOR, INITIALLY, INNER, INOUT, INPUT, INSENSITIVE, INSERT, INSTANCE, INSTANTIABLE, INT, INTEGER, INTERSECT, INTERSECTION, INTERVAL, INTO, INVOKER, IS, ISOLATION, JAVA, JOIN, K, KEY, KEY_MEMBER, KEY_TYPE, LABEL, LANGUAGE, LARGE, LAST, LAST_VALUE, LATERAL, LEADING, LEFT, LENGTH, LEVEL, LIBRARY, LIKE, LIMIT, LN, LOCAL, LOCALTIME, LOCALTIMESTAMP, LOCATOR, LOWER, M, MAP, MATCH, MATCHED, MAX, MAXVALUE, MEMBER, MERGE, MESSAGE_LENGTH, MESSAGE_OCTET_LENGTH, MESSAGE_TEXT, METHOD, MICROSECOND, MILLENNIUM, MIN, MINUTE, MINVALUE, MOD, MODIFIES, MODULE, MODULES, MONTH, MORE, MULTISET, MUMPS, NAME, NAMES, NATIONAL, NATURAL, NCHAR, NCLOB, NESTING, NEW, NEXT, NO, NONE, NORMALIZE, NORMALIZED, NOT, NULL, NULLABLE, NULLIF, NULLS, NUMBER, NUMERIC, OBJECT, OCTETS, OCTET_LENGTH, OF, OFFSET, OLD, ON, ONLY, OPEN, OPTION, OPTIONS, OR, ORDER, ORDERING, ORDINALITY, OTHERS, OUT, OUTER, OUTPUT, OVER, OVERLAPS, OVERLAY, OVERRIDING, PAD, PARAMETER, PARAMETER_MODE, PARAMETER_NAME, PARAMETER_ORDINAL_POSITION, PARAMETER_SPECIFIC_CATALOG, PARAMETER_SPECIFIC_NAME, PARAMETER_SPECIFIC_SCHEMA, PARTIAL, PARTITION, PASCAL, PASSTHROUGH, PATH, PERCENTILE_CONT, PERCENTILE_DISC, PERCENT_RANK, PLACING, PLAN, PLI, POSITION, POWER, PRECEDING, PRECISION, PREPARE, PRESERVE, PRIMARY, PRIOR, PRIVILEGES, PROCEDURE, PUBLIC, QUARTER, RANGE, RANK, RAW, READ, READS, REAL, RECURSIVE, REF, REFERENCES, REFERENCING, REGR_AVGX, REGR_AVGY, REGR_COUNT, REGR_INTERCEPT, REGR_R2, REGR_SLOPE, REGR_SXX, REGR_SXY, REGR_SYY, RELATIVE, RELEASE, REPEATABLE, RESET, RESTART, RESTRICT, RESULT, RETURN, RETURNED_CARDINALITY, RETURNED_LENGTH, RETURNED_OCTET_LENGTH, RETURNED_SQLSTATE, RETURNS, REVOKE, RIGHT, ROLE, ROLLBACK, ROLLUP, ROUTINE, ROUTINE_CATALOG, ROUTINE_NAME, ROUTINE_SCHEMA, ROW, ROWS, ROW_COUNT, ROW_NUMBER, SAVEPOINT, SCALE, SCHEMA, SCHEMA_NAME, SCOPE, SCOPE_CATALOGS, SCOPE_NAME, SCOPE_SCHEMA, SCROLL, SEARCH, SECOND, SECTION, SECURITY, SELECT, SELF, SENSITIVE, SEQUENCE, SERIALIZABLE, SERVER, SERVER_NAME, SESSION, SESSION_USER, SET, SETS, SIMILAR, SIMPLE, SIZE, SMALLINT, SOME, SOURCE, SPACE, SPECIFIC, SPECIFICTYPE, SPECIFIC_NAME, SQL, SQLEXCEPTION, SQLSTATE, SQLWARNING, SQL_TSI_DAY, SQL_TSI_FRAC_SECOND, SQL_TSI_HOUR, SQL_TSI_MICROSECOND, SQL_TSI_MINUTE, SQL_TSI_MONTH, SQL_TSI_QUARTER, SQL_TSI_SECOND, SQL_TSI_WEEK, SQL_TSI_YEAR, SQRT, START, STATE, STATEMENT, STATIC, STDDEV_POP, STDDEV_SAMP, STREAM, STRING, STRUCTURE, STYLE, SUBCLASS_ORIGIN, SUBMULTISET, SUBSTITUTE, SUBSTRING, SUM, SYMMETRIC, SYSTEM, SYSTEM_USER, TABLE, TABLESAMPLE, TABLE_NAME, TEMPORARY, THEN, TIES, TIME, TIMESTAMP, TIMESTAMPADD, TIMESTAMPDIFF, TIMEZONE_HOUR, TIMEZONE_MINUTE, TINYINT, TO, TOP_LEVEL_COUNT, TRAILING, TRANSACTION, TRANSACTIONS_ACTIVE, TRANSACTIONS_COMMITTED, TRANSACTIONS_ROLLED_BACK, TRANSFORM, TRANSFORMS, TRANSLATE, TRANSLATION, TREAT, TRIGGER, TRIGGER_CATALOG, TRIGGER_NAME, TRIGGER_SCHEMA, TRIM, TRUE, TYPE, UESCAPE, UNBOUNDED, UNCOMMITTED, UNDER, UNION, UNIQUE, UNKNOWN, UNNAMED, UNNEST, UPDATE, UPPER, UPSERT, USAGE, USER, USER_DEFINED_TYPE_CATALOG, USER_DEFINED_TYPE_CODE, USER_DEFINED_TYPE_NAME, USER_DEFINED_TYPE_SCHEMA, USING, VALUE, VALUES, VARBINARY, VARCHAR, VARYING, VAR_POP, VAR_SAMP, VERSION, VIEW, WEEK, WHEN, WHENEVER, WHERE, WIDTH_BUCKET, WINDOW, WITH, WITHIN, WITHOUT, WORK, WRAPPER, WRITE, XML, YEAR, ZONE
3. 入门
Flink SQL 使得使用标准 SQL 开发流应用程序变的简单。如果你曾经在工作中使用过兼容 ANSI-SQL 2011 的数据库或类似的 SQL 系统,那么就很容易学习 Flink。本教程将帮助你在 Flink SQL 开发环境下快速入门。
3.1. 先决条件
你只需要具备 SQL 的基础知识即可,不需要其他编程经验。
3.1.1. 安装
安装 Flink 有多种方式。对于实验而言,最常见的选择是下载二进制包并在本地运行。你可以按照本地模式安装中的步骤为本教程的剩余部分设置环境。
完成所有设置后,在安装文件夹中使用以下命令启动本地集群:
./bin/start-cluster.sh
- 1
启动完成后,就可以在本地访问 Flink WebUI localhost:8081,通过它,你可以监控不同的作业。
3.1.2. SQL 客户端
SQL 客户端是一个交互式的客户端,用于向 Flink 提交 SQL 查询并将结果可视化。 在安装文件夹中运行 sql-client 脚本来启动 SQL 客户端。
./bin/sql-client.sh
- 1
3.1.3. Hello World
SQL 客户端(我们的查询编辑器)启动并运行后,就可以开始编写查询了。 让我们使用以下简单查询打印出 ‘Hello World’:
SELECT 'Hello World';
- 1
运行 HELP 命令会列出所有支持的 SQL 语句。让我们运行一个 SHOW 命令,来查看 Flink 内置函数的完整列表。
SHOW FUNCTIONS;
- 1
这些函数为用户在开发 SQL 查询时提供了一个功能强大的工具箱。 例如,CURRENT_TIMESTAMP 将在执行时打印出机器的当前系统时间。
SELECT CURRENT_TIMESTAMP;
- 1
3.2. Source 表
与所有 SQL 引擎一样,Flink 查询操作是在表上进行。与传统数据库不同,Flink 不在本地管理静态数据;相反,它的查询在外部表上连续运行。
Flink 数据处理流水线开始于 source 表。source 表产生在查询执行期间可以被操作的行;它们是查询时 FROM 子句中引用的表。这些表可能是 Kafka 的 topics,数据库,文件系统,或者任何其它 Flink 知道如何消费的系统。
可以通过 SQL 客户端或使用环境配置文件来定义表。SQL 客户端支持类似于传统 SQL 的 SQL DDL 命令。标准 SQL DDL 用于创建,修改,删除表。
Flink 支持不同的连接器和格式相结合以定义表。下面是一个示例,定义一个以 CSV 文件作为存储格式的 source 表,其中 emp_id,name,dept_id 作为 CREATE 表语句中的列。
CREATE TABLE employee_information (
emp_id INT,
name VARCHAR,
dept_id INT
) WITH (
'connector' = 'filesystem',
'path' = '/path/to/something.csv',
'format' = 'csv'
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
可以从该表中定义一个连续查询,当新行可用时读取并立即输出它们的结果。 例如,我们可以过滤出只在部门 1 中工作的员工。
SELECT * from employee_information WHERE dept_id = 1;
- 1
3.3. 连续查询
虽然最初设计时没有考虑流语义,但 SQL 是用于构建连续数据流水线的强大工具。Flink SQL 与传统数据库查询的不同之处在于,Flink SQL 持续消费到达的行并对其结果进行更新。
一个连续查询永远不会终止,并会产生一个动态表作为结果。动态表是 Flink 中 Table API 和 SQL 对流数据支持的核心概念。
连续流上的聚合需要在查询执行期间不断地存储聚合的结果。例如,假设你需要从传入的数据流中计算每个部门的员工人数。查询需要维护每个部门最新的计算总数,以便在处理新行时及时输出结果。
SELECT
dept_id,
COUNT(*) as emp_count
FROM employee_information
GROUP BY dept_id;
- 1
- 2
- 3
- 4
- 5
这样的查询被认为是 有状态的。Flink 的高级容错机制将维持内部状态和一致性,因此即使遇到硬件故障,查询也始终返回正确结果。
3.4. Sink 表
当运行此查询时,SQL 客户端实时但是以只读方式提供输出。存储结果,作为报表或仪表板的数据来源,需要写到另一个表。这可以使用 INSERT INTO 语句来实现。本节中引用的表称为 sink 表。INSERT INTO 语句将作为一个独立查询被提交到 Flink 集群中。
INSERT INTO department_counts
SELECT
dept_id,
COUNT(*) as emp_count
FROM employee_information;
- 1
- 2
- 3
- 4
- 5
提交后,它将运行并将结果直接存储到 sink 表中,而不是将结果加载到系统内存中。
3.5. 了解更多资源
- SQL:SQL 支持的操作和语法。
- SQL 客户端:不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上。
- 概念与通用 API:Table API 和 SQL 公共概念以及 API。
- 流式概念:Table API 和 SQL 中流式相关的文档,比如配置时间属性和如何处理更新结果。
- 内置函数:Table API 和 SQL 中的内置函数。
- 连接外部系统:读写外部系统的连接器和格式。
4. SELECT
4.1. 介绍
4.1.1. 无表查询示例
SELECT supplier_id, rating, COUNT(*) AS total
FROM
(VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4)
) AS Products(supplier_id, product_id, rating)
GROUP BY supplier_id, rating
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可以将该查询结果作为临时视图,也可以作为子表使用,在测试自定义函数中会非常有用。
比如将查询的结果直接插入表:
insert into mysql_table
SELECT supplier_id, rating, COUNT(*) AS total
FROM
(VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4)
) AS Products(supplier_id, product_id, rating)
GROUP BY supplier_id, rating
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.1.2. 查询
SELECT 语句和 VALUES 语句可在 TableEnvironment 对象的 sqlQuery() 方法中使用,该方法会将 SELECT (或 VALUES) 语句的结果作为 Table 对象返回。Table 对象可用于 sql 子查询和 Table API 查询、转化为一个 DataStream 、写入 TableSink 对象。SQL 和 Table API 查询可以无缝混合,并且被优化和翻译到同一个程序中。
为了在 SQL 查询中访问表,表必须被注册到 TabaleEnvironment 中。表可以通过 TableSource、Table、CREATE TABLE 语句、DataStream 被注册。另外,用户也可以通过在 TableEnvironment 中注册 catalog 来指定数据源的位置。
为了方便,Table.toString() 方法会自动将有唯一名称的表注册到 TableEnvironment 中,并返回表。因此,Table 对象可以直接在 SQL 查询中使用,就像下面的示例。
注:包含不支持的 SQL 特性将抛出 TableException 。batch 和 streaming 表所支持的 SQL 特性将会在下面的章节中列出。
4.1.3. 使用查询
下面的案例展示如何在 SQL 查询中指定被注册和内联表。
java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 从外部资源获取一个 DataStream DataStream<Tuple3<Long, String, Integer>> ds = env.addSource(...); // SQL 查询使用内联表(未注册的表) Table table = tableEnv.fromDataStream(ds, $("user"), $("product"), $("amount")); Table result = tableEnv.sqlQuery( "SELECT SUM(amount) FROM " + table + " WHERE product LIKE '%Rubber%'"); // SQL 查询使用被注册的表。 // 注册 DataStream 为视图:Orders tableEnv.createTemporaryView("Orders", ds, $("user"), $("product"), $("amount")); // 在表上执行 SQL 查询,并将结果检索为一张新表 Table result2 = tableEnv.sqlQuery( "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'"); // 创建并注册一个 TableSink final Schema schema = new Schema() .field("product", DataTypes.STRING()) .field("amount", DataTypes.INT()); tableEnv.connect(new FileSystem().path("/path/to/file")) .withFormat(...) .withSchema(schema) .createTemporaryTable("RubberOrders"); // 运行一个 INSERT SQL ,将输入写入 TableSink tableEnv.executeSql( "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
scala
val env = StreamExecutionEnvironment.getExecutionEnvironment val tableEnv = StreamTableEnvironment.create(env) // 从外部资源获取一个 DataStream val ds: DataStream[(Long, String, Integer)] = env.addSource(...) // SQL 查询使用内联表(未注册的表) val table = ds.toTable(tableEnv, $"user", $"product", $"amount") val result = tableEnv.sqlQuery( s"SELECT SUM(amount) FROM $table WHERE product LIKE '%Rubber%'") // SQL 查询使用被注册的表。 // 注册 DataStream 为视图:Orders tableEnv.createTemporaryView("Orders", ds, $"user", $"product", $"amount") // 在表上执行 SQL 查询,并将结果检索为一张新表 val result2 = tableEnv.sqlQuery( "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'") // 创建并注册一个 TableSink val schema = new Schema() .field("product", DataTypes.STRING()) .field("amount", DataTypes.INT()) tableEnv.connect(new FileSystem().path("/path/to/file")) .withFormat(...) .withSchema(schema) .createTemporaryTable("RubberOrders") // 运行一个 INSERT SQL ,将输入写入 TableSink tableEnv.executeSql( "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
4.1.4. 运行查询
可以通过 TableEnvironment.executeSql() 方法来执行一个 SELECT 或 VALUES 语句,并且将结果收集到本地,该方法会将 SELECT 或 VALUES 语句的结果以 TableResult 对象返回。对于一个简单的 SELECT 语句,可以通过调用 Table 对象的 Table.execute() 方法来收集查询的结果到本地客户端,而 TableEnvironment.executeSql() 方法会返回一个可关闭的行迭代器。查询任务在收集到所有结果数据之前不会结束运行,我们应该显式调用 CloseableIterator#close() 方法来避免资源泄露。我们也可以直接调用 TableResult.print() 方法将查询结果答应道客户端控制台。 TableResult 对象的结果数据只可被访问一次,因此,collect() 和 collect() 不能同时使用,只可使用其中一个。
TableResult.collect() 和 TableResult.print() 在不同的 checkpointing 设置下有不同的行为(对流任务启用 checkpointing,请参考 checkpointing配置)。
- 对于批任务和没有开启 checkpointing 的流任务,
TableResult.collect()和TableResult.print()都无法保证恰好一次或至少一次语义。他们产生的结果只能被客户端立即访问,而且在任务失败或重启时,还会抛出异常。 - 对于启用了恰好一次的 checkpoint 的流任务,
TableResult.collect()和TableResult.print()可以保证端到端的恰好一次的消息传递,但只有在他们相对应的 checkpoint 完成时,结果才能被客户端访问。 - 对于启用了至少一次 checkpointing 的流任务,
TableResult.collect()和TableResult.print()端到端至少一次的消息传递,他们产生的结果可以被客户端立即访问,但是可能会多次传递相同的结果。
java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings); tableEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...)"); // 执行 SELECT 语句 TableResult tableResult1 = tableEnv.executeSql("SELECT * FROM Orders"); // 使用 try-with-resources 语句来保证迭代器可以被自动关闭 try (CloseableIterator<Row> it = tableResult1.collect()) { while(it.hasNext()) { Row row = it.next(); // 处理 row } } // 执行表查询 TableResult tableResult2 = tableEnv.sqlQuery("SELECT * FROM Orders").execute(); tableResult2.print();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
scala
val env = StreamExecutionEnvironment.getExecutionEnvironment() val tableEnv = StreamTableEnvironment.create(env, settings) // enable checkpointing tableEnv.getConfig.getConfiguration.set( ExecutionCheckpointingOptions.CHECKPOINTING_MODE, CheckpointingMode.EXACTLY_ONCE) tableEnv.getConfig.getConfiguration.set( ExecutionCheckpointingOptions.CHECKPOINTING_INTERVAL, Duration.ofSeconds(10)) tableEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...)") // 执行 SELECT 语句 val tableResult1 = tableEnv.executeSql("SELECT * FROM Orders") val it = tableResult1.collect() try while (it.hasNext) { val row = it.next // 处理 row } finally it.close() // 关闭迭代器以避免资源泄露 // 执行表查询 val tableResult2 = tableEnv.sqlQuery("SELECT * FROM Orders").execute() tableResult2.print()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
4.1.5. 语法
Flink 使用 Apache Calcite 来转化 SQL,该方案支持标准的 ANSI SQL。
下面的 BNF-grammar 描述了批和流查询支持的 SQL 特性。下面的 Operations 章节展示了所支持的特性,以及表名哪些特性只支持批或流查询。
Grammar
query: values | WITH withItem [ , withItem ]* query | { select | selectWithoutFrom | query UNION [ ALL ] query | query EXCEPT query | query INTERSECT query } [ ORDER BY orderItem [, orderItem ]* ] [ LIMIT { count | ALL } ] [ OFFSET start { ROW | ROWS } ] [ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY] withItem: name [ '(' column [, column ]* ')' ] AS '(' query ')' orderItem: expression [ ASC | DESC ] select: SELECT [ ALL | DISTINCT ] { * | projectItem [, projectItem ]* } FROM tableExpression [ WHERE booleanExpression ] [ GROUP BY { groupItem [, groupItem ]* } ] [ HAVING booleanExpression ] [ WINDOW windowName AS windowSpec [, windowName AS windowSpec ]* ] selectWithoutFrom: SELECT [ ALL | DISTINCT ] { * | projectItem [, projectItem ]* } projectItem: expression [ [ AS ] columnAlias ] | tableAlias . * tableExpression: tableReference [, tableReference ]* | tableExpression [ NATURAL ] [ LEFT | RIGHT | FULL ] JOIN tableExpression [ joinCondition ] joinCondition: ON booleanExpression | USING '(' column [, column ]* ')' tableReference: tablePrimary [ matchRecognize ] [ [ AS ] alias [ '(' columnAlias [, columnAlias ]* ')' ] ] tablePrimary: [ TABLE ] tablePath [ dynamicTableOptions ] [systemTimePeriod] [[AS] correlationName] | LATERAL TABLE '(' functionName '(' expression [, expression ]* ')' ')' | [ LATERAL ] '(' query ')' | UNNEST '(' expression ')' tablePath: [ [ catalogName . ] databaseName . ] tableName systemTimePeriod: FOR SYSTEM_TIME AS OF dateTimeExpression dynamicTableOptions: /*+ OPTIONS(key=val [, key=val]*) */ key: stringLiteral val: stringLiteral values: VALUES expression [, expression ]* groupItem: expression | '(' ')' | '(' expression [, expression ]* ')' | CUBE '(' expression [, expression ]* ')' | ROLLUP '(' expression [, expression ]* ')' | GROUPING SETS '(' groupItem [, groupItem ]* ')' windowRef: windowName | windowSpec windowSpec: [ windowName ] '(' [ ORDER BY orderItem [, orderItem ]* ] [ PARTITION BY expression [, expression ]* ] [ RANGE numericOrIntervalExpression {PRECEDING} | ROWS numericExpression {PRECEDING} ] ')' matchRecognize: MATCH_RECOGNIZE '(' [ PARTITION BY expression [, expression ]* ] [ ORDER BY orderItem [, orderItem ]* ] [ MEASURES measureColumn [, measureColumn ]* ] [ ONE ROW PER MATCH ] [ AFTER MATCH ( SKIP TO NEXT ROW | SKIP PAST LAST ROW | SKIP TO FIRST variable | SKIP TO LAST variable | SKIP TO variable ) ] PATTERN '(' pattern ')' [ WITHIN intervalLiteral ] DEFINE variable AS condition [, variable AS condition ]* ')' measureColumn: expression AS alias pattern: patternTerm [ '|' patternTerm ]* patternTerm: patternFactor [ patternFactor ]* patternFactor: variable [ patternQuantifier ] patternQuantifier: '*' | '*?' | '+' | '+?' | '?' | '??' | '{' { [ minRepeat ], [ maxRepeat ] } '}' ['?'] | '{' repeat '}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
Flink SQL 使用语法词汇来表示标识符(table、attribute、function 名称),就像 java 一样:
- 无论标识符是否被使用,他们都会被保留大小写。
- 在此之后,标识符将会进行大小写匹配。
- 不像 java,反引号允许表示父包含非数字字母符号,比如:
“SELECT a AS my field FROM t”
字符串字面量必须使用单引号括起来,比如:SELECT 'Hello World'。两个双引号是为了转义,比如:SELECT 'It''s me.'。
Flink SQL> SELECT 'Hello World', 'It''s me';
+-------------+---------+
| EXPR$0 | EXPR$1 |
+-------------+---------+
| Hello World | It's me |
+-------------+---------+
1 row in set
- 1
- 2
- 3
- 4
- 5
- 6
- 7
字符串字面量支持 unicode 字符,如果需要显式使用 unicode 编码,使用下面的语法:
- 使用反斜杠
\转义字符(默认):SELECT U&'\263A' - 使用自定义的转义字符:
SELECT U&'#263A' UESCAPE '#'
4.1.6. Operations
- WITH clause
- SELECT & WHERE
- SELECT DISTINCT
- Windowing TVF
- Window Aggregation
- Group Aggregation
- Over Aggregation
- Joins
- Set Operations
- ORDER BY clause
- LIMIT clause
- Top-N
- Window Top-N
- Deduplication
- Pattern Recognition
4.2. SQL提示
在流批处理任务中均可使用。
SQL提示可以与select语句一起使用,以改变运行时的配置。本章展示如何使用提示来强制执行各种语法。
通常来说,提示可以被用于:
- 实施计划器:没有完美的计划器,因此实现提示以让用户更好的控制执行是很有意义的。
- 添加元数据(或统计数据):比如“浏览的表索引”和“shuffle键的倾斜信息”等一些查询的动态统计数据,可以很方便的使用提示来配置他们,因为计划器的元数据并不一直是准确的。
- 操作资源约束:在很多情况下,我们需要给执行操作配置默认的资源,比如最小的并行度或管理内存(UDF 使用的资源)或特殊的资源(GPU 或 SSD 磁盘)等,相比于整个任务,在每个查询中使用提示来配置资源是十分灵活的。
4.2.1. 动态表选项
动态表选项允许动态指定或覆盖表选项,不同于通过 SQL DDL 或连接器 API定义的静态表选项,这些选项可以在每个查询的每张表上灵活指定。
