
- 1面向终客户和设备制造商的Ethernet-APL
- 2android sdk $(^name)已停止工作,Windows 7上的Android Studio安装失败,未找到JDK
- 3COLING'22 | 不同数据,不同模态!用于社交媒体多模态信息抽取的有效数据分割策略...
- 4nltk.download(‘averaged_perceptron_tagger‘)报错
- 5Pytorch学习率衰减基本方法_pytorch中如何使得学习率逐渐下降
- 6Springboot开心学习(第九天)_pr18九天狐狸
- 7Kibana操作ES 全覆盖 基础查询 DSL查询_kibana查询es数据
- 8Elasticsearch的配置文件与参数设置
- 9信用评分卡建模:决策树模型_使用树模型做评分卡
- 10微服务设计原则——高可用
【大数据开发运维解决方案】Ogg For Bigdata 同步Oracle数据到KAFKA(包括初始化历史数据)
赞
踩
OGG同步Oracle数据到KAFKA:OGG初始化进程初始化历史数据
在前面曾写过几篇关于OGG同步Oracle等库数据到kafka的文章:
OGG实时同步Oracle数据到Kafka实施文档(供flink流式计算)
OGG For Bigdata 12按操作类型同步Oracle数据到kafka不同topic
但是那都是做测试,没有说实际工作情况下如何将Oracle等库表的历史数据初始化到kafka的方案,我这里用过两个方案,第一个比较笨的方案那就是写shell脚本将数据从Oracle导出成json格式的数据然后再写到kafka,另一种就是现在要介绍的通过OGG本身的初始化进程来做历史数据初始化,本篇文章环境完全根据前面文章搭建的环境来做的。
先再来看下当前环境的大致配置情况:
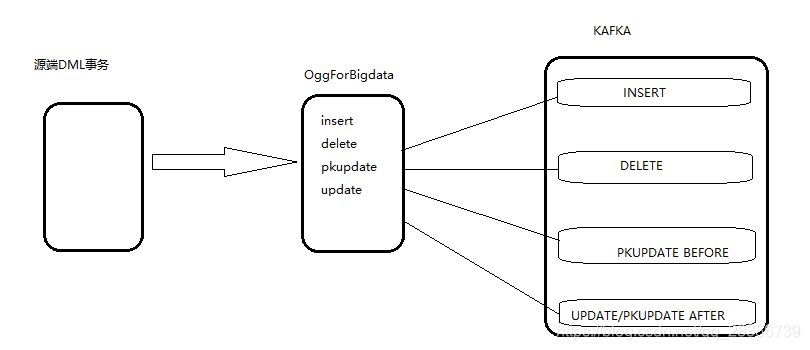
由于本文做的一系列Ogg forBigdata投递j’son消息到kafka操作是为了提供flink消费做实时计算用,为了极大的降低flink代码解析json的成本,提高消费速度,本人文章对insert,delete,update/pkupdate的映射大致逻辑是这样映射的:
1、对于insert操作,由于ogg for bigdata生成的json消息是下面这种情况:

{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:25:01.379000","pos":"00000000000000002199","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":1232,"ENAME":" FORD","JOB":"ANALYST","MGR":7566,"HIREDATE":"1981-12-03 00:00:00","SAL":3000.00,"COMM":null,"DEPTNO":20}}
- 1
也就是有效数据存储在after的部分,这里不做变化;
2、对于delete 操作,由于ogg for bigdata生成的json消息是下面这种情况:
{"table":"SCOTT.SCEMP","op_type":"D","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:25:01.379000","pos":"00000000000000002199","tokens":{"TKN-OP-TYPE":"DELETE"},"BEFORE":{"EMPNO":1232,"ENAME":" FORD","JOB":"ANALYST","MGR":7566,"HIREDATE":"1981-12-03 00:00:00","SAL":3000.00,"COMM":null,"DEPTNO":20}}
- 1
也就是有效数据存储在before的部分,由于insert,delete,update我这里不再像前面文章映射到不同topic,这里都映射到一个topic中,这里flink解析就有问题了,因为json结构不同,insert的有效数据在after而delete的在before,这里为了flink解析json方便,将delete的操作对应的json的有效数据也放到after中,怎么实现?就是将delete转成insert,转置后的结果json如下:
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:25:01.379000","pos":"00000000000000002199","tokens":{"TKN-OP-TYPE":"DELETE"},"after":{"EMPNO":1232,"ENAME":" FORD","JOB":"ANALYST","MGR":7566,"HIREDATE":"1981-12-03 00:00:00","SAL":3000.00,"COMM":null,"DEPTNO":20}}
- 1
但是转置完后,标识操作类型的op_type也变成了I,那后面flink计算时候怎么知道这条记录实际做的是delete?,这就是为什么我上篇文章在源端抽取进程加了TKN-OP-TYPE属性来标识这条记录做的是什么操作,这样就算replicat做了转置,op_type会变,但是TKN-OP-TYPE是从源端带来的属性值,这个不会变。
3、对于普通update操作,由于ogg for bigdata生成的json消息是下面这种情况:
{"table":"SCOTT.SCEMP","op_type":"U","op_ts":"2019-09-16 16:23:50.607615","current_ts":"2019-09-16T16:24:01.925000","pos":"00000000230000015887","tokens":{"TKN-OP-TYPE":"SQL COMPUPDATE"},"before":{"EMPNO":8888},"aft
er":{"EMPNO":6666,"ENAME":"zyand"}}
- 1
- 2
这里的json只会带有加了附加日志的主键及被修改的字段值, 我们首先需要做的是,把update after的数据单独拿出来做一个json:
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 16:36:58.607186","current_ts":"2019-09-16T16:37:06.891000","pos":"00000000230000016276","tokens":{"TKN-OP-TYPE":"SQL COMPUPDATE"},"after":{"EMPNO":6666,"ENAME":"zyand"}}
- 1
为什么不取before的数据,因为before的数据对我们没用,不需要取这些数据,其次,由于flink要计算的字段涉及empno,ename,job,sal,deptno这些字段,就算只是改了ename字段,其他字段没有变化,我们也要将这些没有变动的字段及其现在的值拿出来写到kafka,保证json消息的完整性,让flink在处理的时候更方便。
4、对于pkupdate操作,无论是主键+其他字段的修改还是仅主键单独的变更,原本的pkupdate消息如下:
{"table":"SCOTT.SCEMP","op_type":"U","op_ts":"2019-09-16 15:18:29.607061","current_ts":"2019-09-16T15:46:06.534000","pos":"00000000230000013943","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"before":{"EMPNO":6666},"after":{"EMPNO":8888,"ENAME":"zyand","JOB":"kfc","SAL":100.00,"DEPTNO":30}}
- 1
这里我们要把pkupdate before的数据拆分成一个单独的json拿出来,并且让除了主键以外的其他需要计算的指标ename,job,sal,deptno也要在这个json中并且这些除主键外的字段值均要为null值,如下:
