
- 1selenuim&echarts——可视化分析csdn新星赛道选手展示头像、展示ip城市和断言参赛信息的有效性(进阶篇)
- 2学透Spring Boot — 005. 深入理解 Spring Boot Starter 依赖管理
- 3通过外网访问linux ubuntu主机服务器的设置流程_ufw \\访问linux服务器
- 4分布式 - Redis中有哪些数据结构及底层实现原理_redis属于计算机结构中的哪一级
- 5springboot对接rabbitmq并且实现动态创建队列和消费_javaspringbootmq消息队列
- 6AI大模型引领未来智慧科研暨ChatGPT自然科学高级应用
- 7【Github】PwGen用户友好的Web应用密码生成器
- 8IDEA忽略不必要提交的文件_idea提交时如何忽略文件
- 9蓝桥杯学习笔记 单片机CT107D 新驱动代码的使用._蓝桥杯单片机给的底层驱动怎么使用
- 10js日历代码_PHP实现日历签到,并实现累计积分功能
Java基础常见面试题总结_java 面试 csdn
赞
踩
梳理Java基础相关的面试题,主要参考《Java编程思想》(第四版, Bruce Eckel 著, 陈昊鹏 译)一书,其余部分整合网络相关内容。注意,关于JVM和Java并发编程的面试题因为内容较多,单独整理。
Java类型系统
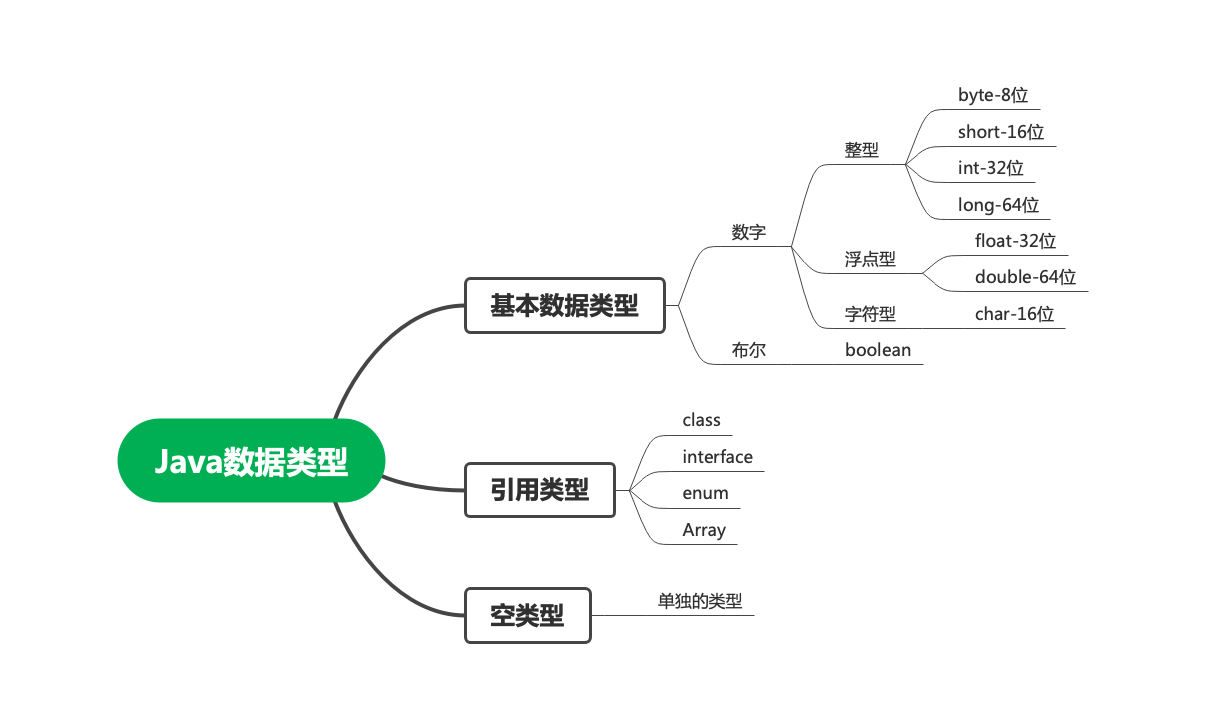
Java数据类型
Java的数据类型主要可以分为三类:基本数据类型(整型、浮点型、字符型、布尔型)、引用类型(Object类及其子类、接口、枚举、数组)、空类型。所以,从数据类型的角度来说,Java并不是严格的面向对象语言。图示如下:
浮点数精度丢失问题
Java语言在处理浮点数,其实现逻辑与整数不同,如果使用不当可能会造成精度丢失、计算不准确、死循环等问题,严重的话,会造成经济损失。本文将从浮点数精度丢失入手,详细介绍下浮点数的原理及使用。
(1) 为什么会出现精度丢失
计算机使用二进制存储数据,由于二进制自身局限性,导致其无法精确的表示所有小数。而浮点数是由整数部分和小数部分组成,这也就意味着,计算机无法精确表示浮点数。也即,在计算机中,浮点数存在精度丢失的问题。这里将以十进制小数转为二进制数为例,介绍下为何二进制无法精确表示小数。
十进制小数转换成二进制小数采用"乘2取整,顺序排列"的做法。基本思想如下:用二乘以当前十进制小数,然后将乘积的整数部分取出,如果乘积中的小数部分为零或者达到所要求的精度则停止计算。否则再用二乘以余下的小数部分,又得到一个乘积,再将积的整数部分取出,如此进行。完成计算后,把每次执行取出的整数部分按顺序排列起来,先取的整数作为二进制小数的高位有效位,后取的整数作为低位有效位。这里介绍下如何把十进制小数0.8125转换为二进制小数。

当然,也存在无法准确适用二进制表示的小数。如十进制小数0.7。

对于无法用二进制表示的小数,只能根据精度近似的表示。
(2) 浮点数底层存储实现
与整数存储数值不同,浮点数在计算机的存储时,会拆分成是三个部分:符号位、指数位、尾数位。其抽象公式是:
(
−
1
)
S
∗
(
1.
M
.
.
.
)
∗
2
E
(-1)^S*(1.M...)*2^E
(−1)S∗(1.M...)∗2E
其中,
S
S
S表示符号(正数、负数)、E表示指数、M表示尾数。在Java中,float是32位存储,double是64存储,各部分的存储长度是:
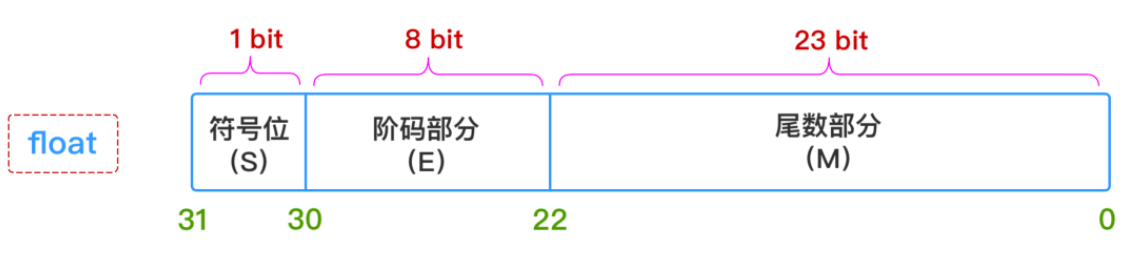
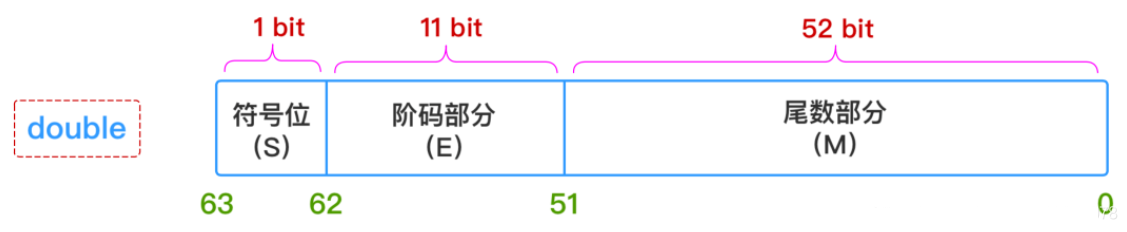 因为指数位影响数的大小,指数位决定大小范围。而小数位则决定计算精度,小数位能表示的数越大,则能计算的精度越大。
因为指数位影响数的大小,指数位决定大小范围。而小数位则决定计算精度,小数位能表示的数越大,则能计算的精度越大。
float 的小数位只有 23 位,即二进制的 23 位,能表示的最大的十进制数为 2 的 23 次方,即 8388608,即十进制的 7 位,严格点,精度只能百分百保证十进制的 6 位运算。
double 的小数位有 52 位,对应十进制最大值为 4 503 599 627 370 496,这个数有 16 位,所以计算精度只能百分百保证十进制的 15 位运算。
(3) 浮点数操作
既然浮点数不能精确表示小数,那么在执行浮点数操作时(算数运算、比较运算等),要考虑精度丢失可能带来的问题。这里以浮点数比较为例,介绍两个浮点数比较带来的死循环问题。
public void createEndlessLoop() {
double a = 1.6;
double b = 0.3;
double c = a + b;
double d = 1.9;
while (c != d) {
System.out.println("c: " + c + ", d: " + d);
}
System.out.print("c == d");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
执行上述方法,该方法将进入到死循环。浮点数的比较,由于精度丢失问题,其比较结果常常与预期相左。一种基本的思路是引入误差来辅助浮点数比较,但是这种做法仍不能满足某些场景。更多该思路的拓展可以参考链接。
(4) 如何避免精度丢失
那么如何避免浮点数的精度丢失问题。其实这个问题没有银弹。要根据不同的业务场景,选择合适的处理方式。如果可以不对浮点数进行运算,则尽量不使用浮点数进行运算。如果必须使用浮点数进行运算,要根据场景,选择合适的处理方式。如浮点数四则运算场景,使用BigDecimal。浮点数比较,引入误差阈值。上一个问题的正确处理方式如下:
public void createEndlessLoopWithBigDecimal() {
BigDecimal a = new BigDecimal("1.6");
BigDecimal b = new BigDecimal("0.3");
BigDecimal c = a.add(b);
BigDecimal d = new BigDecimal("1.9");
while (c.doubleValue() != d.doubleValue()) {
System.out.println("c: " + c.doubleValue() + ", d: " + d.doubleValue());
}
System.out.print("c == d");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注意,这里并没有使用形如"BigDecimal a = new BigDecimal(1.6);"的方式初始化BigDecimal实例,这是因为浮点数无法精确表示,所以使用BigDecimal(Double)创建的BigDecimal是可能损失了精度,其赋值结果可能和实际有差异。考虑下面的代码,将进入死循环。
public void createEndlessLoopWithBigDecimal() {
BigDecimal a = new BigDecimal(1.6);
BigDecimal b = new BigDecimal(0.3);
BigDecimal c = a.add(b);
BigDecimal d = new BigDecimal(1.9);
while (c.doubleValue() != d.doubleValue()) {
System.out.println("c: " + c.doubleValue() + ", d: " + d.doubleValue());
}
System.out.print("c == d");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
更多BigDecimal使用上的坑,可参考链接。
BigDecimal使用
浮点数使用计算机存储时,存在精度丢失的问题。如果遇到浮点数算术运算或比较运算时,一种推荐的做法是使用BigDecimal。
在使用BigDecimal进行浮点数运算时,根据阿里巴巴《Java开发手册》,有以下编程归约:
编程归约一:

编程归约二:

更多BigDecimal源码解析可以参考笔者之前的文章
类型转换
自动类型转换
强制类型转换
装箱与拆箱
装箱就是将基本数据类型转换成包装器类型时,要使用装箱机制。从Java SE5 提供自动装箱的特性。装箱主要执行如下操作:
(1) 在Java堆上分配内存。除了分配基本数据类型各个字段需要的内存,还需加上Java堆中每个对象都具备的成员(对象头、对齐信息等)。
(2) 将内存栈中基本数据类型的字段赋值到上述Java堆内存中。
(3) 返回对象的地址。基本数据类型转换成包装器类型,返回包装器类型的引用地址。
拆箱就是获取已装箱对象中各个字段的地址。拆箱针对装箱而言,没有装箱对象,也不会发现拆箱。拆箱仅能将数据转换成最初未装箱的类型。一次拆箱操作后,经常伴随着一次字段复制操作。所谓字段复制,就是指将基本数据类型对应的字段的值从Java堆复制到基于内存栈的值实例中。
装箱与拆箱实例示例代码如下:
int i = 1;
Integer a = i; //装箱
int j=(int)a; //拆箱
- 1
- 2
- 3
装箱拆箱只是类型转换的一种体现。装箱拆箱仅对于值类型和引用类型的转换而言。装箱拆箱是类型转换的真子集。拆箱只是强制类型转换的一种情况。
类型提升
在Java中,类型提升(Type Promotion)主要涉及到数值类型(如byte, short, char, int, long, float, double)。当进行数值运算时,Java会自动将较小的数值类型转换为较大的数值类型,以避免数据丢失和精度问题。这通常被称为自动类型转换或类型提升。(也就是说,Java中的类型提升都包含在自动类型转换中)
然而,对于引用类型(如类、接口和数组),Java并不支持类似数值类型的自动类型提升。引用类型之间的转换必须显式进行,并且需要满足一定的条件,比如子类到父类的转换(向上转型)是安全的,但父类到子类的转换(向下转型)则可能需要显式的类型检查(使用instanceof)或类型转换(使用强制类型转换)。
Object类简介
Java Object 类是所有类的父类,也就是说 Java 的所有类都继承了 Object,子类可以使用 Object 的所有方法。由于所有的类都继承在Object类,因此省略了extends Object关键字。
注意,严格意义上来说,基本数据类型并不继承自Object。这主要是出于性能方面的考虑。(换言之,对boolean、int、double等数据类型使用基本类型,其目的是为了提高性能)
(1) clone方法
clone方法是一个保护方法,用于实现对象的浅复制。注意,只有实现了Cloneable接口才可以调用该方法,否则抛出 CloneNotSupported Exception异常。
(2) getClass方法
getClass方法是一个final方法,该方法将返回表示该对象的实际类型的Class引用。getClass方法主要用在反射场景。
(3) toString方法
toString方法用于返回对象的字符串表示,该方法用得比较多(如获取对象的序列化表示),一般子类都有覆盖。
(4) equals方法和hashCode方法
Object类中定义equals方法,其初始行为是比较对象的内存地址。在实际应用中,经常重写equals方法。在重写equals方法时,一定要重写hashCode方法。这是因为,在哈希表容器(如Hashtable、HashMap等)时,会先比较哈希码,只有在哈希码相等的情况下,才会进一步equals方法判断是否相等(这主要考虑equals方法带来的性能问题)。
(5) wait方法和notify方法和notifyAll方法
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。调用该方法后当前线程进入睡眠状态,直到以下事件发生:
1)其他线程调用了该对象的notify方法或notifyAll方法;
2)其他线程调用了interrupt中断该线程;
3)时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
notify方法可以唤醒在该对象上等待的某个线程,而notifyAll方法则可以唤醒在该对象上等待的所有线程。
(6) finalize方法
该方法用于释放资源。在GC准备释放对象所占用的内存空间之前,它将首先调用finalize()方法。
不推荐使用finalize方法或重写finalize方法。这主要是因为,在Java中,GC主要是自动回收,因而并不能保证finalize方法会被及时地执行(垃圾对象的回收时机具有不确定性),也不能保证它们会被执行(假设程序由始至终都未触发垃圾回收)。由于finalize()方法的调用时机具有不确定性,从一个对象变得不可到达开始,到finalize()方法被执行,所花费的时间这段时间是任意长的,所以不能依赖finalize()方法能及时的回收占用的资源。如果在资源耗尽之前,GC却仍未触发,则finalize()方法将不会被执行。针对这种场景,通常的做法是提供显示的close()方法供客户端手动调用。
另外,重写finalize()方法意味着延长了回收对象时需要进行更多的操作,从而延长了对象回收的时间。
hashCode详解
当在集合中判断是否存在(包含)某元素时(执行containsXXX方法或put方法),可以使用equals方法实现。但如果元素过多,使用equals方法判断则会带来性能问题。
一种有效的方式是比较哈希值,这样就可以将一个元素用一个整数来代替。以HashMap为例,其实现流程如下:
(1) 添加一个元素时,使用其哈希码计算内部数组的索引(即所谓的桶)
(2) 如果不相等元素有相同的哈希码,那么他们在同一个桶上并且捆绑在一起,如通过列表处理哈希冲突。
(3) 当进行contains操作时,使用带查找元素的哈希码计算出桶值(索引值),如果对应索引值不存在元素,则直接返回,否则对实例进行equals比较。
使用这种方式,可以大大减少equals的执行次数。
相等的元素一定具有有相同的哈希值。其逆反命题是:哈希码不同,则对应的元素一定不同。
所以,在重写equals方法时,一定要重写hashCode方法。
HashCode 生成
Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。
HashCode 准则
hashCode通用约定:
(1) 调用运行Java应用程序中的同一对象,hashCode方法必须始终返回相同的整数。这个整数不需要在不同的Java应用程序中保持一致。
(2) 根据equals(Object)的方法,如果两个对象是相等的,两个对象调用hashCode方法必须产生相同的结果。
(3) 根据equals(Object)的方法,如果两个对象是不相等的,那么两个对象调用hashCode方法并不一定产生不同的整数的结果。
Object的hashCode方法是一个native方法,注释中描述hashCode返回的是由对象存储地址转化得到的值。
public native int hashCode();
- 1
这里记录Java源码(Java 8)实现:
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0 ;
if (hashCode == 0) {
// 根据Park-Miller伪随机数生成器生成的随机数
value = os::random() ;
} else if (hashCode == 1) {
// 此类方案将对象的内存地址,做移位运算后与一个随机数进行异或得到结果
intptr_t addrBits = cast_from_oop<intptr_t>(obj) >> 3 ;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ;
} else if (hashCode == 2) {
value = 1 ; // 返回固定的1
} else if (hashCode == 3) {
value = ++GVars.hcSequence ; // 返回一个自增序列的当前值
} else if (hashCode == 4) {
value = cast_from_oop<intptr_t>(obj) ; // 对象地址
} else {
// 通过和当前线程有关的一个随机数+三个确定值
unsigned t = Self->_hashStateX ;
t ^= (t << 11) ;
Self->_hashStateX = Self->_hashStateY ;
Self->_hashStateY = Self->_hashStateZ ;
Self->_hashStateZ = Self->_hashStateW ;
unsigned v = Self->_hashStateW ;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ;
Self->_hashStateW = v ;
value = v ;
}
value &= markOopDesc::hash_mask;
if (value == 0) value = 0xBAD ;
assert (value != markOopDesc::no_hash, "invariant") ;
TEVENT (hashCode: GENERATE) ;
return value;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
String中重写hashCode实现如下:
/* The hash code for a
* {@code String} object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
*/
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
String类简介
Java 使用 String 类代表字符串。Java 中的所有字符串字面值(如 “abc” )都使用此类实现。字符串是常量;它们的值在创建之后不能更改。字符串缓冲区支持可变的字符串。因为 String 对象是不可变的,所以可以共享。
String的不可变性
在Java中,String是不可变的,这主要体现在三个方面:(1)String类使用final关键字修饰,表示其不可继承;(2)String类使用字节数组存储数据,且使用final关键字修饰,表示该字段创建后引用地址不可变;(3)该字符数组的访问权限为 private,表示外部无法访问,且 String 没有对外提供可以修改该属性的方法。关键源码如下:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
@Stable
private final byte[] value;
// ...