因此提示非常是用于在交互式终端上使用,比如,在 SQL-CLI 上,你可以通过在 CSV source 上增加动态选项 /*+ OPTIONS('csv.ignore-parse-errors'='true') */ 来忽略转化错误。
4.2.1.1. 语法
为了不破坏 SQL 的兼容性,flink sql采用了oracle风格的sql提示语法,如下所示:
table_path /*+ OPTIONS(key=val [, key=val]*) */
key:
stringLiteralval:
stringLiteral
- 1
- 2
- 3
- 4
4.2.1.2. 案例
CREATE TABLE kafka_table1 (id BIGINT, name STRING, age INT) WITH (...); CREATE TABLE kafka_table2 (id BIGINT, name STRING, age INT) WITH (...); -- 在查询中覆盖表选项 select id, name from kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */; -- 在join时覆盖表选项 select * from kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t1 join kafka_table2 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t2 on t1.id = t2.id; -- 覆盖insert的目标表选项 insert into kafka_table1 /*+ OPTIONS('sink.partitioner'='round-robin') */ select * from kafka_table2; -- 通过 sql 提示指定的选项,如果和建表时通过 with 指定的选项重复的,sql 提示指定的选项会将其覆盖
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
4.3. WITH子句
在流批处理任务中均可使用。
WITH提供了一种编写辅助语句的方法,以便在更大的查询中使用。这些语句通常称为公共表表达式(Common Table Expression, CTE),可以认为它们定义了仅用于一个查询的临时视图。
语法:
WITH <with_item_definition> [ , ... ]
SELECT ... FROM ...;
<with_item_defintion>:
with_item_name (column_name[, ...n]) AS ( <select_query> )
- 1
- 2
- 3
- 4
- 5
下面的with子句定义了orders_with_total,并且在group by子句中使用了它。
WITH orders_with_total AS (
SELECT order_id, price + tax AS total
FROM Orders
)
SELECT order_id, SUM(total)
FROM orders_with_total
GROUP BY order_id;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.4. SELECT和WHERE
在流批模式任务中均可使用。
SELECT语句的一般语法为:
SELECT select_list FROM table_expression [ WHERE boolean_expression ];
- 1
table_expression 可以引用任何数据源。它可以是一个现有表、视图或 VALUES 子句、多个现有表的连接结果或一个子查询。假设该表在 catalog 中可用,下面的语句将从 Orders 中读取所有行。
SELECT * FROM Orders;
- 1
select_list 中的 * 号表示查询将会解析所有列。但是,在生产中不鼓励使用。相反,select_list 可以指定手动可用列,或者使用可用列进行计算。入 Orders 表有名为 order_id、price 和 tax 的列,则可以编写以下查询:
SELECT order_id, price + tax FROM Orders
- 1
查询也可以通过 VALUES 子句使用内联数据。每个元组对应一行,可以提供一个别名来为每个列分配名称:
SELECT order_id, price FROM (VALUES (1, 2.0), (2, 3.1)) AS t (order_id, price);
- 1
可以根据 WHERE 子句筛选数据:
SELECT price + tax FROM Orders WHERE id = 10;
- 1
此外,可以在单行的列上调用内置和用户自定义的标量函数。用户自定义函数在使用前必须在目录中注册:
SELECT PRETTY_PRINT(order_id) FROM Orders;
- 1
4.5. SELECT和DISTINCT
在流批模式任务中均可使用。
如果指定了 SELECT DISTINCT,则会从结果集中删除所有重复的行(每组重复的行保留一行):
SELECT DISTINCT id FROM Orders;
- 1
对于流式查询,计算查询结果所需的状态可能会无限增长。状态大小取决于不同的数据行数量。可以提供具有适当状态生存时间(TTL),以防止状态存储过大。
注意,这可能会影响查询结果的正确性。详细信息请参见查询配置。
4.6. 窗口表值函数TVF
只支持流式任务。
Windows是处理无限流的核心,Windows将流分成有限大小的桶,我们可以在桶上面进行计算。
Apache Flink提供了几个窗口表值函数(TVF)来将表中的元素划分为到窗口中以供用户进行处理,包括:
- Tumble windows (滚动窗口)
- Hop windows (滑动窗口)
- Cumulate windows (累计窗口)
- Session windows(会话窗口)(即将支持)
注意,取决于使用的窗口表值函数,每个元素在逻辑上都可以属于多个窗口。比如,滑动窗口创建的重叠窗口,就可以将一个元素分配到多个窗口。
窗口表值函数是 flink 定义的多态表函数(Polymorphic Table Functions,简写 PTF)。PTF 是 SQL 2016 标准的一部分,它是一种特殊的表函数,可以将表作为参数。PTF 是改变表生态的一个强大特性,因为在语义上,PTF 就像表一样,他们的调用发生在 SELECT 语句的 FROM 子句中。
窗口表值函数是传统 Grouped Window Functions 的替换方案,窗口表值函数更兼容 SQL 标准,而且能够支持复杂的基于窗口的计算,比如窗口 TopN,窗口 join,但是 Grouped Window Functions 只能支持窗口聚合。
查看下面的窗口表值函数了解如何支持复杂计算:
4.6.1. 窗口函数
Apache Flink提供了3个内置的窗口TVFs:TUMBLE、HOP和CUMULATE。窗口TVF的返回值是一个新的关系,它包括原来关系的所有列,以及另外3列, 名为window_start,window_end
,window_time来表示分配的窗口。
window_time字段是窗口TVF执行之后的一个时间属性,可以在后续基于时间的操作中使用。比如其他的窗口表值函数、interval joins、over aggregations window_time 的值总是等于window_end - 1ms。
4.6.1.1. TUMBLE
滚动窗口函数将每个元素分配给指定大小的窗口,滚动窗口的大小是固定的,并且不会重叠。假设指定了一个大小为5分钟的滚动窗口,在这种情况下,Flink将计算当前窗口,并每5分钟启动一个新窗口,如下图所示。

TUMBLE 函数根据时间属性列为表的每一行分配一个窗口。TUMBLE 的返回值是一个新的关系,它包括原来表的所有列以及另外3列“window_start”,“window_end”,“window_time”来表示分配的窗口。
原表中的原始时间字段将是窗口TVF函数之后的常规时间列。TUMBLE函数需要三个必选参数和一个可选参数:
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
- 1
- data:表名,该表必须有一列类型为时间戳,也就是
TIMESTAMP类型。 - timecol:列名,表示该列数据映射到滚动窗口。
- size:指定滚动窗口的窗口大小。
- offset:可选参数,用于指定窗口开始的 offset,也就是指定产生窗口的时间点。
比如窗口时间为 5 分钟,指定开始移动的 offset 为 1 分钟,则触发的窗口如下:[1分钟, 6分钟)、[6分钟, 11分钟)、…。
下面是一个对Bid表的调用示例:
-- 表必须有时间字段,比如下表中的 `bidtime` 字段。 Flink SQL> desc Bid; +-------------+------------------------+------+-----+--------+---------------------------------+ | name | type | null | key | extras | watermark | +-------------+------------------------+------+-----+--------+---------------------------------+ | bidtime | TIMESTAMP(3) *ROWTIME* | true | | | `bidtime` - INTERVAL '1' SECOND | | price | DECIMAL(10, 2) | true | | | | | item | STRING | true | | | | +-------------+------------------------+------+-----+--------+---------------------------------+ Flink SQL> SELECT * FROM Bid; +------------------+-------+------+ | bidtime | price | item | +------------------+-------+------+ | 2020-04-15 08:05 | 4.00 | C | | 2020-04-15 08:07 | 2.00 | A | | 2020-04-15 08:09 | 5.00 | D | | 2020-04-15 08:11 | 3.00 | B | | 2020-04-15 08:13 | 1.00 | E | | 2020-04-15 08:17 | 6.00 | F | +------------------+-------+------+ -- 注意:目前flink不支持单独使用表值窗口函数,表值窗口函数应该和聚合操作一起使用,这个示例只是展示语法以及通过表值函数产生数据 SELECT * FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES) ); -- 或者是和参数名称一起使用。注意:DATA参数必须是第一个 SELECT * FROM TABLE( TUMBLE( DATA => TABLE Bid, TIMECOL => DESCRIPTOR(bidtime), SIZE => INTERVAL '10' MINUTES ) ); +------------------+-------+------+------------------+------------------+-------------------------+ | bidtime | price | item | window_start | window_end | window_time | +------------------+-------+------+------------------+------------------+-------------------------+ | 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | | 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | | 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | +------------------+-------+------+------------------+------------------+-------------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
从上面的结果可以看到,原始表的6行数据被分配到3个窗口中,每个滚动窗口是时间间隔为10分钟,窗口时间window_time为对应窗口结束时间-1ms。
-- 在滚动窗口表上执行聚合函数
SELECT window_start, window_end, SUM(price)
FROM
TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES)
)
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
+------------------+------------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
注意:为了更好地理解窗口的行为,我们简化了时间戳值的显示,不显示秒后面的零。
如果时间类型是 timestamp(3),在 Flink SQL Client 中,2020-04-15 08:05 应该显示为 2020-04-15 08:05:00.000。
4.6.1.2. HOP
HOP 函数将元素分配给固定长度的窗口。和 TUMBLE 窗口功能一样,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制跳跃窗口启动的频率,类似于 stream api 中的滑动窗口。
因此,如果滑动小于窗口大小,跳跃窗口就会重叠。在本例中,元素被分配给多个窗口。跳跃窗口也被称为“滑动窗口”。
例如,10 分钟大小的窗口,滑动 5 分钟。这样,每 5 分钟就会得到一个窗口,窗口包含在最近 10 分钟内到达的事件,如下图所示。
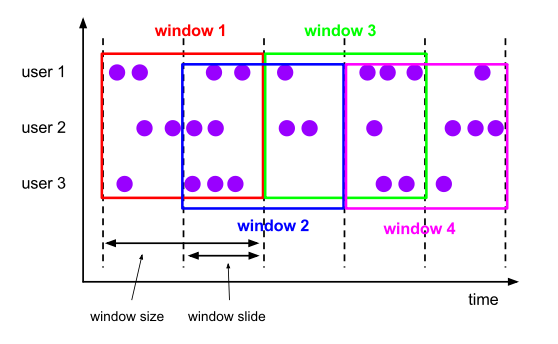
HOP函数窗口会覆盖指定大小区间内的数据行,并根据时间属性列移动。HOP的返回值是一个新的关系,它包括原来关系的所有列,以及“window_start”、“window_end”、“window_time”来表示指定的窗口。原表的原始的时间属性列“timecol”将是执行TVF后的常规时间戳列。
HOP 接受四个必需的参数和一个可选参数:
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
- 1
- data:表名,该表必须有一列类型为时间戳,也就是
TIMESTAMP类型。 - timecol:列名,表示该列数据映射到滑动窗口。
- slide:滑动时间,指定连续滑动窗口之间的间隔时间。
- size:指定滑动窗口的窗口大小。
- offset:可选参数,用于指定窗口开始的 offset,也就是指定产生窗口的时间点。
比如窗口时间为 5 分钟,指定开始移动的 offset 为 1 分钟,则触发的窗口如下:[1分钟, 6分钟)、[6分钟, 11分钟)、…。
下面是一个对Bid表的调用示例:
-- 注意:目前flink不支持单独使用表值窗口函数,表值窗口函数应该和聚合操作一起使用,这个示例只是展示语法以及通过表值函数产生数据 SELECT * FROM TABLE( HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES) ); -- 或者是和参数名称一起使用。注意:DATA参数必须是第一个 SELECT * FROM TABLE( HOP( DATA => TABLE Bid, TIMECOL => DESCRIPTOR(bidtime), SLIDE => INTERVAL '5' MINUTES, SIZE => INTERVAL '10' MINUTES ) ); +------------------+-------+------+------------------+------------------+-------------------------+ | bidtime | price | item | window_start | window_end | window_time | +------------------+-------+------+------------------+------------------+-------------------------+ | 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 | | 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 | | 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 | | 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 | | 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | | 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 | | 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | | 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | | 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:15 | 2020-04-15 08:25 | 2020-04-15 08:24:59.999 | +------------------+-------+------+------------------+------------------+-------------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
从上面的结果可以看出,由于窗口有重叠,所有很多数据都属于两个窗口。
-- 在滑动窗口表上运行聚合函数 SELECT window_start, window_end, SUM(price) FROM TABLE( HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES) ) GROUP BY window_start, window_end; +------------------+------------------+-------+ | window_start | window_end | price | +------------------+------------------+-------+ | 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 | | 2020-04-15 08:05 | 2020-04-15 08:15 | 15.00 | | 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 | | 2020-04-15 08:15 | 2020-04-15 08:25 | 6.00 | +------------------+------------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.6.1.3. CUMULATE
累积窗口,或者叫做渐进式窗口,在某些情况下是非常有用的,例如在固定的窗口间隔内早期触发滚动窗口。
例如,仪表板显示当天的实时总UV数,需要从每天的 00:00 开始到累计每分钟的UV值,10:00 的UV值表示 00:00 到 10:00 的 UV 总数,这就可以通过累积窗口轻松有效地实现。
CUMULATE 函数将元素分配给窗口,这些窗口在初始步长间隔内覆盖行数据,并且每一步都会扩展到一个更多的步长(保持窗口开始时间为固定值),直到最大窗口大小。
可以把 CUMULATE 函数看作是先应用具有最大窗口大小的 TUMBLE 窗口,然后把每个滚动窗口分成几个窗口,每个窗口的开始和结束都有相同的步长差。所以累积窗口有重叠,而且没有固定的大小。
例如有一个累积窗口,1 小时的步长和 1 天的最大大小,将获得窗口:[00:00,01:00),[00:00,02:00),[00:00,03:00),…,[00:00,24:00),每天都如此。
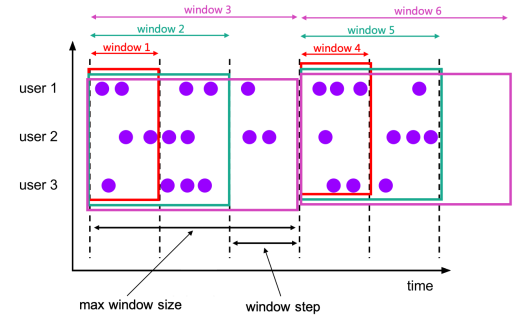
累积窗口基于时间属性列分配窗口。CUMULATE 的返回值是一个新的关系,它包括原来关系的所有列,另外还有3列,分别是“window_start”、“window_end”、“window_time”,表示指定的窗口。
原始的时间属性“timecol”将是窗口TVF之后的常规时间戳列。
CUMULATE接受三个必需的参数和一个可选参数:
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size [, offset ])
- 1
- data:表名,该表必须有一列类型为时间戳,也就是
TIMESTAMP类型。 - timecol:列名,表示该列数据映射到累计窗口。
- step:步长,指定连续累积窗口结束时间之间增加的窗口大小的时间间隔。
- size:指定累积窗口的窗口大小。大小必须是步长的整数倍。
- offset:可选参数,用于指定窗口开始移动的 offset,也就是指定产生窗口的时间点。
比如窗口时间为 5 分钟,指定开始移动的 offset 为 1 分钟,则触发的窗口如下:[1分钟, 6分钟)、[6分钟, 11分钟)、…。
下面是一个对Bid表的调用示例:
-- 注意:目前flink不支持单独使用表值窗口函数,表值窗口函数应该和聚合操作一起使用,这个示例只是展示语法以及通过表值函数产生数据 SELECT * FROM TABLE( CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES) ); -- 或者是和参数名称一起使用。注意:DATA参数必须是第一个 SELECT * FROM TABLE( CUMULATE( DATA => TABLE Bid, TIMECOL => DESCRIPTOR(bidtime), STEP => INTERVAL '2' MINUTES, SIZE => INTERVAL '10' MINUTES ) ); +------------------+-------+------+------------------+------------------+-------------------------+ | bidtime | price | item | window_start | window_end | window_time | +------------------+-------+------+------------------+------------------+-------------------------+ | 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:06 | 2020-04-15 08:05:59.999 | | 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:08 | 2020-04-15 08:07:59.999 | | 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:08 | 2020-04-15 08:07:59.999 | | 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:12 | 2020-04-15 08:11:59.999 | | 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 | | 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:16 | 2020-04-15 08:15:59.999 | | 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:18 | 2020-04-15 08:17:59.999 | | 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | | 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 | | 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:16 | 2020-04-15 08:15:59.999 | | 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:18 | 2020-04-15 08:17:59.999 | | 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | | 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:18 | 2020-04-15 08:17:59.999 | | 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | +------------------+-------+------+------------------+------------------+-------------------------+ -- 在窗口表上运行聚合函数 SELECT window_start, window_end, SUM(price) FROM TABLE( CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES) ) GROUP BY window_start, window_end; +------------------+------------------+-------+ | window_start | window_end | price | +------------------+------------------+-------+ | 2020-04-15 08:00 | 2020-04-15 08:06 | 4.00 | | 2020-04-15 08:00 | 2020-04-15 08:08 | 6.00 | | 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 | | 2020-04-15 08:10 | 2020-04-15 08:12 | 3.00 | | 2020-04-15 08:10 | 2020-04-15 08:14 | 4.00 | | 2020-04-15 08:10 | 2020-04-15 08:16 | 4.00 | | 2020-04-15 08:10 | 2020-04-15 08:18 | 10.00 | | 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 | +------------------+------------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
4.6.2. Window Offset
offset 是一个可选参数,该参数可以被用于更改窗口的分配,该参数的值应该是一个正数或者是负数。默认的 window offset 为 0。如果设置不同的 offset 值,则同一条数据可能会被分配到不同的窗口。下面列出的是时间戳为 2021-06-30 00:00:04 的数据将被分配到哪个以 10 分钟为窗口大小的窗口:
- 如果 offset 值为
-16 MINUTE,数据将会被分配给 [2021-06-29 23:54:00, 2021-06-30 00:04:00) 窗口。 - 如果 offset 值为
-6 MINUTE,数据将会被分配给 [2021-06-29 23:54:00, 2021-06-30 00:04:00) 窗口。 - 如果 offset 值为
-4 MINUTE,数据将会被分配给 [2021-06-29 23:56:00, 2021-06-30 00:06:00) 窗口。 - 如果 offset 值为
0,数据将会被分配给 [2021-06-30 00:00:00, 2021-06-30 00:10:00) 窗口。 - 如果 offset 值为
4 MINUTE,数据将会被分配给 [2021-06-29 23:54:00, 2021-06-30 00:04:00) 窗口。 - 如果 offset 值为
6 MINUTE,数据将会被分配给 [2021-06-29 23:56:00, 2021-06-30 00:06:00) 窗口。 - 如果 offset 值为
16 MINUTE,数据将会被分配给 [2021-06-29 23:56:00, 2021-06-30 00:06:00) 窗口。
通过上述案例可以看到,有些窗口 offset 参数值可能会得到相同的窗口分配。
比如: -16 MINUTE, -6 MINUTE 和 4 MINUTE ,对于 10 MINUTE 大小的窗口,会得到相同滚动窗口。
注意:窗口的 offset 只用于改变窗口的分配,而不会影响水印。
下面是一个在滚动窗口中使用 offset 的 sql 案例:
-- 注意:目前 flink 不支持直接使用窗口表值函数。 -- 窗口表值函数应该被用于聚合操作,下面的例子只是用于展示语法以及表值函数产生的数据。 Flink SQL> SELECT * FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES, INTERVAL '1' MINUTES) ); -- 或者指定参数名称 -- 注意:DATA 参数必须放在最开始 Flink SQL> SELECT * FROM TABLE( TUMBLE( DATA => TABLE Bid, TIMECOL => DESCRIPTOR(bidtime), SIZE => INTERVAL '10' MINUTES, OFFSET => INTERVAL '1' MINUTES ) ); +------------------+-------+------+------------------+------------------+-------------------------+ | bidtime | price | item | window_start | window_end | window_time | +------------------+-------+------+------------------+------------------+-------------------------+ | 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:01 | 2020-04-15 08:11 | 2020-04-15 08:10:59.999 | | 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:01 | 2020-04-15 08:11 | 2020-04-15 08:10:59.999 | | 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:01 | 2020-04-15 08:11 | 2020-04-15 08:10:59.999 | | 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:11 | 2020-04-15 08:21 | 2020-04-15 08:20:59.999 | | 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:11 | 2020-04-15 08:21 | 2020-04-15 08:20:59.999 | | 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:11 | 2020-04-15 08:21 | 2020-04-15 08:20:59.999 | +------------------+-------+------+------------------+------------------+-------------------------+ -- 在滚动窗口结果表上使用聚合函数 Flink SQL> SELECT window_start, window_end, SUM(price) FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES, INTERVAL '1' MINUTES) ) GROUP BY window_start, window_end; +------------------+------------------+-------+ | window_start | window_end | price | +------------------+------------------+-------+ | 2020-04-15 08:01 | 2020-04-15 08:11 | 11.00 | | 2020-04-15 08:11 | 2020-04-15 08:21 | 10.00 | +------------------+------------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
注意:为了更好的理解窗口的行为,我们简单的展示了 timestamp 类型的值,并没有展示后面的0。
比如 2020-04-15 08:05 ,如果类型为 TIMESTAMP(3), 准确来说,在 sql client 中应该被展示为 2020-04-15 08:05:00.000。
4.7. 窗口聚合
4.7.1. 窗口表值函数TVF聚合
只支持流式任务。
窗口聚合函数可以使用通过 group by 子句中定义的窗口表值聚合函数的结果表中的“window_start”和“window_end”列。就像使用常规 GROUP BY 子句的查询一样,使用 GROUP BY 窗口聚合的查询会给每个组计算出单个结果行。
SELECT ...