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-17 09:36:39.480539","current_ts":"2019-09-17T09:36:52.022000","pos":"00000000230000021370","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"after":{"EMPNO":6666,"ENAME":null,"JOB":null,"SAL":null,"DEPTNO":null}}
- 1
而after的也要单独拆分,要保证主键和所有字段的值都是现在最新的状态值:
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-17 09:36:39.480539","current_ts":"2019-09-17T09:37:12.096000","pos":"00000000230000021370","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"after":{"EMPNO":8888,"ENAME":"zyd","JOB":"kfc","SAL":100.00,"DEPTNO":30}}
- 1
之所以这么做一是因为前面说的保证j’son消息的完整性,其次是主键变更后,变更前的主键对应的j’son数据还在kafka中,而新的主键(包括变更主键和其他字段)对应的相关值除了变更主键时被变更的字段外其他的字段值都与旧主键值一致,这样flink计算的时候就会重复计算,为了避免重复计算,在主键变更后生成了新的主键+其他加了附加日志的字段j’son后,还要写一个旧的主键对应的j’son消息,让旧的主键最新的其他字段值都为null,这样flink在计算的时候,根据主键取最新状态值的时候就不会出现重复计算的问题了。
下面是上面逻辑的大致流程图:
下面看具体实验:
–下面所有源端表都是在scott用户下操作。
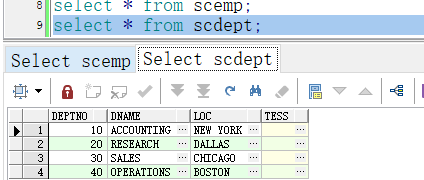
一、源端创建测试用表
create table scemp as select * from emp;
create table scdept as select * from dept;
ALTER TABLE scemp ADD CONSTRAINT PK_scemp PRIMARY KEY (EMPNO);
ALTER TABLE scdept ADD CONSTRAINT PK_scdept PRIMARY KEY (DEPTNO);
- 1
- 2
- 3
- 4

二、源端OGG操作
1、添加附加日志
[oracle@source ogg12]$ ./ggsci
Oracle GoldenGate Command Interpreter for Oracle
Version 12.2.0.2.2 OGGCORE_12.2.0.2.0_PLATFORMS_170630.0419_FBO
Linux, x64, 64bit (optimized), Oracle 11g on Jun 30 2017 14:42:26
Operating system character set identified as UTF-8.
Copyright (C) 1995, 2017, Oracle and/or its affiliates. All rights reserved.
GGSCI (source) 16> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
EXTRACT ABENDED D_KA 00:00:00 5714:15:13
EXTRACT ABENDED D_KF 00:00:00 6507:59:26
EXTRACT ABENDED D_SC 00:00:00 140:41:02
EXTRACT RUNNING D_ZT 00:00:00 00:00:04
EXTRACT STOPPED E_KA 00:00:00 2692:41:17
EXTRACT ABENDED E_SC 00:00:00 00:29:58
EXTRACT STOPPED E_ZT 00:00:00 00:15:43
GGSCI (source) 2> dblogin userid ogg password ogg
Successfully logged into database.
GGSCI (source as ogg@orcl) 18> add trandata SCOTT.SCEMP
Logging of supplemental redo data enabled for table SCOTT.SCEMP.
TRANDATA for scheduling columns has been added on table 'SCOTT.SCEMP'.
TRANDATA for instantiation CSN has been added on table 'SCOTT.SCEMP'.
GGSCI (source as ogg@orcl) 19> add trandata SCOTT.SCDEPT
Logging of supplemental redo data enabled for table SCOTT.SCDEPT.
TRANDATA for scheduling columns has been added on table 'SCOTT.SCDEPT'.
TRANDATA for instantiation CSN has been added on table 'SCOTT.SCDEPT'.
GGSCI (source as ogg@orcl) 20> info trandata SCOTT.SC*
Logging of supplemental redo log data is enabled for table SCOTT.SCDEPT.
Columns supplementally logged for table SCOTT.SCDEPT: DEPTNO.
Prepared CSN for table SCOTT.SCDEPT: 2151646
Logging of supplemental redo log data is enabled for table SCOTT.SCEMP.
Columns supplementally logged for table SCOTT.SCEMP: EMPNO.
Prepared CSN for table SCOTT.SCEMP: 2151611
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
因为现在只是对主键加了附加日志,未来DML操作,insert,delete向kafka投递消息时,规定所有的数据都在after中便于j’son解析注册,没问题,但是update以json格式投递到kafka然后flink消费时字段值只有主键和被修改的字段存在值,但是未来SCEMP表可能empno,ename,job,sal,deptno这几个字段都会用到,dept表所有字段都会用到,并且要求无论对哪些字段做update操作,投递到kafka的所有json数据必须都要有上面几个字段及相关值。所以额外给emp表的empno,ename,job,sal,deptno组合添加附加日志,dept表给整个表添加附加日志来支持后续flink计算:
[oracle@source ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.4.0 Production on Fri Sep 6 15:46:02 2019
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> alter table scott.scemp add SUPPLEMENTAL LOG GROUP groupaa(empno,ename,job,sal,deptno) always;
Table altered.