}
- 1
- 2
- 3
- 4
- 5
- 6
注意,字符串的底层实现使用字节数组存储。使用字节数字而非字符数组的好处是,字节数组与数据的底层存储保持一致,无需额外转换。使用字节数组,保证使用指定的编码、解码方式,屏蔽了底层设备的差异。对于网络传输场景,无需进行额外的转换(网络数据传输使用字节流)。
将String设计成不可变,主要有以下方面的考虑:
(1) 出于性能方面的考虑。可以实现多个变量引用堆内存中的同一个字符串实例,避免创建的开销。因为String太过常用,JAVA类库的设计者在实现时做了个小小的变化,即采用了享元模式,每当生成一个新内容的字符串时,他们都被添加到一个共享池中,当第二次再次生成同样内容的字符串实例时,就共享此对象,而不是创建一个新对象,注意,这种方式仅适用于"="操作符创建的String对象。
(2) 出于安全方面的考虑。由于String的不可变性,可以确保创建后不会被篡改(当然,这也不是绝对,使用反射仍可修改对象的值)。
(3) 防止内存泄露。HashMap 的 key 为String类型,如果String对象可变,则会造成该key无法手动删除,从而造成内存泄露。
(4)出于并发安全的考虑。由于String的不可变性,多个线程可以安全的共享String对象,则不用担心被修改。
String的创建
在创建String实例的时候,根据是否使用运算符创建,可以将其分为两类:(1) 直接赋值创建字符串;(2)使用构造方法创建字符串。
(1) 直接赋值创建字符串
直接赋值创建字符串就是使用运算符直接赋值,可以使用的运算符有等号和加号。示例代码如下:
String strWithEqualOperator = "foo";
String strWithAddOperator = strWithEqualOperator + "test";
- 1
- 2
直接赋值创建字符串时,会优先从字符串常量池中获取已存在的字符串,如果不存在,则会将新生成的字符串添加到常量池,方便下次使用。字符串常量池是享元模式的具体应用,后面会进一步介绍。
注意,这里使用"+"运算符的语法,在Java编译阶段,会将变量替换成真实的字符串并完成拼接。
(2) 使用构造方法创建字符串
除了直接赋值创建字符串外,还可以使用构造方法创建字符串。String类支持多种场景的创建。如字节数组、字符数组、StringBuilder实例等,这里不再一一列举。
需要说明的是,使用构造方法创建字符串对象时,不会复用字符串常量池。如果两个字符串对象分别使用相同的字符串字面量由构造函数创建,且使用等号运算进行比较,因为是两个不同的对象,所以尽管其值相同,但不相等。示例如下:
String str1 = new String("foo");
String str2 = new String("foo");
// 打印false
System.out.println(str1 == str2);
- 1
- 2
- 3
- 4
所以,在进行字符串比较时,尽量使用equals方法,而不要使用相等运算符。
字符串的比较
针对字符串的相等比较有两种选择:使用==运算符和使用equals方法。对于Java语言来说,==运算符,对于“值类型”和“空类型”是比较他们的值;对于“引用类型”是是比较对象在内存中的存放地址,即是否指向指向同一个对象,且这种规则不可修改。对Object类的equals方法来说,其功能与 == 运算符一致,但是String类重写了该方法,使其可以进行值相等比较。关键源码如下:
public class Object {
//...
public boolean equals(Object obj) {
return (this == obj);
}
}
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
// ...
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String aString = (String)anObject;
// 优先比较hashCode是否相等
if (coder() == aString.coder()) {
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
}
return false;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
所以,在对字符串进行相等比较时,为了减少字符串底层存储的优化带来的可能影响,尽量使用equals方法。更多equals方法和==运算符使用细节上的差异,可以参考笔者之前的文章。
除了相等比较,String类还实现了Comparable接口,支持自定义比较。关键代码如下:
public int compareTo(String anotherString) {
byte v1[] = value;
byte v2[] = anotherString.value;
if (coder() == anotherString.coder()) {
return isLatin1() ? StringLatin1.compareTo(v1, v2)
: StringUTF16.compareTo(v1, v2);
}
return isLatin1() ? StringLatin1.compareToUTF16(v1, v2)
: StringUTF16.compareToLatin1(v1, v2);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
String、StringBuilder、StringBuffer、StringConcatFactory 简介
字符串操作是编码中经常进行的操作。
String 对象是不可变的对象, 因此每次对 String 改变,其实都等同于生成一个新的 String 对象,然后将指针指向新的 String 对象。所以对经常更变内容的字符串最好不要用 String 表示。
为简化字符串拼接,Java重写+操作符,使其支持字符串拼接。在String + 拼接的底层,是StringBuilder实现的,整个过程是StringBuilder append之后toString。(Java9 改成了invokedynamic,StringConcatFactory.makeConcatWithConstants)
StringBuffer是线程安全的,append等方法用synchronized修饰,1.0提供的接口。
使用 StringBuffer,每次字符串操作都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,然后改变对象引用。当字符串对象经常改变时,推荐使用StringBuffer。
java.lang.StringBuilder一个可变的字符序列是5.0新增的。此类提供一个与 StringBuffer 兼容的 API,但不保证同步。该类被设计用作 StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。如果可能,建议优先采用该类,因为在大多数实现中,它比 StringBuffer 要快。
Java 9 利用invokeDynamic调用StringConcatFactory.makeConcatWithConstants方法进行字符串拼接优化,相比于Java 8通过转换为StringBuilder来进行优化,Java 9 提供了多种STRATEGY可供选择,这些STRATEGY有BC_SB(等价于Java 8的优化方式)、BC_SB_SIZED、BC_SB_SIZED_EXACT、MH_SB_SIZED、MH_SB_SIZED_EXACT、MH_INLINE_SIZED_EXACT,默认是MH_INLINE_SIZED_EXACT。
String、StringBuilder、StringBuffer、StringConcatFactory的使用建议如下:
(1) 静态以及简单场景字符串拼接,使用+
(2) 循环拼接场景使用StringBuilder,如果是Java 9以上,换成StringConcatFactory。
(3) 集合转String等操作搭配stream、StringJoiner优雅实现
(4) String + 、Joiner、StringJoiner底层均为StringBuilder实现
(5) StringBuffer是线程安全版本的StringBuilder
(6) String + 拼接在静态字符串场景下编译器会优化,生成的字节码是拼接后的字符串
Java集合
Java数组(Array)
Java 语言的数组是用来存储固定大小的同类型元素。Java没有提供数组类,直接使用语言内置的声明方式即可。接下来将从数组的声明、创建、初始化、遍历等几个方面介绍Java中数组的使用。
数组的声明
使用数组前需要先声明一个数组。常见的数组有一维数组、二维数组和三维数组(使用频率更低)。示例代码如下:
// 声明一个一维数组
dataType[] arrayRefVar1;
// 声明一个二维数组
dataType[][] arrayRefVar2;
// 声明一个三维数组
dataType[][][] arrayRefVar3;
- 1
- 2
- 3
- 4
- 5
- 6
需要说明的是,Java也支持形如"dataType arrayRefVar[]"的方式。这种风格是来自 C/C++ 语言,不推荐使用这种风格。
数组的创建
声明一个数组并不会为该数组分配内存空间,还需创建数组。Java语言使用new操作符来创建数组,示例代码如下:
// 创建一个一维数组
arrayRefVar1 = new dataType[arraySize];
// 创建一个二维数组
arrayRefVar2 = new dataType[firstLevelSize][secondLevelSize];
// 创建一个三维数组
arrayRefVar3 = new dataType[firstLevelSize][secondLevelSize][thirdLevelSize];
- 1
- 2
- 3
- 4
- 5
- 6
当然,也可在声明数组的时候,创建数组。示例代码如下:
// 声明并创建一个一维数组
dataType[] arrayRefVar1 = new dataType[arraySize];
// 声明并创建一个二维数组
dataType[][] arrayRefVar2 = new dataType[firstLevelSize][secondLevelSize];
// 声明并创建一个三维数组
dataType[][][] arrayRefVar3 = new dataType[firstLevelSize][secondLevelSize][thirdLevelSize];
- 1
- 2
- 3
- 4
- 5
- 6
此外,Java语言支持声明时赋值初始化数据。示例代码如下:
// 声明并初始化一维数组
dataType[] arrayRefVar1 = {value0, value1, ..., valuek};
// 声明并初始化二维数组
dataType[][] arrayRefVar2 = {
{value00, value01,...,value0n,},
{value10, value11,...,value1n},
...,
{valuem0, valuem1,...,valuemn}
};
// 三维数组就是在二维数组的基础上,进一步赋值初始化数据,这里不再展示(使用较少)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
数组的遍历
数组的元素类型和数组的大小都是确定的,所以当遍历数组时,通常可以使用基本循环或者 For-Each 循环。示例如下:
int[] arrayRefVar1 = {1, 2, 3};
int[][] arrayRefVar2 = {
{1, 2, 3},
{4, 5, 6}
};
int[][][] arrayRefVar3 = {
{{1,2,3}, {4,5,6}, {7,8,9}},
{{10,11,12}, {13,14,15}, {16,17,18}},
{{19,20,21}, {21,22,23},{24,25,26}}
};
for (int i = 0; i < arrayRefVar1.length; i++) {
System.out.print(arrayRefVar1[i]);
}
System.out.println();
// JDK 1.5 引进的循环类型,被称为 For-Each 循环或者加强型循环,它能在不使用下标的情况下遍历数组
for (int element : arrayRefVar1) {
System.out.print(element);
}
System.out.println();
for (int i = 0; i < arrayRefVar2.length; i++) {
for (int j = 0; j < arrayRefVar2[i].length; j++) {
System.out.print(arrayRefVar2[i][j] + " ");
}
System.out.println();
}
System.out.println();
for (int i = 0; i < arrayRefVar3.length; i++) {
for (int j = 0; j < arrayRefVar3[i].length; j++) {
for (int k = 0; k < arrayRefVar3[i][j].length; k++) {
System.out.print(arrayRefVar3[i][j][k] + " ");
}
System.out.println();
}
System.out.println();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
需要注意的是,对于二维数组等多维数组(大于等于二维)来说,不一定包含其是规则的。那么什么是不规则的数组?以二维数组为例,如果数组中每一行的列数相同则其是规则的,如果每一行的列数并不完全相同,则其是不规则的。举例如下:
// 规则的二维数组
int[][] arrayRefVar1 = {
{1, 2, 3},
{4, 5, 6}
};
// 不规则的二维数组
int[][] arrayRefVar2 = {
{1, 2, 3},
{4, 5}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
对于不规则数组,要注意在使用时可能出现的数组越界问题(上述数组遍历的示例代码可兼容不规则的场景)。
List
List是经常使用的集合之一。List类层次结构如下:
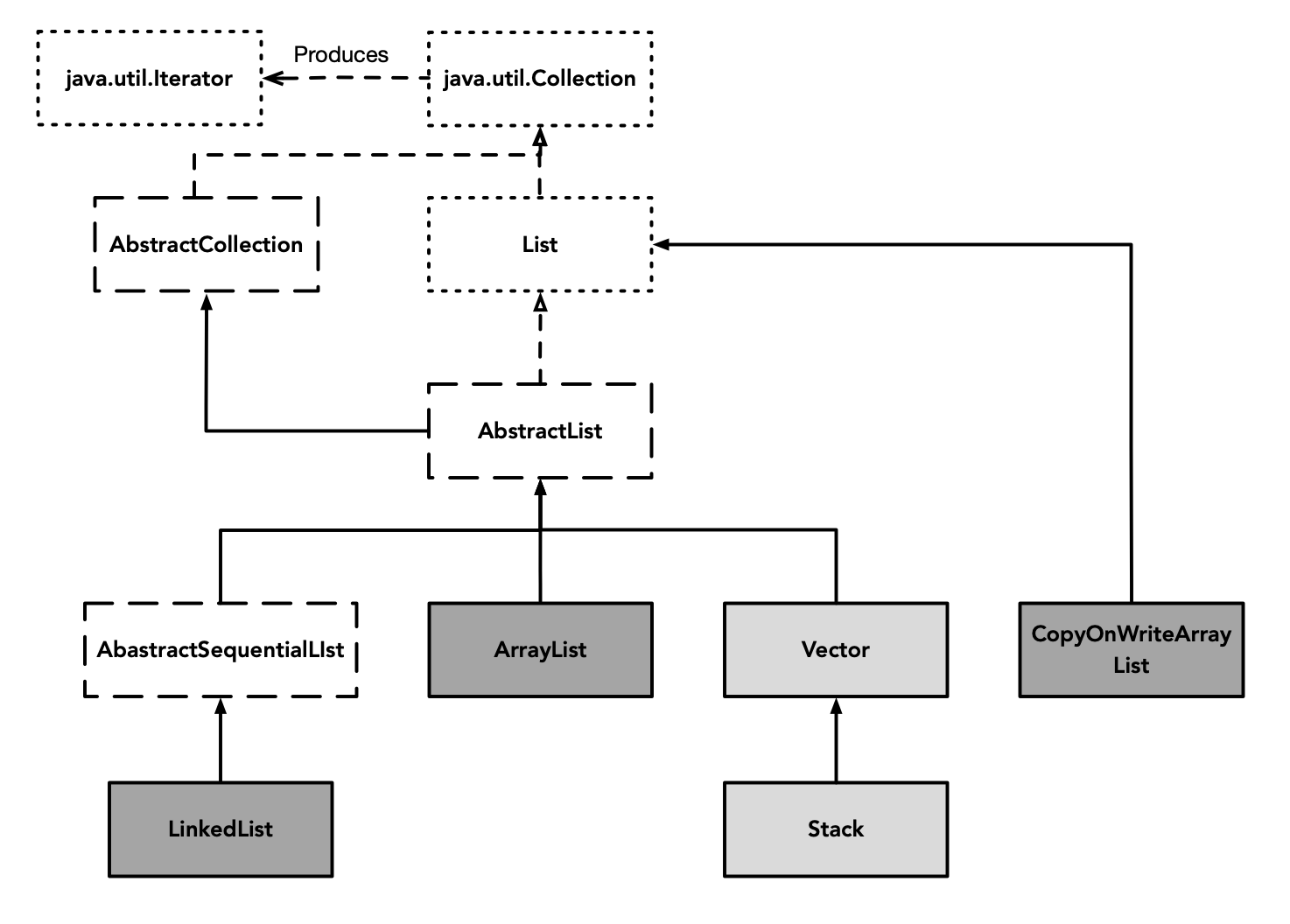
其中,Vector、Stack已弃用,仅具有历史意义,仅需了解其原理实现。在非线程安全场景下,可以选用ArrayList和LinkedList,对于线程安全场景,可以选用CopyOnWriteArrayList。
Vector