FROM <windowed_table> -- 接受通过窗口表值函数TVF生成的表
GROUP BY window_start, window_end, ...
- 1
- 2
- 3
与连续流表上的其他聚合不同,窗口聚合不发出中间结果,而只发出最终结果,即窗口结束之后的总聚合。此外,当不再需要时,窗口聚合会清除所有中间状态。
4.7.1.1. 窗口表值函数TVF
Flink支持 TUMBLE、HOP 和 CUMULATE 类型的窗口聚合,它们可以定义在事件时间或处理时间属性上。
下面是一些 TUMBLE、HOP 和 CUMULATE 窗口聚合的例子。
-- 表必须有时间属性列,比如下面表中的`bidtime`列。 Flink SQL> desc Bid; +-------------+------------------------+------+-----+--------+---------------------------------+ | name | type | null | key | extras | watermark | +-------------+------------------------+------+-----+--------+---------------------------------+ | bidtime | TIMESTAMP(3) *ROWTIME* | true | | | `bidtime` - INTERVAL '1' SECOND | | price | DECIMAL(10, 2) | true | | | | | item | STRING | true | | | | | supplier_id | STRING | true | | | | +-------------+------------------------+------+-----+--------+---------------------------------+ Flink SQL> SELECT * FROM Bid; +------------------+-------+------+-------------+ | bidtime | price | item | supplier_id | +------------------+-------+------+-------------+ | 2020-04-15 08:05 | 4.00 | C | supplier1 | | 2020-04-15 08:07 | 2.00 | A | supplier1 | | 2020-04-15 08:09 | 5.00 | D | supplier2 | | 2020-04-15 08:11 | 3.00 | B | supplier2 | | 2020-04-15 08:13 | 1.00 | E | supplier1 | | 2020-04-15 08:17 | 6.00 | F | supplier2 | +------------------+-------+------+-------------+ -- 滚动窗口聚合 SELECT window_start, window_end, SUM(price) FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES) ) GROUP BY window_start, window_end; +------------------+------------------+-------+ | window_start | window_end | price | +------------------+------------------+-------+ | 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 | | 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 | +------------------+------------------+-------+ -- 滑动窗口聚合 SELECT window_start, window_end, SUM(price) FROM TABLE( HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES)) GROUP BY window_start, window_end; +------------------+------------------+-------+ | window_start | window_end | price | +------------------+------------------+-------+ | 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 | | 2020-04-15 08:05 | 2020-04-15 08:15 | 15.00 | | 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 | | 2020-04-15 08:15 | 2020-04-15 08:25 | 6.00 | +------------------+------------------+-------+ -- 累计窗口聚合 SELECT window_start, window_end, SUM(price) FROM TABLE( CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES) ) GROUP BY window_start, window_end; +------------------+------------------+-------+ | window_start | window_end | price | +------------------+------------------+-------+ | 2020-04-15 08:00 | 2020-04-15 08:06 | 4.00 | | 2020-04-15 08:00 | 2020-04-15 08:08 | 6.00 | | 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 | | 2020-04-15 08:10 | 2020-04-15 08:12 | 3.00 | | 2020-04-15 08:10 | 2020-04-15 08:14 | 4.00 | | 2020-04-15 08:10 | 2020-04-15 08:16 | 4.00 | | 2020-04-15 08:10 | 2020-04-15 08:18 | 10.00 | | 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 | +------------------+------------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
注意:为了更好地理解窗口的行为,我们简化了时间戳值的显示,以不显示秒小数点后面的零,
例如,如果类型是 timestamp(3),在 Flink SQL Client 中,2020-04-15 08:05 应该显示为 2020-04-15 08:05:00.000。
4.7.1.2. GROUPING SETS
窗口聚合也支持 GROUPING SETS 语法。GROUPING SETS 允许进行比标准 GROUP BY 更复杂的分组操作。行按每个指定的分组集单独分组,并为每个分组计算聚合,就像简单的 group by 子句一样。
带有 GROUPING SETS 的窗口聚合要求 window_start 和 window_end 列必须在 GROUP BY 子句中,但不能在 GROUPING SETS 子句中。
SELECT window_start, window_end, supplier_id, SUM(price) as price FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES) ) GROUP BY window_start, window_end, GROUPING SETS ((supplier_id), ()); +------------------+------------------+-------------+-------+ | window_start | window_end | supplier_id | price | +------------------+------------------+-------------+-------+ | 2020-04-15 08:00 | 2020-04-15 08:10 | (NULL) | 11.00 | | 2020-04-15 08:00 | 2020-04-15 08:10 | supplier2 | 5.00 | | 2020-04-15 08:00 | 2020-04-15 08:10 | supplier1 | 6.00 | | 2020-04-15 08:10 | 2020-04-15 08:20 | (NULL) | 10.00 | | 2020-04-15 08:10 | 2020-04-15 08:20 | supplier2 | 9.00 | | 2020-04-15 08:10 | 2020-04-15 08:20 | supplier1 | 1.00 | +------------------+------------------+-------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
GROUPING SETS 的每个子列表可以指定零个或多个列或表达式,并且解释方式与直接写在 GROUP BY 子句相同。空分组集意味着将所有行聚合为单个组,即使没有输入行,该组也会输出。
对于 GROUPING SETS 中的子集,如果没有指定任何数据列或表达式,将会使用 NULL 值来代替,表示对窗口时间内的全量数据进行聚合。
4.7.1.2.1. ROLLUP
ROLLUP 是一种用于指定通用分组集类型的简写符号。它表示给定的表达式列表,前缀列表和空列表。
前缀列表:也就是说,子列表是指定的所有字段,然后每次去掉最后面一个字段而生成的表达式列表,示例如下:
rollup(s1, s2, s3)
s1, s2, s3
s1, s2, null
s1, null, null
null, null, null
- 1
- 2
- 3
- 4
- 5
带有ROLLUP的窗口聚合要求 window_start 和 window_end 列必须在 GROUP BY 子句中,而不是在 ROLLUP 子句中。
例如,下面的查询与上面的查询等价。
SELECT window_start, window_end, supplier_id, SUM(price) as price
FROM
TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES)
)
GROUP BY window_start, window_end, ROLLUP (supplier_id);
- 1
- 2
- 3
- 4
- 5
- 6
4.7.1.2.2. CUBE
CUBE 是一种用于指定公共分组集类型的简写符号。它表示给定的列表及其所有可能的子集,包括空列表。
使用 CUBE 的窗口聚合要求 window_start 和 window_end 列必须在 GROUP BY 子句中,而不在 CUBE 子句中。
例如,下面两个查询是等价的。
SELECT window_start, window_end, item, supplier_id, SUM(price) as price FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES) ) GROUP BY window_start, window_end, CUBE (supplier_id, item); ------------------------------------------------------------------------------ SELECT window_start, window_end, item, supplier_id, SUM(price) as price FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES) ) GROUP BY window_start, window_end, GROUPING SETS ( (supplier_id, item), (supplier_id ), ( item), ( ) )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4.7.1.3. select分组窗口开始结束时间
可以使用分组的 window_start 和 window_end 列来作为组窗口的开始和结束时间戳。
4.7.1.4. 层叠窗口聚合
window_start 和 window_end 列是常规的时间戳列,而不是时间属性。因此,它们不能在随后的基于时间的操作中用作时间属性。为了传播时间属性,需要在 GROUP BY 子句中添加 window_time 列。
window_time 是窗口表值函数 TVF 产生的第三列,它是指定窗口的时间属性,比窗口结束时间早1毫秒。将 window_time 添加到 GROUP BY 子句中,使得 window_time 也成为可以选择的时间列。
然后,查询就可以将此列用于后续基于时间的操作,例如层叠窗口聚合和窗口 TopN。
下面代码显示了层叠窗口聚合用法,其中第一个窗口聚合函数传播第二个窗口聚合的时间属性。
-- 对每个supplier_id进行5分钟的滚动窗口计算 CREATE VIEW window1 AS SELECT window_start, window_end, window_time as rowtime, SUM(price) as partial_price FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES) ) GROUP BY supplier_id, window_start, window_end, window_time; -- 在上面的窗口结果基础上进行10分钟的窗口滚动计算 SELECT window_start, window_end, SUM(partial_price) as total_price FROM TABLE( TUMBLE(TABLE window1, DESCRIPTOR(rowtime), INTERVAL '10' MINUTES) ) GROUP BY window_start, window_end;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.7.2. 分组窗口聚合
流批任务均可使用。
警告:分组窗口聚合已经过时,建议使用窗口表值聚合函数,功能更强,效率更高。
相比于分组窗口聚合,窗口表值函数有很多优点,包括:
分组窗口聚合函数定义在 SQL 查询的 GROUP BY 子句中。就像常规 GROUP BY 子句一样, GROUP BY 子句会会通过一个分组窗口函数对每个组的数据计算一个结果值。下面的分组窗口函数支持在 batch 和 streaming 表上运行的 SQL。
4.7.2.1. 分组窗口函数
| 分组窗口函数 | 描述 |
|---|---|
TUMBLE(time_attr, interval) | 定义一个滚动时间窗口,滚动时间窗口没有间隙,并且有一个固定的时间间隔(interval 参数)。比如,五分钟的滚动时间窗口会将五分钟的数据作为一组。滚动窗口可以通过事件时间(stream + batch)和处理时间(stream)定义。 |
HOP(time_attr, interval, interval) | 定义一个滑动(hop)时间窗口,在 Table API 中叫 sliding 窗口。滑动时间窗口有一个固定的时间间隔(第二个 interval 参数)和滑动的时间间隔(第一个 interval 参数)。如果滑动间隔小于窗口大小,滑动窗口将会重叠,因此数据将会被分配到多个窗口。比如,一个 15 分钟大小的滑动窗口,滑动时间为 5 分钟,一条数据将会在 15 分钟内被分配三个不同的窗口。滑动窗口可以通过事件时间(stream + batch)和处理时间(stream)定义。 |
SESSION(time_attr, interval) | 定义一个会话时间窗口,会话时间窗口没有固定的时间间隔,而是通过指定的不活跃时间间隔来定义,会话窗口将会在指定的时间间隔没有收到任何事件时关闭。比如,会话窗口会在 30 内收不到任何数据时关闭,否则数据将会被添加到一个已经存在的窗口。会话时间窗口可以通过事件时间(stream + batch)和处理时间(stream)定义。 |
4.7.2.2. 时间属性
对于 streaming 表上的 SQL 查询,分组窗口函数的 time_attr 参数必须是通过事件时间或处理时间指定的合法时间属性的字段。查看 documentation of time attributes 来了解怎么定义时间属性。
对于 batch 表上的 SQL 查询,分组窗口函数的 time_attr 参数对应的字段类型必须是 TIMESTAMP。
4.7.2.3. 选择分组窗口的开始和结束时间戳
分组窗口的开始和结束时间戳可以通过下面的辅助函数来选择:
| 辅助函数 | 描述 |
|---|---|
| TUMBLE_START(time_attr, interval) HOP_START(time_attr, interval, interval) SESSION_START(time_attr, interval) | 返回滚动、滑动或会话窗口开始时间戳(包含)。 |
| TUMBLE_END(time_attr, interval) HOP_END(time_attr, interval, interval) SESSION_END(time_attr, interval) | 返回滚动、滑动或会话窗口结束时间戳(不包含)。 注意:上边界时间戳不能作为时间属性字段在基于时间操作的子查询中使用,比如:interval joins、group window 、 over window aggregations。 |
| TUMBLE_ROWTIME(time_attr, interval) HOP_ROWTIME(time_attr, interval, interval) SESSION_ROWTIME(time_attr, interval) | 返回滚动、滑动或会话窗口开始时间戳(包含),该结果属性可以作为运行时的时间属性被用于基于时间操作的子查询,比如:interval joins、group window 、 over window aggregations。 |
| TUMBLE_PROCTIME(time_attr, interval) HOP_PROCTIME(time_attr, interval, interval) SESSION_PROCTIME(time_attr, interval) | 返回处理时间属性,可以被用于基于时间操作的子查询,比如:interval joins、group window 、 over window aggregations。 |
注意:辅助函数的参数必须和 GROUP BY 子句中分组窗口函数一致。
下面的案例展示如何在 streaming 表的 SQL 查询中使用分组窗口函数。
CREATE TABLE Orders (
user BIGINT,
product STIRNG,
amount INT,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '1' MINUTE
) WITH (...);
SELECT
user,
TUMBLE_START(order_time, INTERVAL '1' DAY) AS wStart,
SUM(amount) FROM Orders
GROUP BY
TUMBLE(order_time, INTERVAL '1' DAY),
user
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.8. 分组聚合
可用于流批任务。
像大多数数据系统一样,Apache Flink支持聚合函数:内置的和用户定义的。用户定义函数在使用前必须在 catalog 中注册。
聚合函数通过多个输入行计算单个结果。例如,在一组行数据上计算 COUNT、SUM、AVG (平均)、MAX (最大)和 MIN (最小)的聚合。
SELECT COUNT(*) FROM Orders;
- 1
flink 的流查询是永远不会终止的连续查询。该查询会根据输入表的新数据来更新结果表。对于上面的查询,每次在 Orders 表中插入新行时,Flink 都会输出一个更新的计数。
Apache Flink 支持用于聚合数据的标准 GROUP BY 子句。
SELECT COUNT(*)
FROM Orders
GROUP BY order_id;
- 1
- 2
- 3
对于流式查询,计算查询结果所需的状态可能会无限增长。状态大小取决于组的数量以及聚合函数的数量和类型。可以配置查询的状态生存时间(TTL),以防止状态大小过大。但这可能会影响查询结果的正确性。
详细信息请参见查询配置。
Apache Flink 为 Group Aggregation 提供了一系列性能调优方法,请参阅更多的性能调优。
4.8.1. DISTINCT聚合
有些聚合需要在调用聚合函数之前删除重复值。下面的示例计算 Orders 表中不同 order_ids 的数量,而不是总行数。
SELECT COUNT(DISTINCT order_id) FROM Orders;
- 1
对于流式查询,计算查询结果所需的状态可能无限增长。状态大小主要取决于不同的行数和组维护的时间,短时间的窗口组聚合不是问题。可以配置查询的状态生存时间(TTL),以防止状态大小过大。
注意,这可能会影响查询结果的正确性。详细信息请参见查询配置。
4.8.2. GROUPING SETS
grouping sets 可以执行比标准 GROUP BY 更复杂的分组操作。行数据按每个分组集单独分组,并为每个分组计算聚合函数,就像简单的 group by 子句一样。
SELECT supplier_id, rating, COUNT(*) AS total FROM (VALUES ('supplier1', 'product1', 4), ('supplier1', 'product2', 3), ('supplier2', 'product3', 3), ('supplier2', 'product4', 4) ) AS Products(supplier_id, product_id, rating) GROUP BY GROUPING SETS ((supplier_id, rating), (supplier_id), ()); +-------------+--------+-------+ | supplier_id | rating | total | +-------------+--------+-------+ | supplier1 | 4 | 1 | | supplier1 | (NULL) | 2 | | (NULL) | (NULL) | 4 | | supplier1 | 3 | 1 | | supplier2 | 3 | 1 | | supplier2 | (NULL) | 2 | | supplier2 | 4 | 1 | +-------------+--------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
GROUPING SETS 的每个子列表可以指定零个或多个列或表达式,并且其解释方式与直接在 GROUP BY 子句中使用相同。空分组集意味着将所有行聚合为单个组,即使没有输入行,该组也会输出。
对于分组中集中未出现的列或表达式,会使用 NULL 进行替换,如上图所示。
对于流式查询,计算查询结果所需的状态可能无限增长。状态大小取决于组集的数量和聚合函数的类型。可以配置查询的状态生存时间(TTL),以防止状态大小过大。注意,这可能会影响查询结果的正确性。
详细信息请参见查询配置。
4.8.2.1. ROLLUP
ROLLUP是一种用于指定通用分组集类型的简单用法。它表示给定的表达式列表、前缀列表、空列表。 例如,下面的查询与上面的查询等价。
SELECT supplier_id, rating, COUNT(*)
FROM
(VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4)
)
AS Products(supplier_id, product_id, rating)
GROUP BY ROLLUP (supplier_id, rating);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.8.2.2. CUBE
CUBE 是一种用于指定公共分组集类型的简单用法。它表示给定的列表及其所有可能的子集。例如,下面两个查询是等价的。
SELECT supplier_id, rating, product_id, COUNT(*) FROM (VALUES ('supplier1', 'product1', 4), ('supplier1', 'product2', 3), ('supplier2', 'product3', 3), ('supplier2', 'product4', 4) ) AS Products(supplier_id, product_id, rating) GROUP BY CUBE (supplier_id, rating, product_id); -------------------------------------------------------------------------- SELECT supplier_id, rating, product_id, COUNT(*) FROM (VALUES ('supplier1', 'product1', 4), ('supplier1', 'product2', 3), ('supplier2', 'product3', 3), ('supplier2', 'product4', 4) ) AS Products(supplier_id, product_id, rating) GROUP BY GROUPING SET ( ( supplier_id, product_id, rating ), ( supplier_id, product_id ), ( supplier_id, rating ), ( supplier_id ), ( product_id, rating ), ( product_id ), ( rating ), ( ) );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
4.8.3. HAVING
HAVING 消除不满足条件的组行。HAVING 不同于 WHERE: WHERE 在 GROUP BY 之前过滤单独的行,而 HAVING 过滤 GROUP BY 创建的行数据。HAVING 条件引用的每个列必须是分组列中的列,以及聚合函数结果。
SELECT SUM(amount)
FROM Orders
GROUP BY users
HAVING SUM(amount) > 50;
- 1
- 2
- 3
- 4
HAVING 的存在会将查询转换为分组查询,即使没有 GROUP BY 子句。这与查询包含聚合函数但没有 GROUP BY 子句时发生的情况相同。
查询会将所有选定的行组成一个组,SELECT 列表和 HAVING 子句只能从聚合函数中引用列。如果 HAVING 条件为真,这样的查询将产生一行结果,如果不为真,则产生零行结果。
4.9. OVER聚合
流批处理任务均可使用。
OVER 聚合会对输入的每一行有序数据计算聚合值。与 GROUP BY 聚合相比,OVER 聚合不会将每个组的结果行数减少到一行。相反,OVER 聚合为每个输入行生成一个聚合值。
下面的查询会为每个订单计算在当前订单之前一小时内收到的相同产品的所有订单的总和。
SELECT order_id, order_time, amount,
SUM(amount) OVER (
PARTITION BY product
ORDER BY order_time
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
) AS one_hour_prod_amount_sum
FROM Orders
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
OVER 窗口的语法结构如下:
SELECT
agg_func(agg_col) OVER (
[PARTITION BY col1[, col2, ...]]