SQL> ALTER TABLE scott.scdept add SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
Table altered.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2、源端配置初始化进程
数据初始化,指的是从源端Oracle 数据库将已存在的需要的数据同步至目标端,配置初始化进程:
GGSCI (source) 1> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
EXTRACT ABENDED D_KA 00:00:00 5714:15:13
EXTRACT ABENDED D_KF 00:00:00 6507:59:26
EXTRACT ABENDED D_SC 00:00:00 140:41:02
EXTRACT RUNNING D_ZT 00:00:00 00:00:04
EXTRACT STOPPED E_KA 00:00:00 2692:41:17
EXTRACT ABENDED E_SC 00:00:00 00:29:58
EXTRACT STOPPED E_ZT 00:00:00 00:15:43
GGSCI (source) 2> dblogin userid ogg password ogg
Successfully logged into database.
GGSCI (source as ogg@orcl) 3> add extract initsc,sourceistable
EXTRACT added.
GGSCI (source as ogg@orcl) 4> edit params init01
加入下面配置
EXTRACT init01
SETENV (NLS_LANG=AMERICAN_AMERICA.AL32UTF8)
USERID ogg,PASSWORD ogg
RMTHOST 192.168.1.66, MGRPORT 7809
RMTFILE ./dirdat/ed,maxfiles 999, megabytes 500
----------SCOTT.SCEMP
table SCOTT.SCEMP,tokens(
TKN-OP-TYPE = @GETENV ('GGHEADER', 'OPTYPE')
);
----------SCOTT.SCDEPT
table SCOTT.SCDEPT,tokens(
TKN-OP-TYPE = @GETENV ('GGHEADER', 'OPTYPE')
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
3、源端生成表结构
GoldenGate 提供了 DEFGEN 工具,用于生成数据定义,当源表和目标表中 的定义不同时,GoldenGate 进程将引用该专用工具。在运行 DEFGEN 之前,需要 为其创建一个参数文件:
GGSCI (source) 1> edit params init_scott
加入下面配置
defsfile /u01/app/oracle/ogg12/dirdef/init_scott.def
userid ogg,password ogg
table scott.SCEMP;
table scott.SCDEPT;
GGSCI (source) 4> exit
生成表结构文件,需要执行shell命令,如果配置中的文件已经存在,执行下面命令会报错,所以 在执行前需要先删除:
[oracle@source ogg12]$ cd dirdef/
[oracle@source dirdef]$ ls
emp.def hdfs.def init_emp.def init_scott.def kafka.def scott.def ztvoucher.def
[oracle@source dirdef]$ rm -rf init_scott.def
[oracle@source ogg12]$ ./defgen paramfile dirprm/init_scott.prm
***********************************************************************
Oracle GoldenGate Table Definition Generator for Oracle
Version 12.2.0.2.2 OGGCORE_12.2.0.2.0_PLATFORMS_170630.0419
Linux, x64, 64bit (optimized), Oracle 11g on Jun 30 2017 11:35:56
Copyright (C) 1995, 2017, Oracle and/or its affiliates. All rights reserved.
Starting at 2019-09-10 15:41:15
***********************************************************************
Operating System Version:
Linux
Version #2 SMP Tue May 17 07:23:38 PDT 2016, Release 4.1.12-37.4.1.el6uek.x86_64
Node: source
Machine: x86_64
soft limit hard limit
Address Space Size : unlimited unlimited
Heap Size : unlimited unlimited
File Size : unlimited unlimited
CPU Time : unlimited unlimited
Process id: 84810
***********************************************************************
** Running with the following parameters **
***********************************************************************
defsfile /u01/app/oracle/ogg12/dirdef/init_scott.def
userid ogg,password ***
table scott.SCEMP;
Retrieving definition for SCOTT.SCEMP.
table scott.SCDEPT;
Retrieving definition for SCOTT.SCDEPT.
Definitions generated for 2 tables in /u01/app/oracle/ogg12/dirdef/init_scott.def.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
将生成的定义文件传送到目标端, 目标端的replicate进程会使用这个文件。
[oracle@source ogg12]$ scp /u01/app/oracle/ogg12/dirdef/init_scott.def root@192.168.1.66:/hadoop/ogg12/dirdef/
root@192.168.1.66's password:
init_scott.def 100% 2354 2.3KB/s 00:00
- 1
- 2
- 3
- 4
4、配置抽取进程
因为环境中已经存在一个向195.168.1.66作用的抽取进程和投递进程 e_zt,d_zt:
GGSCI (source) 1> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
EXTRACT ABENDED D_KA 00:00:00 5714:15:13
EXTRACT ABENDED D_KF 00:00:00 6507:59:26
EXTRACT ABENDED D_SC 00:00:00 140:41:02
EXTRACT RUNNING D_ZT 00:00:00 00:00:04 --这个
EXTRACT STOPPED E_KA 00:00:00 2692:41:17
EXTRACT ABENDED E_SC 00:00:00 00:29:58
EXTRACT STOPPED E_ZT 00:00:00 00:15:43 --这个
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
,并且195.168.1.66的kafka应用进程已经存在并停止了:
[root@hadoop ogg12]# ./ggsci
Oracle GoldenGate for Big Data
Version 12.3.2.1.1 (Build 005)
Oracle GoldenGate Command Interpreter
Version 12.3.0.1.2 OGGCORE_OGGADP.12.3.0.1.2_PLATFORMS_180712.2305
Linux, x64, 64bit (optimized), Generic on Jul 13 2018 00:46:09
Operating system character set identified as UTF-8.
Copyright (C) 1995, 2018, Oracle and/or its affiliates. All rights reserved.