Vector是 JDK 1.0 版本提供的同步容器类,并在JDK 1.2中实现了Collection接口。随着JDK版本的不断更新,这个类已经逐渐被弃用。
1 Vector 基于动态数组实现
Vector 基于动态数组实现,其结构设计如下:
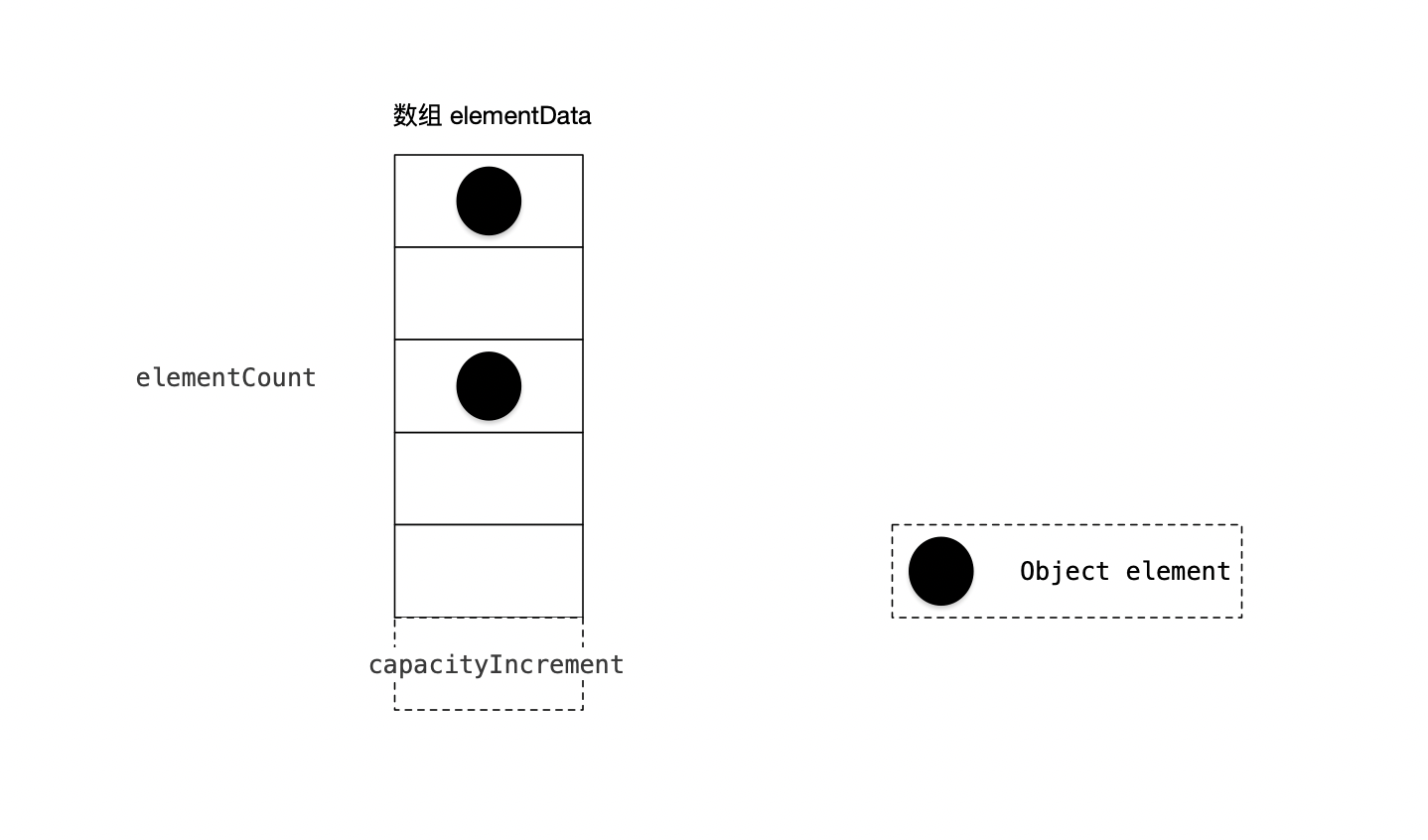
(1) Object[] elementData 数组保存添加到Vector中的元素。elementData是个动态数组,默认值大小10。随着Vector中元素的增加,Vector的容量也会,根据capacityIncrement动态增长。因为在扩容时,必须保证有连续的内存空间,所以会将原数据拷贝到新申请的内存空间中。
(2) elementCount 是数组的实际大小。
(3) capacityIncrement 是动态数组的增长系数。在创建Vector时,可指定capacityIncrement的大小。当capacityIncrement值小于等于0或者未设置时,Vector中将增长一倍(默认增长一倍)。
(4) Vector的克隆函数,会将全部元素克隆到一个数组中。
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity); // 将全部元素克隆到新数组
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2 Vector是线程安全
Vector作为同步容器类,通过将状态封住起来,并对每个公有方法进行同步,使得每次只有一个线程能够访问容器的状态(使用synchronized关键字修饰)。
代码示例如下:
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
protected Object[] elementData;
protected int elementCount;
protected int capacityIncrement;
// 公有方法均使用 synchronized 修饰
public synchronized int capacity() {
return elementData.length;
}
public synchronized int size() {
return elementCount;
}
// 其他公共方法
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3 Vector上某些复合操作存在非线程安全问题
Vector作为同步容器类无法保证“绝对线程安全”(同步容器类在执行某些场景的复合操作时,需要额外的客户端加锁来保护),且不支持并发操作。
容器上常见的复合操作有迭代(反复访问元素,主动遍历完容器中所有元素),跳转(根据指定顺序找到当前元素的下一个元素)以及条件运算,等等。 同步容器类中,容器被多个线程并发修改时,可能会出现意料之外的行为。实例如下:
对Vector 封装两个方法:getLast、deleteLast,都会“先检查再执行”操作。完整代码如下:
public static Object getLast(Vector vec){
int lastIndex=vec.size()-1;
return vec.get(lastIndex);
}
public static Object deleteLast(Vector vec){
int lastIndex=vec.size()-1;
return vec.remove(lastIndex);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
从方法调用的角度来看,如果线程A在10个元素中调用getLast,线程B调用deleteLast。当线程B在线程A读取lastIndex后执行时,线程A在执行getLast时,将抛出ArrayIndexOutOfBoundsException异常(数组越界)。
所以, 同步容器类要遵循同步策略,即客户端加锁。示例代码如下:
public static Object getLast(Vector vec){
synchronized(vec){
int lastIndex=vec.size()-1;
return vec.get(lastIndex);
}
}
public static Object deleteLast(Vector vec){
synchronized(vec){
int lastIndex=vec.size()-1;
return vec.remove(lastIndex);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Stack
Stack继承Vector,仅封装了部分Stack接口。关键源码如下:
public class Stack<E> extends Vector<E> {
public E push(E item) {
addElement(item);
return item;
}
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
ArrayList
ArrayList 是一个动态数组。与Java中的内置的数组相比,它的容量能动态增长。
ArrayList 继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
ArrayList 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们可以通过元素的序号快速获取元素对象;这就是快速随机访问。
1 ArrayList基于动态数组实现
ArrayList实现了动态数组功能。ArrayList基于数组实现了动态数组。相关定义如下:
transient Object[] elementData; // non-private to simplify nested class access
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 动态增长为原来的一半
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
相比于Map的增长一倍,ArrayList动态增长的长度是之前长度的一半。
ArrayList的默认长度是10。
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
- 1
- 2
- 3
- 4
因为是动态数组,所以ArrayList理论上不会出现数组越界的情况。
2 ArrayList是非线程安全
ArrayList是非线程安全,即任一时刻可以有多个线程同时写ArrayList,可能会导致数据的不一致。
LinkedList
LinkedList实现了Queue接口。LinkedList提供Stack操作接口。
1 LinkedList基于双链表实现
(1)LinkedList 使用 Node 存储节点信息
Node定义如下:
private static class Node<E> {
E item;
// 下一个节点
Node<E> next;
// 上一个节点
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(2)LinkedList可快速访问头节点和尾节点
LinkedList是基于链表实现,无法实现基于索引的快速查找。但是,LinkedList记录了头节点和尾节点的信息,可以快速的定位头尾节点。
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(3)LinkedList实现了双端队列接口
LinkedList实现了双端队列(Deque)接口,支持将其当做双端队列进行使用。
(4)LinkedList可作为队列使用
Java并未直接实现Queue的实体类,而是在LinkedList实现了Queue接口。
(5)LinkedList可作为栈使用
相比于基于Vector实现的Stack,LinkedList虽然不支持线程同步,但是非多线程场景下,其访问性能要高很多。所以非多线程场景下,LinkedList是栈的首选。
2 LinkedList是非线程安全
LinkedList非线程安全,即任一时刻可以有多个线程同时写LinkedList,可能会导致数据的不一致。
CopyOnWriteArrayList
CopyOnWriteArrayList是ArrayList的线程安全版本。CopyOnWriteArrayList是在有写操作的时候copy一份数据,然后写完再设置成新的数据。CopyOnWriteArrayList适用于读多写的并发场景。
1 使用COW技术+重入锁保证线程安全
CopyOnWriteArrayList使用了ReentrantLock来支持并发操作,array就是实际存放数据的数组对象。ReentrantLock是一种支持重入的独占锁,任意时刻只允许一个线程获得锁,所以可以安全的并发去写数组。对应成员变量如下:
// 重入锁保证写操作互斥
final transient ReentrantLock lock = new ReentrantLock();
// volatile保证读可见性
private transient volatile Object[] array;
- 1
- 2
- 3
- 4
向CopyOnWriteArrayList添加元素,可以发现在添加的时候是需要加锁的,否则多线程写的时候会Copy出N个副本出来。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 加锁,保证只有一个线程进入
lock.lock();
try {
// 获得当前数组对象
Object[] elements = getArray();
int len = elements.length;
// 拷贝到一个新的数组中
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 追加新元素
newElements[len] = e;
// 使用新数组对象更新当前数组的引用
setArray(newElements);
return true;
} finally {
// 解锁
lock.unlock();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
读操作时不需要加锁,如果读的时候有多个线程正在向ArrayList添加数据,读还是会读到旧的数据(可能出现脏读),因为写的时候不会锁住旧的ArrayList。
public E get(int index) {
return get(getArray(), index);
}
- 1
- 2
- 3
2 CopyOnWriteArrayList是线程安全
Map
Map是经常使用的集合之一。Map类层次结构如下:
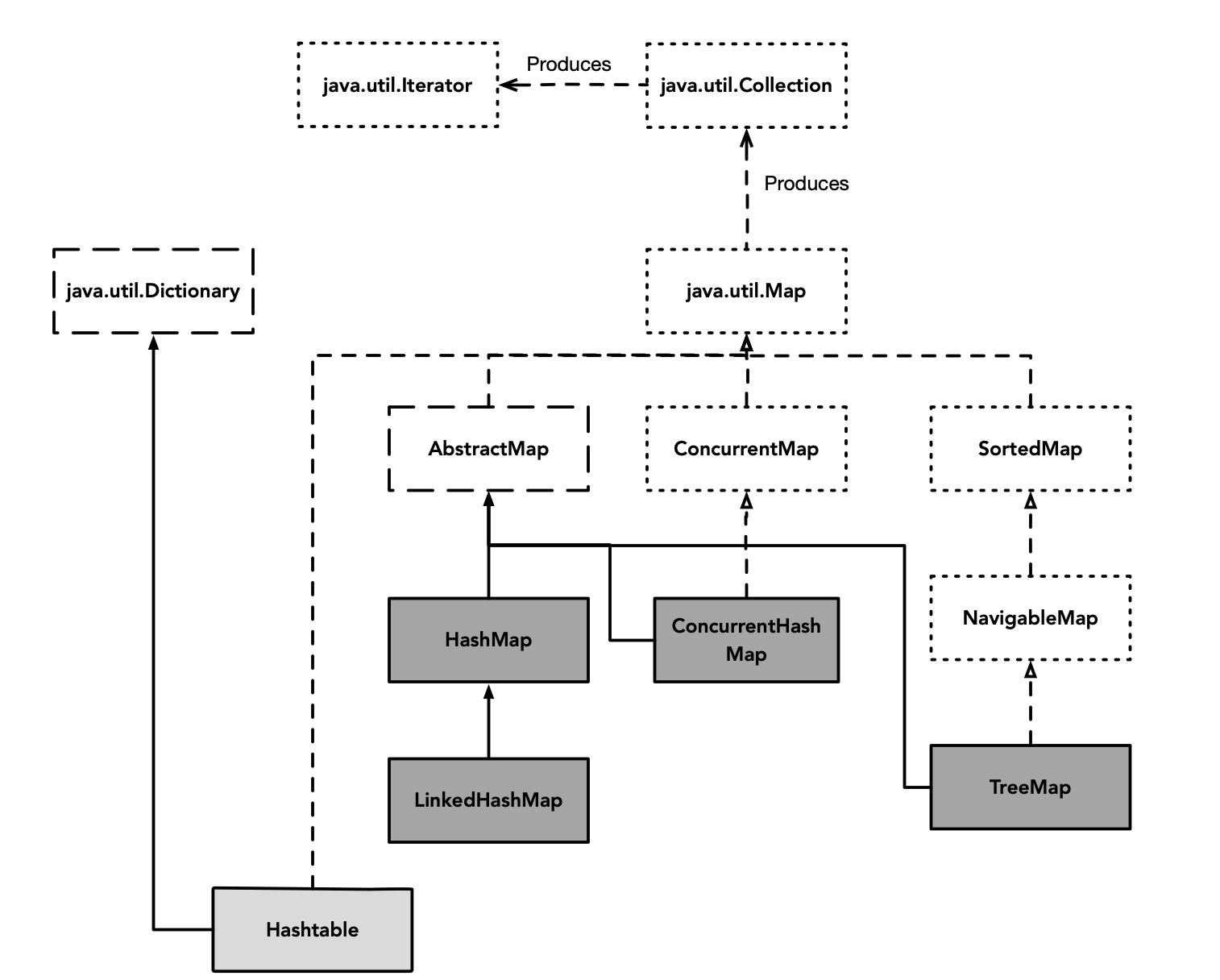
其中,Hashtable 已弃用,仅具有历史意义,仅需了解其原理实现。在非线程安全场景下,可以选用HashMap,对于线程安全场景,可以选用ConcurrentHashMap。如果需要保证插入有序或访问有序,可以选用LinkedHashMap。如果需要保证键的有序性,可以选用TreeMap。
Hashtable
Hashtable虽已弃用,但作为最早(JDK 1.1)的Map数据结构,分析其结构及实现仍有参考价值。Hashtable继承于Dictionary,实现了Map(从JDK 1.2开始)、Cloneable、java.io.Serializable接口。
1 Hashtable基于数组+链表(JDK1.2实现Map接口)实现
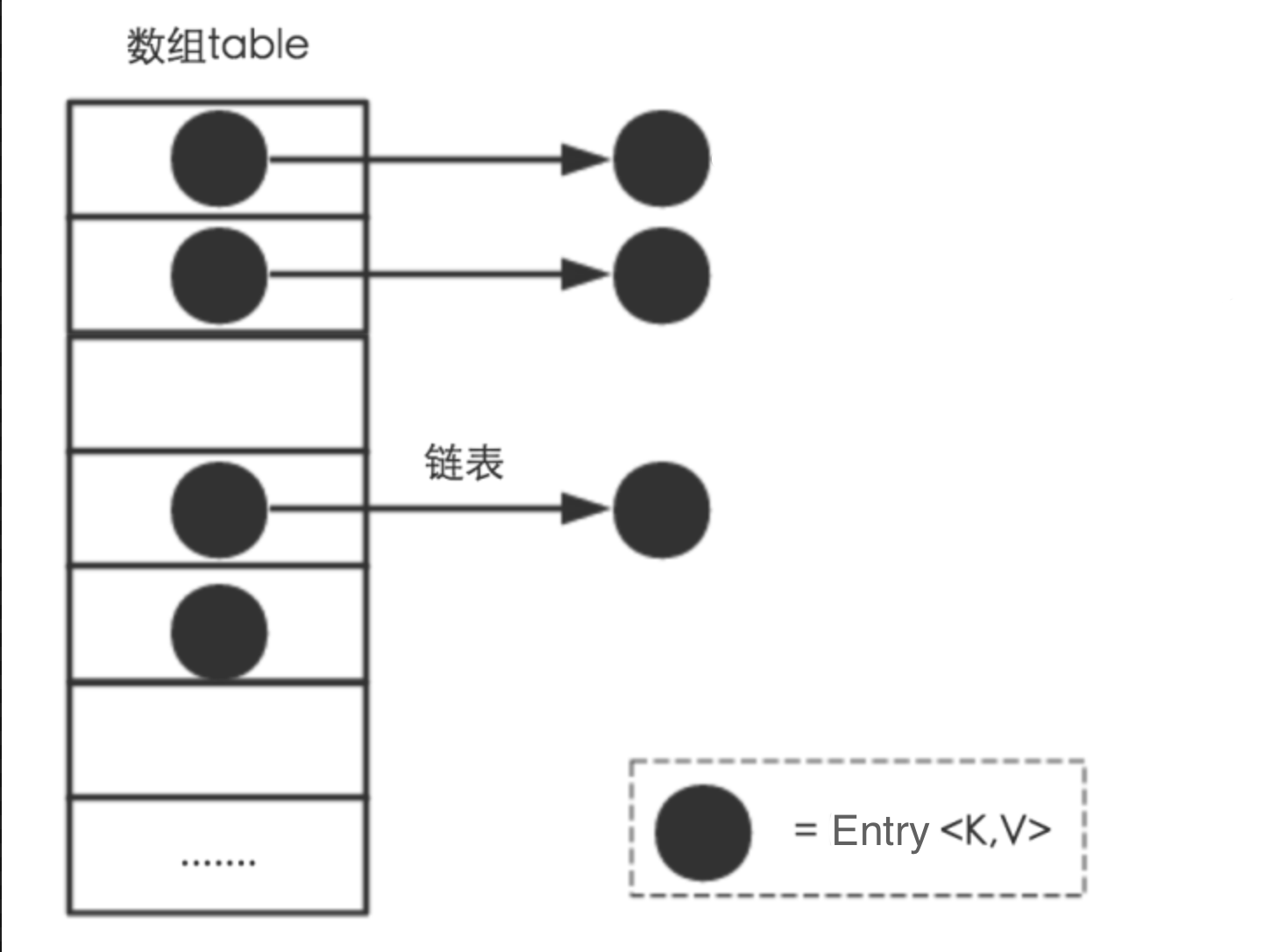
(1)Hashtable 使用 Entry[] table(哈希桶数组)存储键值对
Entry实体结构如下:
/**
* Hashtable bucket collision list entry
*/
private static class Entry<K,V> implements Map.Entry<K,V> {
// 用来定位数组索引位置
final int hash;
final K key;
V value;
// 链表的下一个entry, 使用链表处理哈希冲突
Entry<K,V> next;
protected Entry(int hash, K key, V value, Entry<K,V> next) { ... }
// Map.Entry Ops
public K getKey() { ... }
public V getValue() { ... }
public V setValue(V value) { ... }
public boolean equals(Object o) { ... }
public int hashCode() { ... }
public String toString() { ... }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
(2)Hashtable使用链表处理冲突
哈希表无法避免冲突。为解决冲突,Hashtable使用链地址法来解决问题(其他的处理冲突的方法还有:开放定址法、再哈希法、建立公共溢出区等)。链地址法,就是在每个数组元素上添加一个链表结构,当数据被Hash后,得到数组下标后,把数据放在对应下标元素的链表上。
(3)Hashtable支持自动化扩容(再哈希)
在 Hashtable 中 Entry[] table的初始化长度(length)默认值是11,负载因子(Load factor)默认值是0.75,最大容量(threshold)是Hashtable所能容纳的最大数据量的Entry(键值对)个数,threshold = length * Load factor。
当HashMap中存储数据超过 threshold,就需要执行rehash(再哈希),从而实现扩容,扩容后的HashMap容量是之前容量的两倍。再哈希源码如下:
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
// 使用newMap
table = newMap;
// 迁移oldMap中数据到newMap
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
注意,默认的负载因子0.75是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
另外,HashMap使用 size 表示实际存在的键值对数量。
2 Hashtable是线程安全
Hashtable线程安全,即任一时刻可以有多个线程同时写Hashtable时,不会出现数据不一致问题。由于Hashtable使用互斥同步策略实现的线程安全存在性能问题,所以多线程访问场景下使用ConcurrentHashMap替代。
HashMap
JDK1.8对HashMap底层的实现进行了优化,例如引入红黑树的数据结构和优化扩容实现等等。本文结合JDK1.7和JDK1.8的区别,深入探讨HashMap的结构实现和功能原理。