ORDER BY time_col
range_definition
),
...
FROM ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以在 SELECT 子句中定义多个 OVER 窗口聚合。但是,对于流查询,由于当前的限制,所有聚合的 OVER 窗口必须是相同的。
4.9.1. ORDER BY
OVER 窗口定义在一个有序的行序列上。由于表数据没有固定的顺序,因此 order by 子句是强制的。对于流式查询,Flink 目前只支持以升序时间属性列顺序定义的窗口。
4.9.2. PARTITION BY
可以在分区表上定义 OVER 窗口。如果存在 PARTITION BY 子句,则只在每个输入行所在分区的行上计算聚合。
4.9.3. Range定义
范围定义指定聚合中包含多少行。这个范围是用 BETWEEN 子句定义的,它定义了下边界和上边界。边界之间的所有行都会包含在聚合中。Flink 只支持 CURRENT ROW 作为上边界。
有两个选项可以定义范围,ROWS 间隔和 RANGE 间隔。
RANGE intervals
RANGE 间隔是在 ORDER BY 列的值上定义的,在 Flink 中,需要该列类型为时间属性。下面的 RANGE 间隔定义函数:聚合中包含时间为当前行 30 分钟的所有行。
RANGE BETWEEN INTERVAL '30' MINUTE PRECEDING AND CURRENT ROW
- 1
ROW intervals
ROWS 间隔是一个基于计数的间隔。它确切地定义了聚合中包含的数据行数。下面的 ROWS 间隔定义函数:当前行和当前行之前的 10 行(总共 11 行)包含在聚合中。
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
- 1
4.9.4. WINDOW子句
WINDOW 子句可用于在 SELECT 子句之外定义 OVER 窗口。它可以使查询更具可读性,也允许我们的多个聚合重用同一个窗口定义。
SELECT order_id, order_time, amount,
SUM(amount) OVER w AS sum_amount,
AVG(amount) OVER w AS avg_amount
FROM Orders
WINDOW w AS (
PARTITION BY product
ORDER BY order_time
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.10. Join
可同时用于流批处理任务。
Flink SQL 支持对动态表执行复杂而灵活的连接操作。有几种不同类型的连接来支持需要的各种查询。
默认情况下,表的连接顺序并不会优化查询效率。表是按照在FROM子句中指定的顺序连接的。通过先列出更新频率最低的表,然后列出更新频率最高的表,可以调整连接查询的性能。
确保以不会产生交叉连接(笛卡尔积)的顺序指定表即可,交叉连接不受支持,而且会导致查询失败。
4.10.1. 常规Join
常规连接是最通用的连接类型,其中任何新记录或对连接任意一侧的更改都会影响整个连接结果。例如,左表产生一条新记录,当产品 id 在右表可以找到时,它将与右表所有以前和将来的记录进行连接。
SELECT * FROM Orders
INNER JOIN Product
ON Orders.productId = Product.id;
- 1
- 2
- 3
对于流查询,常规连接的语法是最灵活的,可以使用任何类型的更新(插入、更新、删除)输入表。然而,该操作具有重要的含义:它要求连接输入的两张表永远在Flink中保持state状态。
因此,计算查询结果所需的状态可能会无限增长,这取决于所有输入表和中间连接结果的不同输入行数。可以适当配置查询的状态生存时间(TTL),以防止状态大小过大。注意,这可能会影响查询结果的正确性。详细信息请参见查询配置。
对于流查询,计算查询结果所需的状态可能会无限增长,这取决于聚合的类型和不同分组键的数量。请提供具有有效保留间隔的查询配置,以防止状态大小过大。查看 Idle State Retention Time 来了解更多细节。
4.10.1.1. INNER等值连接
返回受连接条件限制的简单笛卡尔积。目前只支持等值连接,即至少具有一个具有相等谓词的连接条件的连接。不支持任意交叉或 theta 连接。
SELECT *
FROM Orders
INNER JOIN Product
ON Orders.product_id = Product.id;
- 1
- 2
- 3
- 4
4.10.1.2. OUTER等值连接
返回限定的笛卡尔积中的所有行(即,传递其连接条件的所有合并行),加上连接条件与另一个表的任何行不匹配的外表中每一行的一个副本。
Flink 支持左、右和全外连接。目前,只支持等值连接,即至少具有一个具有相等谓词的连接条件的连接。不支持任意交叉或 theta 连接。
SELECT *
FROM Orders
LEFT JOIN Product
ON Orders.product_id = Product.id;
--------------------------------------------------------------
SELECT *
FROM Orders
RIGHT JOIN Product
ON Orders.product_id = Product.id;
--------------------------------------------------------------
SELECT *
FROM Orders
FULL OUTER JOIN Product
ON Orders.product_id = Product.id;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4.10.2. Interval Join
返回受连接条件和时间约束限制的简单笛卡尔积。Interval Join 需要至少一个等连接谓词和一个连接条件来限制双方的时间。
两个适当的范围谓词就可以定义这样的条件,比如:<、<=、>=、>、BETWEEN 或单个相等谓词,都可以用于比较两个输入表的相同类型的时间属性(处理时间或事件时间)。
例如,如果在收到订单4小时后发货,则此查询将会把所有订单与其相应的发货关联起来。
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time;
- 1
- 2
- 3
- 4
以下谓词是有效的 Interval Join 条件的示例:
ltime = rtime
ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE
ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
- 1
- 2
- 3
流式连接查询与常规连接相比,Interval Join 只支持带有时间属性的仅追加表。由于时间属性是准单调递增的,Flink 可以在不影响结果正确性的情况下将旧值从其状态中移除。
4.10.3. Temporal Join
时态表是随着时间变化的表,在 flink 中也成为了动态表。时态表中的行在一个或多个时间周期内存在,所有 Flink 表都是时态的(动态的)。
时态表包含一个或多个版本表的快照,是一个可以追踪变更历史表(比如:数据库变更历史,包含所有的快照),或者是变化的维表(比如:包含最新快照的数据库表)。
4.10.3.1. Event Time Temporal Join
时态连接允许对版本表进行连接,这意味着可以通过更改元数据来丰富表信息,并在某个时间点检索它的值。
时态连接取任意表(左输入/探查侧),并将每一行与版本控制表(右输入/构建侧)中相应行的相关版本关联起来。Flink使用 FOR SYSTEM_TIME AS of 的SQL语法根据SQL:2011标准执行这个操作。时态连接的语法如下:
SELECT [column_list]
FROM table1 [AS <alias1>]
[LEFT] JOIN table2 FOR SYSTEM_TIME AS OF table1.{ proctime | rowtime } [AS <alias2>]
ON table1.column-name1 = table2.column-name1;
- 1
- 2
- 3
- 4
使用事件时间属性(即 rowtime 属性),可以检索键在过去某个时刻的值。这允许在一个共同的时间点来连接两张表。版本化表将存储自最后一个水印以来所有版本的数据(按时间标识)。
例如,假设我们有一个订单表,每个订单的价格以不同的货币表示。要将此表适当地规范化为单一货币(如美元),每个订单都需要与下单时的适当货币转换汇率连接起来。
-- 创建一个订单表,这是个标准的仅追加表。 CREATE TABLE orders ( order_id STRING, price DECIMAL(32,2), currency STRING, order_time TIMESTAMP(3), WATERMARK FOR order_time AS order_time ) WITH (/* ... */); -- 定义一个版本化表来存储货币转化率。这个表可以通过CDC定义,比如Debezium、压缩的kafka主题,或者是任何其他的方式定义版本化表。 CREATE TABLE currency_rates ( currency STRING, conversion_rate DECIMAL(32, 2), update_time TIMESTAMP(3) METADATA FROM `values.source.timestamp` VIRTUAL WATERMARK FOR update_time AS update_time ) WITH ( 'connector' = 'upsert-kafka', 'value.format' = 'debezium-json', /* ... */ ); SELECT order_id, price, currency, conversion_rate, order_time, FROM orders LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time ON orders.currency = currency_rates.currency; order_id price currency conversion_rate order_time ======== ===== ======== =============== ========= o_001 11.11 EUR 1.14 12:00:00 o_002 12.51 EUR 1.10 12:06:00
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
注意:事件时间时态连接是由左右两边的水印触发的,连接的两张表都必须正确地设置水印。
注意:事件时间时态连接需要有包含主键的等值连接条件,例如,product_changelog 表的主键 P.product_id 被约束在条件 orders.currency = currency_rates.currency 中。
与常规连接相比,尽管构建端(右表)发生了更改,但前面的时态表结果并不会受到影响。与Interval Join相比,时态表连接没有定义连接记录的时间窗口。
间隔连接包含时间窗口,时间窗口内的左右表数据都会进行连接。探测端(左表)记录总是在time属性指定的时间与构建端对应时间的数据进行连接。
因此,构建端的行可能是任意旧的。随着时间的推移,不再需要的记录版本(对于给定的主键)将从状态中删除。
4.10.3.2. Processing Time Temporal Join
处理时间时态表连接使用处理时间属性将行与外部版本表中键对应的最新版本数据进行关联。
根据定义,使用处理时间属性,连接将始终返回给定键的最新值。可以将查询表看作简单的 HashMap<K, V>
,它存储了来自构建端的所有记录。这种连接的强大之处是,当不能在 Flink 中将表具体化为动态表时,它允许 Flink 直接针对外部系统工作。
下面的处理时间时态表连接示例显示了一个只追加的表订单,它与 LatestRates 表连接。LatestRates 是一个维表(例如 HBase 表),存储最新的比例。
在 10:15,10:30,10:52,LatestRates 的内容如下:
10:15> SELECT * FROM LatestRates; currency rate ======== ====== US Dollar 102 Euro 114 Yen 1 10:30> SELECT * FROM LatestRates; currency rate ======== ====== US Dollar 102 Euro 114 Yen 1 10:52> SELECT * FROM LatestRates; currency rate ======== ====== US Dollar 102 Euro 116 <==== changed from 114 to 116 Yen 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
10:15 和 10:30 的 LatestRates 的内容是相等的。欧元汇率在 10:52 从 114 变到了 116。
订单是一个仅追加表,表示给定金额和给定货币的支付数据。例如,在 10:15 有一个 2 欧元的订单。
SELECT * FROM Orders;
amount currency
====== =========
2 Euro <== arrived at time 10:15
1 US Dollar <== arrived at time 10:30
2 Euro <== arrived at time 10:52
- 1
- 2
- 3
- 4
- 5
- 6
- 7
根据这些表,来将所有订单转换为相同的货币。
amount currency rate amount*rate
====== ========= ======= ============
2 Euro 114 228 <== arrived at time 10:15
1 US Dollar 102 102 <== arrived at time 10:30
2 Euro 116 232 <== arrived at time 10:52
- 1
- 2
- 3
- 4
- 5
在时态表连接的帮助下,我们可以在 SQL 中进行这样一个查询:
SELECT
o_amount, r_rate
FROM
Orders,
LATERAL TABLE (Rates(o_proctime))
WHERE
r_currency = o_currency
- 1
- 2
- 3
- 4
- 5
- 6
- 7
探测端(左表)中的每条记录都将与构建端表(右表)的当前版本记录进行连接。在上例中,使用了处理时间概念,因此在执行操作时,新添加的记录总是与最新版本的 LatestRates 表数据连接。
对于任何表/视图的最新版本的时态连接,不支持使用 FOR SYSTEM_TIME AS OF 语法的原因仅仅是语义上的考虑,因为左流的连接处理不等待时态表的完整快照,这可能会误导生产环境中的用户。由时态表函数实现的处理时间时态连接也存在同样的语义问题,但它已经存在很长时间了,因此我们从兼容性角度考虑支持它。
处理时间的结果是不确定的。处理时间时态连接最常使用外部表(即维度表)作为构建端(右表)。
与常规连接相比,尽管构建端(右表)发生了更改,前面的时态表结果也不会受到影响。与 interval joins 相比,时态表连接没有定义记录连接的时间窗口,也就是说,旧行不会进行状态存储。
4.10.3.3. Temporal Table Function Join
注意:当前只支持在时态表上使用 inner join 和 left outer join。
假设 Rates 是一个时态表函数,则可以下面的例子一样使用:
SELECT
o_amount, r_rate
FROM
Orders,
LATERAL TABLE (Rates(o_proctime))
WHERE
r_currency = o_currency
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Temporal Table DDL 和 Temporal Table Function 之间主要的区别为:
- temporal table DDL 可以在 SQL 中定义,但是 temporal table function 不可以。
- temporal table DDL 和 temporal table function 都支持关联版本表,但是只有 temporal table function 可以时态连接任何 表/视图 的最新版本数据。
4.10.4. Lookup Join
Lookup Join 通常使用从外部系统查询的数据来丰富表。连接要求一个表具有处理时间属性,另一个表由 lookup source 连接器支持。
查找连接使用上面的 Processing Time Temporal join 语法,并使用查找源连接器支持表。
下面的示例显示了指定 Lookup Join 的语法。
-- Customers通过JDBC连接器创建,并且可以被用于lookup joins CREATE TEMPORARY TABLE Customers ( id INT, name STRING, country STRING, zip STRING ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://mysqlhost:3306/customerdb', 'table-name' = 'customers' ); -- 通过customer来丰富订单信息 SELECT o.order_id, o.total, c.country, c.zip FROM Orders AS o JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c ON o.customer_id = c.id;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
在上面的示例中,Orders 表使用来自 MySQL 数据库中的 Customers 表的数据进行数据信息扩展。通过后面处理时间属性的 FOR SYSTEM_TIME AS OF 子句确保在连接操作处理 Orders 行时,
Orders 表的每一行都与那些匹配连接谓词的 Customers 行连接。它还防止在将来更新已连接的 Customer 行时更新连接结果。
Lookup Join 还需要一个强制相等联接谓词,如上面示例中的 o.customer_id = c.id。
4.10.5. Array展开
为给定数组中的每个元素返回新行。目前还不支持 WITH ORDINALITY。
SELECT order_id, t.tag
FROM Orders
CROSS JOIN UNNEST(tags) AS t (tag);
- 1
- 2
- 3
4.10.6. 表函数
将表与表函数的结果进行连接。左表(外部表)的每一行都与对应的table函数调用产生的所有行连接。用户自定义的表函数在使用前必须注册。
4.10.6.1. INNER JOIN
如果左表(外部)的表函数调用返回空结果,则删除该行。
SELECT order_id, res
FROM Orders, LATERAL TABLE(table_func(order_id)) t(res);
- 1
- 2
4.10.6.2. LEFT OUTER JOIN
如果表函数调用返回空结果,则保留相应的左表数据行,并在结果中填充空值。目前,针对表的左外连接需要在 ON 子句中使用 TRUE 字面值。
SELECT order_id, res
FROM Orders
LEFT OUTER JOIN LATERAL TABLE(table_func(order_id)) t(res)
ON TRUE;
- 1
- 2
- 3
- 4
4.11. window join
只能在流式处理中使用。
window join 会将时间尺度添加到他们的 join 标准中。如此一来, window join 就会将两个流中同一个窗口内拥有两个相同 key 的元素 join 起来。
window join 的语义和 DataStream window join 的语义相同。
对于 streaming 查询,和其他的流表 join 不同, window join 不会马上发射结果数据,而是在窗口结束之后发射最终的结果。此外,在不需要保存数据时, window join 会清除所有的中间状态数据。
通常来说,window join 会和窗口表值函数一起使用。因此,基于窗口表值函数,window join 后面可以接受其他函数操作,比如窗口聚合、窗口 TopN、window join。
目前,window join 要求 join 的输入表有相同的窗口开始和相同的窗口结束。
window join 支持 INNER、LEFT/RIGHT/FULL OUTER、ANTI、SEMI JOIN。
4.11.1. INNER/LEFT/RIGHT/FULL OUTER
下面的例子展示在 window join 语句中使用 INNER/LEFT/RIGHT/FULL OUTER 的语法。
SELECT ...
FROM L
[LEFT|RIGHT|FULL OUTER] JOIN R -- L 和 R 表可以是窗口表值函数产生的表
ON L.window_start = R.window_start AND L.window_end = R.window_end AND ...
