
- 1考研复试操作系统_os用户态就绪钛
- 2多线程八股文常见面试题总结(一)
- 3【ACM模式】牛客网ACM机试模式Python&Java&C++主流语言OJ输入输出案例代码总结
- 4Xilinx IP核 Block Memory Generator v8.4 的使用
- 5【导读】后门学习新基准!BackdoorBench目前已集成了9种攻击方法、12种防御方法、5种分析工具,leaderboard公布了8000组攻防结果!
- 6Hbase和hive单机安装及环境配置_hbase和hive单独装
- 7ios html跳转appstore,iOS 获取appStore的链接地址,从app中跳转 appStore中应用
- 8SpringBoot 自定义注解+AOP+Redis 防止接口重复提交表单数据_springboot处理多次点击
- 9【RocketMQ】安装与部署(Windows)_please set the rocketmq_home variable in your envi
- 10Git - No such remote ‘origin‘(git remote set-url origin ‘xxx.git‘)
MySQL基础知识——MySQL事务
赞
踩
事务背景
什么是事务?
一组由一个或多个数据库操作组成的操作组,能够原子的执行,且事务间相互独立;
简单来说,事务就是要保证一组数据库操作,要么全部成功,要么全部失败。
注:MySQL是一个支持多引擎的系统,并不是所有的引擎都支持事务。
提到事务,你肯定会想到ACID(Atomicity、 Consistency、 Isolation、 Durability),那么什么是ACID呢?
- 原子性(Atomicity):事务中的操作全部执行,或一个也不执行;
- 隔离性(Isolation):事务的执行独立于其它事务,互不影响;(影响程度根据隔离级别而定)
- 持久性(Durability):事务中的操作完成,则对数据库的影响不会变更,持久保存;
- 一致性(Consistency):事务执行的结果是可预期的,同样的输入一定得出同样的输出;
保证数据一致性,是事务操作的最终目的(AID皆为此);
隔离性与隔离级别
当数据库上有多个事务同时执行的时候, 就可能出现脏读(dirtyread) 、 不可重复读(non-repeatable read) 、 幻读( phantom read) 的问题, 为了解决这些问题, 就有了“隔离级别”的概念。
在谈隔离级别之前, 你首先要知道, 隔离得越严实, 效率就会越低。 因此很多时候, 我们都要在二者之间寻找一个平衡点。
下面对SQL标准的事务隔离级别进行逐一介绍(隔离性由低到高):
- 读未提交(read uncommitted): 一个事务还没提交时, 它做的变更就能被别的事务看到。
- 读提交(read committed): 一个事务提交之后, 它做的变更才会被其他事务看到。
- 可重复读(repeatable read): 一个事务执行过程中看到的数据, 总是跟这个事务在启动时看到的数据是一致的。 当然在可重复读隔离级别下, 未提交变更对其他事务也是不可见的。
- 串行化(serializable): 顾名思义是对于同一行记录, “写”会加“写锁”, “读”会加“读锁”。 当出现读写锁冲突的时候, 后访问的事务必须等前一个事务执行完成, 才能继续执行。
其中“读提交”和“可重复读”比较难理解,下面用一个例子说明这几种隔离级别。
假设数据表T中只有一列, 其中一行的值为1, 下面是按照时间顺序执行两个事务的行为。
- mysql> create table T(c int) engine=InnoDB;
- insert into T(c) values(1);

接下来,我们看一下在不同隔离级别下,事务A会有哪些不同的返回结果:
- 若隔离级别是“读未提交”, 则V1的值就是2。 这时候事务B虽然还没有提交, 但是结果已经被A看到了。 因此, V2、 V3也都是2。
- 若隔离级别是“读提交”, 则V1是1, V2的值是2。 事务B的更新在提交后才能被A看到。 所以, V3的值也是2。
- 若隔离级别是“可重复读”, 则V1、 V2是1, V3是2。 之所以V2还是1, 遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。
- 若隔离级别是“串行化”, 则在事务B执行“将1改成2”的时候, 会被锁住。 直到事务A提交后,事务B才可以继续执行。 所以从A的角度看, V1、 V2值是1, V3的值是2。
在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。
- 在“可重复读”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。
- 在“读提交”隔离级别下,这个视图是在每个SELECT语句开始执行的时候创建的。
注1:“读未提交”隔离级别下直接返回记录上的最新值,所以没有视图概念。而“串行化”隔离级别下直接使用加锁的方式来避免并发访问。
注2:不同数据库其默认隔离级别有所差异。Oracle默认隔离界别为“读提交”,因此对于一些从Oracle迁移到MySQL的应用,为保证数据库隔离级别的一致,需要把MYSQL隔离级别设为“读提交”,MySQL默认隔离级别为“可重复读”。
事务隔离的实现
下面以“可重复读”隔离级别为例,介绍事务隔离是怎么实现的。
在MySQL中,实际上每条记录在更新的时候都会记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态值。
假设一个值从1被按顺序改成了2、3、4,在回滚日志里面就会有类似下面的记录:

记录当前值是4,在查询记录时,不同时刻启动的事务会有不同的read-view。在视图A、B、C里面,这一个记录的值分别是1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC);对于read-view A,要得到1,就必须将当前值依次执行图中所有的回滚操作得到。
同时你会发现, 即使现在有另外一个事务正在将4改成5, 这个事务跟read-view A、 B、 C对应的事务是不会冲突的。
问:回滚日志什么时候删除?