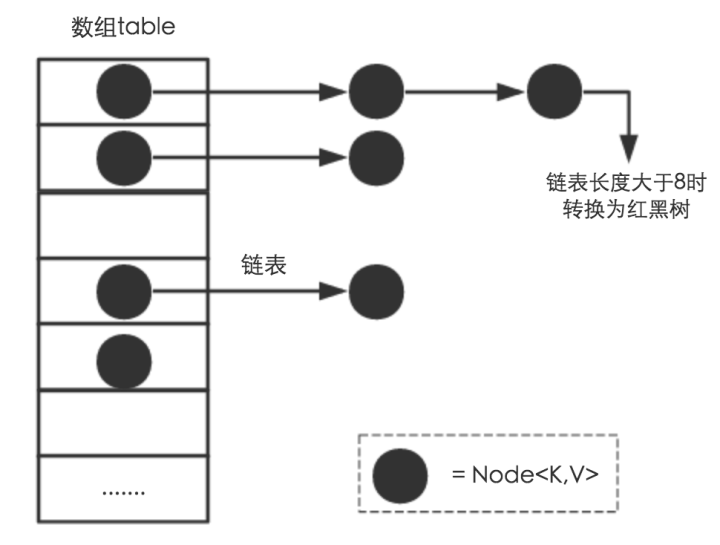
1 HashMap基于数组+链表+红黑树(JDK1.8增加红黑树部分)实现
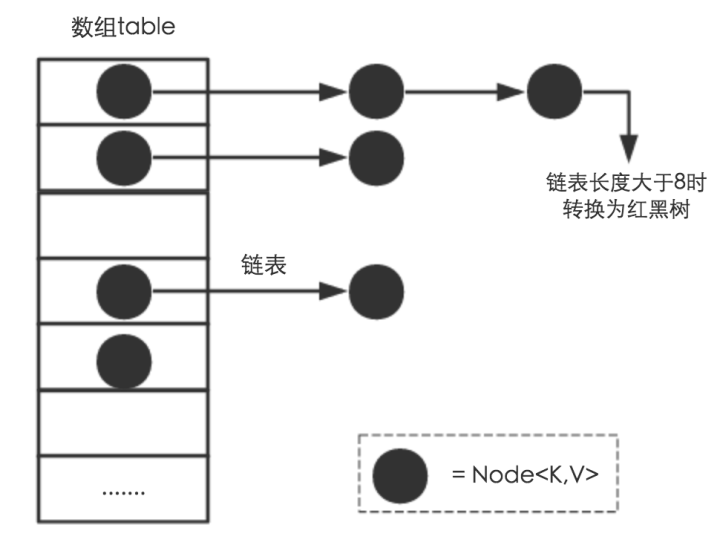
(1)HashMap 使用 Node[] table(哈希桶数组)存储键值对
Node实体结构如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node, 使用链表处理哈希冲突
Node(int hash, K key, V value, Node<K,V> next) { ... }
public final K getKey(){ ... }
public final V getValue() { ... }
public final String toString() { ... }
public final int hashCode() { ... }
public final V setValue(V newValue) { ... }
public final boolean equals(Object o) { ... }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(2)HashMap使用链表处理冲突
哈希表无法避免冲突。为解决冲突,HashMap使用链地址法来解决问题(其他的处理冲突的方法还有:开放定址法、再哈希法、建立公共溢出区等)。链地址法,就是在每个数组元素上添加一个链表结构,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上。
(3)HashMap使用红黑树解决链表过长的问题
即使负载因子(Load Factor)和Hash算法设计再合理,也无法避免会处理冲突的链表过长的问题。当链表过长时,会降低Hash的性能(从O(1)降到O(n))。为较少链表在这种场景下带来的性能问题,JDK1.8 引入红黑树。
当链表长度太长(TREEIFY_THRESHOLD = 8)时,链表就转换为红黑树。
红黑树是一种特殊的有序二叉树,其插入、删除、查找的时间复杂度位O(log N),因其支持自平衡,所以其性能在最坏场景下,要优于有序二叉树。更多红黑树数据结构的工作原理可以参考链接。
注意,红黑树size过小(UNTREEIFY_THRESHOLD = 6),红黑树将转化为链表。
(4)HashMap支持自动化扩容
在 HashMap 中 Node[] table的初始化长度(length)默认值是16,负载因子(Load factor)默认值是0.75,最大容量(threshold)是HashMap所能容纳的最大数据量的Node(键值对)个数,threshold = length * Load factor。
当HashMap中存储数据超过 threshold,就需要重新resize(扩容),扩容后的HashMap容量是之前容量的两倍。在HashMap中,table的长度length大小必须为2的n次方(一定是合数),这是一种非常规的设计,常规的设计是把桶的大小设计为素数。相对来说素数导致冲突的概率要小于合数,具体证明可以参考链接,Hashtable初始化桶大小为11,就是桶大小设计为素数的应用(Hashtable扩容后不能保证还是素数)。HashMap>采用这种非常规设计,主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap定位哈希桶索引位置时,也加入了高位参与运算的过程。
注意,默认的负载因子0.75是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
另外,HashMap使用 size 表示实际存在的键值对数量。
2 HashMap是非线程安全
HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法包装HashMap,使其具有线程安全的能力,或者使用ConcurrentHashMap。
ConcurrentHashMap
通过使用并发容器替换同步容器,可以极大的提升伸缩性(随着并发数量的增加,平均响应时间逐渐稳定下来)并降低风险。
ConcurrentHashMap继承于AbstractMap(和HashMap一致),并实现了ConcurrentMap接口。
1 ConcurrentHashMap基于数组+链表+红黑树(JDK1.8增加红黑树部分)实现
ConcurrentHashMap在JDK 1.5中引入,在JDK 1.8对其进行优化。两个版本中,ConcurrentHashMap使用的数据结构和HashMap一致。只是并发处理实现不同。
接下来重点介绍ConcurrentHashMap在JDK 1.5 和 JDK 1.8中实现。
(1) 基于分段锁机制的数据共享
JDK 1.5 使用分段锁(Lock Striping)技术实现更细粒度的加锁机制实现更大程度的共享。
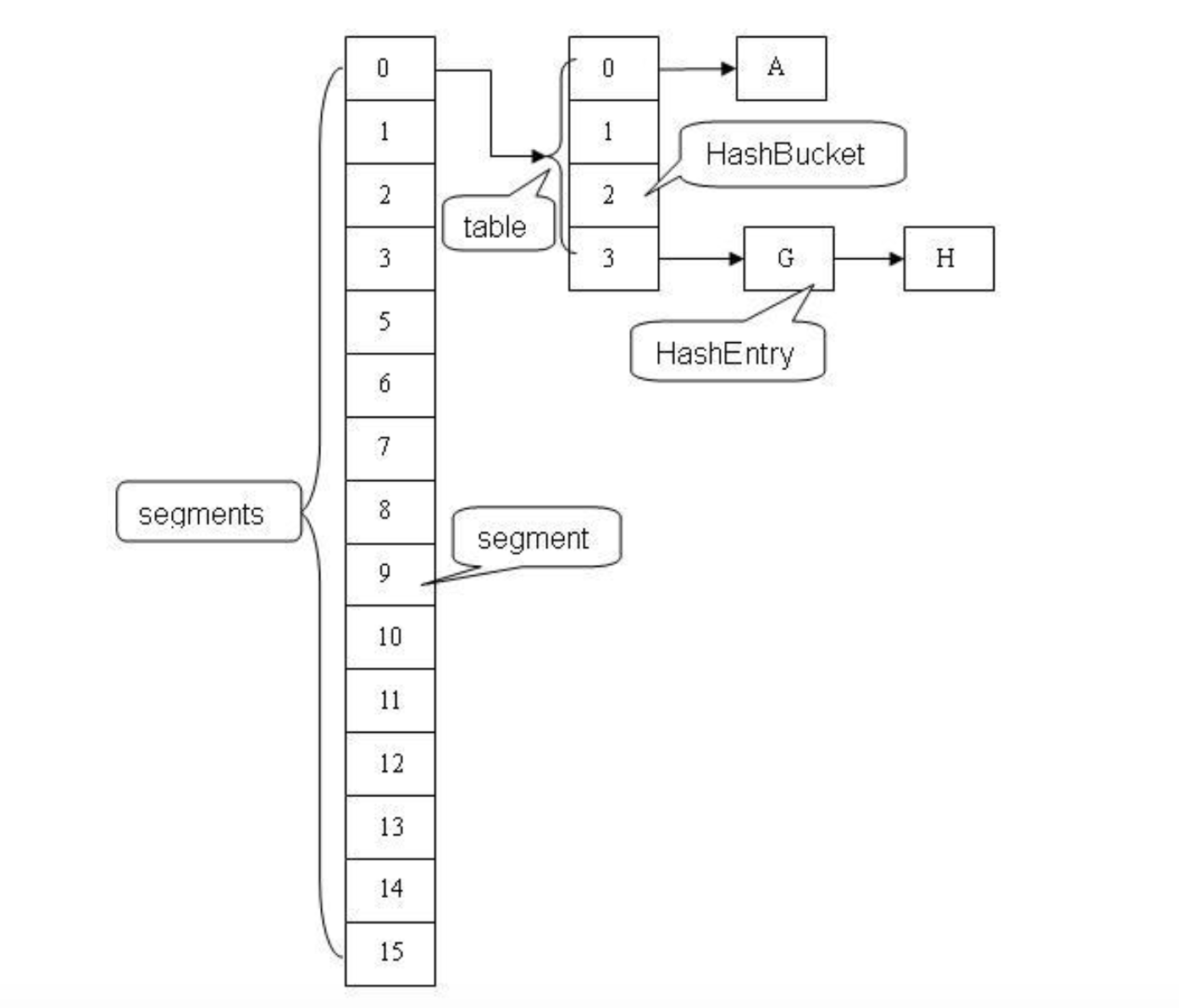
ConcurrentHashMap将数据分段存储,并给每一段数据分配一把锁(Segment),当一个线程占用一把锁(Segment)访问其中一段数据的时候,其他段的数据仍能被其它的线程访问,默认分配16个Segment。
这里的Segment 继承于 ReentrantLock 类。所以分段锁的本质是Segment对象充当锁的角色。
Segment定义如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* 在本 segment 范围内,包含的 HashEntry 元素的个数
* 该变量被声明为 volatile 型
*/
transient volatile int count;
/**
* table 被更新的次数
*/
transient int modCount;
/**
* 当 table 中包含的 HashEntry 元素的个数超过本变量值时,触发 table 的再散列
*/
transient int threshold;
/**
* table 是由 HashEntry 对象组成的数组
* 如果散列时发生碰撞,碰撞的 HashEntry 对象就以链表的形式链接成一个链表
* table 数组的数组成员代表散列映射表的一个桶
* 每个 table 守护整个 ConcurrentHashMap 包含桶总数的一部分
* 如果并发级别为 16,table 则守护 ConcurrentHashMap 包含的桶总数的 1/16
*/
transient volatile HashEntry<K,V>[] table;
/**
* 装载因子
*/
final float loadFactor;
Segment(int initialCapacity, float lf) {
loadFactor = lf;
setTable(HashEntry.<K,V>newArray(initialCapacity));
}
/**
* 设置 table 引用到这个新生成的 HashEntry 数组
* 只能在持有锁或构造函数中调用本方法
*/
void setTable(HashEntry<K,V>[] newTable) {
// 计算临界阀值为新数组的长度与装载因子的乘积
threshold = (int)(newTable.length * loadFactor);
table = newTable;
}
/**
* 根据 key 的散列值,找到 table 中对应的那个桶(table 数组的某个数组成员)
*/
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
// 把散列值与 table 数组长度减 1 的值相“与”,
// 得到散列值对应的 table 数组的下标
// 然后返回 table 数组中此下标对应的 HashEntry 元素
return tab[hash & (tab.length - 1)];
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
(2)基于CAS机制的数据共享
JDK 1.8使用CAS技术+ synchronized关键字实现更大程度的共享。
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// ConcurrentHashMap 不允许插入null键,HashMap允许插入一个null键
if (key == null || value == null) throw new NullPointerException();
// 计算key的hash值
int hash = spread(key.hashCode());
int binCount = 0;
// for循环的作用:因为更新元素是使用CAS机制更新,需要不断的失败重试,直到成功为止。
for (Node<K,V>[] tab = table;;) {
// f:链表或红黑二叉树头结点,向链表中添加元素时,需要synchronized获取f的锁。
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 通过hash定位Node[]数组的索引坐标,
// 是否有Node节点,如果没有则使用CAS进行添加(链表的头结点),添加失败则进入下次循环。
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 检查到内部正在移动元素(Node[] 数组正在扩容)
else if ((fh = f.hash) == MOVED)
// 帮助扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 使用synchronized加锁链表或红黑树头结点
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果链表长度已经达到临界值(默认是8),就把链表转换为树结构
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
2 ConcurrentHashMap是线程安全
ConcurrentHashMap线程安全,多线程访问场景下使用ConcurrentHashMap替代。
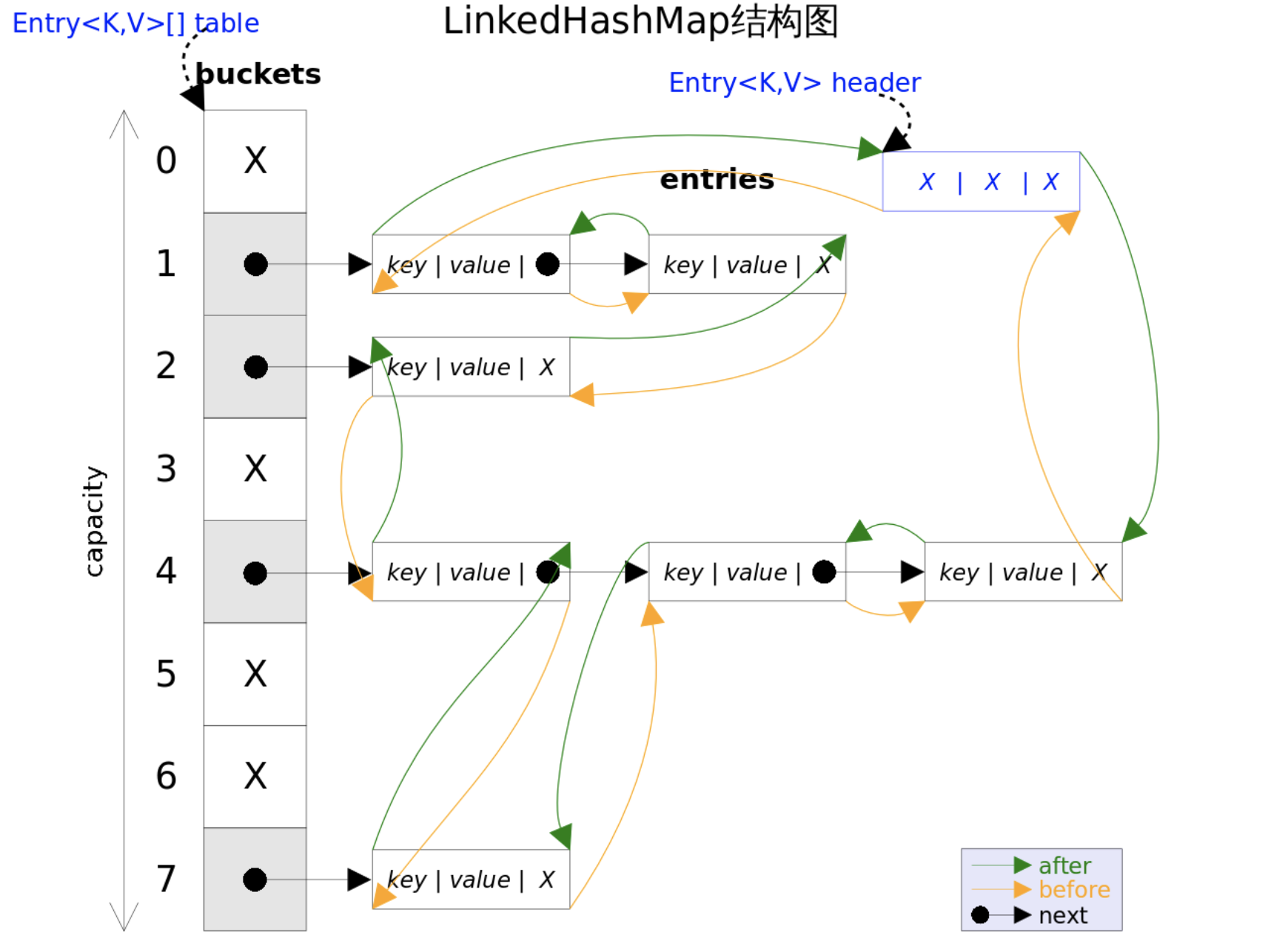
LinkedHashMap
HashMap是无序的。在某些场景下需要使用有序的HashMap(插入有序或访问有序)。LinkedHashMap实现了一个有序的HashMap。LinkedHashMap继承HashMap。
1 LinkedHashMap基于HashMap+双链表实现
LinkedHashMap在HashMap数据结构基础上维持了一个双链表,用来记录数据插入顺序或访问顺序,从而保证访问有序。
(1)使用双链表保证有序
使用双链表维持HashMap有序的数据结构如下:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
为保证使用Iterator遍历LinkedHashMap时,仍保证有序,LinkedHashMap还重写迭代器LinkedHashIterator。
(2)支持插入有序或访问有序
有序既可以是插入顺序,也可以是访问顺序。LinkedHashMap的默认实现是按插入顺序排序的。可在创建LinkedHashMap实例时设置插入有序还是访问有序。对应LinkedHashMap构造函数如下:
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
- 1
- 2
- 3
- 4
2 LinkedHashMap是非线程安全
与HashMap一样, LinkedHashMap也是非线程安全,即任一时刻可以有多个线程同时写LinkedHashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法包装LinkedHashMap,使其具有线程安全的能力。
TreeMap
TreeMap 是一个有序的Map,使用红黑树(Red-Black tree)实现有序。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
因为使用树结构实现,所以TreeMap的基本操作如 containsKey、get、put 和 remove 等的时间复杂度是 log(n) 。
1 TreeMap基于红黑树实现
(1)TreeMap使用红黑树存储键值对
红黑树的结构及功能实现不在本POST展开,更多红黑树知识可参考《数据结构》(严蔚敏)或《算法导论》(Cormen Leiserson)一书。
红黑树中树节点结构定义如下:
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
// 左孩子
Entry<K,V> left;
// 右孩子
Entry<K,V> right;
// 父节点
Entry<K,V> parent;
// 树节点默认颜色是黑色
boolean color = BLACK;
public K getKey() { ... }
public V getValue() { ... }
public V setValue(V value) { ...}
public boolean equals(Object o) { ... }
public int hashCode() { ... }
public String toString() { ... }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
(2)TreeMap有序
TreeMap其键默认是字典序排序(升序),但可以根据创建时提供的 Comparator 进行排序。
TreeMap通过实现NavigableMap接口,使其具备有序功能。
更多Tree有序功能的使用可参考链接
2 TreeMap是非线程安全
TreeMap非线程安全,即任一时刻可以有多个线程同时写TreeMap,可能会导致数据的不一致。
Set
相比List和Map,Set使用较少。Set类层次结构如下:

目前接触的三个实现(HashSet、LinkedHashSet、TreeSet)都是非线程安全的实现。默认情况下,使用HashSet。当需要保证插入有序或访问有序时,使用LinkedHashSet。当需要保证键的有序性,可以选用TreeMap。
HashSet
HashSet实现了Set接口,它不允许集合中出现重复元素。
1 HashSet基于HashMap实现
HashSet通过组合HashMap实现不出现重复元素的集合。
(1)HashSet仅使用HashMap的键
添加到HashSet中的值在HashMap对象中起作用的是键,且其值使用相同的常量(所以在键值对中所有的键的值都是一样的)。
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap map;
// Constructor - 1
// All the constructors are internally creating HashMap Object.