- 1
- 2
- 3
- 4
INNER/LEFT/RIGHT/FULL OUTER WINDOW JOIN 的语法彼此是非常相似的,下面我们只给出了 FULL OUTER JOIN 的例子。
当使用 window join 时,在一个滚动窗口中,拥有相同 key 的所有元素将会 join 到一起。
下面的例子中,我们只在 window join 的滚动窗口上使用了一个滚动窗口表值函数。
通过将 join 的窗口限制在五分钟间隔,我们将会截断数据集为两个不同的窗口:[12:00, 12:05) 和 [12:05, 12:10)。L2 和 R2 行不会 join 到一起,因为他们处于不同的窗口中。
desc LeftTable; +----------+------------------------+------+-----+--------+----------------------------------+ | name | type | null | key | extras | watermark | +----------+------------------------+------+-----+--------+----------------------------------+ | row_time | TIMESTAMP(3) *ROWTIME* | true | | | `row_time` - INTERVAL '1' SECOND | | num | INT | true | | | | | id | STRING | true | | | | +----------+------------------------+------+-----+--------+----------------------------------+ SELECT * FROM LeftTable; +------------------+-----+----+ | row_time | num | id | +------------------+-----+----+ | 2020-04-15 12:02 | 1 | L1 | | 2020-04-15 12:06 | 2 | L2 | | 2020-04-15 12:03 | 3 | L3 | +------------------+-----+----+ desc RightTable; +----------+------------------------+------+-----+--------+----------------------------------+ | name | type | null | key | extras | watermark | +----------+------------------------+------+-----+--------+----------------------------------+ | row_time | TIMESTAMP(3) *ROWTIME* | true | | | `row_time` - INTERVAL '1' SECOND | | num | INT | true | | | | | id | STRING | true | | | | +----------+------------------------+------+-----+--------+----------------------------------+ SELECT * FROM RightTable; +------------------+-----+----+ | row_time | num | id | +------------------+-----+----+ | 2020-04-15 12:01 | 2 | R2 | | 2020-04-15 12:04 | 3 | R3 | | 2020-04-15 12:05 | 4 | R4 | +------------------+-----+----+ SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, L.window_start, L.window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L FULL JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end; +-------+------+-------+------+------------------+------------------+ | L_Num | L_Id | R_Num | R_Id | window_start | window_end | +-------+------+-------+------+------------------+------------------+ | 1 | L1 | null | null | 2020-04-15 12:00 | 2020-04-15 12:05 | | null | null | 2 | R2 | 2020-04-15 12:00 | 2020-04-15 12:05 | | 3 | L3 | 3 | R3 | 2020-04-15 12:00 | 2020-04-15 12:05 | | 2 | L2 | null | null | 2020-04-15 12:05 | 2020-04-15 12:10 | | null | null | 4 | R4 | 2020-04-15 12:05 | 2020-04-15 12:10 | +-------+------+-------+------+------------------+------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
注意:为了更好的理解窗口 join 的行为,我们简单展示了时间戳值,并没有展示后面的0。
比如,TIMESTAMP(3) 类型的数据,在 FLINK CLI 中,2020-04-15 08:05 应该被展示为 2020-04-15 08:05:00.000 。
4.11.2. SEMI
在同一个窗口中,如果左表和右表至少有一行匹配,则 semi window join 会返回左表的一行记录。
SELECT * FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L WHERE L.num IN ( SELECT num FROM ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R WHERE L.window_start = R.window_start AND L.window_end = R.window_end ); +------------------+-----+----+------------------+------------------+-------------------------+ | row_time | num | id | window_start | window_end | window_time | +------------------+-----+----+------------------+------------------+-------------------------+ | 2020-04-15 12:03 | 3 | L3 | 2020-04-15 12:00 | 2020-04-15 12:05 | 2020-04-15 12:04:59.999 | +------------------+-----+----+------------------+------------------+-------------------------+ SELECT * FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L WHERE EXISTS ( SELECT * FROM ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R WHERE L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end ); +------------------+-----+----+------------------+------------------+-------------------------+ | row_time | num | id | window_start | window_end | window_time | +------------------+-----+----+------------------+------------------+-------------------------+ | 2020-04-15 12:03 | 3 | L3 | 2020-04-15 12:00 | 2020-04-15 12:05 | 2020-04-15 12:04:59.999 | +------------------+-----+----+------------------+------------------+-------------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
注意:为了更好的理解窗口 join 的行为,我们简单展示了时间戳值,并没有展示后面的0。
比如,TIMESTAMP(3) 类型的数据,在 FLINK CLI 中,2020-04-15 08:05 应该被展示为 2020-04-15 08:05:00.000 。
4.11.3. ANTI
anti window join 会返回同一个窗口中所有没有 join 到一起的行。
SELECT * FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L WHERE L.num NOT IN ( SELECT num FROM ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R WHERE L.window_start = R.window_start AND L.window_end = R.window_end ); +------------------+-----+----+------------------+------------------+-------------------------+ | row_time | num | id | window_start | window_end | window_time | +------------------+-----+----+------------------+------------------+-------------------------+ | 2020-04-15 12:02 | 1 | L1 | 2020-04-15 12:00 | 2020-04-15 12:05 | 2020-04-15 12:04:59.999 | | 2020-04-15 12:06 | 2 | L2 | 2020-04-15 12:05 | 2020-04-15 12:10 | 2020-04-15 12:09:59.999 | +------------------+-----+----+------------------+------------------+-------------------------+ SELECT * FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L WHERE NOT EXISTS ( SELECT * FROM ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R WHERE L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end ); +------------------+-----+----+------------------+------------------+-------------------------+ | row_time | num | id | window_start | window_end | window_time | +------------------+-----+----+------------------+------------------+-------------------------+ | 2020-04-15 12:02 | 1 | L1 | 2020-04-15 12:00 | 2020-04-15 12:05 | 2020-04-15 12:04:59.999 | | 2020-04-15 12:06 | 2 | L2 | 2020-04-15 12:05 | 2020-04-15 12:10 | 2020-04-15 12:09:59.999 | +------------------+-----+----+------------------+------------------+-------------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
注意:为了更好的理解窗口 join 的行为,我们简单展示了时间戳值,并没有展示后面的0。
比如,TIMESTAMP(3) 类型的数据,在 FLINK CLI 中,2020-04-15 08:05 应该被展示为 2020-04-15 08:05:00.000 。
4.11.4. 限制
4.11.4.1. join条件的限制
目前,window join 要求两张表拥有相同的窗口开始和窗口结束。未来,我们简化 join on 条件,如果窗口表值函数为滚动或者滑动,则只需要两张表有相同的窗口开始即可。
4.11.4.2. 在输入表上使用窗口TVF的限制
目前,左表和右表必须有相同的窗口表值函数。将来我们会扩展该功能,比如,有用相同窗口大小的滚动窗口 join 滑动窗口。
4.11.4.3. 直接在窗口TVF后使用window join的限制
目前,如果在窗口表值函数之后使用 window join ,窗口函数只能是滚动窗口、滑动窗口或者是累计窗口,而不能是会话窗口。
4.12. 集合操作
在流批任务中均可使用。
4.12.1. UNION
UNION 和 UNION ALL 会返回两张表的所有行。UNION 会对结果去重,而 UNION ALL 不会对结果行去重。
Flink SQL> create view t1(s) as values ('c'), ('a'), ('b'), ('b'), ('c'); Flink SQL> create view t2(s) as values ('d'), ('e'), ('a'), ('b'), ('b'); Flink SQL> (SELECT s FROM t1) UNION (SELECT s FROM t2); +---+ | s| +---+ | c| | a| | b| | d| | e| +---+ Flink SQL> (SELECT s FROM t1) UNION ALL (SELECT s FROM t2); +---+ | s| +---+ | c| | a| | b| | b| | c| | d| | e| | a| | b| | b| +---+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.12.2. INTERSECT
交集
INTERSECT 和 INTERSECT ALL 返回在两个表中都存在的行。INTERSECT 会对结果行去重,而 INTERSECT ALL 不会去重。
Flink SQL> (SELECT s FROM t1) INTERSECT (SELECT s FROM t2);
+---+
| s|
+---+
| a|
| b|
+---+
Flink SQL> (SELECT s FROM t1) INTERSECT ALL (SELECT s FROM t2);
+---+
| s|
+---+
| a|
| b|
| b|
+---+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.12.3. EXCEPT
差集
EXCEPT 和 EXCEPT ALL 返回在一个表中找到,但在另一个表中没有找到的行。EXCEPT 会对结果去重,而 EXCEPT ALL 不会对结果去重。
Flink SQL> (SELECT s FROM t1) EXCEPT (SELECT s FROM t2);
+---+
| s |
+---+
| c |
+---+
Flink SQL> (SELECT s FROM t1) EXCEPT ALL (SELECT s FROM t2);
+---+
| s |
+---+
| c |
| c |
+---+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.12.4. IN
如果外表字段值存在于给定的子查询结果表数据,则返回 true。子查询结果表必须由一列组成。此列必须具有与表达式相同的数据类型。
SELECT user, amount
FROM Orders
WHERE product IN
(
SELECT product
FROM NewProducts
)
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
优化器将 IN 条件重写为 join 和 group 操作。对于流查询,计算查询结果所需的状态可能会无限增长,这取决于不同的输入行数。
可以通过配置合适的状态生存时间(TTL),以防止状态大小过大。注意,这可能会影响查询结果的正确性。详细信息请参见查询配置。
4.12.5. EXISTS
SELECT user, amount
FROM Orders
WHERE product EXISTS
(
SELECT product
FROM NewProducts
)
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果子查询返回至少一行,则返回 true。只有当操作可以在 join 和 group 操作中重写时才支持该语法。
优化器将 EXISTS 操作重写为 join 和 group 操作。对于流查询,计算查询结果所需的状态可能会无限增长,这取决于不同的输入行数。
可以通过配置合适的状态生存时间(TTL),以防止状态大小过大。注意,这可能会影响查询结果的正确性。详细信息请参见查询配置。
4.13. ORDER BY子句
在流批任务中均可使用。
ORDER BY 子句会根据指定的表达式对结果行进行排序。如果根据最左边的表达式比较,两行相等,则继续根据下一个表达式对它们进行比较,以此类推。如果根据所有指定的表达式比较,它们都是相等的,则以依赖于实现的顺序返回它们。
当以流模式运行时,表的主要排序顺序必须根据时间属性进行升序进行排序。所有后续排序都可以自由选择。但是在批处理模式中没有这种限制。
SELECT *
FROM Orders
ORDER BY order_time, order_id;
- 1
- 2
- 3
4.13.1. LIMIT子句
只能在批处理任务中使用。
LIMIT 子句限制 SELECT 语句返回的行数。LIMIT 通常与 ORDER BY 一起使用,以确保结果的确定性。
下面的示例返回 Orders 表中的前 3 行。
SELECT *
FROM Orders
ORDER BY orderTime
LIMIT 3;
- 1
- 2
- 3
- 4
4.14. Top-N
在流批任务中均可使用。
Top-N 查询返回按列排序的 N 个最小或最大值。最小和最大的值集都被认为是 Top-N 查询。top-N 查询在需要只显示批处理/流表中最下面的 N 条或最上面的 N 条记录的情况下非常有用。此结果集可用于进一步分析。
Flink 使用 OVER 窗口子句和筛选条件的组合来表示 Top-N 查询。通过 OVER 窗口 PARTITION BY 子句的功能, Flink 还支持多组 Top-N。
例如,每个类别中实时销售额最高的前五种产品。对于批处理表和流表上的 SQL ,都支持 Top-N 查询。
Top-N 语句的语法如下:
SELECT [column_list]
FROM
(
SELECT [column_list],
ROW_NUMBER() OVER (
[PARTITION BY col1[, col2...]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]
) AS rownum
FROM table_name
)
WHERE rownum <= N [AND conditions]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
参数说明:
- ROW_NUMBER():根据分区中的数据行顺序,从 1 开始为每一行分配一个唯一的连续编号。目前,我们只支持ROW_NUMBER 作为 over window 函数。将来,我们会支持 RANK() 和 DENSE_RANK() 。
PARTITION BY col1[, col2...]:分区列。每个分区都有一个 Top-N 结果。ORDER BY col1 [asc|desc][, col2 [asc|desc]...]:指定排序列。不同列的排序方式可能不同。- WHERE rownum <= N: Flink 需要 rownum <= N 来识别这个查询是 Top-N 查询。N 表示将保留 N 条最小或最大的记录。
- [AND conditions]:在 where 子句中可以随意添加其他条件,但其他条件只能使用 AND 关键字与 rownum <= N 组合。
注意:必须完全遵循上述模式,否则优化器将无法转换查询。
TopN 查询结果为“结果更新”。Flink SQL 将根据 order 键对输入数据流进行排序,因此如果前 N 条记录被更改,则更改后的记录将作为撤销/更新记录发送到下游。建议使用支持更新的存储作为 Top-N 查询的 sink。
此外,如果 top N 记录需要存储在外部存储中,结果表应该具有与 top-N 查询相同的唯一键。
Top-N 查询的唯一键是 partition 列和 rownum 列的组合。以下面的作业为例,假设 product_id 是 ShopSales 的唯一键,那么 Top-N 查询的唯一键是 [category, rownum] 和 [product_id]。
下面的示例展示如何在流表上使用 Top-N 指定 SQL 查询。这是一个获得“每个类别中实时销售额最高的前五种产品”的例子。
CREATE TABLE ShopSales (
product_id STRING,
category STRING,
product_name STRING,
sales BIGINT
) WITH (...);
SELECT product_id, category, product_name, sales, row_num
FROM
(
SELECT product_id, category, product_name, sales,
ROW_NUMBER() OVER (PARTITION BY category ORDER BY sales DESC) AS row_num
FROM ShopSales
)
WHERE row_num <= 5;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.14.1. 无等级字段输出优化
如前所述,rownum 字段将作为唯一键的一个字段写入结果表,这可能会导致大量记录被写入结果表。例如,当排名 9 的记录(比如 product-1001 )被更新并将其排名升级为 1 时,排名 1 ~9 的所有记录将作为更新消息输出到结果表。
如果结果表接收的数据过多,将成为 SQL 作业的瓶颈。优化方法是在 Top-N 查询的外部 SELECT 子句中省略 rownum 字段。这是合理的,因为前N个记录的数量通常不大,因此消费者可以自己快速地对结果记录进行排序。
在上面的示例中,如果没有 rownum 字段,只需要将更改后的记录(product-1001)发送到下游,这可以减少对结果表的大量 IO。
下面的例子展示了如何用这种方式优化上面的 Top-N:
CREATE TABLE ShopSales ( product_id STRING, category STRING, product_name STRING, sales BIGINT ) WITH (...); -- 输出时省略row_num字段 SELECT product_id, category, product_name, sales FROM ( SELECT product_id, category, product_name, sales, ROW_NUMBER() OVER (PARTITION BY category ORDER BY sales DESC) AS row_num FROM ShopSales ) WHERE row_num <= 5;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
注意在流模式下,为了将上述查询输出到外部存储并得到正确的结果,外部存储必须与 Top-N 查询具有相同的唯一键。在上面的查询示例中,如果 product_id 是查询的唯一键,那么外部表也应该将 product_id 作为唯一键。
4.15. Window Top-N
只能在流模式任务中使用。
Window Top-N 是一个特殊的 Top-N,它返回每个窗口以及其他分区键的 N 个最小或最大值。
对于流查询,与连续表上的常规 top-N 不同,窗口 top-N 不会发出中间结果,而只发出最终结果,即窗口末端的 top-N 所有记录。
此外,当不再需要时,窗口 Top-N 会清除所有中间状态。因此,如果用户不需要对每条记录更新结果,那么窗口 Top-N 查询会具有更好的性能。通常,窗口 top-N 与窗口聚合函数一起使用。
Window Top-N 可以用与常规 Top-N 相同的语法定义,此外,Window Top-N 要求 PARTITION BY 子句包含 window_start 和 window_end 列,通过 Windowing TVF 或窗口聚合产生。
否则,优化器将无法翻译对应的sql查询。
Window Top-N语句的语法如下所示:
SELECT [column_list]
FROM
(
SELECT [column_list],
ROW_NUMBER() OVER (
PARTITION BY window_start, window_end [, col_key1...]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]
) AS rownum
FROM table_name
) -- 通过windowing TVF产生表
WHERE rownum <= N [AND conditions]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.15.1. 案例
4.15.1.1. 在窗口聚合函数后使用窗口Top-N
下面的例子展示如何计算每 10 分钟滚动窗口中销售额最高的前 3 个供应商:
-- 表必须有时间属性,比如下表中的bidtime列 Flink SQL> desc Bid; +-------------+------------------------+------+-----+--------+---------------------------------+ | name | type | null | key | extras | watermark | +-------------+------------------------+------+-----+--------+---------------------------------+ | bidtime | TIMESTAMP(3) *ROWTIME* | true | | | `bidtime` - INTERVAL '1' SECOND | | price | DECIMAL(10, 2) | true | | | | | item | STRING | true | | | | | supplier_id | STRING | true | | | | +-------------+------------------------+------+-----+--------+---------------------------------+ Flink SQL> SELECT * FROM Bid; +------------------+-------+------+-------------+ | bidtime | price | item | supplier_id | +------------------+-------+------+-------------+ | 2020-04-15 08:05 | 4.00 | A | supplier1 | | 2020-04-15 08:06 | 4.00 | C | supplier2 | | 2020-04-15 08:07 | 2.00 | G | supplier1 | | 2020-04-15 08:08 | 2.00 | B | supplier3 | | 2020-04-15 08:09 | 5.00 | D | supplier4 | | 2020-04-15 08:11 | 2.00 | B | supplier3 | | 2020-04-15 08:13 | 1.00 | E | supplier1 | | 2020-04-15 08:15 | 3.00 | H | supplier2 | | 2020-04-15 08:17 | 6.00 | F | supplier5 | +------------------+-------+------+-------------+ Flink SQL> SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY price DESC) as rownum FROM ( SELECT window_start, window_end, supplier_id, SUM(price) as price, COUNT(*) as cnt FROM TABLE (TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES)) GROUP BY window_start, window_end, supplier_id ) ) WHERE rownum <= 3; +------------------+------------------+-------------+-------+-----+--------+ | window_start | window_end | supplier_id | price | cnt | rownum | +------------------+------------------+-------------+-------+-----+--------+ | 2020-04-15 08:00 | 2020-04-15 08:10 | supplier1 | 6.00 | 2 | 1 | | 2020-04-15 08:00 | 2020-04-15 08:10 | supplier4 | 5.00 | 1 | 2 | | 2020-04-15 08:00 | 2020-04-15 08:10 | supplier2 | 4.00 | 1 | 3 | | 2020-04-15 08:10 | 2020-04-15 08:20 | supplier5 | 6.00 | 1 | 1 | | 2020-04-15 08:10 | 2020-04-15 08:20 | supplier2 | 3.00 | 1 | 2 | | 2020-04-15 08:10 | 2020-04-15 08:20 | supplier3 | 2.00 | 1 | 3 | +------------------+------------------+-------------+-------+-----+--------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
注意:为了更好地理解窗口的行为,我们简化了时间戳值的显示,不显示秒小数点后的零。
例如,如果类型是 timestamp(3),在 Flink SQL Client 中,2020-04-15 08:05 应该显示为 2020-04-15 08:05:00.000。
4.15.1.2. 在窗口TVF后使用窗口Top-N
下面的例子展示如何在每个 10 分钟的滚动窗口内计算出最高价格的 3 个商品。
Flink SQL> SELECT * FROM ( SELECT bidtime, price, item, supplier_id, window_start, window_end, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY price DESC) as rownum FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES)) ) WHERE rownum <= 3; +------------------+-------+------+-------------+------------------+------------------+--------+ | bidtime | price | item | supplier_id | window_start | window_end | rownum | +------------------+-------+------+-------------+------------------+------------------+--------+ | 2020-04-15 08:05 | 4.00 | A | supplier1 | 2020-04-15 08:00 | 2020-04-15 08:10 | 2 | | 2020-04-15 08:06 | 4.00 | C | supplier2 | 2020-04-15 08:00 | 2020-04-15 08:10 | 3 | | 2020-04-15 08:09 | 5.00 | D | supplier4 | 2020-04-15 08:00 | 2020-04-15 08:10 | 1 | | 2020-04-15 08:11 | 2.00 | B | supplier3 | 2020-04-15 08:10 | 2020-04-15 08:20 | 3 | | 2020-04-15 08:15 | 3.00 | H | supplier2 | 2020-04-15 08:10 | 2020-04-15 08:20 | 2 | | 2020-04-15 08:17 | 6.00 | F | supplier5 | 2020-04-15 08:10 | 2020-04-15 08:20 | 1 | +------------------+-------+------+-------------+------------------+------------------+--------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
注意:为了更好地理解窗口的行为,我们简化了时间戳值的显示,不显示秒小数点后的零。
例如,如果类型是 timestamp(3),在 Flink SQL Client 中,2020-04-15 08:05 应该显示为 2020-04-15 08:05:00.000。
4.15.2. 限制
目前,Flink 只支持 Window Top-N 在滚动窗口、滑动窗口、渐进式窗口上使用 Windowing TVF 产生的表。在不久的将来,将支持 在会话窗口上使用 Windowing TVF 产生的表。
4.16. 去重
在流批模式中均可使用。
去重会删除在一组列上重复的行,只保留第一行或最后一行。在某些情况下,上游 ETL 作业并不是端到端精确一次的;当发生故障转移时,这可能会导致接收器中出现重复记录。
重复记录会影响下游分析作业(如 SUM、COUNT)的正确性,因此需要在进一步分析之前进行重复数据删除。
Flink 使用 ROW_NUMBER() 来删除重复数据,就像 Top-N 查询一样。理论上,重复数据删除是 Top-N 的一种特殊情况,其中N为 1,按处理时间或事件时间排序。
重复数据删除语句的语法如下:
SELECT [column_list]
FROM
(
SELECT [column_list],
ROW_NUMBER() OVER (
[PARTITION BY col1[, col2...]]
ORDER BY time_attr [asc|desc]
) AS rownum
FROM table_name
)
WHERE rownum = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
参数说明:
- ROW_NUMBER():为每一行分配一个唯一的连续编号,从1开始。
**PARTITION BY col1[, col2...]**:指定分区列,即重复数据删除键。**ORDER BY time_attr [asc|desc]**:排序列,必须是时间属性。目前Flink支持处理时间属性和事件时间属性。按 ASC 排序意味着保留第一行,按 DESC 排序意味着保留最后一行。- WHERE rownum = 1:Flink 需要 rownum = 1 来识别这个查询是重复数据删除。
注意:必须完全遵循上述模式,否则优化器将无法转换查询。
以下示例展示如何在流表上使用重复数据删除的SQL语句:
CREATE TABLE Orders ( order_time STRING, user STRING, product STRING, num BIGINT, proctime AS PROCTIME() ) WITH (...); -- 移除重复的order_id行数据,只保留第一个接收到的行数据,因为同一个order_id不应该出现两个订单 SELECT order_id, user, product, num FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY order_id ORDER BY proctime ASC) AS row_num FROM Orders ) WHERE row_num = 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.17. 模式识别
暂时不做翻译。
5. CREATE
5.1. 介绍
CREATE 语句用于将 表/视图/函数 注册到当前或指定的 Catalog 中。已注册的表/视图/函数可以在SQL查询中使用。
Flink SQL目前支持以下CREATE语句:
- CREATE TABLE
- CREATE CATALOG
- CREATE DATABASE
- CREATE VIEW
- CREATE FUNCTION
5.2. 运行一个CREATE语句
java/scala
CREATE 语句可以通过 TableEnvironment 对象的 executeSql() 方法执行,当 CREATE 操作成功时返回 OK,否则抛出异常。
下面的案例展示如何使用 TableEnvironment 运行一个 CREATE 语句。
java
EnvironmentSettings settings = EnvironmentSettings.newInstance()...
