
热门标签
热门文章
- 1文本分类与聚类(text categorization and clustering)_文本聚类和文本分类
- 2【Kafka】Kafka 架构深入
- 3iphone桌面上的圆圈怎么设置_不会这20个iPhone苹果手机技巧,轻则玩不转,重则被盗刷数万!...
- 4基于Java后台(Springboot框架)+前端小程序(MINA框架)+Mysql数据库的教室实验室预约小程序系统设计与实现_java连接mysql数据库 教室预约
- 5RK3588 设备树pinctrl gpio子系统解析,解决GPIO无法正确拉高拉低的问题,RK3588设备树详解
- 6Elemnt-ui Table组件及 <template scope=“scopeData“>的使用理解
- 7VHDL语言基础-基本语句
- 8什么是运行时Runtime、运行时库Runtime Library、运行时环境Runtime environment
- 9Sql删除
- 10强化学习的实际应用案例分析
当前位置: article > 正文
预训练大模型最佳Llama开源社区中文版Llama2
作者:weixin_40725706 | 2024-04-10 19:05:43
赞
踩
预训练大模型最佳Llama开源社区中文版Llama2
Llama中文社区率先完成了国内首个真正意义上的中文版Llama2-13B大模型,从模型底层实现了Llama2中文能力的大幅优化和提升。毋庸置疑,中文版Llama2一经发布将开启国内大模型新时代。
作为AI领域最强大的开源大模型,Llama2基于2万亿token数据预训练,并在100万人类标记数据上微调得到对话模型。在包括推理、编程、对话和知识测试等许多基准测试中效果显著优于MPT、Falcon以及第一代LLaMA等开源大语言模型
Atom-7B是一个基于Llama2架构的预训练语言模型,我们将基于大规模中文语料,从预训练开始对Llama2模型进行中文能力的持续迭代升级。
我们希望能将模型能力进化的过程展示出来,同时欢迎社区提供优质的数据资源加入到预训练中。
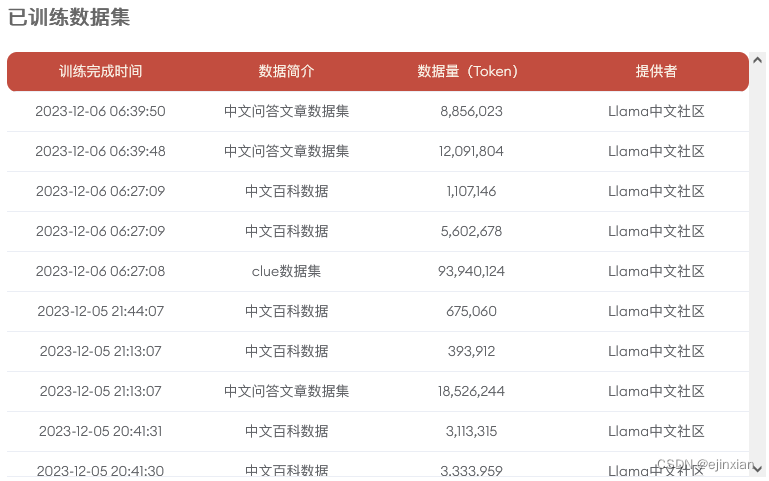
社区将持续开放每一阶段训练出的最新模型,供所有社区伙伴免费下载使用
参考:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/400479
推荐阅读
相关标签