public HashSet()
{
// Creating internally backing HashMap object
map = new HashMap<>();
}
// Constructor - 2
public HashSet(int initialCapacity)
{
// Creating internally backing HashMap object
map = new HashMap<>(initialCapacity);
}
// Dummy value to associate with an Object in Map
private static final Object PRESENT = new Object();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
查看HashSet中的元素添加方法,可以看到map成员对象中添加键值对的值是同一个常对象。相关代码如下:
public boolean add(E e)
{
return map.put(e, PRESENT) == null;
}
- 1
- 2
- 3
- 4
2 HashSet是非线程安全
HashSet基于HashMap实现,所以HashSet也是非线程安全。
LinkedHashSet
1 LinkedHashSet基于LinkedHashMap实现
LinkedHashSet继承自HashSet,深入HashSet源码可知,其底层使用LinkedHashMap实现。关键源码如下:
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
/**
* Constructs a new, empty linked hash set with the default initial
* capacity (16) and load factor (0.75).
*/
public LinkedHashSet() {
super(16, .75f, true);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2 LinkedHashSet是非线程安全
LinkedHashSet基于LinkedHashMap实现,所以LinkedHashSet也是非线程安全。
TreeHashSet
TreeHashSet实现了 NavigableSet接口,它保证集合中的元素按照键顺序存储(如果指定比较器,则按照比较顺序存储)。
1 TreeHashSet基于TreeMap实现,关键源码如下:
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
/**
* The backing map.
*/
private transient NavigableMap<E,Object> m;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap<>());
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2 TreeHashSet是非线程安全
TreeHashSet基于TreeMap实现,因为TreeMap是非线程安全的,所以TreeHashSet也是非线程安全。
Queue
Queue类层次结构如下:
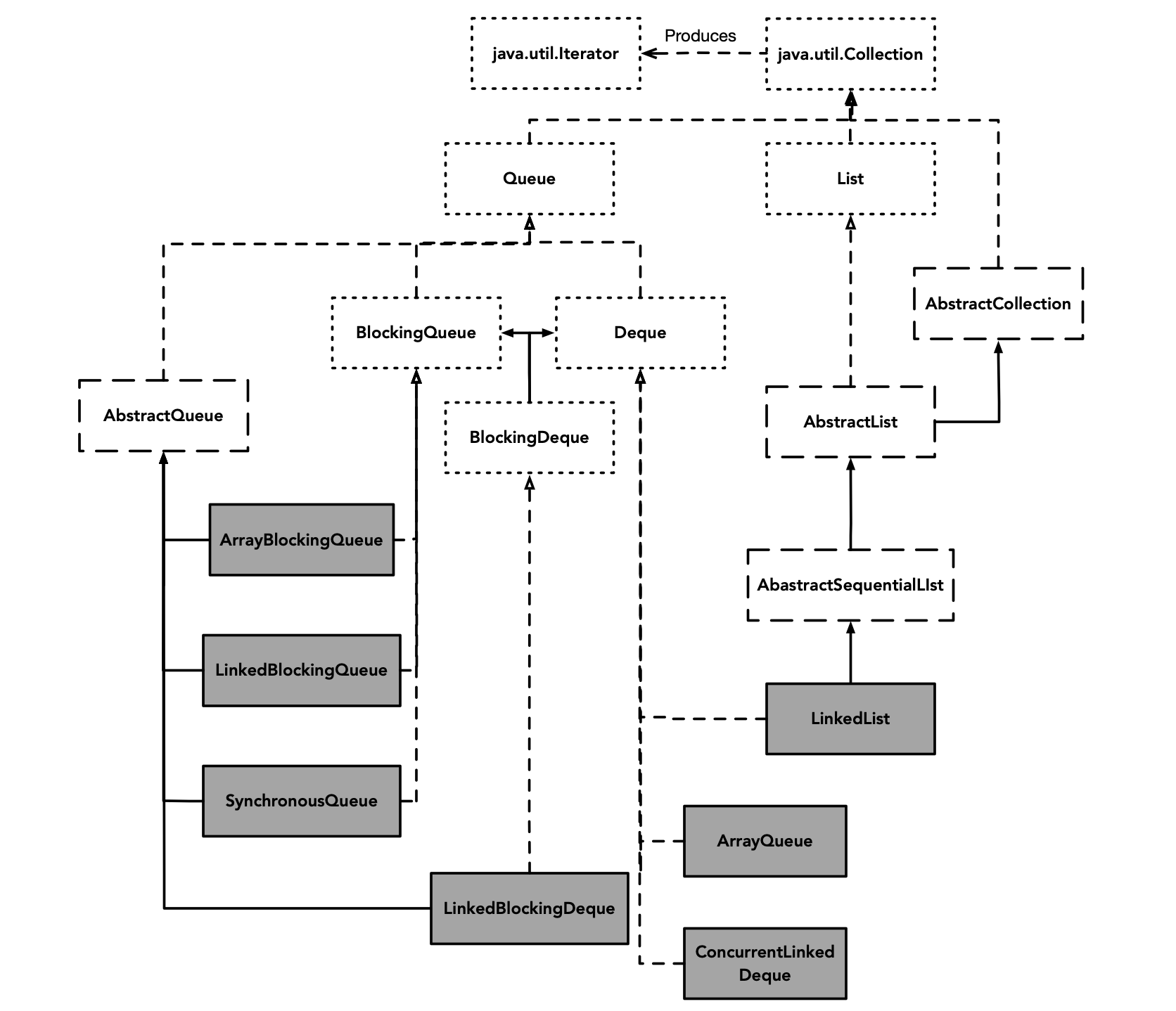
Java在实现Queue时,主要进行了Deque(双向队列)、BlockingQueue(阻塞队列)、BlockingDeque(双向阻塞队列)三种划分。
BlockingQueue
BlockingQueue是Java 5.0新增的容器。类库中包含BlockingQueue的多种实现。如ArrayBlockingQueue和LinkedBlockingQueue是FIFO队列,二者分别与ArrayList和LinkedList类似,但比同步List拥有更好的并发性能。PriorityBlockingQueue是一个按照优先级排序的队列,当希望按照某种特定的顺序处理元素时,这个队列将非常有用。SynchronousQueue则不是一个真正的队列,因为它不会为队列中的元素维护存储空间。它维护一组线程,这些线程在等待着把元素加入或移出队列。
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。另外,在线程池中,ThreadPoolExecutor使用的工作队列也是阻塞队列。
BlockingQueue是线程安全。BlockingQueue方法使用内部锁及其他形式的并发控制策略实现线程安全。但是,对批量操作来说,则不一定是线程安全操作。如addAll©操作会执行失败,当仅将c中一部分元素可以添加。
1. ArrayBlockingQueue
ArrayBlockingQueue是一个用数组实现的固定的(容量一旦设置不能改变,不支持动态扩容)有界阻塞队列。ArrayBlockingQueue支持公平和非公平访问,且默认是非公平访问(参考JDK 1.8源码)。(每一个线程在获取锁的时候可能都会排队等待,如果在等待时间上,先获取锁的线程的请求一定先被满足,那么这个锁就是公平的。反之,这个锁就是不公平的。公平的获取锁,也就是指当前等待时间最长的线程先获取锁)。
针对插入和移除操作,ArrayBlockingQueue提供了多种实现,这里重点分析下put方法和take方法(阻塞的调用方式较常用)。
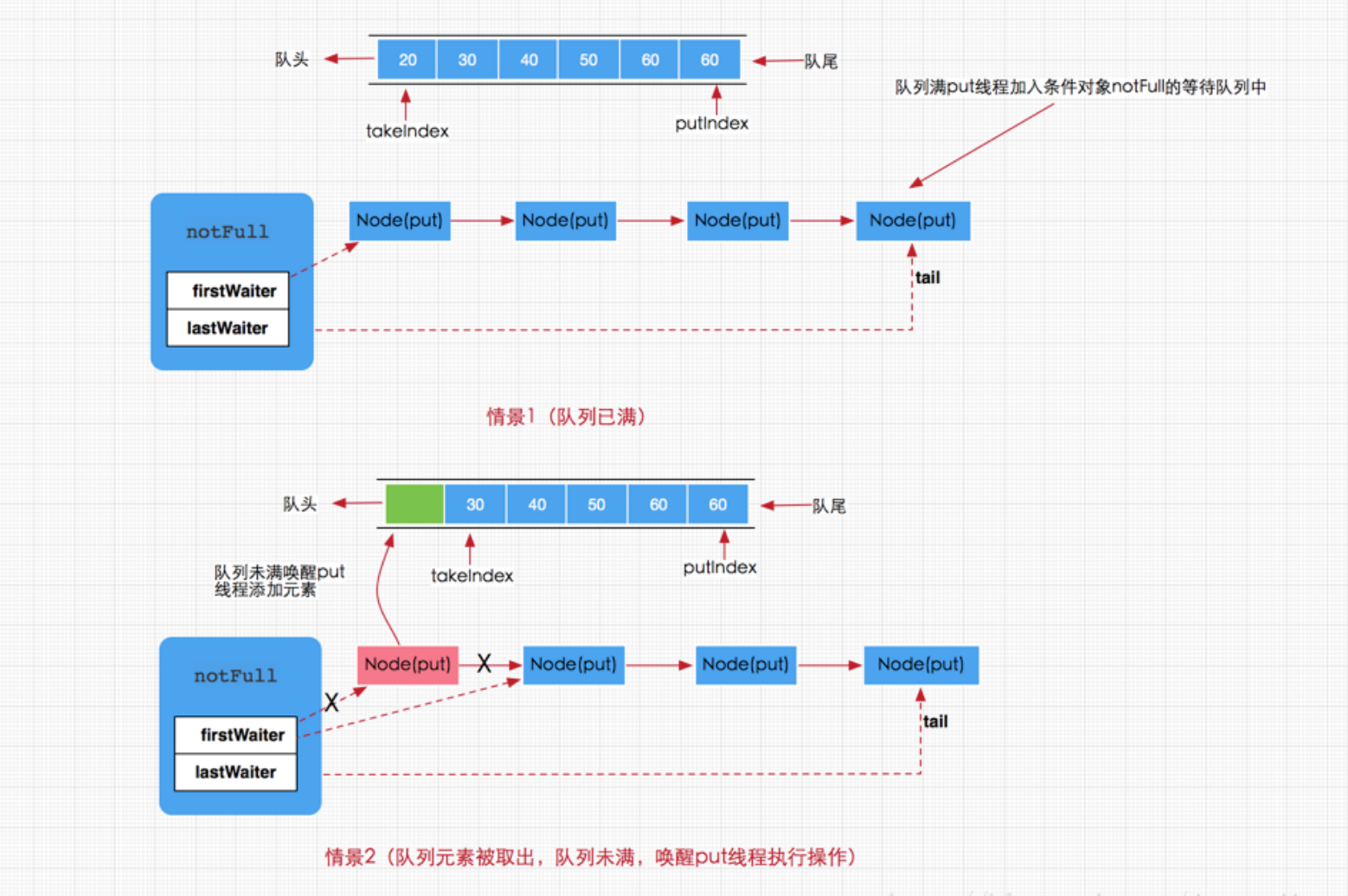
线程在调用put方法向阻塞队列插入数据时,如果检测到阻塞队列已满,则会一直等待,直到队列非满或者响应中断退出。在执行put方法时,如果队列已满,那么当前线程将会被添加到notFull Condition对象的等待队列中,直到队列非满时,才会唤醒执行添加操作。如果队列没有满,那么就直接调用enqueue(e)方法将元素加入到队列中。 所以,可以推断,当在阻塞队列上执行移除元素操作时,在移除成功的同时会唤醒notFull Condition对象的等待队列的线程。
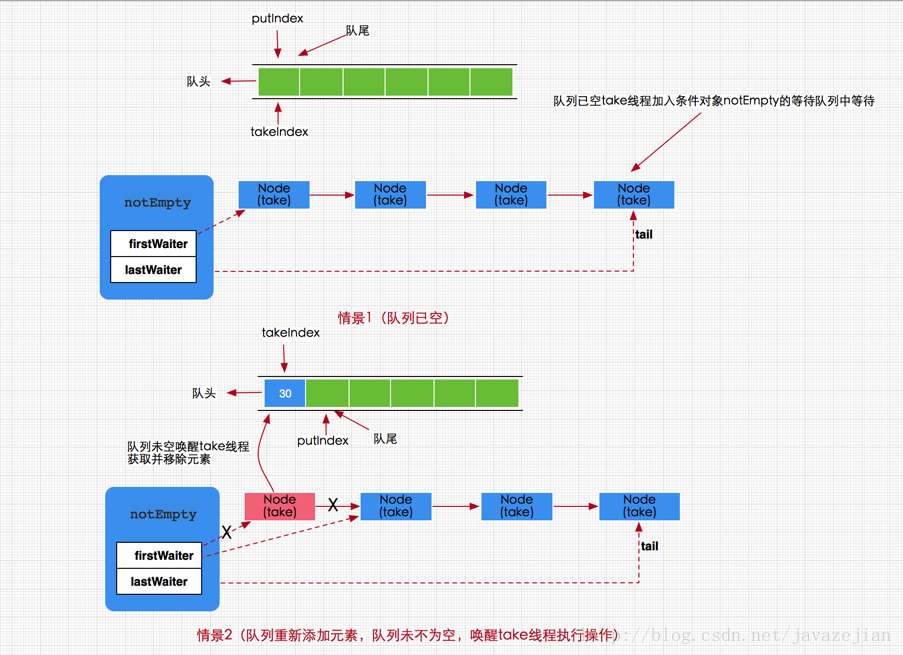
线程在调用take方法从阻塞队列移除数据时,如果检测到阻塞队列已空,则会一直等待,直到队列非空或者响应中断退出。在执行take方法时,如果队列已空,那么当前线程将会被添加到notEmpty Condition对象的等待队列中,直到队列非空时,才会唤醒执行移除操作。如果队列不为空,那么就直接调用dequeue()方法从队头移除元素。 所以,可以推断,当在阻塞队列上执行添加元素操作时,在添加成功的同时会唤醒notEmpty Condition对象的等待队列的线程。
分析ArrayBlockingQueue源码可以发现,ArrayBlockingQueue线程安全是通过ReentrantLock来保证线程独占访问实现的。
2 LinkedBlockingQueue
LinkedBlockingQueue是一个由链表结构组成的有界队列,此队列的默认最大长度为Integer.MAX_VALUE(可将其看成无界队列)。在使用LinkedBlockingQueue时,也可以在初始化时指定其容量。 LinkedBlockingQueue队列按照先进先出(FIFO)的顺序进行排序。
因为实现了BlockingQueue接口,所以针对插入和移除操作,LinkedBlockingQueue同样提供了多种实现。与ArrayBlockingQueue一致,这里重点分析下put方法和take方法(阻塞的调用方式较常用)。
分析LinkedBlockingQueue的put方法源码可以发现,其处理流程与ArrayBlockingQueue的思路一致:线程在调用put方法向阻塞队列插入数据时,如果检测到阻塞队列已满,则会一直等待,直到队列非满或者响应中断退出。线程在调用take方法从阻塞队列移除数据时,如果检测到阻塞队列已空,则会一直等待,直到队列非空或者响应中断退出。
3 PriorityBlockingQueue
PriorityBlockingQueue是一个支持线程优先级排序的无界队列(动态数组),默认按照自然序进行排序,也可以自定义实现compareTo()方法来指定元素排序规则,但不能保证同优先级元素的顺序。
因为实现了BlockingQueue接口,所以针对插入和移除操作,PriorityBlockingQueue同样提供了多种实现。与ArrayBlockingQueue一致,这里重点分析下put方法和take方法(阻塞的调用方式较常用)。
分析PriorityBlockingQueue的put方法源码可以发现,因为PriorityBlockingQueue是无界队列,所以不会出现阻塞(只会出现OOM),其实现是offer方法的转调。进一步分析offer方法源码可以发现,PriorityBlockingQueue使用动态数组存储元素,并支持自定义比较器。分析PriorityBlockingQueue的take方法源码可以发现,因为队列不可能满,所以不会对队列满进行判断。
SynchronousQueue
SynchronousQueue是一个不存储元素的阻塞队列,每一个put操作必须等待take操作,否则不能添加元素。支持公平锁和非公平锁(默认是非公平)。SynchronousQueue的一个使用场景是在线程池里。Executors.newCachedThreadPool()就使用了SynchronousQueue,这个线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用,线程空闲了60秒后会被回收。
SynchronousQueue 的公平模式(FIFO,先进先出)可以减少了线程之间的冲突,在竞争频繁的场景下反而具备更高的性能,而非公平模式(LIFO,后进先出)能够更好的维持线程局部性(thread locality),减少线程上下文切换的开销。
虽然 SynchronousQueue 实现了 BlockingQueue 接口,但并未对接口中声明的方法全部支持,如 peek 方法始终返回 null,在使用时应先阅读明确接口实现,避免影响程序的正确性。
SynchronousQueue 中定义了一个 Transferer 抽象类,该类抽象了 Dual Stack 和 Dual Queue 数据结构的实现,定义如下:
abstract static class Transferer<E> {
abst
ract E transfer(E e, boolean timed, long nanos);
}
- 1
- 2
- 3
- 4
SynchronousQueue 的出列和入队列操作均委托给 Transferer的transfer 接口,该方法接收 3 个参数,其中参数 e 表示待添加到队列中的元素值,对于出队列操作来说,e 等于 null;参数 timed 用于设置当前操作是否具备超时策略,如果是则需要使用 nanos 参数(单位为nanoseconds)指定超时时间。
1 Dual Stack
针对 Dual Stack 数据结构,SynchronousQueue 实现了 TransferStack 类。 TransferStack 继承自 Transferer 抽象类,并定义了 SNode 类记录栈上的结点信息。分析TransferStack的 transfer 接口源码可以发现:
(1) 当栈为空或栈中等待线程的运行模式与当前线程的运行模式相同时,则尝试将结点入栈,并让当前线程在结点上等待。
(2) 当栈中正在等待的线程运行模式与当前线程互补(可以简单理解为栈中等待的线程都是生产者,而当前线程是消费者),并且此时没有线程正在执行匹配操作,则当前线程进入匹配阶段。
(3) 当栈中正在等待的线程运行模式与当前线程互补,并且此时有线程正在执行匹配操作,则说明正在进行匹配。
基于 Dual Stack 的 SynchronousQueue 始终在栈顶执行入队列和出队列操作,后入队的线程会先被匹配,这也解释了为什么基于 Dual Stack 的 SynchronousQueue 是非公平的。基于 Dual Stack 的 SynchronousQueue 潜在的一个问题是可能导致先入队的线程长期得不到匹配而饥饿,而优点在于能够更好的维持线程局部性(thread locality),减少线程上下文切换的开销。
2 Dual Queue
针对 Dual Queue 数据结构,SynchronousQueue 实现了 TransferQueue 类,TransferQueue 同样继承自 Transferer 抽象类,并定义了 QNode 类描述队列上的结点。分析TransferStack的 transfer 接口源码可以发现:
(1) 当队列为空,或者队列中等待的线程运行模式与当前线程的运行模式相同,此时需要将结点入队列,并让当前线程在结点上等待。
(2) 当队列中正在等待的线程运行模式与当前线程互补,则进入匹配阶段。
基于 Dual Queue 的 SynchronousQueue 在队头执行出队列操作,并在队尾执行入队列操作,先入队的线程通常会先被匹配,这也解释了为什么基于 Dual Queue 的 SynchronousQueue 是公平的。基于 Dual Queue 的 SynchronousQueue 因为入队和出队的冲突相对较小,所以在竞争频繁的场景下相对于非公平模式反而具有更好的性能。
Deque
Java 6增加Deque(发音为"deck")容器,Deque(Deque 是 “Double Ended Queue”的简称)是一个双端队列,实现了队列头和队列尾的高效插入和移除。类库中包含Deque的多种实现,如ArrayDeque、LinkedList是实现不同的Deque,二者分别与ArrayList和LinkedList类似。此外,还有线程安全实现——ConcurrentLinkedDeque。
Deque声明了12个基本方法,它们是:
| 操作类型\方法名称 | 头部元素-抛出异常 | 头部元素-返回特殊值 | 尾部元素-抛出异常 | 尾部元素-返回特殊值 |
|---|---|---|---|---|
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 移除 | removeFirst()() | pollFirst() | removeLast() | pollLast() |
| 检查 | getFirst()() | peekFirst() | getLast() | peekLast() |
可以看到,尽管当前提条件未满足时,依赖状态的操作有以下四种可选操作:可以抛出一个异常或返回一个错误状态(让调用者处理这个问题),也可以保持阻塞直到对象进入正确的状态或者保持阻塞直到超时。但Deque并未对阻塞操作提供支持。
Deque接口扩展(继承)了 Queue 接口。在将双端队列用作队列时,将得到 FIFO(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。从 Queue 接口继承的方法完全等效于 Deque 方法,对比如下:
| Queue 方法 | Deque 方法 |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst()() |
| poll() | pollFirst()() |
| element() | getFirst()() |
| peek() | peekFirst()() |
这里假设元素从右侧进从左侧出(约定不同的进出方向,对应的方法不同)。
双端队列也可用作 LIFO(后进先出)堆栈。应优先使用此接口而不是遗留 Stack 类。在将双端队列用作堆栈时,元素被推入双端队列的开头并从双端队列开头弹出。堆栈方法完全等效于 Deque 方法,如下表所示:
| Stack 方法 | Deque 方法 |
|---|---|
| push(e) | addFirst(e)/offerFirst(e) |
| pop() | removeFirst()/pollFirst() |
| peek() | getFirst()/peek()First() |
这里假设元素从Deque的左侧进出。
Deque集成了Queue接口,所以Deque可以作为**普通队列(一端进另一端出)使用。此外Deque还声明了双端队列(两端都可进出)需要的接口。也可将双端队列通过行为规范成栈(先进后出)**来使用。
1 ArrayDeque
ArrayDeque 是 Deque 接口的一种具体实现,ArrayDeque 是基于动态数组来实现的,ArrayDeque 没有容量限制,可根据需求自动进行扩容。注意ArrayDeque不支持值为 null 的元素。ArrayDeque无法保证线程安全。对于线程安全场景,推荐使用ConcurrentLinkedDeque。
ArrayDeque的默认长度是16。ArrayDeque动态增长的长度会根据当前的容量选用不同的策略。具体来说,当容量小于64时,每次成倍的增长,当容量大于等于64时,增长一半。
Deque支持的操作很多,但无法绕开三个操作:插入、删除、检查。这里选择有代表性的addFirst()方法、removeFirst()方法、getFirst()方法。
/**
* Circularly decrements i, mod modulus.
* Precondition and postcondition: 0 <= i < modulus.
*/
static final int dec(int i, int modulus) {
if (--i < 0) i = modulus - 1;
return i;
}
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
final Object[] es = elements;
es[head = dec(head, es.length)] = e;
if (head == tail)
grow(1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