TableEnvironment tableEnv = TableEnvironment.create(settings);
// 运行创建表的 SQL,被注册的表叫:Orders
tableEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...)");
// 运行 SQL 查询表,并将结果检索为一张新表。
Table result = tableEnv.sqlQuery(
"SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
// 运行创建表的 SQL,注册一个 TableSink
tableEnv.executeSql("CREATE TABLE RubberOrders(product STRING, amount INT) WITH (...)");
// 运行一个 insert SQL 语句,并且将结果写入 TableSink
tableEnv.executeSql(
"INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
scala
val settings = EnvironmentSettings.newInstance()...
val tableEnv = TableEnvironment.create(settings)
// 运行创建表的 SQL,被注册的表叫:Orders
tableEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...)");
// 运行 SQL 查询表,并将结果检索为一张新表。
val result = tableEnv.sqlQuery(
"SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
// 运行创建表的 SQL,注册一个 TableSink
tableEnv.executeSql("CREATE TABLE RubberOrders(product STRING, amount INT) WITH ('connector.path'='/path/to/file' ...)");
// 运行一个 insert SQL 语句,并且将结果写入 TableSink
tableEnv.executeSql(
"INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
SQL CLI
可以在 SQL CLI 中执行 CREATE 语句。
下面的案例展示如何在 SQL CLI 中运行一个 CREATE 语句。
Flink SQL> CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...);
[INFO] Table has been created.
Flink SQL> CREATE TABLE RubberOrders (product STRING, amount INT) WITH (...);
[INFO] Table has been created.
Flink SQL> INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%';
[INFO] Submitting SQL update statement to the cluster...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.3. CREATE TABLE
语法概述:
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name ( { <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> }[ , ...n] [ <watermark_definition> ] [ <table_constraint> ][ , ...n] ) [COMMENT table_comment] [PARTITIONED BY (partition_column_name1, partition_column_name2, ...)] WITH (key1=val1, key2=val2, ...) [ LIKE source_table [( <like_options> )] ] <physical_column_definition>: column_name column_type [ <column_constraint> ] [COMMENT column_comment] <column_constraint>: [CONSTRAINT constraint_name] PRIMARY KEY NOT ENFORCED <table_constraint>: [CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED <metadata_column_definition>: column_name column_type METADATA [ FROM metadata_key ] [ VIRTUAL ] <computed_column_definition>: column_name AS computed_column_expression [COMMENT column_comment] <watermark_definition>: WATERMARK FOR rowtime_column_name AS watermark_strategy_expression <source_table>: [catalog_name.][db_name.]table_name <like_options>: { { INCLUDING | EXCLUDING } { ALL | CONSTRAINTS | PARTITIONS } | { INCLUDING | EXCLUDING | OVERWRITING } { GENERATED | OPTIONS | WATERMARKS } }[, ...]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
上面的语句创建了一个带有给定名称的表。如果catalog中已经存在同名的表,则会引发异常。
5.3.1. Columns(字段)
5.3.1.1. Physical / Regular Columns(物理/常规列)
物理列是数据库中已知的常规列。它们定义物理数据中字段的名称、类型和顺序。因此,物理列表示从外部系统读取和写入的有效负载。
连接器和格式转化使用这些列(按照定义的顺序)来配置自己。其他类型的列可以在物理列之间声明,但不会影响最终的物理模式。
下面的语句创建了一个只有常规列的表:
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING
) WITH (
...
);
- 1
- 2
- 3
- 4
- 5
- 6
5.3.1.2. Metadata Columns(元数据列)
元数据列是SQL标准的扩展,允许访问连接器和/或表中每一行的特定字段。元数据列由metadata关键字表示。例如,元数据列可以用来读取和写入Kafka记录的时间戳,以进行基于时间的操作。
连接器和格式文档列出了每个组件的可用元数据字段。在表的模式中声明元数据列是可选的。
下面的语句创建了一个表,其中包含引用元数据 timestamp 的附加元数据列:
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
`record_time` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' -- 读取和写入kafka记录的时间戳
) WITH (
'connector' = 'kafka'
...
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
每个元数据字段都由基于字符串的键标识,并具有文档化的数据类型。例如,Kafka 连接器暴露了一个元数据字段,该字段由键 timestamp 和数据类型 TIMESTAMP_LTZ(3) 标识,可以用于读写记录。
在上面的例子中,元数据列 record_time 成为表模式的一部分,可以像普通列一样进行转换和存储:
INSERT INTO MyTable SELECT user_id, name, record_time + INTERVAL '1' SECOND FROM MyTable;
- 1
为了方便起见,如果将列名直接用于标识元数据,则可以省略 FROM 子句:
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
`timestamp` TIMESTAMP_LTZ(3) METADATA -- 使用列名作为元数据键
) WITH (
'connector' = 'kafka'
...
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
为方便起见,如果列的数据类型与元数据字段的数据类型不同,可以显式指示强制类型转换,不过要求这两种数据类型是兼容的。
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
`timestamp` BIGINT METADATA -- 转化timestamp类型为BIGINT
) WITH (
'connector' = 'kafka'
...
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
默认情况下,planner 计划器会假定元数据列可以同时用于读写。然而在许多情况下,外部系统提供的元数据字段用于只读比可写更多。因此,可以使用 VIRTUAL 关键字将元数据列排除在持久化之外。
CREATE TABLE MyTable (
`timestamp` BIGINT METADATA, -- query-to-sink schema的一部分
`offset` BIGINT METADATA VIRTUAL, -- 不是query-to-sink schema的一部分
`user_id` BIGINT,
`name` STRING,
) WITH (
'connector' = 'kafka'
...
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在上面的示例中,偏移量是一个只读元数据列,并从 query-to-sink schema 中排除。因此,source-to-query 模式(用于 SELECT)和 query-to-sink (用于 INSERT INTO )模式不同:
source-to-query schema:
MyTable(`timestamp` BIGINT, `offset` BIGINT, `user_id` BIGINT, `name` STRING)
query-to-sink schema:
MyTable(`timestamp` BIGINT, `user_id` BIGINT, `name` STRING)
- 1
- 2
- 3
- 4
5.3.1.3. Computed Columns(计算列)
计算列是使用语法 column_name AS computed_column_expression 生成的虚拟列。
计算列可以引用同一表中声明的其他列的表达式,可以访问物理列和元数据列。列本身并不物理地存储在表中,列的数据类型通过给定的表达式自动派生,不需要手动声明。
计划器会将计算列转换为常规投影。对于优化或水印策略下推,计算列的实际计算可能会跨算子进行,并执行多次,或者在给定查询不需要的情况下跳过。例如,计算列可以定义为:
CREATE TABLE MyTable (
`user_id` BIGINT,
`price` DOUBLE,
`quantity` DOUBLE,
`cost` AS price * quanitity, -- 执行表达式并接收查询结果
) WITH (
'connector' = 'kafka'
...
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
表达式可以是列、常量或函数的任意组合。表达式不能包含子查询。
计算列通常在 Flink 中用于在 CREATE TABLE 语句中定义时间属性。
- 可以通过
proc AS PROCTIME()使用系统的PROCTIME()函数轻松定义处理时间属性。 - 事件时间属性 timestamp 可以在水印声明之前进行预处理。例如,如果原始字段不是 TIMESTAMP(3) 类型或嵌套在 JSON 字符串中,则可以使用计算列。
与虚拟元数据列类似,计算列被排除在持久化之外。因此,计算列不能是 INSERT INTO 语句的目标列。因此,source-to-query 模式(用于 SELECT)和 query-to-sink (用于 INSERT - INTO)模式不同:
source-to-query schema:
MyTable(`user_id` BIGINT, `price` DOUBLE, `quantity` DOUBLE, `cost` DOUBLE)
query-to-sink schema:
MyTable(`user_id` BIGINT, `price` DOUBLE, `quantity` DOUBLE)
- 1
- 2
- 3
- 4
5.3.2. WATERMARK
WATERMARK 子句用于定义表的事件时间属性,其形式为 WATERMARK FOR rowtime_column_name AS watermark_strategy_expression。
- rowtime_column_name 定义一个列,该列被标记为表的事件时间属性。该列必须为 TIMESTAMP(3) 类型,并且是模式中的顶级列。它可以是一个计算列。
- watermark_strategy_expression 定义了水印生成策略。它允许任意非查询表达式(包括计算列)来计算水印。表达式返回类型必须为 TIMESTAMP(3),表示从 Epoch 开始的时间戳。返回的水印只有在非空且其值大于先前发出的本地水印时才会发出(以保持升序水印的规定)。框架会对每条记录执行水印生成表达式。框架将周期性地发出生成的最大水印。 如果当前水印与前一个相同,或为空,或返回的水印值小于上次发出的水印值,则不会发出新的水印。水印通过
pipeline.auto-watermark-interval配置的时间间隔发出。如果水印间隔为 0ms,弱生成的水印不为空且大于上次发出的水印,则每条记录都发出一次水印。
当使用事件时间语义时,表必须包含事件时间属性和水印策略。
Flink提供了几种常用的水印策略:
- 严格递增时间戳:WATERMARK FOR rowtime_column AS rowtime_column
发出到目前为止观察到的最大时间戳的水印。时间戳大于最大时间戳的行不属于延迟。 - 升序时间戳:WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL ‘0.001’ SECOND
发出到目前为止观察到的最大时间戳减去1的水印。时间戳大于或等于最大时间戳的行不属于延迟。 - 时间戳:WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL ‘string’ timeUnit
发出到目前为止观察到的最大时间戳减去指定延迟的水印,例如:WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL '5' SECOND是一个延迟5秒的水印策略。
CREATE TABLE Orders (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH ( . . . );
- 1
- 2
- 3
- 4
- 5
- 6
5.3.3. PRIMARY KEY
主键约束是 Flink 用于优化的一个提示。它告诉 flink,指定的表或视图的一列或一组列是唯一的,它们不包含 null。主列中的任何一列都不能为空。主键唯一地标识表中的一行。
主键约束可以与列定义(列约束)一起声明,也可以作为单行声明(表约束)。只能使用这两种方式之一,如果同时定义多个主键约束,则会引发异常。
有效性检查
SQL 标准指定约束可以是强制的,也可以是不强制的。这将控制是否对传入/传出数据执行约束检查。Flink 不保存数据,因此我们希望支持的唯一模式是 not forced 模式。确保查询执行的主键唯一性由用户负责。
Flink 通过假定主键的列的可空性与主键中列的可空性一致,从而假定主键是正确的。连接器应该确保它们是一致的。
注意:在 CREATE TABLE 语句中,主键约束会改变列的可空性,也就是说,一个有主键约束的列是不能为 NULL 的。
5.3.4. PARTITIONED BY
根据指定的列对已创建的表进行分区。如果将该表用作 filesystem sink,则为每个分区创建一个目录。
5.3.5. WITH选项
用于创建表 source/sink 的表属性,属性通常用于查找和创建底层连接器。
表达式 key1=val1 的键和值都应该是字符串字面值。有关不同连接器的所有受支持的表属性,请参阅连接器中的详细信息。
表名可以是三种格式:
catalog_name.db_name.table_namedb_name.table_nametable_name
对于 catalog_name.db_name.Table_name,表将被注册到catalog名为 “catalog_name” ,数据库名为 “db_name”;对于 db_name.Table_name,表将注册到当前表执行环境的 catalog 和数据库名为“db_name”;对于 table_name,表将注册到表执行环境的当前 catalog 和数据库中。
注意:用 CREATE TABLE 语句注册的表既可以用作表 source,也可以用作表 sink,我们不能决定它是用作源还是用作接收器,直到它在 DML 语句中被引用。
5.3.6. LIKE
LIKE 子句是 SQL 特性的变体/组合。子句可用于基于现有表的定义创建表。此外,用户可以扩展原始表或排除其中的某些部分。与 SQL 标准相反,子句必须在 CREATE 语句的顶层定义。这是因为子句适用于定义的多个部分,而不仅仅适用于模式部分。
您可以使用该子句重用或覆盖某些连接器属性或向外部定义的表添加水印。例如,在 Apache Hive 中定义的表中添加水印。
下面为示例语句:
CREATE TABLE Orders ( `user` BIGINT, product STRING, order_time TIMESTAMP(3) ) WITH ( 'connector' = 'kafka', 'scan.startup.mode' = 'earliest-offset' ); CREATE TABLE Orders_with_watermark ( -- 增加水印定义 WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND ) WITH ( -- 覆盖startup-mode 'scan.startup.mode' = 'latest-offset' ) LIKE Orders;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
生成的表 Orders_with_watermark 等价于用以下语句创建的表:
CREATE TABLE Orders_with_watermark (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'scan.startup.mode' = 'latest-offset'
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
表特性的合并逻辑可以通过like选项进行控制。
可以控制合并的特性有:
- CONSTRAINTS:约束,比如主键和唯一键
- GENERATED:计算列
- METADATA:元数据列
- OPTIONS:描述连接器和格式属性的连接器选项
- PARTITIONS:表的分区
- WATERMARKS:水印声明
有三种不同的合并策略:
- INCLUDING:包含源表的特性,有重复的表项时失败,例如,如果两个表中都存在一个具有相同键的选项。
- EXCLUDING:不包含源表的给定特性。
- OVERWRITING:包含源表的特性,用新表的属性覆盖源表的重复项,例如,如果两个表中都存在一个具有相同键的选项,则使用当前语句中的选项。
此外,如果没有定义特定的策略,可以使用 INCLUDING/EXCLUDING ALL 选项来指定使用什么策略,例如,如果你使用 EXCLUDING ALL INCLUDING WATERMARKS,则表示只有源表中的水印会被包含。
例子:
-- 存储在filesystem中的source表 CREATE TABLE Orders_in_file ( `user` BIGINT, product STRING, order_time_string STRING, order_time AS to_timestamp(order_time) ) PARTITIONED BY (`user`) WITH ( 'connector' = 'filesystem', 'path' = '...' ); -- 想存储在kafka中的对应的表 CREATE TABLE Orders_in_kafka ( -- 增加水印定义 WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND ) WITH ( 'connector' = 'kafka', ... ) LIKE Orders_in_file ( -- 不包含任何东西,除了需要的水印计算列。 -- 我们不需要分区和文件系统选项这些kafka不接受的特性。 EXCLUDING ALL INCLUDING GENERATED );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
如果没有提供like选项,INCLUDING ALL OVERWRITING OPTIONS 将作为默认选项使用。
注意:无法控制物理列归并行为。这些物理列将被合并,就像使用了 INCLUDING 策略一样。
注意:source_table 可以是复合标识符。因此,它可以是来自不同 catalog 或数据库的表,例如:
my_catalog.my_db.MyTable,指定来自 MyCatalog 和数据库 my_db 的表 MyTable;my_db.MyTable指定来自当前 catalog 和数据库 my_db 的表 MyTable。
5.4. CREATE CATALOG
CREATE CATALOG catalog_name WITH (
key1=val1, key2=val2, ...
)
- 1
- 2
- 3
通过给定的 catalog 属性来创建一个 catalog。如果提供的 catalog 名称已经存在,则会抛出异常。
WITH参数
用于指定与此目录相关的额外信息的目录属性。表达式 key1=val1 的键和值都应该是字符串字面值。
通过 Catalogs 查看更多细节内容。
5.5. CREATE DATABASE
CREATE DATABASE [IF NOT EXISTS] [catalog_name.]db_name
[COMMENT database_comment]
WITH (key1=val1, key2=val2, ...)
- 1
- 2
- 3
使用给定的数据库属性创建数据库。如果目录中已经存在同名的数据库,则会引发异常。
IF NOT EXISTS
如果数据库已经存在,则不会发生任何事情。
WITH OPTIONS
用于指定与此数据库相关的额外信息的数据库属性。表达式 key1=val1 的键和值都应该是字符串字面值。
5.6. CREATE VIEW
CREATE [TEMPORARY] VIEW [IF NOT EXISTS] [catalog_name.][db_name.]view_name
[( columnName [, columnName ]* )] [COMMENT view_comment]
AS query_expression
- 1
- 2
- 3
使用给定的查询表达式创建视图。如果 catalog 中已经存在同名的视图,则会抛出异常。
TEMPORARY
创建具有目录和数据库名称空间并覆盖视图的临时视图。
IF NOT EXISTS
如果视图已经存在,则不会发生任何事情。
5.7. CREATE FUNCTION
CREATE [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF NOT EXISTS] [catalog_name.][db_name.]function_name AS identifier [LANGUAGE JAVA|SCALA|PYTHON]
- 1
创建一个函数,该函数具有带有标识符和可选语言标记的 catalog 和数据库名称空间。如果目录中已经存在同名的函数,则会引发异常。
如果语言标记是 JAVA/SCALA,则标识符是 UDF 的完整类路径。关于 Java/Scala UDF 的实现,请参考用户自定义函数。
如果语言标记是 PYTHON,则标识符是 UDF 的完全限定名,例如 pyflink.table.tests.test_udf.add。
有关 Python UDF 的实现,请参阅官网,这里暂不列出。
TEMPORARY
创建具有 catalog 和数据库名称空间并覆盖编目函数的临时编目函数。
TEMPORARY SYSTEM
创建没有命名空间并覆盖内置函数的临时系统函数。
IF NOT EXISTS
如果函数已经存在,则什么也不会发生。
LANGUAGE JAVA|SCALA|PYTHON
用于指导 Flink 运行时如何执行该函数的语言标记。目前只支持 JAVA、SCALA 和 PYTHON,函数默认语言为 JAVA。
5.7.1. 案例代码
create temporary function fetch_millisecond as 'cn.com.log.function.udf.time.FetchMillisecond' language java;
- 1
6. DROP
6.1. 介绍
DROP 语句用于从当前或指定的 Catalog 中删除已注册的表/视图/函数。 Flink SQL 目前支持以下 DROP 语句:
- DROP CATALOG
- DROP TABLE
- DROP DATABASE
- DROP VIEW
- DROP FUNCTION
6.2. 运行DROP语句
java/scala
可以通过 TableEnvironment 对象的 executeSql() 方法来执行 DROP 语句。 executeSql() 方法会在 DROP 操作执行成功之后返回 OK ,否则抛出异常。
下面的案例演示如何使用 TableEnvironment 来运行 DROP 语句。
java
EnvironmentSettings settings = EnvironmentSettings.newInstance()... TableEnvironment tableEnv = TableEnvironment.create(settings); // 注册一个叫 "Orders" 的表 tableEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...)"); // 返回字符串数组:["Orders"] String[] tables = tableEnv.listTables(); // or tableEnv.executeSql("SHOW TABLES").print(); // 从 catalog 中删除 "Orders" 表 tableEnv.executeSql("DROP TABLE Orders"); // 返回空字符串数组 String[] tables = tableEnv.listTables(); // or tableEnv.executeSql("SHOW TABLES").print();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
scala
val settings = EnvironmentSettings.newInstance()... val tableEnv = TableEnvironment.create(settings) // 注册一个叫 "Orders" 的表 tableEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...)") // 返回字符串数组:["Orders"] val tables = tableEnv.listTables() // or tableEnv.executeSql("SHOW TABLES").print() // 从 catalog 中删除 "Orders" 表 tableEnv.executeSql("DROP TABLE Orders") // 返回空字符串数组 val tables = tableEnv.listTables() // or tableEnv.executeSql("SHOW TABLES").print()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
SQL CLI
Flink SQL> CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...);
[INFO] Table has been created.
Flink SQL> SHOW TABLES;
Orders
Flink SQL> DROP TABLE Orders;
[INFO] Table has been removed.