当没有事务再需要用到这些回滚段日志时,回滚日志会被删除。即当系统里没有比这个回滚日志更早的read-view的时候。(换句话说,回滚日志一般在当前视图所在事务中才会被用到)
问:为什么建议尽量不要使用长事务?
1)长事务表示系统存在很老的事务视图。这些事务可能访问数据库的任何数据,所以事务提交前,可能用到的回滚记录必须保留,导致回滚记录占用大量存储空间;
2)回滚日志跟数据字典一起放在ibdata文件中,即使长事务提交,回滚段被清理,文件也不会变小。我见过数据只有20GB,而回滚段有200GB的库。最终只好为了清理回滚段,重建整个库。( MySQL
3)长事务还占用锁资源,也可能拖垮整个库;
问:为避免长事务,业务开发和DBA分别应该采取哪些措施?
业务侧:
1)去掉没必要的事务,比如查询语句;
2)设置SQL执行超时时间;
DBA侧:
1)监控 information_schema.Innodb_trx表,设置长事务阈值,超过就报警/或者kill;
2)Percona的pt-kill这个工具不错,推荐使用;
3)在业务功能测试阶段要求输出所有的general_log,分析日志行为提前发现问题;
4)把innodb_undo_tablespaces设置>=2,出现大事务导致回滚段过大,方便清理。(MySQL >= 5.6)
事务的启动方式
autocommit用于决定是否开启事务自动提交:
1)autocommit=0
- 手动提交,当用户执行start transaction/begin时(事务初始化),一个事务开启,当用户执行commit命令时当前事务提交。从用户执行start transaction命令到用户执行commit之间的一系列操作为一个完整的事务周期。回滚事务使用rollback命令;
- 如果为显式通过start transaction/begin开启事务,则会在执行SQL时自动开启一个事务,但不提交;
2)autocommit=1
- 若用户未执行start transaction/begin对数据库进行操作,系统默认用户对数据库的每一个操作为一个孤立的事务,也就是说用户每进行一次操作系都会即时提交或者即时回滚。这种情况下用户的每一个操作都是一个完整的事务周期。
- 若显式执行start transaction/begin,则需要显式提交;情况同autocommit=0;
注:有些客户端连接框架会默认连接成功后先执行一个set autocommit=0的命令。这可能导致接下来的查询都在事务中,如果是长连接,就可能导致了意外的长事务;比如Java的Spring框架,可以显式告诉驱动,是否在事务环境中执行语句。
问:事务在什么时候会被隐式提交?
1)当设置autocommit = 1时,对于已经开启但是未提交的事务,若遇到DDL/begin/lock table/unlock table等语句时,会自动提交上一个事务;
2)当设置autocommit = 0时,对于已经开启但是未提交的事务,若遇到DDL/begin/lock table/unlock table等语句时,会自动回滚上一个事务;
MVCC实现
MVCC在InnoDB引擎层基于read view实现。
问:什么是事务ID?
1)引擎层用于唯一标识事务的ID,在事务开始时由InnoDB事务系统分配,按申请顺序严格递增;越早发起的事务,事务ID越小;
2)begin/start transaction命令不是InnoDB事务的起点,故不会生成事务ID;直到执行变更InnoDB表的语句,才会生成事务ID;
问:什么是数据版本?
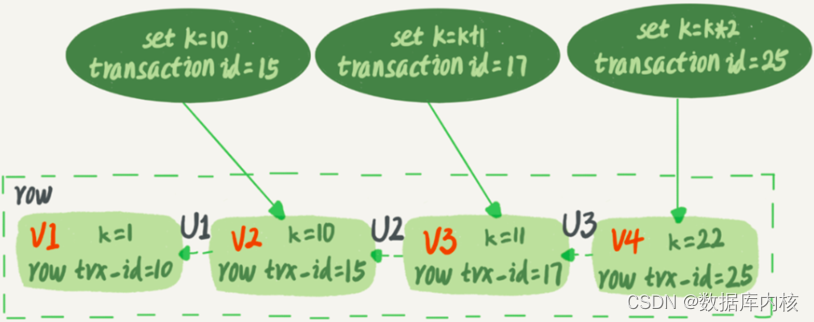
1)每行数据有多个版本,按照事务ID倒序排列,每次事务更新数据时,会生成一个新的数据版本,并在版本中记录事务ID,即row trx_id;
2)数据表中的一行记录,可能有多个版本(row),每个版本有自己的row trx_id,可通过遍历拿到对应trx_id的版本;
3)数据版本存放在undo log中,每次查询时根据当前版本和undo log向前推算得出结果。比如,查询V2时,通过V4依次执行V3、V2算出来;
MVCC 并发控制原理详见:MVCC 并发控制原理-源码解析(非常详细)-CSDN博客