分析addFirst()源码可以发现,向ArrayDeque新增元素时,如果元素为null则抛出异常(不支持值为null的元素),在使用时要注意(其他插入方法也会进行该判断)。
分析addFirst()源码还可以发现,存储元素的数组作为环形来使用的,正常情况下在队头添加元素后,如果数组越界,则会从队尾向前插入元素(如果已存在元素则覆盖)。
当检测到对头和队尾指向同一个元素时,说明容量已被占用,这时可以进行扩容。
/**
* Circularly increments i, mod modulus.
* Precondition and postcondition: 0 <= i < modulus.
*/
static final int inc(int i, int modulus) {
if (++i >= modulus) i = 0;
return i;
}
public E removeFirst() {
E e = pollFirst();
if (e == null)
throw new NoSuchElementException();
return e;
}
public E pollFirst() {
final Object[] es;
final int h;
E e = elementAt(es = elements, h = head);
if (e != null) {
es[h] = null;
head = inc(h, es.length);
}
return e;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
分析removeFirst()方法源码可以发现,其仅是对pollFirst()方法的转调。深入pollFirst()方法源码,可以发现移除元素的过程就是将其值置空的过程,同时更新head指针。
/**
* Returns element at array index i.
* This is a slight abuse of generics, accepted by javac.
*/
@SuppressWarnings("unchecked")
static final <E> E elementAt(Object[] es, int i) {
return (E) es[i];
}
public E getFirst() {
E e = elementAt(elements, head);
if (e == null)
throw new NoSuchElementException();
return e;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
getFirst()方法就是从数组获取元素的过程,无特殊处理。
2 LinkedList
LinkedList已经在之前进行过介绍,这里从Deque的角度进一步分析LinkedList。
LinkedList 是 Deque 接口的一种具体实现, LinkedList 是基于链表来实现的。与ArrayDeque不同的是,LinkedList支持值为 null 的元素。与ArrayDeque相同的是,LinkedList也无法保证线程安全。对于线程安全场景,同样推荐使用ConcurrentLinkedDeque。
3 ConcurrentLinkedDeque
ConcurrentLinkedDeque 是 Deque 接口的一种具体实现, ConcurrentLinkedDeque 是基于链表来实现,ConcurrentLinkedDeque 可以保证线程安全,与 LinkedList 不同的是,ConcurrentLinkedDeque 不允许 null 元素。
ConcurrentLinkedDeque 内部通过 CAS 来实现线程安全,一般来说,如果需要使用线程安全的双端队列,那么推荐使用该类。
public class ConcurrentLinkedDeque<E>
extends AbstractCollection<E>
implements Deque<E>, java.io.Serializable {
private transient volatile Node<E> head;
private transient volatile Node<E> tail;
// 双链表
static final class Node<E> {
volatile Node<E> prev;
volatile E item;
volatile Node<E> next;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在使用 ConcurrentLinkedDeque 时,要注意:
(1) 慎用size()方法,size方法结果可能不准确。由于 ConcurrentLinkedDeque 使用 CAS 保证线程安全,所以size方法的返回值不一定准确(多个线程可以同时操作 ConcurrentLinkedDeque 中元素)。
(2) 批量操作无法保证原子性。对如addAll,removeAll,retainAll,containsAll,equals,toArray等批量操作来说,ConcurrentLinkedDeque 不能保证这些操作的原子性。
(3) 使用迭代器遍历ConcurrentLinkedDeque时,由于是双链表,所以存在元素删除但仍可通过迭代器访问的情况(弱一致性遍历)。
4 ArrayDeque、LinkedList、ConcurrentLinkedDeque选用原则
在非线程安全场景,可以选用ArrayDeque或LinkedList。因为Deque的特殊性,ArrayDeque和LinkedList的选用标准与标准数组和List的选用标准有所不同。因为Deque的操作重点集中在队头或队尾,所以LinkedList具有天生的优势。推荐在Deque的实现中优选选择LinkedList。
根据ArrayDeque源码注释,当将其作为queue时,其性能高于LinkedList(仅限元素数量已知场景)。
This class is likely to be faster than {@link Stack} when used as a stack, and faster than {@link LinkedList} when used as a queue.
- 1
在线程安全场景,可以选用ConcurrentLinkedDeque。
BlockingDeque
Java 6增加了BlockingDeque容器,它是BlockingQueue进行了扩展。BlockingDeque是一个阻塞双端队列,除了具备双端队列的功能外,还具备阻塞队列的功能——在不能够插入元素时,它将阻塞住试图插入元素的线程;在不能够抽取元素时,它将阻塞住试图抽取的线程;线程安全;不允许值为null的元素等。具体实现有LinkedBlockingQueue。 BlockingDeque源码注释如下:
Like any BlockingQueue, a BlockingDeque is thread safe, does not permit null elements, and may (or may not) be capacity-constrained.
- 1
BlockingDeque继承了BlockingQueue和Deque,所以BlockingDeque既支持BlockingQueue操作也支持Deque操作。
与BlockingQueue一样,BlockingDeque也是线程安全的,且使用内部锁(非空锁和非满锁)的并发控制策略实现线程安全,同时,对于批量操作来说,不一定是线程安全操作。
BlockingDeque既可应用于BlockingQueue场景,也可应用于Deque场景。但更多的时候,BlockingDeque不是为了替换BlockingQueue或Deque,而是解决需要同时使用BlockingQueue和Deque的场景。如工作密取场景
1 LinkedBlockingDeque
LinkedBlockingDeque 是 BlockingDeque 接口的一种具体实现。LinkedBlockingDeque 基于双链表来实现,在创建LinkedBlockingDeque实例时,可以指定容量大小。LinkedBlockingDeque使用锁+Condition对象保证线程安全访问。LinkedBlockingDeque不允许插入值为null的元素。
BlockingQueue、Deque、BlockingDeque
正如阻塞队列适用于生产者——消费者模式,双端阻塞队列则适用于工作密取(Work Stealing)模式。在生产者——消费者模式中,所有消费者有一个共享的工作队列,所有的消费者会在共享的工作队列上竞争资源。而在工作密取中,每个消费者有各自的双端队列。如果一个消费者完成了自己双端队列中的全部工作,那么它可以从其他消费者的双端队列末尾(注意,不是队头,减少队列上的竞争)获取工作。
工作密取非常适合用于即是消费者又是生产者问题——当执行某个工作可能导致出现更多的工作。
操作符和表达式
== 和 equals
==二元运算符和equals方法
根据数据类型的不同(值类型、引用类型、空类型),==运算符对于“值类型”和“空类型”,是比较他们的值;对于“引用类型”,比较的是他们在内存中的存放地址,即是否指向指向同一个对象。
Java中所有类都是继承于Object。Object类定义equals方法,这个方法的初始行为是比较对象的内存地址。实现如下:
public boolean equals(Object obj) {
return (this == obj);
}
- 1
- 2
- 3
但有些类库对这个方法进行了重写,如String,Integer,Date等,而不再是比较堆内存中的存放地址。
String
String对equals进行重写,比较值是否相等。实现如下:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String aString = (String)anObject;
if (coder() == aString.coder()) {
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
}
return false;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
因为String重写的equals方法,所以下述代码返回为true。
String str1 = new String("123");
String str2 = new String("123");
// true
str1.equals(str2);
- 1
- 2
- 3
- 4
由于==运算符对于“引用类型”仅比较是否指向同一片内存,所以new的两个String实例不相等。示例代码如下:
String str1 = new String("123");
String str2 = new String("123");
// false
str1 == str2;
- 1
- 2
- 3
- 4
String包装器支持字面量赋值,当使用形如:stringInstance="xxx"方式创建字符串时,程序首先会在字符串缓冲池中寻找相同值的对象,如果池中无相同值的对象,则在池中添加一个值。所以以下代码值相等:
String str1 = "123";
// true
str1 == "123";
- 1
- 2
- 3
但也应注意,如果使用new的方式创建字符串示例,则使用==会认为两边不相等。示例代码如下:
String str1 = new String("123");
// false
str1 == "123";
- 1
- 2
- 3
综上,对于String的相等比较,严格使用equals接口。包装器(如Integer与之类似)
Integer
为提高Integer等包装器的性能,Java引入缓存池。Integer有两种实例方式:new Integer(xxx) 与 Integer.valueOf(xxx) 。两者的区别在于:new Integer(xxx)方式每次都会新建一个对象;Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。在 Java 8 中,Integer 缓存池的大小默认为 -128~127。一旦超出这个范围,则不会缓存整数值。valueOf源码如下:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
- 1
- 2
- 3
- 4
- 5
Short和Long
Short和Long也提供了缓存池
public static Short valueOf(short s) {
final int offset = 128;
int sAsInt = s;
if (sAsInt >= -128 && sAsInt <= 127) { // must cache
return ShortCache.cache[sAsInt + offset];
}
return new Short(s);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) { // will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Float和Double
Float和Double未提供缓存池实现。使用时要特别注意。Float相关实现如下:
public static Float valueOf(float f) {
return new Float(f);
}
public Double(double value) {
this.value = value;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
流程控制
顺序语句、条件语句、循环语句
面向对象
对象拷贝
对象拷贝就是创建对象的一个副本。按照拷贝的深度,可将对象拷贝细分为两类:浅拷贝和深拷贝。
在Java语言中,如果需要实现深克隆,可以通过覆盖Object类的clone()方法实现,也可以通过序列化(Serialization)等方式来实现。(如果引用类型里面还包含很多引用类型,或者内层引用类型的类里面又包含引用类型,使用clone方法就会很麻烦。这时我们可以用序列化的方式来实现对象的深克隆。) 总结如下:
(1) 实现Cloneable接口并重写Object类中的clone()方法。
(2) 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆。
面向对象–三大基本特性
也称“三大基本特征”、“三个要素”。封装、继承、多态
封装(Encapsulation)
封装包含两层含义:
一种语言结构,便于将数据与对该数据进行操作的方法(或其他功能)捆绑在一起。(对象封装)
一种语言机制,用于限制对某些对象组件的直接访问。(访问控制)
Java封装可以理解成:封装数据和方法(定义类)、控制访问权限(添加访问修饰符)。
访问权限的控制常被成为“具体实现的隐藏”。把数据和方法包装进类中,以及具体实现的隐藏,常共同被称为“封装”。(Java编程思想)
更多信息
为了将数据和对这些数据操作的方法捆绑在一起,Java等面向对象语言通过引入“类”实现这一功能。同时,为了限制直接访问,提供了访问修饰符。
继承(Inheritance)
继承是基于一个对象(基于原型的继承)或类(基于类的继承)创建另一个对象或类的语言机制。该语言机制在创建新类(子类)的同时,不仅保留现有类(超类或基类)的实现,还形成类的层次结构。更多信息
单继承(single inheritance)与多继承(multiple inheritance)
单纯比较单继承和多继承没有任何意义。基于单继承的Java语言和基于多继承的C++语言都在特定的领域获得了极大的成功。这里重点关注Java语言选择单继承,放弃多继承的原因。要理解Java针对单继承和多继承的技术选型,就必须先了解Java语言的设计目标:
Simple, object oriented, and familiar
Robust and secure
Architecture neutral and portable
High performance
Interpreted, threaded, and dynamic
- 1
- 2
- 3
- 4
- 5
类的多继承尤其灵活性,但其语义复杂给理解和使用带来了困难。另一方面,多继承的使用频度较低(Rarely Used),且很多功能可以通过“单继承 + 多接口继承 + 组合”实现。link1 link2
Java实现多继承
Java内部类:在内部中继承,然后在外部类中创建内部类的实例。本质是一种组合机制。
多态(Polymorphism)
多态就是使用单个接口指代不同类型的实体,或者使用单个符号来表示多种不同类型。Polymorphism is the provision of a single interface to entities of different types or the use of a single symbol to represent multiple different types
在Java中,就是在编码时,调用父类方法,在运行时,动态绑定子类方法。所以,多态也称为“动态绑定”、“后期绑定”、“运行时绑定”。
前期绑定和后期绑定
所谓“绑定”,就是将一个方法调用和一个方法主体关联的过程。
所谓“前期绑定”,就是在程序执行前,已明确方法和对应的方法主体。(C语言只支持前期绑定)
所谓“动态绑定”,就是在程序运行时,可根据对象的类型,绑定对应的方法主体。(Java支持动态绑定,且除了static方法和final方法(所有的private方法均是final方法),其他所有的方法都是后期绑定)。
多态与可扩展性
多态机制可以实现程序的可扩展性。
面向对象基本原则
在程序设计领域, SOLID(单一职责、开闭原则、里氏替换、接口隔离以及依赖反转)是由罗伯特·C·马丁在21世纪早期引入的记忆术首字母缩略字,指代了面向对象编程和面向对象设计的五个基本原则。当这些原则被一起应用时,它们使得一个程序员开发一个容易进行软件维护和扩展的系统变得更加可能。SOLID所包含的原则是通过引发编程者进行软件源代码的代码重构进行软件的代码异味清扫,从而使得软件清晰可读以及可扩展时可以应用的指南。这是 参考链接
