
热门标签
热门文章
- 1同程面试经历
- 2PaddlePaddl安装_paddle1.5.1要用python几?
- 3Java 十大算法: 01、冒泡排序 02、选择排序 03、插入排序 04、希尔排序 05、归并排序 06、快速排序 07、堆排序 08、计数排序 09、桶排序 10、基数排序_java十大算法
- 4影像分辨率、地面分辨率、比例尺及DPI之间的关系
- 5数据挖掘—网格搜索2_grid_search.cv_results_
- 6【python】Django——连接mysql数据库_django连接数据库mysql
- 7站群服务器可以搭建几个网站,香港站群服务器最适合搭建哪些WordPress 网站 - WordPress 多站点站群...
- 8git本地分支如何与远端分支关联_git 分支和远程分支关联
- 9KEIL安装额外版本的arm compiler v6.16 v5.06update7_arm compiler 5.06 update 7
- 10调OpenAI API报错You exceeded your current quota_insufficient_quota you exceeded your current quota
当前位置: article > 正文
Pytorch框架—文本情感分类问题项目(一)_英文文本情感分析pytorch
作者:weixin_40725706 | 2024-04-13 16:33:40
赞
踩
英文文本情感分析pytorch
1 情感分类概念介绍
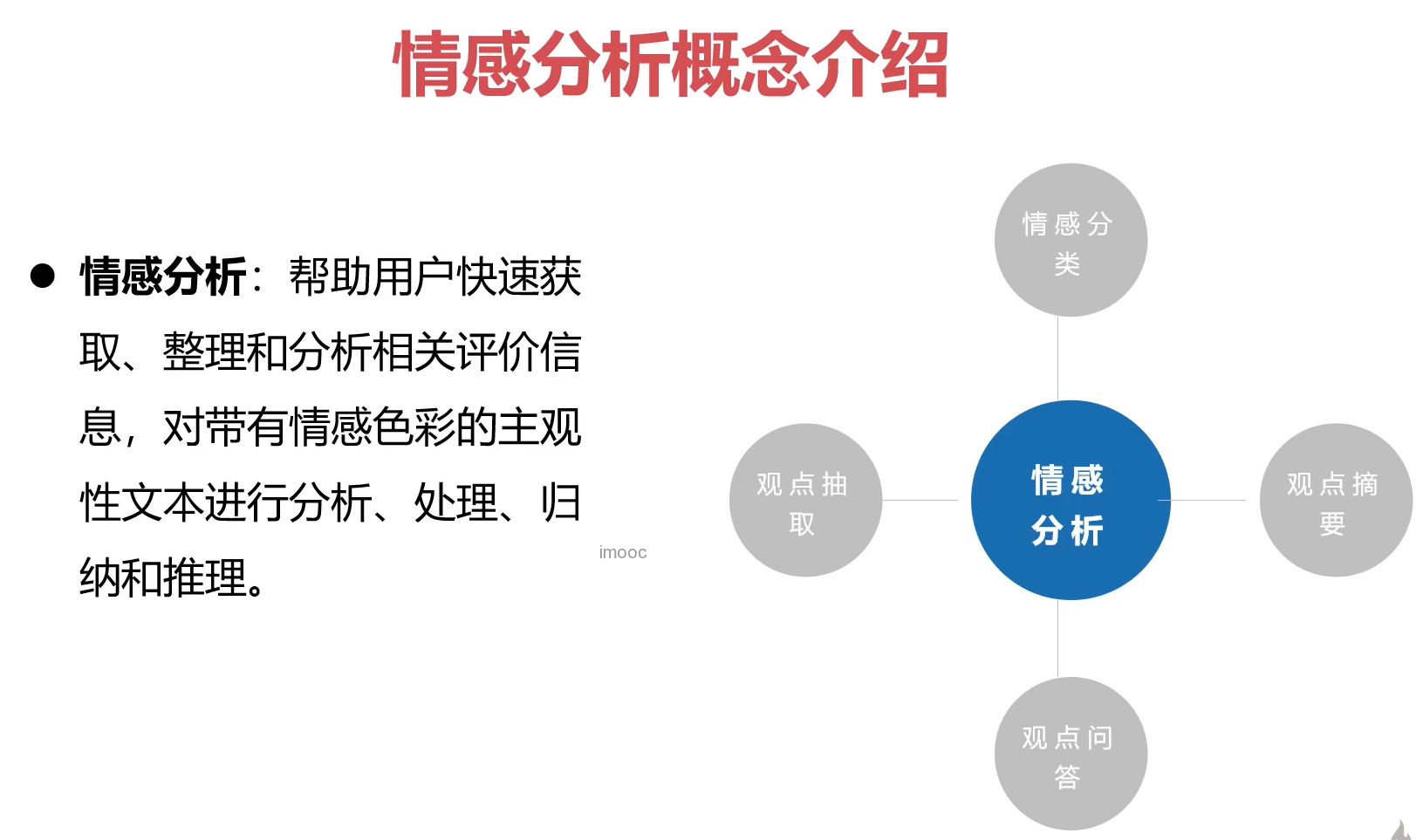