GGSCI (hadoop) 2> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
REPLICAT STOPPED RHDFS 00:00:00 454:26:03
REPLICAT STOPPED RKAFKA 00:00:00 2637:46:02 --这个
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
现在只需要把上面两张表的配置加入到e_zt,现在抽取进程配置如下:
GGSCI (source) 2> edit params e_zt
写入下面内容:
extract e_zt
userid ogg,password ogg
setenv(NLS_LANG=AMERICAN_AMERICA.AL32UTF8)
setenv(ORACLE_SID="orcl")
reportcount every 30 minutes,rate
numfiles 5000
discardfile ./dirrpt/e_zt.dsc,append,megabytes 1000
warnlongtrans 2h,checkinterval 30m
exttrail ./dirdat/zt
dboptions allowunusedcolumn
tranlogoptions archivedlogonly
tranlogoptions altarchivelogdest primary /u01/arch
dynamicresolution
fetchoptions nousesnapshot
ddl include mapped
ddloptions addtrandata,report
notcpsourcetimer
NOCOMPRESSDELETES
NOCOMPRESSUPDATES
GETUPDATEBEFORES
----------SCOTT.ZTVOUCHER
table SCOTT.ZTVOUCHER,keycols(MANDT,GJAHR,BUKRS,BELNR,BUZEI,MONAT,BUDAT),tokens(
TKN-OP-TYPE = @GETENV ('GGHEADER', 'OPTYPE')
);
----------SCOTT.ORA_HDFS
table SCOTT.ORA_HDFS,tokens(
TKN-OP-TYPE = @GETENV ('GGHEADER', 'OPTYPE')
);
----------SCOTT.SCEMP
table SCOTT.SCEMP,tokens(
TKN-OP-TYPE = @GETENV ('GGHEADER', 'OPTYPE')
);
----------SCOTT.SCDEPT
table SCOTT.SCDEPT,tokens(
TKN-OP-TYPE = @GETENV ('GGHEADER', 'OPTYPE')
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
5、配置投递进程
将上面两张表加进来
extract d_zt
rmthost 192.168.1.66,mgrport 7809,compress
userid ogg,password ogg
PASSTHRU
numfiles 5000
rmttrail ./dirdat/zt
dynamicresolution
table scott.ztvoucher;
table scott.ora_hdfs;
table scott.scemp;
table scott.scdept;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
三、ODS端操作
1、配置初始化进程
GGSCI (hadoop) 3> ADD replicat init01, specialrun
REPLICAT added.
GGSCI (hadoop) 4> edit params init01
添加下面配置:
SPECIALRUN
end runtime
setenv(NLS_LANG="AMERICAN_AMERICA.AL32UTF8")
targetdb libfile libggjava.so set property=./dirprm/kafka.props
SOURCEDEFS ./dirdef/init_scott.def
EXTFILE ./dirdat/ed
reportcount every 1 minutes, rate
grouptransops 10000
map scott.SCEMP,target SCOTT.SCEMP;
map scott.SCDEPT,target SCOTT.SCDEPT;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2、配置应用进程
因为之前已经配置了rkafka进程,现在只需要在这个进程里面加那两张表的配置就行。
这里有一个问题,虽然update之后的数据能够让flink正常算,但是对于pkupdate之前的主键对应的记录值我们还是会做计算,所以这里flink计算会出现问题,会让同一条记录(只变了主键其他值不变,在kafka中是两条消息)计算两次了,而且我们前面规定了为了flink计算方便,所有数据都从json的after部分取数,所以这里我把对于pkupdate操作来说,在插入kafka一条update之后的数据后,再插入一条update前的数据,并且这个update前的数据除了主键是原来的值外,其余要计算的指标值都设置成null,这样相当于原来变更前的主键其他指标最新的值都是null了,flink在对当前主键最新值计算的时候就会把这些值当成空值来计算从而减去update前的值,只计算update后的值,就不会出现重复计算了,而且前面的配置太冗余,看最新的应用进程配置:
GGSCI (hadoop) 9> view params rkafka
REPLICAT rkafka
-- Trail file for this example is located in "AdapterExamples/trail" directory
-- Command to add REPLICAT
-- add replicat rkafka, exttrail AdapterExamples/trail/tr
TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props
REPORTCOUNT EVERY 1 MINUTES, RATE
allowduptargetmap
NOINSERTDELETES
IGNOREDELETES
IGNOREINSERTS
GETUPDATES
INSERTUPDATES
MAP SCOTT.SCEMP, TARGET SCOTT.SCEMP;
IGNOREDELETES
IGNOREINSERTS
MAP SCOTT.SCEMP, TARGET SCOTT.SCEMP,colmap(
EMPNO=before.EMPNO,
ENAME=@COLSTAT (NULL),
JOB=@COLSTAT (NULL),
SAL=@COLSTAT (NULL),
DEPTNO=@COLSTAT (NULL)
),filter(@strfind(@token('TKN-OP-TYPE'),'PK UPDATE') >0);
NOINSERTUPDATES
GETINSERTS
IGNOREDELETES
IGNOREUPDATES
MAP SCOTT.SCEMP, TARGET SCOTT.SCEMP;
IGNOREUPDATES
IGNOREINSERTS
GETDELETES
INSERTDELETES
MAP SCOTT.SCEMP, TARGET SCOTT.SCEMP;
NOINSERTDELETES
IGNOREDELETES
IGNOREINSERTS
GETUPDATES
INSERTUPDATES
MAP SCOTT.SCDEPT, TARGET SCOTT.SCDEPT;
IGNOREDELETES
IGNOREINSERTS
MAP SCOTT.SCDEPT, TARGET SCOTT.SCDEPT,colmap(
DEPTNO=before.DEPTNO,
DNAME=@COLSTAT (NULL),
LOC=@COLSTAT (NULL),
TESS=@COLSTAT (NULL)
),filter(@strfind(@token('TKN-OP-TYPE'),'PK UPDATE') >0);
NOINSERTUPDATES
GETINSERTS
IGNOREDELETES
IGNOREUPDATES
MAP SCOTT.SCDEPT, TARGET SCOTT.SCDEPT;
IGNOREUPDATES
IGNOREINSERTS
GETDELETES
INSERTDELETES
MAP SCOTT.SCDEPT, TARGET SCOTT.SCDEPT;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
三、同步数据
1、源端操作
启动进程:
GGSCI (source) 9> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
EXTRACT ABENDED D_KA 00:00:00 5853:30:25
EXTRACT ABENDED D_KF 00:00:00 6647:14:38
EXTRACT ABENDED D_SC 00:00:00 279:56:15
EXTRACT RUNNING D_ZT 00:00:00 00:00:07
EXTRACT STOPPED E_KA 00:00:00 2831:56:29
EXTRACT ABENDED E_SC 00:00:00 00:08:54
EXTRACT STOPPED E_ZT 00:00:00 137:51:42
GGSCI (source) 10> start e_zt
Sending START request to MANAGER ...