但是,在实际的面向对象开发过程中,还会使用“迪米特法则”和“组合/聚合复用原则”。
熟悉“面向对象基本原则”后,可将其理解成“高内聚、松耦合”为实现目标。
1. 单一职责原则(Single Responsibility Principle)
每一个类应该专注于做一件事情。
该原则参考了《结构化分析和系统规格》的“内聚原则”。
在编码的过程中,常使用“职责分离”思想来遵循该原则。
参考链接
2. 开闭原则(Open Close Principle)
面向扩展开放,面向修改关闭。
该原则是一种编码追求,过度的追求“开闭原则”会带来功能会系统的复杂性。
参考链接
3. 里氏替换原则(Liskov Substitution Principle)
基类存在的地方,都可使用子类替换。
里氏代换原则的直接应用是多态(动态绑定)。
4. 接口隔离原则(Interface Segregation Principle)
应为客户端提供尽可能小的单独的接口,而不是提供大的总的接口。该原则指明客户(client)应该不依赖于它不使用的方法。也是实现“高内聚”的方式之一。该原则也用于系统解耦,方便系统重构。
参考链接
5. 依赖倒置原则(Dependency Inversion Principle)
也称为“依赖倒置原则”,“依赖反转原则”。
该原则是指一种特定的解耦(传统的依赖关系创建在高层次上,而具体的策略设置则应用在低层次的模块上)形式,使得高层次的模块不依赖于低层次的模块的实现细节,依赖关系被颠倒(反转),从而使得低层次模块依赖于高层次模块的需求抽象。该原则规定:
(1)高层次的模块不应该依赖于低层次的模块,两者都应该依赖于抽象接口。(面向接口编程)
(2)抽象接口不应该依赖于具体实现(类的实例)。而具体实现则应该依赖于抽象接口(实现尽量依赖抽象,不依赖具体实现)
参考链接1
参考链接2
6. 迪米特法则(Law Of Demeter)
又叫“最少知识原则”,一个软件实体应当尽可能少的与其他实体发生相互作用。(我将其称为“最小知道原则”)
该原则是实现松耦合(Loose Coupling)遵循的原则之一。
参考链接1
7. 组合/聚合复用原则(Composite/Aggregate Reuse Principle, CARP)
合成/聚合复用原则(CARP),也称为组合复用原则。该原则的语义化描述是:尽量使用合成/聚合达到复用,尽量少用继承。
注意,该原则并不是银弹,因为不能完全使用组合替换继承。只是在告知要慎用“继承”,一旦使用继承,就会带来“子类”和“父类”的紧耦合。
实现:在一个类中引用另一个类的对象。
参考链接1
类简介
在面向对象的语言中,大多使用 class 来表示一种新类型,Java 也采用了该关键字。
static关键字和final 关键字
初始化和清理
在C程序编码时,很多错误都是由于程序员忘记初始化变量和占用内存回收造成。**C++和Java引入构造器,确保每个对象都能初始化。并通过垃圾回收机制,确保对象的清理。**在Java中,“初始化”和“创建”捆绑在一起,两者不能分离。
finalize()方法
作用一:作为垃圾回收机制的补充,释放不基于new方法创建的对象占用的内存空间(如本地方法调用C或C++分配的内存空间)
作用二:执行垃圾回收之外的清理工作如关闭文件句柄)。
访问控制
Java提供访问权限修饰符,以供类库开发人员向客户端程序员指明成员的可用或不可用。
package
package(包)内包含一组类,它们在单一的名字空间之下被组织在一起。(类比C#的namespace),包的命名是全小写,使用点号分隔。
创造独一无二的包名:将所有文件收入一个子目录,然后定义一个独一无二的目录名(如Internet域名)。
使用ClassPath指定.class文件所在路径,或jar包的存储位置(c:\access\java\grape.jar)
包访问权限
默认访问权限。处于同一个包内的所有成员可自动访问,但对包外的所有类,这些成员都是private。
public
private
protected
类访问权限
外部类的访问权限只能是public和包访问权限:private和protected类不能被外部访问。如果这个类是一个内部类(成员类),则四种访问修饰符都能使用。
封装
访问权限的控制常被称为具体实现的隐藏。把数据和方法包装进类中,以及具体实现的隐藏,常共同被称为封装。
封装的两个方面:封装数据和方法(定义类)、控制访问权限(添加访问修饰符)。
复用
复用的形式有很多种,具体来说,可以分为三类:继承、组合、代理。
组合
将对象引用置于新类中。(在新类中产生现有类的对象或使用现有类的静态方法)
编译器不会为每个引用都创建默认对象。必须手动初始化这些引用。
继承(单根继承)
按照现有类来创建新类。
代理
将一个对象置于所要构造的类中(类比组合),但同时在新类中暴露该成员对象的所有方法(类比继承)。可见,代理是组合+手动继承。
继承与组合的选用
多用组合,少用继承。仅在必须进行向上转型时,才使用继承。
组合技术通常用于需要使用现有类的功能而非它的接口的情况。
继承则用于需要使用现有类的接口的情况。
多态
通过动态绑定实现多态,实现在调用父类方法时,表现出子类的特性。
所谓的绑定,就是将一个方法调用同一个方法体关联起来。根据绑定发生的时间,将其分为前期绑定和后期绑定。
前期绑定
在程序执行前进行绑定。C语言只有一种方法调用,即前期绑定。
后期绑定(动态绑定/运行时绑定)
在运行时根据对象的类型进行绑定。Java中除了static方法和final方法(private方法是final方法的一种),其他所有方法都是后期绑定。
构造器与多态
尽量不要在构造器中使用后期绑定的方法,以避免多态带来的不确定性。
内部类
在 Java 中,将放在一个类的内部的另一个类称为内部类。根据使用的修饰符不同和定义的位置不同,可将内部类划分为:成员内部类(没有static修饰符),静态内部类(有static修饰符),局部内部类(有类名),匿名内部类(没有类名)四种。内部类的使用场景优先,且逐渐被Lamda表达式替代(由其是局部内部类、匿名内部类)。
Java语言引入内部类,主要有以下两方面的考虑:
(1) 完善Java语言的多继承能力。Java语言是单继承机制(所有的子类拥有一个共同的父类),这种设计极大的简化了语言的使用,但是有些场景仍需要多继承机制。Java语言引入内部类,就是为了完善Java语言的多继承能力。每个内部类都能独立地继承一个类,无论外部类是否已经继承一个类,对于内部类都没有影响。在开发设计中,会存在一些使用接口很难解决的问题,而类却只能继承一个父类。这个时候可以利用内部类去继承其他父类和实现多个接口来解决。
(2) 提高封装性。内部类可以根据访问权限实现对外部的不同程度的隐藏。这复合面向对象思想的高内聚、低耦合原则。将内部类隐藏在外部类中,也能提高代码的可读性和可维护性。
内部类的划分,可以参照类的成员变量的分类。内部类根据使用的修饰符不同和定义的位置不同,可进行如下划分:
(1) 定义在外部类的成员所在层级
成员内部类(没有static修饰符)
静态内部类(有static修饰符)
(2)定义在外部类的方法体/代码块内
局部内部类(有类名)
匿名内部类(没有类名)
成员内部类
在外部类的内部定义的非静态的内部类,叫成员内部类(Member Inner Class)。创建成员内部类的示例代码如下:
// OuterClass.java
public class OuterClass {
private String privateField;
String defaultField;
protected String protectedField;
public String publicField;
class DefaultInnerClass {
private String privateField;
String defaultField;
protected String protectedField;
public String publicField;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在外部类中声明一个成员内部类,可以看做是将该成员类当做成员变量或成员方法处理。如上述示例代码中的内部类,其访问权限是默认访问权限(包权限)。同时,也支持用private、protected、public、final、static等访问控制符或修饰符来修饰。
注意,不建议用public修饰内部类。这是因为,这样做会破坏内部类用于隐藏细节的特性。如果真需要用public修饰,应该将其单独定义并通过组合的方式使用外部类。
在使用成员内部类时,需要特别注意内部类与外部类之间的访问。成员内部类可以直接访问外部类,外部类需通过引用方式访问内部类实例。
静态内部类
在外部类的内部定义的静态的内部类,叫静态内部类(Static Inner Class)。静态内部类也称为嵌套类(Nested Class),嵌套类特指静态内部类。创建静态内部类的示例代码如下:
// OuterClass.java
public class OuterClass {
private String privateField;
private static String privateStaticField;
static class StaticInnerClass {
private String privateField;
private static String privateStaticField;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在使用静态内部类时,同样关注静态内部类与外部类之间的访问。静态内部类可以直接访问外部类的静态成员或实例成员,外部类可以直接访问静态内部类的静态成员或通过引用方式访问内部类实例。
局部内部类
在外部类的方法中,定义的非静态的内部类,叫局部内部类(Local Inner Class)。创建局部内部类的示例代码如下:
// OuterClass.java
public class OuterClass {
private String privateField;
private void visitLocalInnerClass() {
class LocalInnerClass {
private String privateField;
}
LocalInnerClass localInnerClass = new LocalInnerClass();
System.out.println(localInnerClass.privateField);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在使用局部内部类时,也需要关注局部内部类与外部类之间的访问。局部内部类可以直接访问外部类的静态成员或实例成员,外部类则无法在方法体外访问该局部内部类(局部内部类定义在方法内,限制该内部类只能在该方法中生效)。
直接使用局部内部类的场景并不多(笔者还没看到过相关的代码),更多的是使用Lamda表达式代替。对局部内部类仅做了解即可。
匿名内部类
在外部类的方法中,定义的非静态的没有类名的内部类,叫匿名内部类(Anonymous Inner Class)。创建匿名内部类的示例代码如下:
// OuterClass.java
public class OuterClass {
private String privateField;
private void visitAnonymousInnerClass() {
Runnable runnable = new Runnable() {
private String privateField;
@Override
public void run() {
System.out.println(privateField);
}
};
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在使用匿名内部类时,同样需要关注匿名内部类与外部类之间的访问。匿名内部类是局部内部类的一种特性,所以遵循局部内部类与外部类的规则。这里再重复说明下:匿名内部类可以直接访问外部类的静态成员或实例成员,外部类则无法在方法体外访问匿名内部类(匿名内部类定义在方法内,限制该内部类只能在该方法中生效)。匿名内部类可以使用Lamda表达式简化,上述匿名内部类简化后的效果如下:
private void visitAnonymousInnerClass(String input) {
int localNumber = 0;
Runnable runnable = () -> {
System.out.println(localNumber);
System.out.println(input);
System.out.println(OuterClass.this.privateField);
OuterClass outerClass = new OuterClass();
System.out.println(outerClass.privateField);
};
runnable.run();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
匿名内部类适合只使用一次的局部内部类场景,当创建一个匿名内部类时,会立即创建该类的一个实例对象,匿名内部类因为没有类名,所以不能重复使用。
匿名内部类是局部内部类的特例(匿名的含义是编译器会自动给匿名内部类起一个名称)。与局部内部类一样,匿名内部类也有被Lamda表达式替代的风险。对于遗留代码还有部分保留匿名内部类写法,但是对于新增代码,尽量使用Lamda表达式。
Java IO
一个流是一组有序的数据序列。Java 程序通过流来完成输入/输出,所有的输入/输出以流的形式处理。
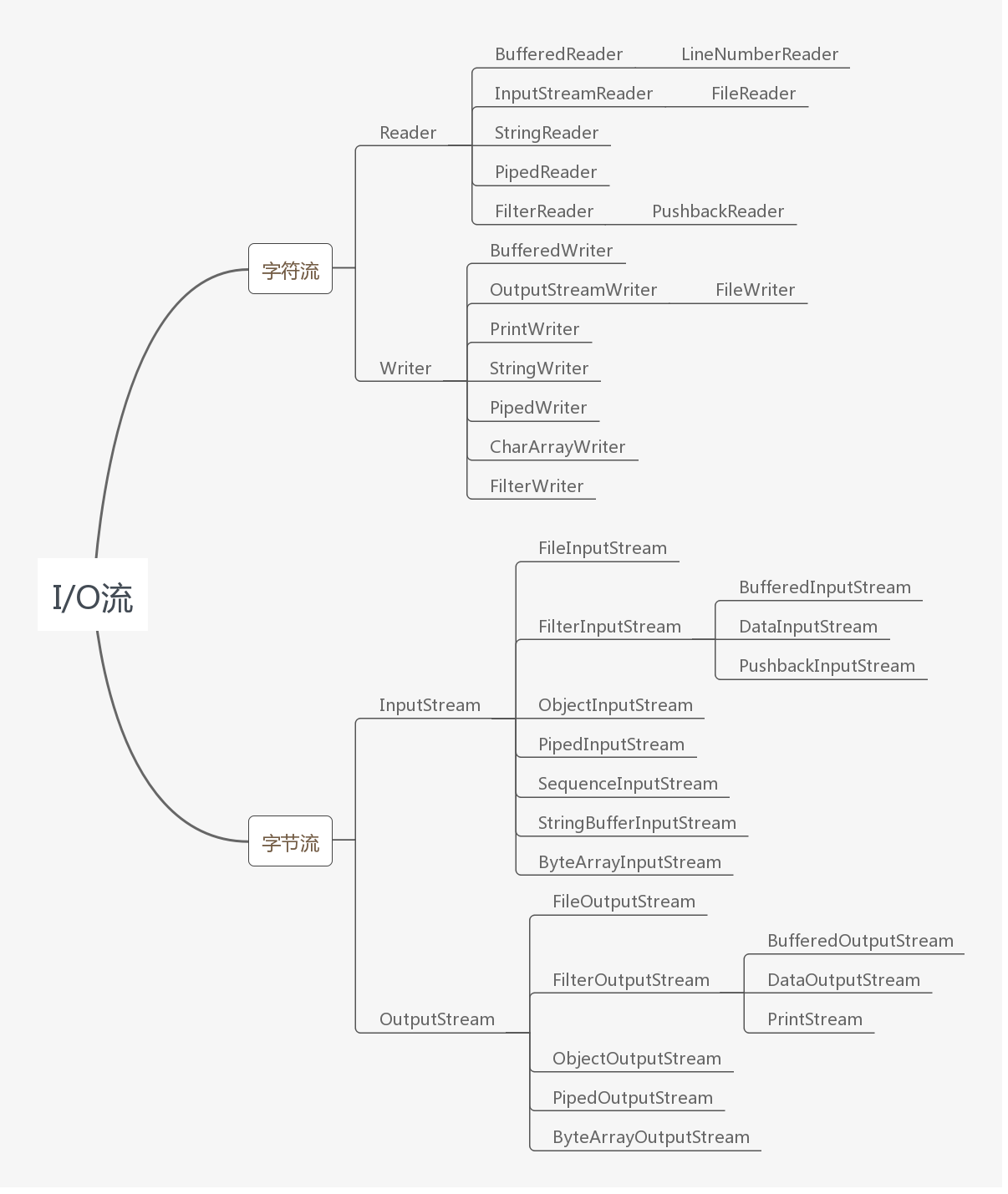
Java 的I/O流是实现输入/输出的基础,它可以方便地实现数据的输入/输出操作,在 Java 中把不同的输入/输出源(键盘、文件、网络等)抽象表示为流。这样做简化了输入/输出处理。Java 的IO流涉及到了40多个类,如下图所示:
IO流分类
Java 中 IO 流按功能来分:输入流(input)、输出流(output)。按类型来分:字节流和字符流。
字节流和字符流的区别是:字节流按 8 位传输,以字节为单位输入输出数据,字符流按 16 位传输,以字符为单位输入输出数据。
字节流
字节流,传输数据的基本单位是字节。字节数据是二进制形式的,要转成我们能识别的正常字符,需要选择正确的编码方式。我们生活中遇到的乱码问题就是字节数据没有选择正确的编码方式造成的。
在Java 1.0中,类库的设计者首先限定与输入有关的所有类读应该从InputStream继承,而与输出有关的所有类都应该从OutputStream继承。其中,InputStream的作用是用来表示从不同数据源产生输入的类。OutputStream决定了输出所要去往的目标:字节数组、文件或管道。
字符流
字符流,传输数据的基本单位是字符。字符编码方式不同,相同字符占用的字节数可能不同。如ASCLL编码的字符,占一个字节;而UTF-8方式编码的字符,一个英文字符需要一个字节,一个中文需要三个字节。
Java 1.1对基本的I/O流类库进行了重大的修改。注意,Reader和Writer并不是为了替代InputStream和OutStream。尽管一些原始的“流”类库不再被使用(如果使用它们,则会收到编译器的警告信息),但InputStream和OutputStream在以面向字节形式的I/O中仍可以提供极有价值的功能,Reader和Writer则提供兼容Unicode与面向字符的IO功能。
字节流和字符流之间的转换
Java虽然支持字节流和字符流,但有时需要在字节流和字符流两者之间转换。InputStreamReader和OutputStreamWriter,这两个为类是字节流和字符流之间相互转换的类。其中InputSreamReader用于将一个字节流中的字节解码成字符。有两个构造方法:
// 功能:用默认字符集创建一个InputStreamReader对象
InputStreamReader(InputStream in);
// 功能:接收已指定字符集名的字符串,并用该字符创建对象
InputStreamReader(InputStream in,String CharsetName);
- 1
- 2
- 3
- 4
- 5
OutputStream用于将写入的字符编码成字节后写入一个字节流。同样有两个构造方法:
// 功能:用默认字符集创建一个OutputStreamWriter对象;
OutputStreamWriter(OutputStream out);
// 功能:接收已指定字符集名的字符串,并用该字符集创建OutputStreamWrite对象
OutputStreamWriter(OutputStream out,String CharSetName);
- 1
- 2
- 3
- 4
- 5
为了避免频繁的转换字节流和字符流,对以上两个类进行了封装。BufferedWriter类封装了OutputStreamWriter类;BufferedReader类封装了InputStreamReader类;封装格式如下:
BufferedWriter out=new BufferedWriter(new OutputStreamWriter(System.out));
BufferedReader in= new BufferedReader(new InputStreamReader(System.in);
- 1
- 2
- 3
字节流和字符流区别
(1) 字节流一般用来处理图像、视频、音频、PPT、Word等类型的文件。字符流一般用于处理纯文本类型的文件,如TXT文件等,但不能处理图像视频等非文本文件。用一句话说就是:字节流可以处理一切文件,而字符流只能处理纯文本文件。
(2) 字节流本身没有缓冲区,缓冲字节流相对于字节流,效率提升非常高。而字符流本身就带有缓冲区,缓冲字符流相对于字符流效率提升就不是那么大了。
BIO和NIO和AIO–IO模型
