
- 1stm32与51 Proteus仿真初体验之点灯大师
- 2xcode在应用市场不能直接更新时,可以用以下方法:_xcode15更新网站
- 3Python 将Influxdb时序数据写入mysql库时遇到的问题
- 4计算机应届生有没有必要参加IT培训?_应届生计算机培训有没有必要
- 5保姆级 -- Zookeeper超详解
- 6对泛型的认识_symbol: variable roundingmode where t is a type-va
- 7微星迫击炮b660m使用intel arc a750/770显卡功耗优化方法_native pcie enable
- 8Github 2024-02-08 开源项目日报 Top9_我的电视 github
- 9小程序backgroundAudioManager.pause()无法停止播放的原因_taro.stopbackgroundaudio不生效
- 10java+idea+mysql采用医疗AI自然语言处理技术的3D智能导诊导系统源码
源神,启动!马斯克开源史上最大模型Grok,参数高达3140亿,可商用!_马斯克的grok多少大
赞
踩
马斯克真不愧是源神,自开源X的推荐算法以及特斯拉智能驾驶算法后,又说到做到,开源旗下大模型Grok!
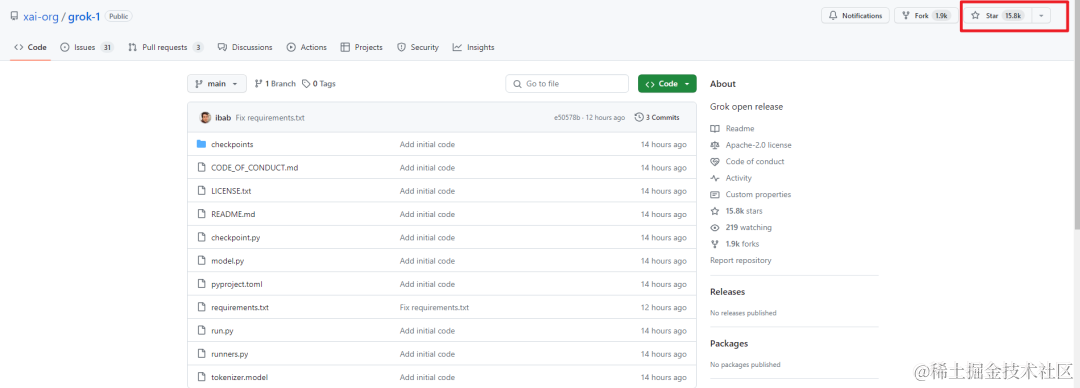
代码和模型权重已上线GitHub。官方信息显示,此次开源的Grok-1是一个3140亿参数的混合专家模型,远超OpenAI GPT-3.5的1750亿。,就是说,这是当前开源模型中参数量最大的一个,遵照Apache 2.0协议开放模型权重和架构。
消息一出,Grok-1的GitHub仓库已揽获15K标星,并且还在库库猛涨。
GitHub地址:https://github.com/xai-org/grok-1?tab=readme-ov-file
目前Grok-1的源权重数据大小大约为300GB。
表情包们,第一时间被吃瓜群众们热传了起来。

而ChatGPT本Chat,也现身Grok评论区,开始了和马斯克新一天的斗嘴……
Grok-1介绍
此次开源,xAI发布了Grok-1的基本模型权重和网络架构。
具体来说是2023年10月预训练阶段的原始基础模型,没有针对任何特定应用(例如对话)进行微调。
Grok-1是一个混合专家(Mixture-of-Experts,MOE)大模型,这种MOE架构重点在于提高大模型的训练和推理效率,形象地理解,MOE就像把各个领域的“专家”集合到了一起,遇到任务派发给不同领域的专家,最后汇总结论,提升效率。决定每个专家做什么的是被称为“门控网络”的机制。

在GitHub页面上,官方特别强调了Grok模型的巨大规模(总共314B参数),这意味着运行Grok需要强大的GPU和内存支持。
此外,模型的权重文件以磁力链接的形式提供,文件大小接近300GB,这也是一个相当庞大的数字。
除了参数规模之外,Grok在工程架构上也颇具创新精神——它并没有选择常见的Python、PyTorch或Tensorflow,而是采用了Rust编程语言和新兴的深度学习框架JAX。
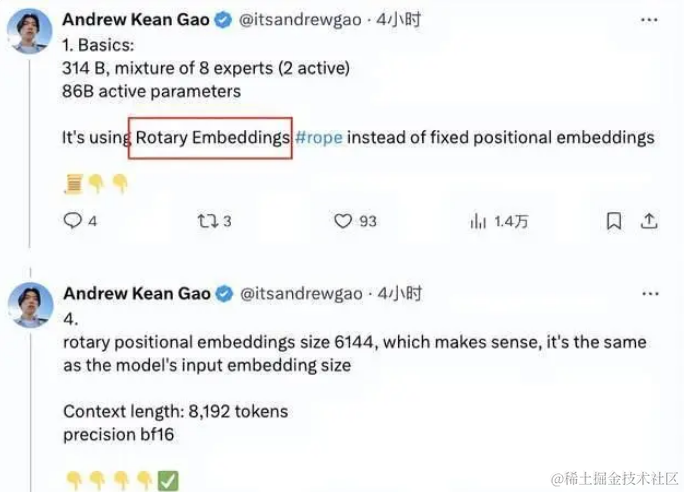
除了官方通告外,一些专家通过深入分析代码等方式揭示了更多关于Grok的技术细节。例如,斯坦福大学的Andrew Kean Gao就对Grok的技术细节进行了深入解释。
他指出,Grok采用了旋转的embedding方式,而非传统的固定位置embedding,旋转位置的embedding大小为6144,与输入embedding相同这种创新方法为Grok的性能和效率提供了新的可能性.
当然,还有更多的参数信息:

-
Transformer层数为64,每层都有一个解码器层,包含多头注意力块和密集块;
key value大小为128;多头注意力块中,有48 个头用于查询,8 个用于KV,KV 大小为 128;密集块(密集前馈块)扩展因子为8,隐藏层大小为32768。窗口长度为8192tokens,精度为bf16Tokenizer vocab大小为131072(2^17),与GPT-4接近;embedding大小为6144(48×128);
除了Gao,还有英伟达AI科学家Ethan He(何宜晖)指出,在专家系统的处理方面,Grok也与另一知名开源MoE模型Mixtral不同,Grok对全部的8个专家都应用了softmax函数,然后从中选择top2专家,而Mixtral则是先选定专家再应用softmax函数。
而至于有没有更多细节,可能要看官方会不会发布进一步的消息了,另外,值得一提的是,Grok-1采用的是Apache 2.0 license,也就是说,支持商用。