EXTRACT E_ZT starting
GGSCI (source) 12> start d_zt
EXTRACT D_ZT is already running.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2、源端初始化进程
GGSCI (source) 3> start init01
Sending START request to MANAGER ...
EXTRACT INIT01 starting
GGSCI (source) 4> info init01
EXTRACT INIT01 Last Started 2019-09-16 10:14 Status STARTING
Checkpoint Lag Not Available
Process ID 87517
Log Read Checkpoint Table SCOTT.SCDEPT
2019-09-16 10:14:47 Record 4
Task SOURCEISTABLE
GGSCI (source) 5> info init01
EXTRACT INIT01 Last Started 2019-09-16 10:17 Status STOPPED
Checkpoint Lag Not Available
Log Read Checkpoint Table SCOTT.SCDEPT
2019-09-16 10:17:01 Record 4
Task SOURCEISTABLE
或则通过下面方式初始化
[oracle@source ogg12]$ ./extract paramfile dirprm/init01.prm reportfile dirrpt/init01.rpt
[oracle@source ogg12]$ tail -30f dirrpt/init01.rpt
2019-09-16 09:45:32 INFO OGG-02911 Processing table SCOTT.SCEMP.
2019-09-16 09:45:32 INFO OGG-02911 Processing table SCOTT.SCDEPT.
***********************************************************************
* ** Run Time Statistics ** *
***********************************************************************
Report at 2019-09-16 09:45:32 (activity since 2019-09-16 09:45:26)
Output to ./dirdat/ed:
From Table SCOTT.SCEMP:
# inserts: 16
# updates: 0
# deletes: 0
# discards: 0
From Table SCOTT.SCDEPT:
# inserts: 4
# updates: 0
# deletes: 0
# discards: 0
REDO Log Statistics
Bytes parsed 0
Bytes output 4417
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
去目标端查看生成的trail文件:
[root@hadoop dirdat]# ls -ltr ed*
-rw-r----- 1 root root 6265 Sep 16 10:17 ed000000
[root@hadoop ogg12]# cat loginit_zt
cd ./dirdat
open ed000000
ghdr on
detail on
detail data
usertoken on
usertoken detail
ggstoken on
ggstoken detail
headertoken on
headertoken detail
reclen 0
pos last
pos rev
logtrail
pos
[root@hadoop dirdat]# cd ..
[root@hadoop ogg12]# ./logdump
Oracle GoldenGate Log File Dump Utility
Version 12.3.0.1.2 OGGCORE_OGGADP.12.3.0.1.2_PLATFORMS_180712.2305
Copyright (C) 1995, 2018, Oracle and/or its affiliates. All rights reserved.
Logdump 91 >obey loginit_zt
cd ./dirdat
open ed000000
Current LogTrail is /hadoop/ogg12/dirdat/ed000000
ghdr on
detail on
detail data
usertoken on
usertoken detail
ggstoken on
ggstoken detail
headertoken on
headertoken detail
reclen 0
Reclen set to 0
pos last
Reading forward from RBA 6265
pos rev
Reading in reverse from RBA 6265
logtrail
Current LogTrail is /hadoop/ogg12/dirdat/ed000000
pos
Current position is RBA 6265 Reverse
Logdump 92 >pos last
Reading in reverse from RBA 6265
Logdump 93 >pos rev
Reading in reverse from RBA 6265
Logdump 94 >n
TokenID x47 'G' Record Header Info x01 Length 129
TokenID x48 'H' GHDR Info x00 Length 36
450c 0041 3600 05ff e26e 1fa8 d5b8 f202 0000 0000 | E..A6....n..........
0000 0000 0000 0000 0352 0000 0001 0000 | .........R......
TokenID x44 'D' Data Info x00 Length 54
TokenID x55 'U' User Tokens Info x00 Length 19
TokenID x5a 'Z' Record Trailer Info x01 Length 129
___________________________________________________________________
Hdr-Ind : E (x45) Partition : . (x0c)
UndoFlag : . (x00) BeforeAfter: A (x41)
RecLength : 54 (x0036) IO Time : 2019/09/16 10:17:08.011.746
IOType : 5 (x05) OrigNode : 255 (xff)
TransInd : . (x03) FormatType : R (x52)
SyskeyLen : 0 (x00) Incomplete : . (x00)
AuditRBA : 0 AuditPos : 0
Continued : N (x00) RecCount : 1 (x01)
2019/09/16 10:17:08.011.746 Insert Len 54 RBA 6136
Name: SCOTT.SCDEPT (TDR Index: 2)
After Image: Partition 12 U s
0000 000a 0000 0000 0000 0000 0028 0001 000e 0000 | .............(......
000a 4f50 4552 4154 494f 4e53 0002 000a 0000 0006 | ..OPERATIONS........
424f 5354 4f4e 0003 0004 ffff 0000 | BOSTON........
Column 0 (x0000), Len 10 (x000a)
0000 0000 0000 0000 0028 | .........(
Column 1 (x0001), Len 14 (x000e)
0000 000a 4f50 4552 4154 494f 4e53 | ....OPERATIONS
Column 2 (x0002), Len 10 (x000a)
0000 0006 424f 5354 4f4e | ....BOSTON
Column 3 (x0003), Len 4 (x0004)
ffff 0000 | ....