BIO:Blocking IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
NIO:Java 1.4 中引入了NIO。Java官网给出的含义是 New I/O,但其重点还是实现Non-Blocking IO。同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
AIO:JDK 1.7 中新增了一些与文件(网络)I/O相关的一些API,这些API被称为AIO(Asynchronous I/O)。Asynchronous IO 是 NIO 的升级(对JDK1.4中提出的同步非阻塞I/O(NIO)的增强),也叫 NIO2,实现了异步非堵塞 IO,AIO 的操作基于事件和回调机制。
BIO
BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO
NIO (New I/O): NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
AIO
AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。
序列化与反序列化
序列化是将Java对象转换为字节序列的过程。在序列化过程中,Java对象被转换为一个字节流。
反序列化是将字节序列转换回Java对象的过程。在反序列化过程中,字节序列被读取并转换回原始的Java对象。
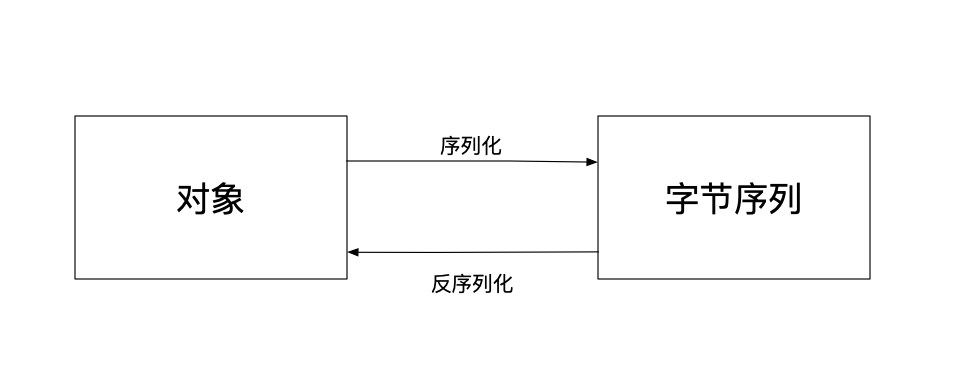
在梳理序列化与反序列化的应用场景前,需要明确的一点是,序列化和反序列化针对的都是对象,不是类。以下两个场景是序列化与反序列化常用的场景:
(1) 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中,也即持久化对象;
(2) 在网络上传送对象的字节序列,也即网络传输对象;
此外,有时为提供访问性能,会将对象存放到缓存中。
在Java中,如果一个对象要想实现序列化,必须要实现 Serializable 接口或 Externalizable 接口。Externalizable接口继承自 Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类采用默认的序列化方式。
序列化和反序列化的三方件很多,常用的有阿里巴巴的fastjson、Spring默认的序列化组件 jackson等。基于fastjson或jackson的实现,还请自行学习使用。
更多基于 Serializable 接口实现序列化或基于 Externalizable 接口实现序列化的示例代码,还请参考Java序列化与反序列化一文。
Java 异常
发现错误的理想时机是在编译阶段。然而,编译期间并不能找出所有的错误。对于编译期间无法找出的错误,必须在运行期间解决。这就需要错误源能通过某种方式,把适当的信息传递给某个接受者——该接受者直到如何正确处理这个问题。
改进的错误恢复机制是提供代码健壮性的最强有力的方式。Java使用异常来提供一致的错误报告模型,使得构件能够与客户端代码可靠地沟通问题。
Java的异常处理的目的在于通过使用少量的代码来简化大型、可靠的程序的生成,并且通过这种方式来保证程序没有未处理的错误。
Throwable类是所有异常类的基类。Throwable可以细分为两种类型(指从Throwable继承而得到的类型):Error用来表示编译时和系统错误;Exception是可以被抛出的基本类型,在Java类库、用户方法以及运行时故障中可能抛出Exception的异常。Exception又可细分为运行时异常(RuntimeException及其子类)和编译期异常(运行时异常之外的Exception),两者区别如下:
RuntimeException:程序运行过程中才可能发生的异常。一般为代码的逻辑错误。例如:类型错误转换,数组下标访问越界,空指针异常、找不到指定类等等。
运行时异常之外的Exception:编译期间可以检查到的异常,要求编码时必须必须处理(捕获或者抛到调用侧)这些异常,如果不处理,则编译无法通过。例如:IOException, FileNotFoundException等等。
其异常划分如下:
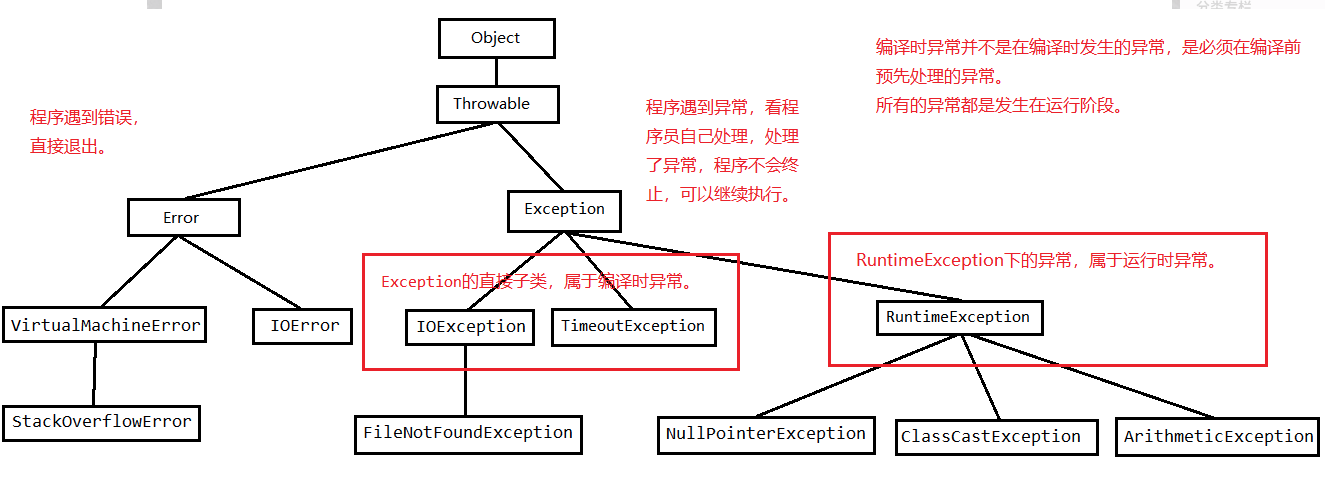
更多异常的知识总结可以参考Java异常。
Java 注解
Java注解又称Java标注,JDK 5.0 引入的一种注释机制,是可加入源代码的特殊语法元数据(所谓元数据,就是描述数据的数据)。Java注解为在代码中添加信息提供了一种形式化的方法,使我们可以在编辑之后的某个时刻(如编译期、运行时等)非常方便的使用这些数据(目的是使用这些数据)。
Java语言中的类、方法、变量、参数和包等都可以被标注。在编译器生成类文件时,注解可以被嵌入到字节码中。和Javadoc不同,Java注解可以通过反射获取注解内容。Java虚拟机可以保留注解内容,在运行时可以获取到注解内容。当然也支持自定义注解。
注解的作用
注解是一个辅助类,它在 Junit、Struts、Spring 等工具框架中被广泛使用(注解在框架中广泛使用)。注解的主要作用有:
(1) 编译检查
注解具有"让编译器进行编译检查的作用"。如@SuppressWarnings, @Deprecated 和 @Override 都具有编译检查作用。以@Override为例,若某个方法被 @Override 的标注,则意味着该方法会覆盖父类中的同名方法。如果有方法被 @Override 标识,但父类中却没有"被 @Override 标注"的同名方法,则编译器会报错。
(2) 在反射中使用
在反射的 Class,Method,Field 等中,有许多于注解相关的接口。这也意味着,我们可以在反射中解析并使用注解。
(3) 根据注解生成帮助文档
通过给注解注解加上 @Documented 标签,能使该注解标签(可以将注解称为标签,常见术语如打标签就是指在某某某上使用xxx注解)出现在 javadoc 中。
(4) 功能扩展。
注解支持通过自定义注解来实现一些其他功能。
更多注解的学习可以参考Java 注解一文。
Java 泛型
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。泛型的意义在于代码的复用。Java泛型使用擦除原理来实现,所以在使用泛型时,任何具体的类型信息都已被擦除。
更多泛型的学习可以参考Java 泛型一文。
Java泛型是使用擦除来实现的,这意味着在使用泛型时,任何具体的类型信息都会被擦除,唯一知道的就是此时在使用一个对象。擦除是导致泛型无法用于显式地引用运行时类型的操作。(擦除方式移除了类型信息)
引入擦除的主要原因是,实现非泛化代码到泛化代码的转变,以及在不破坏现有类库的情况下,将泛型融入Java语言。擦除使得现有的非泛型客户端能够在不改变的情况下继续使用。这是一个崇高的动机,因为它不会突然间破坏所有现有的代码。
擦除的代码是显著的。Java泛型不能用于显式地引用运行时类型的操作之中,如转型、instanceof操作和new表达式。
擦除丢失了在泛型代码中执行某些操作的能力。任何在运行时需要知道确切类型信息的操作将无法工作。针对这种情况,可以通过引入类型标签来对擦除进行补偿。这意味着,必须显式地传递类型的Class对象,以便在类型表达式中使用它。
更多泛型的学习可以参考Java泛型一文。
Java 反射
反射的概念是由 B. C. Smith 在 1982 年[首次提出](Procedural reflection in programming languages)的,主要是指程序可以访问、检测和修改它本身状态或行为的一种能力。
Java反射就是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性,并且能改变它的属性值。
反射是运行时类型信息(RunTime Type Information, RTTI)的一种实现方式。运行时类型信息使得程序开发人员可以在程序运行时发现和使用类型信息。
使用反射的基本步骤如下:
(1) 获取类型的Class对象;
(2) 基于Class对象获取类型元数据:Constructor类型、Field类型、Method类型;
(3) 基于Constructor类型、Field类型、Method类型访问成员。
Java提供Class类型、Constructor类型、Field类型、Method类型,帮助实现运行时访问类型实例上的成员。在获取成员时,根据成员的访问权限、声明位置,需要选用不同的方法,具体可以分为两类:
getXxx 获取包含父类的某个public的构造方法、字段、方法。
getDeclaredXxx 获取当前类的包含private访问权限的所有构造方法、字段、方法。
更多Java反射的学习可以参考Java反射概述、Java反射–实战篇。
Java 动态代理
动态代理的本质是反射。动态代理的常见实现方式有两种:JDK动态代理和CGLIB动态代理。JDK动态代理技术生成的代理类($Proxy0 extends Proxy implements XXX)时,继承了Proxy类,所以JDK动态代理类们无法实现对类的动态代理。如果需要实现对类的动态代理,可以使用CGlib技术。
更多动态代理的学习可以参考动态代理概述一文。
参考
《Java编程思想》(第四版) Bruce Eckel [译]陈昊鹏
https://github.com/JetBrains/jdk8u_hotspot/blob/master/src/share/vm/runtime/synchronizer.cpp#L560 hashcode实现
https://blog.csdn.net/changrj6/article/details/100043822 Java Object.hashCode()源码分析
https://www.sitepoint.com/how-to-implement-javas-hashcode-correctly/ hashcode
http://www.codeceo.com/article/java-hashcode-implement.html 如何正确实现Java中的hashCode方法
https://www.cnblogs.com/dolphin0520/p/3780005.html 深入剖析Java中的装箱和拆箱
https://blog.csdn.net/rmn190/article/details/1492013 String,StringBuffer与StringBuilder对比
https://www.runoob.com/w3cnote/java-different-of-string-stringbuffer-stringbuilder.html String,StringBuffer与StringBuilder
https://www.jianshu.com/p/aa4242253645 String字符串拼接性能优化
https://www.apiref.com/java11-zh/java.base/java/lang/invoke/StringConcatFactory.html Class StringConcatFactory
https://medium.com/javarevisited/java-compiler-optimization-for-string-concatenation-7f5237e5e6ed Java Compiler Optimization for String Concatenation
https://www.runoob.com/java/java-array.html Java 数组
https://cloud.tencent.com/developer/article/1860151 Java数组的定义与使用
https://www.jianshu.com/p/cd7a73e6bd78 Java CopyOnWriteArrayList详解
https://zhuanlan.zhihu.com/p/59601301 CopyOnWriteArrayList源码解析
https://blog.jrwang.me/2016/java-collections-deque-arraydeque/
https://www.jianshu.com/p/2f633feda6fb Java 容器源码分析之 Deque 与 ArrayDeque
https://www.cnblogs.com/msymm/p/9873551.html java之vector详细介绍
https://www.cnblogs.com/skywang12345/p/3308556.html Java 集合系列03之 ArrayList详细介绍(源码解析)和使用示例
https://www.cnblogs.com/skywang12345/p/3308807.html Java 集合系列05之 LinkedList详细介绍(源码解析)和使用示例
JDK 1.8源码
https://www.jianshu.com/p/2dcff3634326 Java集合–TreeMap完全解析
https://www.cnblogs.com/skywang12345/p/3310928.html#a2 Java 集合系列12之 TreeMap详细介绍(源码解析)和使用示例
https://zhuanlan.zhihu.com/p/21673805 Java 8系列之重新认识HashMap
https://www.lifengdi.com/archives/article/1198#ConcurrentHashMap_ji_cheng_guan_xi ConcurrentHashMap常用方法源码解析(jdk1.8)
https://www.cnblogs.com/xiaoxi/p/6170590.html Java集合之LinkedHashMap
https://blog.csdn.net/justloveyou_/article/details/71713781 Map 综述(二):彻头彻尾理解 LinkedHashMap
https://blog.csdn.net/sinat_36246371/article/details/53366104 Java中的HashSet
https://blog.csdn.net/educast/article/details/77102360 阻塞队列 BlockingQueue和阻塞双端队列 BlockingDeque
https://www.cnblogs.com/bjxq-cs88/p/9759571.html 北极猩球
Java 阻塞队列–BlockingQueue
https://my.oschina.net/wangzhenchao/blog/4566195 深入理解 JUC:SynchronousQueue
https://www.jianshu.com/p/d5e2e3513ba3 SynchronousQueue
https://blog.csdn.net/devnn/article/details/82716447 Java双端队列Deque使用详解
https://blog.csdn.net/ryo1060732496/article/details/88890075 双端队列之 ConcurrentLinkedDeque
https://www.jianshu.com/p/231caf90f30b 并发容器-ConcurrentLinkedQueue详解
https://blog.csdn.net/hanchao5272/article/details/79947785 基于CAS算法的非阻塞双向无界队列ConcurrentLinkedDueue
https://blog.csdn.net/zxc123e/article/details/51841034 双端阻塞队列(BlockingDeque)
https://blog.csdn.net/qq_38293564/article/details/80592429 LinkedBlockingDeque阻塞队列详解
https://www.w3schools.cn/java/java_inner_classes.asp Java 内部类 (嵌套类)
https://blog.csdn.net/liuxiao723846/article/details/108006609 Java内部类
https://blog.csdn.net/xiaojin21cen/article/details/104532199 单例模式之静态内部类
https://www.joshua317.com/article/212 Java内部类
https://www.runoob.com/java/java-inner-class.html Java内部类
https://developer.aliyun.com/article/726774 深入理解Java的内部类
https://www.cnblogs.com/shenjianeng/p/6409311.html java内部类使用总结
https://blog.csdn.net/liuxiao723846/article/details/108006609 Java内部类
https://segmentfault.com/a/1190000023832584 JAVA内部类的使用介绍
https://www.zhihu.com/tardis/bd/ans/672095170?source_id=1001 java中什么是序列化和反序列化?
https://blog.csdn.net/qq_44543508/article/details/103232007 java中的transient关键字详解
https://www.baidu.com/ 百度AI搜索
https://www.cnblogs.com/lqmblog/p/8530108.html 序列化和反序列化的简单理解
https://www.cnblogs.com/huhx/p/5303024.html java基础---->Serializable的使用
https://www.cnblogs.com/huhx/p/sSerializableTheory.html java高级---->Serializable的过程分析