粒度:文章,段落,句子,词组
情感分类(倾向性分析):积极,中性,消极
2 情感分类流程
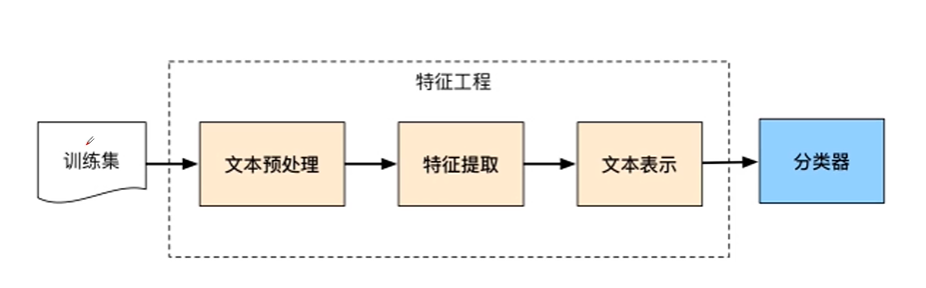
训练集:建立语料库
文本预处理:对语料库进行加工。例如中文进行分词
特征提取:对文本内容进行数据分析挖掘等时,需要对文字重新进行编码。(文本转向量)
文本表示:拿到可以被机器识别的文本信息
分类器:情感分析典型的分类问题。
3 文本预处理-中文分词

分词的同时进行句法,语义分析,利用句法信息和语义信息来处理歧义现象
对于英文就可以之间以空格进行分词。
例:南京长江大桥--南京/长江/大桥--南京/长江大桥 基于理解的分词有歧义

去除停用词,例如的,而,吗,!#等特殊符号
文本特征表示与文字表示

所谓one hot就是当前的这个字对应到的字典中的索引这个值我们将他定义为1,其他的定义为0
例如北京欢迎你 分词为 北京 欢迎 你 编码为北京为100,欢迎为010 你为001