User tokens: 19 bytes
TKN-OP-TYPE : INSERT
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
数据过来了
3、目标端初始化进程
先看下当前kafka中topic信息:
[root@hadoop kafka]# cat ./list.sh
#!/bin/bash
bin/kafka-topics.sh -describe -zookeeper 192.168.1.66:2181
[root@hadoop kafka]# ./list.sh
Topic:DEPT PartitionCount:1 ReplicationFactor:1 Configs:
Topic: DEPT Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:EMP PartitionCount:1 ReplicationFactor:1 Configs:
Topic: EMP Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:ZTVOUCHER_DEL PartitionCount:1 ReplicationFactor:1 Configs:
Topic: ZTVOUCHER_DEL Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:ZTVOUCHER_INS PartitionCount:1 ReplicationFactor:1 Configs:
Topic: ZTVOUCHER_INS Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:kylin_streaming_topic PartitionCount:1 ReplicationFactor:1 Configs:
Topic: kylin_streaming_topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:scott PartitionCount:1 ReplicationFactor:1 Configs:
Topic: scott Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:zttest PartitionCount:1 ReplicationFactor:1 Configs:
Topic: zttest Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:ztvoucher PartitionCount:1 ReplicationFactor:1 Configs:
Topic: ztvoucher Partition: 0 Leader: 0 Replicas: 0 Isr: 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
因为kafka已经配置了当没有相关topic时会自动创建相关topic,但是为了规范,这里手动创建topic:
[root@hadoop kafka]# cat create.sh
read -p "input topic:" name
bin/kafka-topics.sh --create --zookeeper 192.168.1.66:2181 --replication-factor 1 --partitions 1 --topic $name
[root@hadoop kafka]# ./create.sh
input topic:SCEMP
Created topic "SCEMP".
[root@hadoop kafka]# ./create.sh
input topic:SCDEPT
Created topic "SCDEPT".
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
单独开两个会话消费上面两个topic数据:
[root@hadoop kafka]# cat console.sh
#!/bin/bash
read -p "input topic:" name
bin/kafka-console-consumer.sh --zookeeper 192.168.1.66:2181 --topic $name --from-beginning
[root@hadoop kafka]# ./console.sh
input topic:SCEMP
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
[root@hadoop kafka]# ./console.sh
input topic:SCDEPT
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
开始初始化数据:
[root@hadoop ogg12]# ./replicat paramfile ./dirprm/init01.prm reportfile ./dirrpt/init01.rpt -p INITIALDATALOAD
- 1
查看日志:
[root@hadoop ogg12]# tail -f dirrpt/init01.rpt
Sep 16, 2019 10:24:59 AM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
INFO: Loading XML bean definitions from class path resource [oracle/goldengate/datasource/DataSource-context.xml]
Sep 16, 2019 10:24:59 AM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
INFO: Loading XML bean definitions from class path resource [config/ggue-context.xml]
Sep 16, 2019 10:24:59 AM org.springframework.beans.factory.support.DefaultListableBeanFactory registerBeanDefinition
INFO: Overriding bean definition for bean 'dataSourceConfig' with a different definition: replacing [Generic bean: class [oracle.goldengate.datasource.DataSourceConfig]; scope=singleton; abstract=false; lazyIni
t=false; autowireMode=0; dependencyCheck=0; autowireCandidate=true; primary=false; factoryBeanName=null; factoryMethodName=null; initMethodName=null; destroyMethodName=null; defined in class path resource [oracle/goldengate/datasource/DataSource-context.xml]] with [Generic bean: class [oracle.goldengate.datasource.DataSourceConfig]; scope=singleton; abstract=false; lazyInit=false; autowireMode=0; dependencyCheck=0; autowireCandidate=true; primary=false; factoryBeanName=null; factoryMethodName=null; initMethodName=null; destroyMethodName=null; defined in class path resource [config/ggue-context.xml]]Sep 16, 2019 10:24:59 AM org.springframework.beans.factory.support.DefaultListableBeanFactory registerBeanDefinition
INFO: Overriding bean definition for bean 'versionInfo' with a different definition: replacing [Generic bean: class [oracle.goldengate.util.VersionInfo]; scope=singleton; abstract=false; lazyInit=false; autowir
eMode=0; dependencyCheck=0; autowireCandidate=true; primary=false; factoryBeanName=null; factoryMethodName=null; initMethodName=null; destroyMethodName=null; defined in class path resource [oracle/goldengate/datasource/DataSource-context.xml]] with [Generic bean: class [oracle.goldengate.util.VersionInfo]; scope=singleton; abstract=false; lazyInit=false; autowireMode=0; dependencyCheck=0; autowireCandidate=true; primary=false; factoryBeanName=null; factoryMethodName=null; initMethodName=null; destroyMethodName=null; defined in class path resource [config/ggue-context.xml]]Sep 16, 2019 10:24:59 AM org.springframework.context.support.AbstractApplicationContext prepareRefresh
INFO: Refreshing org.springframework.context.support.GenericApplicationContext@501edcf1: startup date [Mon Sep 16 10:24:59 CST 2019]; root of context hierarchy
Oracle GoldenGate for Big Data, 12.3.2.1.1.005
Copyright (c) 2007, 2018. Oracle and/or its affiliates. All rights reserved
Built with Java 1.8.0_161 (class version: 52.0)
SOURCEDEFS ./dirdef/init_scott.def
EXTFILE ./dirdat/ed
reportcount every 1 minutes, rate
grouptransops 10000
map scott.SCEMP,target SCOTT.SCEMP;
map scott.SCDEPT,target SCOTT.SCDEPT;
2019-09-16 10:25:01 INFO OGG-01815 Virtual Memory Facilities for: COM
anon alloc: mmap(MAP_ANON) anon free: munmap
file alloc: mmap(MAP_SHARED) file free: munmap
target directories:
/hadoop/ogg12/dirtmp.
Database Version:
Database Language and Character Set:
2019-09-16 10:25:01 INFO OGG-02243 Opened trail file /hadoop/ogg12/dirdat/ed000000 at 2019-09-16 10:25:01.285030.
2019-09-16 10:25:01 INFO OGG-03506 The source database character set, as determined from the trail file, is UTF-8.
***********************************************************************
** Run Time Messages **
***********************************************************************
2019-09-16 10:25:01 INFO OGG-02243 Opened trail file /hadoop/ogg12/dirdat/ed000000 at 2019-09-16 10:25:01.303836.
2019-09-16 10:25:01 WARNING OGG-02761 Source definitions file, ./dirdef/init_scott.def, is ignored because trail file /hadoop/ogg12/dirdat/ed000000 contains table definitions.
2019-09-16 10:25:01 INFO OGG-06505 MAP resolved (entry scott.SCEMP): map "SCOTT"."SCEMP",target SCOTT.SCEMP.