Flink SQL> SHOW TABLES;
[INFO] Result was empty.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6.3. DROP CATALOG
DROP CATALOG [IF EXISTS] catalog_name
- 1
删除指定的 catalog。
IF EXISTS
如果该 catalog 不存在,则什么也不会发生。
6.4. DROP TABLE
DROP [TEMPORARY] TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
- 1
删除指定表名的表。如果要删除的表不存在,则抛出异常。
TEMPORARY
删除具有目录和数据库名称空间的临时表。
IF EXISTS
如果该表不存在,则什么也不会发生。
6.5. DROP DATABASE
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
- 1
删除给定数据库名称的数据库。如果要删除的数据库不存在,则抛出异常。
IF EXISTS
如果数据库不存在,则什么也不会发生。
RESTRICT
删除非空数据库将触发异常。默认启用。
CASCADE
删除非空数据库时也会删除所有相关的表和函数。
6.6. DROP VIEW
DROP [TEMPORARY] VIEW [IF EXISTS] [catalog_name.][db_name.]view_name
- 1
删除具有目录和数据库名称空间的视图。如果要删除的视图不存在,则抛出异常。
TEMPORARY
删除具有目录和数据库名称空间的临时视图。
IF EXISTS
如果视图不存在,则什么也不会发生。
保持依赖: Flink 不通过 CASCADE/RESTRICT 关键字维护视图的依赖关系,当前的方式是当用户试图在视图的底层表被删除的情况下使用视图时抛出延迟错误消息。
6.7. DROP FUNCTION
DROP [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF EXISTS] [catalog_name.][db_name.]function_name
- 1
删除具有目录和数据库名称空间的目录函数。如果要删除的函数不存在,则抛出异常。
TEMPORARY
删除具有目录和数据库名称空间的临时目录函数。
TEMPORARY SYSTEM
删除没有命名空间的临时系统函数。
IF EXISTS
如果函数不存在,什么也不会发生。
7. ALTER
7.1. 介绍
ALTER语句用于修改 Catalog 中已注册的表/视图/函数定义。
Flink SQL 目前支持以下 ALTER 语句:
- ALTER TABLE
- ALTER VIEW
- ALTER DATABASE
- ALTER FUNCTION
7.2. 运行ALter语句
java/scala
可以通过 TableEnvironment 对象的 executeSql() 方法来执行 ALTER 语句。 executeSql() 方法会在 ALTER 操作执行成功之后返回 OK ,否则抛出异常。
下面的案例演示如何使用 TableEnvironment 来运行 ALTER 语句。
java
EnvironmentSettings settings = EnvironmentSettings.newInstance()... TableEnvironment tableEnv = TableEnvironment.create(settings); // 注册一个叫 "Orders" 的表 tableEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...)"); // 返回字符串数组:["Orders"] String[] tables = tableEnv.listTables(); // or tableEnv.executeSql("SHOW TABLES").print(); // 修改表名 "Orders" 为 "NewOrders" tableEnv.executeSql("ALTER TABLE Orders RENAME TO NewOrders;"); // 返回字符串数组:["NewOrders"] String[] tables = tableEnv.listTables(); // or tableEnv.executeSql("SHOW TABLES").print();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
scala
val settings = EnvironmentSettings.newInstance()... val tableEnv = TableEnvironment.create(settings) // 注册一个叫 "Orders" 的表 tableEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...)"); // 返回字符串数组:["Orders"] val tables = tableEnv.listTables() // or tableEnv.executeSql("SHOW TABLES").print() // 修改表名 "Orders" 为 "NewOrders" tableEnv.executeSql("ALTER TABLE Orders RENAME TO NewOrders;") // 返回字符串数组:["NewOrders"] val tables = tableEnv.listTables() // or tableEnv.executeSql("SHOW TABLES").print()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
SQL CLI
Flink SQL> CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...);
[INFO] Table has been created.
Flink SQL> SHOW TABLES;
Orders
Flink SQL> ALTER TABLE Orders RENAME TO NewOrders;
[INFO] Table has been removed.
Flink SQL> SHOW TABLES;
NewOrders
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
7.3. ALTER TABLE
重命名表
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
- 1
将给定的表名重命名为另一个新表名。
设置或更改表属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
- 1
给指定的表设置一个或多个属性。如果表中已经设置了特定的属性,则用新值覆盖旧值。
7.4. ALTER VIEW
ALTER VIEW [catalog_name.][db_name.]view_name RENAME TO new_view_name
- 1
将之前 catalog 和 database 下的视图重名为新的名称。
ALTER VIEW [catalog_name.][db_name.]view_name AS new_query_expression
- 1
改变视图之前的查询定义为新的查询。
7.5. ALTER DATABASE
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)
- 1
给指定的数据库设置一个或多个属性。如果数据库中已经设置了特定的属性,则使用新值覆盖旧值。
7.6. ALTER FUNCTION
ALTER [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF EXISTS] [catalog_name.][db_name.]function_name AS identifier [LANGUAGE JAVA|SCALA|PYTHON]
- 1
使用新的标识符和可选的语言标记更改 catalog 函数。如果函数在 catalog 中不存在,则抛出异常。如果语言标记是 JAVA/SCALA,则标识符是 UDF 的完整类路径。关于 Java/Scala UDF 的实现,请参考用户自定义函数。
TEMPORARY
更改具有 catalog 和数据库名称空间的临时 catalog 函数,并重写 catalog 函数。
TEMPORARY SYSTEM
更改没有名称空间的临时系统函数并覆盖内置函数。
IF EXISTS
如果函数不存在,什么也不会发生。
LANGUAGE JAVA|SCALA|PYTHON
用于指示 flink 运行时如何执行该函数的语言标记。目前只支持 JAVA、SCALA 和 PYTHON,函数默认语言为 JAVA。
8. INSERT
8.1. 介绍
NSERT 语句用于向表中添加行数据。
8.2. 运行INSERT语句
java/scala
可以通过 TableEnvironment 对象的 executeSql() 方法来执行单个 INSERT 语句。 executeSql() 方法在执行 INSERT 语句时,会立即提交一个 Flink 任务,并返回一个和提交的任务相关联的 TableResult 实例。多个 INSERT 语句可以通过 TableEnvironment.createStatementSet() 方法创建的 StatementSet 对象的 addInsertSql() 方法来执行,addInsertSql() 方法是懒执方法,将会在调用了 StatementSet.execute() 方法后执行。
下面的案例演示如何使用 TableEnvironment 来运行 单个 INSERT 语句,以及使用 StatementSet 运行多个 INSERT 语句。
java
EnvironmentSettings settings = EnvironmentSettings.newInstance()... TableEnvironment tEnv = TableEnvironment.create(settings); // 注册一个名叫 "Orders" 的 source 表和一个名叫 "RubberOrders" 的 sink 表。 tEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product VARCHAR, amount INT) WITH (...)"); tEnv.executeSql("CREATE TABLE RubberOrders(product VARCHAR, amount INT) WITH (...)"); // 运行一个从注册的 source 表中查询数据然后将结果写入到注册的 sink 表的单个 INSERT 语句 TableResult tableResult1 = tEnv.executeSql( "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'"); // 通过 TableResult 对象获取任务状态 System.out.println(tableResult1.getJobClient().get().getJobStatus()); //---------------------------------------------------------------------------- // 注册一个名叫 "GlassOrders" 的 sink 表,用于运行多个 INSERT 语句 tEnv.executeSql("CREATE TABLE GlassOrders(product VARCHAR, amount INT) WITH (...)"); // 运行多个从一个 source 表读取数据然后将结果写入到多个 sink 表的 INSERT 语句 StatementSet stmtSet = tEnv.createStatementSet(); // `addInsertSql` 方法每次只能添加单个 INSERT 语句 stmtSet.addInsertSql( "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'"); stmtSet.addInsertSql( "INSERT INTO GlassOrders SELECT product, amount FROM Orders WHERE product LIKE '%Glass%'"); // 一起执行所有的语句 TableResult tableResult2 = stmtSet.execute(); // 通过 TableResult 对象获取任务状态 System.out.println(tableResult2.getJobClient().get().getJobStatus());
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
scala
val settings = EnvironmentSettings.newInstance()... val tEnv = TableEnvironment.create(settings) // 注册一个名叫 "Orders" 的 source 表和一个名叫 "RubberOrders" 的 sink 表。 tEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...)") tEnv.executeSql("CREATE TABLE RubberOrders(product STRING, amount INT) WITH (...)") // 运行一个从注册的 source 表中查询数据然后将结果写入到注册的 sink 表的单个 INSERT 语句 val tableResult1 = tEnv.executeSql( "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'") // 通过 TableResult 对象获取任务状态 println(tableResult1.getJobClient().get().getJobStatus()) //---------------------------------------------------------------------------- // 注册一个名叫 "GlassOrders" 的 sink 表,用于运行多个 INSERT 语句 tEnv.executeSql("CREATE TABLE GlassOrders(product VARCHAR, amount INT) WITH (...)") // 运行多个从一个 source 表读取数据然后将结果写入到多个 sink 表的 INSERT 语句 val stmtSet = tEnv.createStatementSet() // `addInsertSql` 方法每次只能添加单个 INSERT 语句 stmtSet.addInsertSql( "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'") stmtSet.addInsertSql( "INSERT INTO GlassOrders SELECT product, amount FROM Orders WHERE product LIKE '%Glass%'") // 一起执行所有的语句 val tableResult2 = stmtSet.execute() // 通过 TableResult 对象获取任务状态 println(tableResult2.getJobClient().get().getJobStatus())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
SQL CLI
Flink SQL> CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...);
[INFO] Table has been created.
Flink SQL> CREATE TABLE RubberOrders(product STRING, amount INT) WITH (...);
Flink SQL> SHOW TABLES;
Orders
RubberOrders
Flink SQL> INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%';
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
8.3. 通过select查询Insert数据
select 查询结果可以通过使用 insert 子句插入到表中。
8.3.1. 语法
INSERT { INTO | OVERWRITE } [catalog_name.][db_name.]table_name [PARTITION part_spec] [column_list] select_statement
part_spec:
(part_col_name1=val1 [, part_col_name2=val2, ...])
column_list:
(col_name1 [, column_name2, ...])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
OVERWRITE
INSERT OVERWRITE 将覆盖表或分区中的任何现有数据。否则(INTO),将追加新的数据。
PARTITION
PARTITION 子句指定插入语句的静态分区列。
COLUMN LIST
现在有表 T(a INT, b INT, c INT), flink 支持
INSERT INTO T(c, b) SELECT x, y FROM S
- 1
查询的数据列‘x’将被写入列‘c’,查询的数据列‘y’将被写入列‘b’,并且列‘a’被设置为 NULL(需保证列‘z’是可以为空的)。
overwrite 和 partition 关键字经常用于写入 hive 。
8.3.2. 案例
-- 创建一个分区表 CREATE TABLE country_page_view (user STRING, cnt INT, date STRING, country STRING) PARTITIONED BY (date, country) WITH (...) -- 向静态分区(date='2019-8-30', country='China')追加数据行 INSERT INTO country_page_view PARTITION (date='2019-8-30', country='China') SELECT user, cnt FROM page_view_source; -- 向分区(date, country)追加数据行,静态data分区值为“2019-8-30”,country为动态分区,该分区值通过每行对应字段值动态获取 INSERT INTO country_page_view PARTITION (date='2019-8-30') SELECT user, cnt, country FROM page_view_source; -- 向静态分区(date='2019-8-30', country='China')覆盖数据 INSERT OVERWRITE country_page_view PARTITION (date='2019-8-30', country='China') SELECT user, cnt FROM page_view_source; -- 向分区(date, country)覆盖数据行,静态data分区值为“2019-8-30”,country为动态分区,该分区值通过每行对应字段值动态获取 INSERT OVERWRITE country_page_view PARTITION (date='2019-8-30') SELECT user, cnt, country FROM page_view_source; -- 向静态分区(date='2019-8-30', country='China')追加数据行,cnt字段值被设置为NULL INSERT INTO country_page_view PARTITION (date='2019-8-30', country='China') (user) SELECT user FROM page_view_source;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
8.4. Insert values into tables
可以使用 INSERT…VALUES 语句将数据直接从 SQL 插入到表中。
8.4.1. 语法
INSERT { INTO | OVERWRITE } [catalog_name.][db_name.]table_name VALUES values_row [, values_row ...]
values_row:
: (val1 [, val2, ...])
- 1
- 2
- 3
- 4
OVERWRITE
INSERT OVERWRITE 将覆盖表中任何现有数据。否则,将追加新的数据。
8.4.2. 案例
CREATE TABLE students (name STRING, age INT, gpa DECIMAL(3, 2)) WITH (...);
INSERT INTO students
VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
- 1
- 2
- 3
- 4
8.5. 运行多个insert
运行多个 insert 任务,在 flink UI 界面中,会体现出多个运行图。当然,如果你的多个 insert 语句读取了同一张表,或者是写入了同一张表,flink 则会对其优化,最后生成一张运行图。
9. DESCRIBE
9.1. 介绍
DESCRIBE 语句用于描述表或视图的 schema。
9.2. 运行ALter语句
java/scala
可以通过 TableEnvironment 对象的 executeSql() 方法来执行 DESCRIBE 语句。 executeSql() 方法会在 DESCRIBE 操作执行成功之后返回 指定表的 schema ,否则抛出异常。
下面的案例演示如何使用 TableEnvironment 来运行 DESCRIBE 语句。
java
EnvironmentSettings settings = EnvironmentSettings.newInstance()... TableEnvironment tableEnv = TableEnvironment.create(settings); // 注册一个叫 "Orders" 的表 tableEnv.executeSql( "CREATE TABLE Orders (" + " `user` BIGINT NOT NULl," + " product VARCHAR(32)," + " amount INT," + " ts TIMESTAMP(3)," + " ptime AS PROCTIME()," + " PRIMARY KEY(`user`) NOT ENFORCED," + " WATERMARK FOR ts AS ts - INTERVAL '1' SECONDS" + ") with (...)"); // 打印 schema tableEnv.executeSql("DESCRIBE Orders").print(); // 打印 schema tableEnv.executeSql("DESC Orders").print(); +---------+----------------------------------+-------+-----------+-----------------+----------------------------+ | name | type | null | key | computed column | watermark | +---------+----------------------------------+-------+-----------+-----------------+----------------------------+ | user | BIGINT | false | PRI(user) | | | | product | VARCHAR(32) | true | | | | | amount | INT | true | | | | | ts | TIMESTAMP(3) *ROWTIME* | true | | | `ts` - INTERVAL '1' SECOND | | ptime | TIMESTAMP(3) NOT NULL *PROCTIME* | false | | PROCTIME() | | +---------+----------------------------------+-------+-----------+-----------------+----------------------------+ 5 rows in set
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
scala
val settings = EnvironmentSettings.newInstance()... val tableEnv = TableEnvironment.create(settings) // 注册一个叫 "Orders" 的表 tableEnv.executeSql( "CREATE TABLE Orders (" + " `user` BIGINT NOT NULl," + " product VARCHAR(32)," + " amount INT," + " ts TIMESTAMP(3)," + " ptime AS PROCTIME()," + " PRIMARY KEY(`user`) NOT ENFORCED," + " WATERMARK FOR ts AS ts - INTERVAL '1' SECONDS" + ") with (...)") // 打印 schema tableEnv.executeSql("DESCRIBE Orders").print() // 打印 schema tableEnv.executeSql("DESC Orders").print() +---------+----------------------------------+-------+-----------+-----------------+----------------------------+ | name | type | null | key | computed column | watermark | +---------+----------------------------------+-------+-----------+-----------------+----------------------------+ | user | BIGINT | false | PRI(user) | | | | product | VARCHAR(32) | true | | | | | amount | INT | true | | | | | ts | TIMESTAMP(3) *ROWTIME* | true | | | `ts` - INTERVAL '1' SECOND | | ptime | TIMESTAMP(3) NOT NULL *PROCTIME* | false | | PROCTIME() | | +---------+----------------------------------+-------+-----------+-----------------+----------------------------+ 5 rows in set
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
SQL CLI
Flink SQL> CREATE TABLE Orders ( > `user` BIGINT NOT NULl, > product VARCHAR(32), > amount INT, > ts TIMESTAMP(3), > ptime AS PROCTIME(), > PRIMARY KEY(`user`) NOT ENFORCED, > WATERMARK FOR ts AS ts - INTERVAL '1' SECONDS > ) with ( > ... > ); [INFO] Table has been created. Flink SQL> DESCRIBE Orders; Flink SQL> DESC Orders; root |-- user: BIGINT NOT NULL |-- product: VARCHAR(32) |-- amount: INT |-- ts: TIMESTAMP(3) *ROWTIME* |-- ptime: TIMESTAMP(3) NOT NULL *PROCTIME* AS PROCTIME() |-- WATERMARK FOR ts AS `ts` - INTERVAL '1' SECOND |-- CONSTRAINT PK_3599338 PRIMARY KEY (user)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
9.3. 语法
{ DESCRIBE | DESC } [catalog_name.][db_name.]table_name
- 1
10. EXPLAIN
10.1. 介绍
EXPLAIN 语句用于解释 SELECT 或 INSERT 语句的逻辑和优化的查询计划。
10.2. 运行EXPLAIN语句
java/scala
可以通过 TableEnvironment 对象的 executeSql() 方法来执行 EXPLAIN 语句。 executeSql() 方法会在 EXPLAIN 操作执行成功之后返回 explain 结果 ,否则抛出异常。
下面的案例演示如何使用 TableEnvironment 来运行 EXPLAIN 语句。
java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env); // 注册一个叫 "Orders" 的表 tEnv.executeSql("CREATE TABLE MyTable1 (`count` bigint, word VARCHAR(256) WITH (...)"); tEnv.executeSql("CREATE TABLE MyTable2 (`count` bigint, word VARCHAR(256) WITH (...)"); // 通过 TableEnvironment.explainSql() 执行 explain SELECT 语句 String explanation = tEnv.explainSql( "SELECT `count`, word FROM MyTable1 WHERE word LIKE 'F%' " + "UNION ALL " + "SELECT `count`, word FROM MyTable2"); System.out.println(explanation); // 通过 TableEnvironment.executeSql() 执行 explain SELECT 语句 TableResult tableResult = tEnv.executeSql( "EXPLAIN PLAN FOR " + "SELECT `count`, word FROM MyTable1 WHERE word LIKE 'F%' " + "UNION ALL " + "SELECT `count`, word FROM MyTable2"); tableResult.print(); TableResult tableResult2 = tEnv.executeSql( "EXPLAIN ESTIMATED_COST, CHANGELOG_MODE, JSON_EXECUTION_PLAN " + "SELECT `count`, word FROM MyTable1 WHERE word LIKE 'F%' " + "UNION ALL " + "SELECT `count`, word FROM MyTable2"); tableResult2.print();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
scala
val env = StreamExecutionEnvironment.getExecutionEnvironment() val tEnv = StreamTableEnvironment.create(env) // 注册一个叫 "Orders" 的表 tEnv.executeSql("CREATE TABLE MyTable1 (`count` bigint, word VARCHAR(256) WITH (...)") tEnv.executeSql("CREATE TABLE MyTable2 (`count` bigint, word VARCHAR(256) WITH (...)") // 通过 TableEnvironment.explainSql() 执行 explain SELECT 语句 val explanation = tEnv.explainSql( "SELECT `count`, word FROM MyTable1 WHERE word LIKE 'F%' " + "UNION ALL " + "SELECT `count`, word FROM MyTable2") println(explanation) // 通过 TableEnvironment.executeSql() 执行 explain SELECT 语句 val tableResult = tEnv.executeSql( "EXPLAIN PLAN FOR " + "SELECT `count`, word FROM MyTable1 WHERE word LIKE 'F%' " + "UNION ALL " + "SELECT `count`, word FROM MyTable2") tableResult.print() val tableResult2 = tEnv.executeSql( "EXPLAIN ESTIMATED_COST, CHANGELOG_MODE, JSON_EXECUTION_PLAN " + "SELECT `count`, word FROM MyTable1 WHERE word LIKE 'F%' " + "UNION ALL " + "SELECT `count`, word FROM MyTable2") tableResult2.print()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
SQL CLI
Flink SQL> CREATE TABLE MyTable1 (`count` bigint, word VARCHAR(256)) WITH ('connector' = 'datagen');
[INFO] Table has been created.
Flink SQL> CREATE TABLE MyTable2 (`count` bigint, word VARCHAR(256)) WITH ('connector' = 'datagen');
[INFO] Table has been created.