本文采用BERT。
文本分类模型


N-gram 是一种文本表示方法,它将文本分割成连续的字符序列,并对这些序列进行统计分析。具体来说,N-gram 是由 N 个连续的字符组成的子序列,其中 N 是一个整数。
例如,对于一个句子“Hello world”,1-gram 可以是“H”、“e”、“l”、“l”、“o”、“w”、“r”、“l”和“d”等单个字符。2-gram 可以是“He”、“el”、“ll”、“lo”、“ow”、“wr”和“ld”等两个连续字符的组合。3-gram 可以是“Hel”、“ell”、“llo”、“low”、“owl”和“wor”等三个连续字符的组合,依此类推。
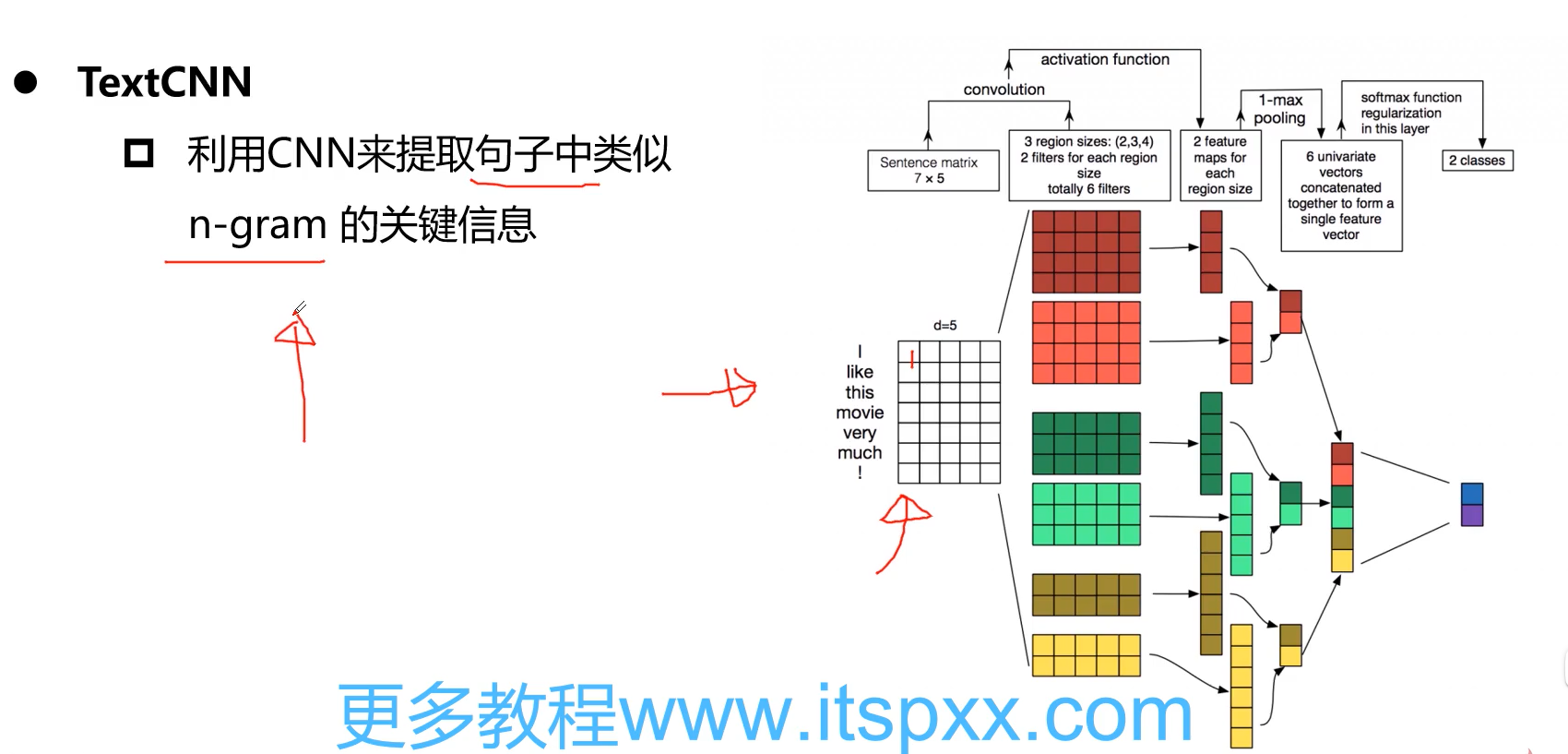
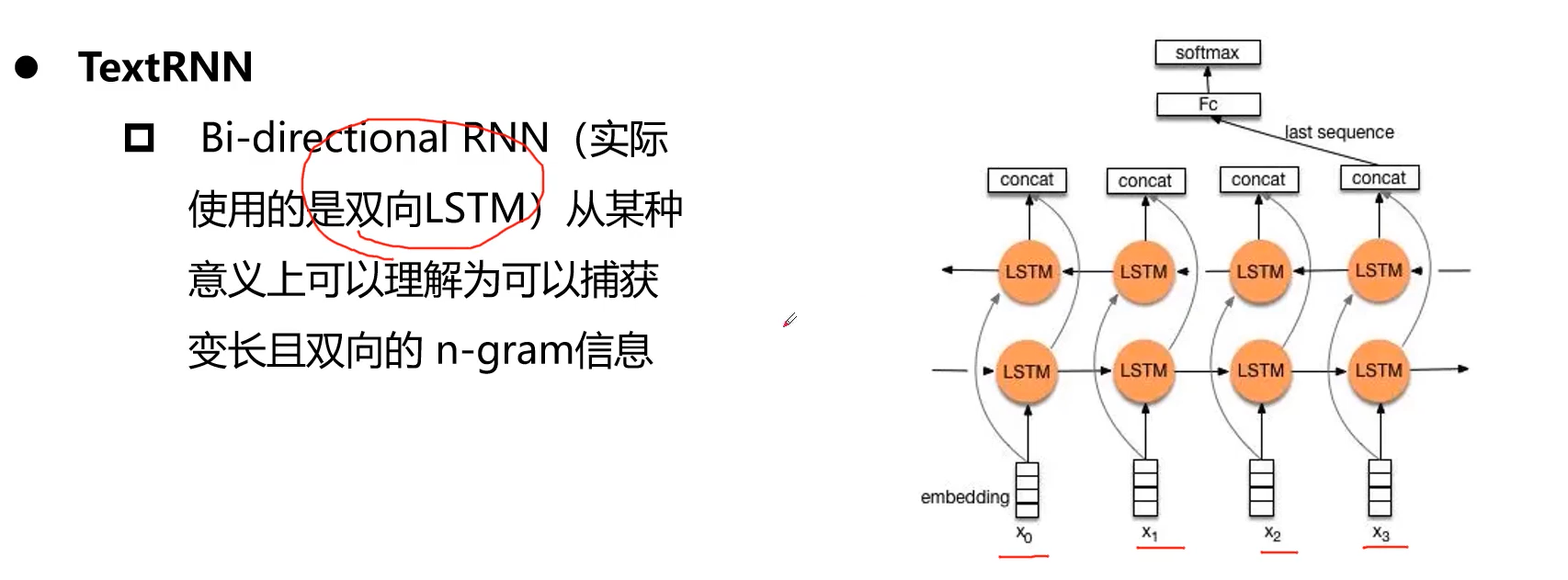
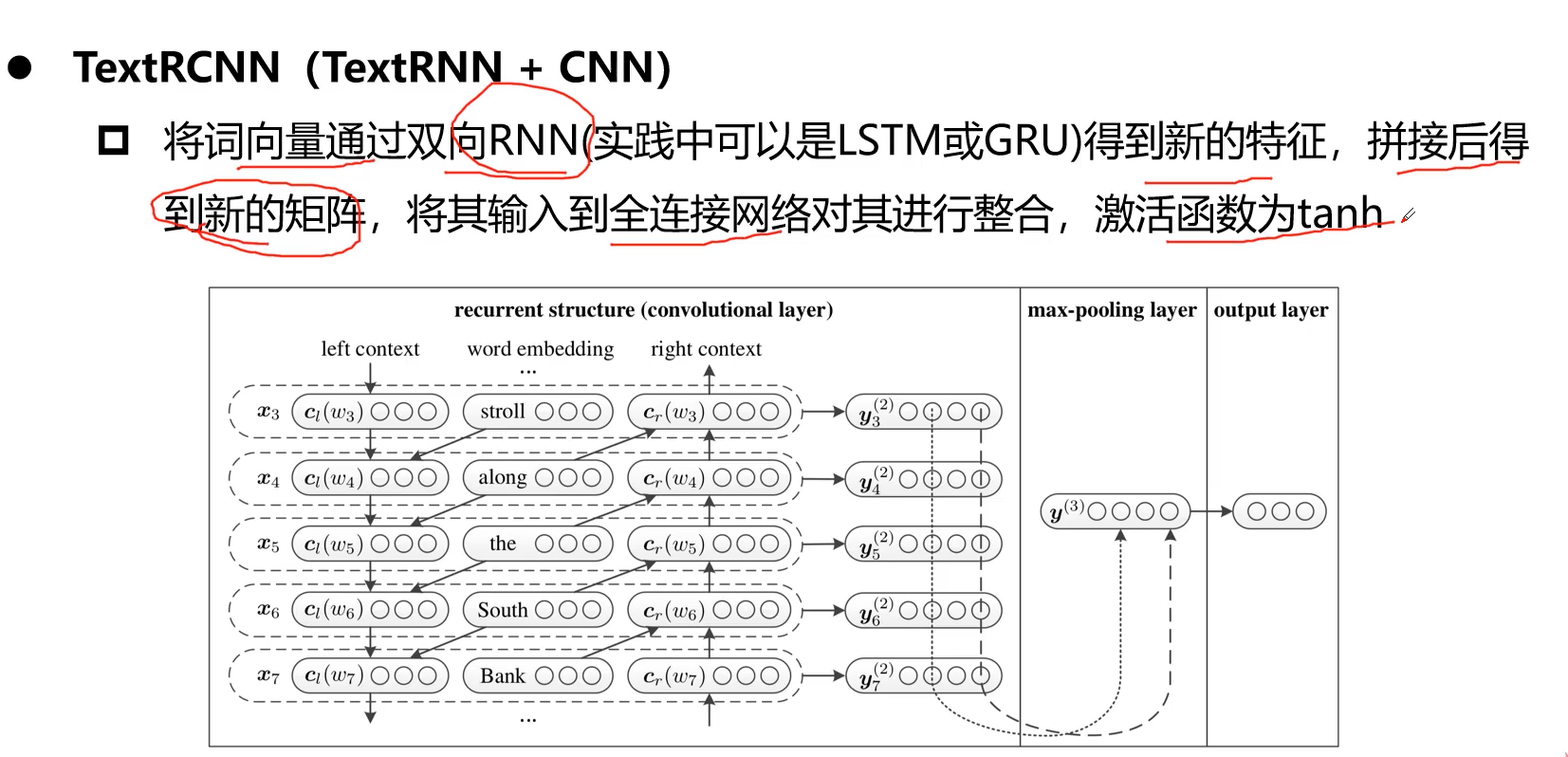
本文采用TextRCNN

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/417417
推荐阅读
相关标签