2019-09-16 10:25:01 INFO OGG-02756 The definition for table SCOTT.SCEMP is obtained from the trail file.
2019-09-16 10:25:01 INFO OGG-06511 Using following columns in default map by name: EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO.
2019-09-16 10:25:01 INFO OGG-06510 Using the following key columns for target table SCOTT.SCEMP: EMPNO.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
查看两个topic消费情况:
[root@hadoop kafka]# ./console.sh
input topic:SCEMP
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:25:01.379000","pos":"00000000000000002199","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":1232,"ENAME":"
FORD","JOB":"ANALYST","MGR":7566,"HIREDATE":"1981-12-03 00:00:00","SAL":3000.00,"COMM":null,"DEPTNO":20}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:25:21.767000","pos":"00000000000000002396","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":1222,"ENAME":"
FORD","JOB":"ANALYST","MGR":7566,"HIREDATE":"1981-12-03 00:00:00","SAL":3000.00,"COMM":null,"DEPTNO":20}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:25:31.787000","pos":"00000000000000002593","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":3211,"ENAME":"
FORD","JOB":"ANALYST","MGR":7566,"HIREDATE":"1981-12-03 00:00:00","SAL":3000.00,"COMM":null,"DEPTNO":20}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:25:41.803000","pos":"00000000000000002790","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7369,"ENAME":"
er","JOB":"CLERK","MGR":7902,"HIREDATE":"1980-12-17 00:00:00","SAL":800.00,"COMM":null,"DEPTNO":20}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:25:51.814000","pos":"00000000000000002983","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7499,"ENAME":"
ALLEN","JOB":"SALESMAN","MGR":7698,"HIREDATE":"1981-02-20 00:00:00","SAL":1600.00,"COMM":300.00,"DEPTNO":30}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:26:01.831000","pos":"00000000000000003182","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7521,"ENAME":"
WARD","JOB":"SALESMAN","MGR":7698,"HIREDATE":"1981-02-22 00:00:00","SAL":1250.00,"COMM":500.00,"DEPTNO":30}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:26:11.847000","pos":"00000000000000003380","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7566,"ENAME":"
JONES","JOB":"MANAGER","MGR":7839,"HIREDATE":"1981-04-02 00:00:00","SAL":2975.00,"COMM":null,"DEPTNO":20}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:26:21.864000","pos":"00000000000000003578","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7654,"ENAME":"
MARTIN","JOB":"SALESMAN","MGR":7698,"HIREDATE":"1981-09-28 00:00:00","SAL":1250.00,"COMM":1400.00,"DEPTNO":30}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:26:31.881000","pos":"00000000000000003778","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7698,"ENAME":"
BLAKE","JOB":"MANAGER","MGR":7839,"HIREDATE":"1981-05-01 00:00:00","SAL":2850.00,"COMM":null,"DEPTNO":30}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:26:41.898000","pos":"00000000000000003976","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7782,"ENAME":"
CLARK","JOB":"MANAGER","MGR":7839,"HIREDATE":"1981-06-09 00:00:00","SAL":2450.00,"COMM":null,"DEPTNO":10}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:26:51.907000","pos":"00000000000000004174","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7839,"ENAME":"
KING","JOB":"PRESIDENT","MGR":null,"HIREDATE":"1981-11-17 00:00:00","SAL":5000.00,"COMM":null,"DEPTNO":10}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:27:01.920000","pos":"00000000000000004373","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7844,"ENAME":"
TURNER","JOB":"SALESMAN","MGR":7698,"HIREDATE":"1981-09-08 00:00:00","SAL":1500.00,"COMM":0,"DEPTNO":30}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:27:11.932000","pos":"00000000000000004573","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7876,"ENAME":"
ADAMS","JOB":"CLERK","MGR":7788,"HIREDATE":"1987-05-23 00:00:00","SAL":1100.00,"COMM":null,"DEPTNO":20}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:27:21.938000","pos":"00000000000000004769","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7900,"ENAME":"
JAMES","JOB":"CLERK","MGR":7698,"HIREDATE":"1981-12-03 00:00:00","SAL":950.00,"COMM":null,"DEPTNO":30}}{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-16 10:17:08.006650","current_ts":"2019-09-16T10:27:31.948000","pos":"00000000000000004965","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":7902,"ENAME":"
FORD","JOB":"ANALYST","MGR":7566,"HIREDATE":"1981-12-03 00:00:00","SAL":3000.00,"COMM":null,"DEPTNO":20}}
[root@hadoop kafka]# ./console.sh
input topic:SCDEPT
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
{"table":"SCOTT.SCDEPT","op_type":"I","op_ts":"2019-09-16 10:17:08.011746","current_ts":"2019-09-16T10:27:51.977000","pos":"00000000000000005753","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"DEPTNO":10,"DNAME":"
ACCOUNTING","LOC":"NEW YORK","TESS":null}}{"table":"SCOTT.SCDEPT","op_type":"I","op_ts":"2019-09-16 10:17:08.011746","current_ts":"2019-09-16T10:28:12.000000","pos":"00000000000000005884","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"DEPTNO":20,"DNAME":"
RESEARCH","LOC":"DALLAS","TESS":null}}{"table":"SCOTT.SCDEPT","op_type":"I","op_ts":"2019-09-16 10:17:08.011746","current_ts":"2019-09-16T10:28:22.011000","pos":"00000000000000006011","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"DEPTNO":30,"DNAME":"
SALES","LOC":"CHICAGO","TESS":null}}{"table":"SCOTT.SCDEPT","op_type":"I","op_ts":"2019-09-16 10:17:08.011746","current_ts":"2019-09-16T10:28:32.027000","pos":"00000000000000006136","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"DEPTNO":40,"DNAME":"
OPERATIONS","LOC":"BOSTON","TESS":null}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
SCDEP ,SCEMP表已经 初始化数据过来了。
接下来启动应用进程增量同步数据:
GGSCI (hadoop) 2> start rkafka
Sending START request to MANAGER ...