Flink SQL> EXPLAIN PLAN FOR SELECT `count`, word FROM MyTable1 WHERE word LIKE 'F%'
> UNION ALL
> SELECT `count`, word FROM MyTable2;
Flink SQL> EXPLAIN ESTIMATED_COST, CHANGELOG_MODE, JSON_EXECUTION_PLAN SELECT `count`, word FROM MyTable1
> WHERE word LIKE 'F%'
> UNION ALL
> SELECT `count`, word FROM MyTable2;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
EXPLAIN 结果:
EXPLAIN PLAN
== Abstract Syntax Tree == LogicalUnion(all=[true]) :- LogicalProject(count=[$0], word=[$1]) : +- LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')]) : +- LogicalTableScan(table=[[default_catalog, default_database, MyTable1]]) +- LogicalProject(count=[$0], word=[$1]) +- LogicalTableScan(table=[[default_catalog, default_database, MyTable2]]) == Optimized Physical Plan == Union(all=[true], union=[count, word]) :- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')]) : +- TableSourceScan(table=[[default_catalog, default_database, MyTable1]], fields=[count, word]) +- TableSourceScan(table=[[default_catalog, default_database, MyTable2]], fields=[count, word]) == Optimized Execution Plan == Union(all=[true], union=[count, word]) :- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')]) : +- TableSourceScan(table=[[default_catalog, default_database, MyTable1]], fields=[count, word]) +- TableSourceScan(table=[[default_catalog, default_database, MyTable2]], fields=[count, word])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
EXPLAIN PLAN WITH DETAILS
== Abstract Syntax Tree == LogicalUnion(all=[true]) :- LogicalProject(count=[$0], word=[$1]) : +- LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')]) : +- LogicalTableScan(table=[[default_catalog, default_database, MyTable1]]) +- LogicalProject(count=[$0], word=[$1]) +- LogicalTableScan(table=[[default_catalog, default_database, MyTable2]]) == Optimized Physical Plan == Union(all=[true], union=[count, word], changelogMode=[I]): rowcount = 1.05E8, cumulative cost = {3.1E8 rows, 3.05E8 cpu, 4.0E9 io, 0.0 network, 0.0 memory} :- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')], changelogMode=[I]): rowcount = 5000000.0, cumulative cost = {1.05E8 rows, 1.0E8 cpu, 2.0E9 io, 0.0 network, 0.0 memory} : +- TableSourceScan(table=[[default_catalog, default_database, MyTable1]], fields=[count, word], changelogMode=[I]): rowcount = 1.0E8, cumulative cost = {1.0E8 rows, 1.0E8 cpu, 2.0E9 io, 0.0 network, 0.0 memory} +- TableSourceScan(table=[[default_catalog, default_database, MyTable2]], fields=[count, word], changelogMode=[I]): rowcount = 1.0E8, cumulative cost = {1.0E8 rows, 1.0E8 cpu, 2.0E9 io, 0.0 network, 0.0 memory} == Optimized Execution Plan == Union(all=[true], union=[count, word]) :- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')]) : +- TableSourceScan(table=[[default_catalog, default_database, MyTable1]], fields=[count, word]) +- TableSourceScan(table=[[default_catalog, default_database, MyTable2]], fields=[count, word]) == Physical Execution Plan == { "nodes" : [ { "id" : 37, "type" : "Source: TableSourceScan(table=[[default_catalog, default_database, MyTable1]], fields=[count, word])", "pact" : "Data Source", "contents" : "Source: TableSourceScan(table=[[default_catalog, default_database, MyTable1]], fields=[count, word])", "parallelism" : 1 }, { "id" : 38, "type" : "Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])", "pact" : "Operator", "contents" : "Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])", "parallelism" : 1, "predecessors" : [ { "id" : 37, "ship_strategy" : "FORWARD", "side" : "second" } ] }, { "id" : 39, "type" : "Source: TableSourceScan(table=[[default_catalog, default_database, MyTable2]], fields=[count, word])", "pact" : "Data Source", "contents" : "Source: TableSourceScan(table=[[default_catalog, default_database, MyTable2]], fields=[count, word])", "parallelism" : 1 } ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
10.3. Explain细节
打印语句包含指定 explain 细节的 plan 信息。
- ESTIMATED_COST:估计成本,生成优化器估计的物理节点的成本信息,
比如:TableSourceScan(…, cumulative cost ={1.0E8 rows, 1.0E8 cpu, 2.4E9 io, 0.0 network, 0.0 memory})。 - CHANGELOG_MODE:为每个物理节点生成变更日志模式,比如:GroupAggregate(…, changelogMode=[I,UA,D])。
- JSON_EXECUTION_PLAN:生成json格式的程序执行计划。
10.4. 语法
EXPLAIN [([ExplainDetail[, ExplainDetail]*]) | PLAN FOR] <query_statement_or_insert_statement>
- 1
11. USE
11.1. 介绍
USE 语句用于设置当前数据库或 catalog,或更改模块的解析顺序和启用状态。
11.2. 运行USE语句
java/scala
可以通过 TableEnvironment 对象的 executeSql() 方法来执行 USE 语句。 executeSql() 方法会在 USE 操作执行成功之后返回 OK ,否则抛出异常。
下面的案例演示如何使用 TableEnvironment 来运行 USE 语句。
java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env); // 创建 catalog tEnv.executeSql("CREATE CATALOG cat1 WITH (...)"); tEnv.executeSql("SHOW CATALOGS").print(); // +-----------------+ // | catalog name | // +-----------------+ // | default_catalog | // | cat1 | // +-----------------+ // 修改默认的 catalog tEnv.executeSql("USE CATALOG cat1"); tEnv.executeSql("SHOW DATABASES").print(); // 数据库为空 // +---------------+ // | database name | // +---------------+ // +---------------+ // 创建 database tEnv.executeSql("CREATE DATABASE db1 WITH (...)"); tEnv.executeSql("SHOW DATABASES").print(); // +---------------+ // | database name | // +---------------+ // | db1 | // +---------------+ // 修改默认数据库 tEnv.executeSql("USE db1"); // 修改模块解析顺序并启用模块 tEnv.executeSql("USE MODULES hive"); tEnv.executeSql("SHOW FULL MODULES").print(); // +-------------+-------+ // | module name | used | // +-------------+-------+ // | hive | true | // | core | false | // +-------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
scala
val env = StreamExecutionEnvironment.getExecutionEnvironment() val tEnv = StreamTableEnvironment.create(env) // 创建 catalog tEnv.executeSql("CREATE CATALOG cat1 WITH (...)") tEnv.executeSql("SHOW CATALOGS").print() // +-----------------+ // | catalog name | // +-----------------+ // | default_catalog | // | cat1 | // +-----------------+ // 修改默认的 catalog tEnv.executeSql("USE CATALOG cat1") tEnv.executeSql("SHOW DATABASES").print() // 数据库为空 // +---------------+ // | database name | // +---------------+ // +---------------+ // 创建 database tEnv.executeSql("CREATE DATABASE db1 WITH (...)") tEnv.executeSql("SHOW DATABASES").print() // +---------------+ // | database name | // +---------------+ // | db1 | // +---------------+ // 修改默认数据库 tEnv.executeSql("USE db1") // 修改模块解析顺序并启用模块 tEnv.executeSql("USE MODULES hive") tEnv.executeSql("SHOW FULL MODULES").print() // +-------------+-------+ // | module name | used | // +-------------+-------+ // | hive | true | // | core | false | // +-------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
SQL CLI
Flink SQL> CREATE CATALOG cat1 WITH (...); [INFO] Catalog has been created. Flink SQL> SHOW CATALOGS; default_catalog cat1 Flink SQL> USE CATALOG cat1; Flink SQL> SHOW DATABASES; Flink SQL> CREATE DATABASE db1 WITH (...); [INFO] Database has been created. Flink SQL> SHOW DATABASES; db1 Flink SQL> USE db1; Flink SQL> USE MODULES hive; [INFO] Use modules succeeded! Flink SQL> SHOW FULL MODULES; +-------------+-------+ | module name | used | +-------------+-------+ | hive | true | | core | false | +-------------+-------+ 2 rows in set
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
11.3. USE CATALOG
USE CATALOG catalog_name
- 1
设置当前 catalog。所有未显式指定 catalog 的后续命令都将使用此 catalog。 如果提供的 catalog 不存在,则抛出异常。默认当前 catalog 为 default_catalog。
11.4. USE MODULES
USE MODULES module_name1[, module_name2, ...]
- 1
按照声明的顺序设置已启用的模块。所有后续命令将解析启用模块中的元数据(函数/用户定义类型/规则等),并遵循声明顺序。
模块在加载时被默认使用。如果没有使用 USE modules 语句,加载的模块将被禁用。默认加载和启用的模块是 core。如果使用了该语句启动模块,则不在该语句中的模块都将被禁用。
11.4.1. 案例
use MODULES hive, core;
- 1
表示后续使用到的函数/用户定义类型/规则等,会先按照 hive 来解析,如果 hive 解析不了的,再用 flink 来解析。
11.5. USE
USE [catalog_name.]database_name
- 1
设置当前数据库。所有未显式指定数据库的后续命令都将使用此数据库。如果提供的数据库不存在,则抛出异常。默认的当前数据库是 default_database。
12. SHOW
12.1. 介绍
SHOW 语句用于列出所有 catalog,或在当前 catalog,列出所有数据库中所有表/视图/字段,或列出当前 catalog 和当前数据库,或显示当前 catalog 和数据库,
或列出当前catalog和当前的数据库的所有函数包括系统函数和用户自定义的函数。或只列出当前 catalog 和当前数据库中用户自定义的函数,或列出启用的模块名,或列出当前会话中为启用状态的所有已加载模块。
SHOW CREATE 语句被用于打印 DDL 语句,目前, SHOW CREATE 语句值能用于打印给定表或试图的 DDL 语句。 Flink SQL目前支持以下SHOW语句:
- SHOW CATALOGS
- SHOW CURRENT CATALOG
- SHOW DATABASES
- SHOW CURRENT DATABASE
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW VIEWS
- SHOW FUNCTIONS
- SHOW MODULES
- SHOW JARS
12.2. 运行SHOW语句
java/scala
可以通过 TableEnvironment 对象的 executeSql() 方法来执行 ALTER 语句。 executeSql() 方法会在 SHOW 操作执行成功之后返回对象 ,否则抛出异常。
下面的案例演示如何使用 TableEnvironment 来运行 SHOW 语句。
java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env); // show catalogs tEnv.executeSql("SHOW CATALOGS").print(); // +-----------------+ // | catalog name | // +-----------------+ // | default_catalog | // +-----------------+ // show current catalog tEnv.executeSql("SHOW CURRENT CATALOG").print(); // +----------------------+ // | current catalog name | // +----------------------+ // | default_catalog | // +----------------------+ // show databases tEnv.executeSql("SHOW DATABASES").print(); // +------------------+ // | database name | // +------------------+ // | default_database | // +------------------+ // show current database tEnv.executeSql("SHOW CURRENT DATABASE").print(); // +-----------------------+ // | current database name | // +-----------------------+ // | default_database | // +-----------------------+ // create a table tEnv.executeSql("CREATE TABLE my_table (...) WITH (...)"); // show tables tEnv.executeSql("SHOW TABLES").print(); // +------------+ // | table name | // +------------+ // | my_table | // +------------+ // show create table tEnv.executeSql("SHOW CREATE TABLE my_table").print(); // CREATE TABLE `default_catalog`.`default_db`.`my_table` ( // ... // ) WITH ( // ... // ) // create a view tEnv.executeSql("CREATE VIEW my_view AS ..."); // show views tEnv.executeSql("SHOW VIEWS").print(); // +-----------+ // | view name | // +-----------+ // | my_view | // +-----------+ // show functions tEnv.executeSql("SHOW FUNCTIONS").print(); // +---------------+ // | function name | // +---------------+ // | mod | // | sha256 | // | ... | // +---------------+ // create a user defined function tEnv.executeSql("CREATE FUNCTION f1 AS ..."); // show user defined functions tEnv.executeSql("SHOW USER FUNCTIONS").print(); // +---------------+ // | function name | // +---------------+ // | f1 | // | ... | // +---------------+ // show modules tEnv.executeSql("SHOW MODULES").print(); // +-------------+ // | module name | // +-------------+ // | core | // +-------------+ // show full modules tEnv.executeSql("SHOW FULL MODULES").print(); // +-------------+-------+ // | module name | used | // +-------------+-------+ // | core | true | // | hive | false | // +-------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
scala
val env = StreamExecutionEnvironment.getExecutionEnvironment() val tEnv = StreamTableEnvironment.create(env) // show catalogs tEnv.executeSql("SHOW CATALOGS").print() // +-----------------+ // | catalog name | // +-----------------+ // | default_catalog | // +-----------------+ // show databases tEnv.executeSql("SHOW DATABASES").print() // +------------------+ // | database name | // +------------------+ // | default_database | // +------------------+ // create a table tEnv.executeSql("CREATE TABLE my_table (...) WITH (...)") // show tables tEnv.executeSql("SHOW TABLES").print() // +------------+ // | table name | // +------------+ // | my_table | // +------------+ // show create table tEnv.executeSql("SHOW CREATE TABLE my_table").print() // CREATE TABLE `default_catalog`.`default_db`.`my_table` ( // ... // ) WITH ( // ... // ) // create a view tEnv.executeSql("CREATE VIEW my_view AS ...") // show views tEnv.executeSql("SHOW VIEWS").print() // +-----------+ // | view name | // +-----------+ // | my_view | // +-----------+ // show functions tEnv.executeSql("SHOW FUNCTIONS").print() // +---------------+ // | function name | // +---------------+ // | mod | // | sha256 | // | ... | // +---------------+ // create a user defined function tEnv.executeSql("CREATE FUNCTION f1 AS ...") // show user defined functions tEnv.executeSql("SHOW USER FUNCTIONS").print() // +---------------+ // | function name | // +---------------+ // | f1 | // | ... | // +---------------+ // show modules tEnv.executeSql("SHOW MODULES").print() // +-------------+ // | module name | // +-------------+ // | core | // +-------------+ // show full modules tEnv.executeSql("SHOW FULL MODULES").print() // +-------------+-------+ // | module name | used | // +-------------+-------+ // | core | true | // | hive | false | // +-------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
SQL CLI
Flink SQL> SHOW CATALOGS; default_catalog Flink SQL> SHOW DATABASES; default_database Flink SQL> CREATE TABLE my_table (...) WITH (...); [INFO] Table has been created. Flink SQL> SHOW TABLES; my_table Flink SQL> SHOW CREATE TABLE my_table; CREATE TABLE `default_catalog`.`default_db`.`my_table` ( ... ) WITH ( ... ) Flink SQL> CREATE VIEW my_view AS ...; [INFO] View has been created. Flink SQL> SHOW VIEWS; my_view Flink SQL> SHOW FUNCTIONS; mod sha256 ... Flink SQL> CREATE FUNCTION f1 AS ...; [INFO] Function has been created. Flink SQL> SHOW USER FUNCTIONS; f1 ... Flink SQL> SHOW MODULES; +-------------+ | module name | +-------------+ | core | +-------------+ 1 row in set Flink SQL> SHOW FULL MODULES; +-------------+------+ | module name | used | +-------------+------+ | core | true | +-------------+------+ 1 row in set Flink SQL> SHOW JARS; /path/to/addedJar.jar
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
12.3. SHOW CATALOGS
SHOW CATALOGS
- 1
显示所有 catalog。
12.4. SHOW CURRENT CATALOG
SHOW CURRENT CATALOG
- 1
展示当前 catalog。
12.5. SHOW DATABASES
SHOW DATABASES
- 1
展示当前 catalog 里的所有数据库。
12.6. SHOW CURRENT DATABASE
SHOW CURRENT DATABASE
- 1
展示当前数据库。
12.7. SHOW TABLES
SHOW TABLES
- 1
展示当前 catalog 和当前数据库中的所有表。
12.8. SHOW CREATE TABLE
SHOW CREATE TABLE
- 1
展示指定表的建表语句。
另外:当前的 SHOW CREATE TABLE 语句只支持展示通过 flink SQL DDL 创建的表。
12.9. SHOW VIEWS
SHOW VIEWS
- 1
展示当前 catalog 和当前数据库中的所有视图。
12.10. SHOW FUNCTIONS
SHOW [USER] FUNCTIONS
- 1
展示当前 catalog 和当前数据库中的所有系统和自定义函数。
USER
值展示当前 catalog 和当前数据库中的所有自定义函数。
12.11. SHOW MODULES
SHOW [FULL] MODULES
- 1
按解析顺序显示所有启用的模块名称。
FULL
按照顺序显示所有启用状态的已加载模块。
12.12. SHOW JARS
SHOW JARS
- 1
展示所有通过 ADD JAR 语句在当前会话类加载中增加的 jar 包。
另外:当前 SHOW JARS 语句只支持在 SQL CLI 中使用。
13. LOAD
13.1. 介绍
LOAD 语句用于加载内置或用户自定义的模块。
13.2. 运行LOAD语句
java/scala
可以通过 TableEnvironment 对象的 executeSql() 方法来执行 LOAD 语句。 executeSql() 方法会在 ALTER 操作执行成功之后返回 OK ,否则抛出异常。
下面的案例演示如何使用 TableEnvironment 来运行 LOAD 语句。
java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// load a hive module
tEnv.executeSql("LOAD MODULE hive WITH ('hive-version' = '3.1.2')");
tEnv.executeSql("SHOW MODULES").print();
// +-------------+
// | module name |
// +-------------+
// | core |
// | hive |
// +-------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
scala
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val tEnv = StreamTableEnvironment.create(env)
// load a hive module
tEnv.executeSql("LOAD MODULE hive WITH ('hive-version' = '3.1.2')")
tEnv.executeSql("SHOW MODULES").print()
// +-------------+
// | module name |
// +-------------+
// | core |
// | hive |
// +-------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
SQL CLI
Flink SQL> LOAD MODULE hive WITH ('hive-version' = '3.1.2');
[INFO] Load module succeeded!
Flink SQL> SHOW MODULES;
+-------------+
| module name |
+-------------+
| core |
| hive |
+-------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
13.3. LOAD模块
语法结构:
LOAD MODULE module_name [WITH ('key1' = 'val1', 'key2' = 'val2', ...)]
- 1
module_name 是一个简单的标识符,区分大小写。它应该与模块工厂中定义的模块类型相同,其用于模块的发现。
properties ('key1' = 'val1', 'key2' = 'val2',…) 是一个映射,包含一组键值对,传递给发现服务相对应的模块。
13.4. 案例代码
-- 加载 hive 模块
load module hive with ('hive-version' = '2.3.6');
-- 推荐下面这种写法,不指定 hive 的版本,由系统去自动提取。
load module hive;
- 1
- 2
- 3
- 4
给平台添加了 flink-connector-sql-hive 依赖之后,就相当于已经添加了 hive 模块的实现,因此可以直接去加载 hive 模块。
在 flink sql 中加载了 hive 模块,并且 use 了 hive 模块之后,查询语句中就可以直接去使用 hive 中的函数了。
14. UNLOAD
14.1. 介绍
UNLOAD 语句用于卸载内置或用户自定义的模块。
14.2. 运行UNLOAD语句
java/scala
可以通过 TableEnvironment 对象的 executeSql() 方法来执行 UNLOAD 语句。 executeSql() 方法会在 ALTER 操作执行成功之后返回 OK ,否则抛出异常。
下面的案例演示如何使用 TableEnvironment 来运行 UNLOAD 语句。
java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// unload a core module
tEnv.executeSql("UNLOAD MODULE core");
tEnv.executeSql("SHOW MODULES").print();
// Empty set
- 1
- 2
- 3
- 4
- 5
- 6
- 7
scala
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val tEnv = StreamTableEnvironment.create(env)
// unload a core module
tEnv.executeSql("UNLOAD MODULE core")
tEnv.executeSql("SHOW MODULES").print()
// Empty set
- 1
- 2
- 3
- 4
- 5
- 6
- 7
SQL CLI
Flink SQL> UNLOAD MODULE core;
[INFO] Unload module succeeded!
Flink SQL> SHOW MODULES;
Empty set
- 1
- 2
- 3
- 4
- 5
14.3. UNLOAD模块
语法结构:
UNLOAD MODULE module_name
- 1
15. SET
15.1. 介绍
SET 语句用于修改配置或列出配置。
15.2. 运行SET语句
SQL CLI
Flink SQL> SET 'table.local-time-zone' = 'Europe/Berlin';
[INFO] Session property has been set.
Flink SQL> SET;
'table.local-time-zone' = 'Europe/Berlin'
- 1
- 2
- 3
- 4
- 5
15.3. 语法
SET ('key' = 'value')
- 1
如果没有指定键和值,则只打印所有属性。否则,使用指定的键值对设置属性值。
15.4. 案例
Flink SQL> SET 'table.local-time-zone' = 'Europe/Berlin';
[INFO] Session property has been set.
Flink SQL> SET;
'table.local-time-zone' = 'Europe/Berlin'
- 1
- 2
- 3
- 4
- 5
16. RESET
16.1. 介绍
RESET 语句用于将配置重置为默认值。
16.2. 运行RESET语句
Flink SQL> RESET table.planner;
[INFO] Session property has been reset.
Flink SQL> RESET;
[INFO] All session properties have been set to their default values.
- 1
- 2
- 3
- 4
- 5
16.3. 语法
RESET ('key')
- 1
如果没有指定键,则将所有属性重置为默认值。否则,将指定的键重置为默认值。
16.4. 案例
Flink SQL> RESET 'table.planner';
[INFO] Session property has been reset.
Flink SQL> RESET;
[INFO] All session properties have been set to their default values.
- 1
- 2
- 3
- 4
- 5
17. JAR
JAR 语法用于将用户的 jar 增加到 classpath 或从 classpath 中移除用户的 jar 或在运行时展示增加到 classpath 中的 jar 包。
flink SQL 现在支持下面这些 JAR 语法:
- ADD JAR
- REMOVE JAR
- SHOW JARS
另外:JAR 语法现在只支持在 SQL CLI 中使用。
17.1. 运行JAR语句
SQL CLI
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] The specified jar is added into session classloader.
Flink SQL> SHOW JARS;
/path/hello.jar
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
17.2. ADD JAR
ADD JAR '<path_to_filename>.jar'
- 1
目前只支持将本地的 jar 添加到会话的类加载器。
17.3. REMOVE JAR
REMOVE JAR '<path_to_filename>.jar'
- 1
目前子支持移除通过 ADD JAR 语句增加的 jar 包。
17.4. SHOW JARS
SHOW JARS
- 1
展示所有通过 ADD JAR 语句增加到会话类加载器中的 jar 包。