REPLICAT RKAFKA starting
GGSCI (hadoop) 3> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
REPLICAT STOPPED RHDFS 00:00:00 617:28:44
REPLICAT STARTING RKAFKA 00:00:00 00:32:14
GGSCI (hadoop) 8> !
info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
REPLICAT STOPPED RHDFS 00:00:00 617:28:58
REPLICAT RUNNING RKAFKA 00:00:00 00:00:02
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
4、验证增量同步
a、源端做insert操作:
insert into scemp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (9999, 'zhaoyd', 'kfc', 6666, sysdate, 100.00, 300.00, 30);
insert into scdept(deptno,dname,loc)values(99,'kfc','bj');
- 1
- 2
- 3
- 4
去kafka看结果:
----SCEMP消息:
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-18 09:29:42.000388","current_ts":"2019-09-18T09:30:57.750000","pos":"00000000230000057892","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"EMPNO":9999,"ENAME":"zhaoyd","JOB":"kfc","MGR":6666,"HIREDATE":"2019-09-18 09:29:40","SAL":100.00,"COMM":300.00,"DEPTNO":30}}
----SCDEPT消息:
{"table":"SCOTT.SCDEPT","op_type":"I","op_ts":"2019-09-18 09:29:42.000388","current_ts":"2019-09-18T09:31:07.764000","pos":"00000000230000058138","tokens":{"TKN-OP-TYPE":"INSERT"},"after":{"DEPTNO":99,"DNAME":"kfc","LOC":"bj","TESS":null}}
- 1
- 2
- 3
- 4
可以看到insert都正常同步过来了。
b、源端做普通update操作:
update scemp set ename='zyd' where empno=9999;--修改带附加日志的字段
update scemp set mgr=654 where empno=9999;--修改没加附加日志的字段
update scdept set dname='beij' where deptno=99;--这个表全列附加日志
- 1
- 2
- 3
去kafka看结果:
----SCEMP
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-18 09:32:59.000686","current_ts":"2019-09-18T09:33:53.994000","pos":"00000000230000058486","tokens":{"TKN-OP-TYPE":"SQL COMPUPDATE"},"after":{"EMPNO":9999,"ENAME":"zyd","JOB":"kfc","SAL":100.00,"DEPTNO":30}}
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-18 09:32:59.000686","current_ts":"2019-09-18T09:34:04.009000","pos":"00000000230000058850","tokens":{"TKN-OP-TYPE":"SQL COMPUPDATE"},"after":{"EMPNO":9999,"ENAME":"zyd","JOB":"kfc","MGR":654,"SAL":100.00,"DEPTNO":30}}
----SCDEPT
{"table":"SCOTT.SCDEPT","op_type":"I","op_ts":"2019-09-18 09:32:59.000686","current_ts":"2019-09-18T09:34:14.021000","pos":"00000000230000059193","tokens":{"TKN-OP-TYPE":"SQL COMPUPDATE"},"after":{"DEPTNO":99,"
DNAME":"beij","LOC":"bj","TESS":null}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
从第一条update结果看,所有添加了附加日志的列及最新值都过来了,第二条结果发现SCEMP表在做了update mgr字段时候,除了其余所有加了附加日志的字段值都跟着过来了,mgr最新值也过来了,现在的json内容是:
主键+附加日志字段+被修改字段,能够满足flink极为方便的获取每个需要计算指标的最新值。
c、源端做pkupdate操作:
update scemp set empno=3333, ename='zzd' where empno=9999;
update scemp set empno=9999, mgr=6543 where empno=3333;
update scemp set empno=3333 where empno=9999;
update scdept set deptno=33,dname='zd' where deptno=99;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
去看kafka消息:
----SCEMP
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-18 09:40:33.000792","current_ts":"2019-09-18T09:40:58.666000","pos":"00000000230000059547","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"after":{"EMPNO":3333,"ENAME":"zzd","JOB":"kfc","SAL":100.00,"DEPTNO":30}}
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-18 09:40:33.000792","current_ts":"2019-09-18T09:41:08.681000","pos":"00000000230000059547","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"after":{"EMPNO":9999,"ENAME":null,"JOB":null,"SAL":null,"DEPTNO":null}}
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-18 09:53:59.000496","current_ts":"2019-09-18T09:54:07.801000","pos":"00000000230000060265","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"after":{"EMPNO":9999,"ENAME":"zzd","JOB":"kfc","MGR":6543,"SAL":100.00,"DEPTNO":30}}
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-18 09:53:59.000496","current_ts":"2019-09-18T09:54:17.820000","pos":"00000000230000060265","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"after":{"EMPNO":3333,"ENAME":null,"JOB":null,"SAL":null,"DEPTNO":null}}
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-18 09:54:44.000419","current_ts":"2019-09-18T09:54:54.876000","pos":"00000000230000060664","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"after":{"EMPNO":3333,"ENAME":"zzd","JOB":"kfc","SAL":100.00,"DEPTNO":30}}
{"table":"SCOTT.SCEMP","op_type":"I","op_ts":"2019-09-18 09:54:44.000419","current_ts":"2019-09-18T09:55:04.882000","pos":"00000000230000060664","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"after":{"EMPNO":9999,"ENAME":null,"JOB":null,"SAL":null,"DEPTNO":null}}
----SCDEPT
{"table":"SCOTT.SCDEPT","op_type":"I","op_ts":"2019-09-18 09:40:33.000792","current_ts":"2019-09-18T09:41:18.697000","pos":"00000000230000059888","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"after":{"DEPTNO":33,"DNAME":"zd","LOC":"bj","TESS":null}}
{"table":"SCOTT.SCDEPT","op_type":"I","op_ts":"2019-09-18 09:40:33.000792","current_ts":"2019-09-18T09:41:28.704000","pos":"00000000230000059888","tokens":{"TKN-OP-TYPE":"PK UPDATE"},"after":{"DEPTNO":99,"DNAME":null,"LOC":null,"TESS":null}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
从上面结果看到,现在pkupdate操作被分成了两个json,旧的主键对应的j’son中需要计算的指标值都是空,而新的主键对应的json中需要计算的指标都是各指标最新的值,能够满足flink在发生pkupdate时候计算不会出错。

