
热门标签
热门文章
- 1无人驾驶学习笔记--路径规划(二)【Dubins曲线和Reeds-Shepp曲线】_dubins曲线,这对无人车
- 2AIGC时代 可演进的私有云将蔚然成风
- 3windows11 Administrator帐户自动被锁定解决方法_为安全考虑 已锁定该用户账户,原因是登录尝试
- 4程序员们一个一个的都挺神的,堪称 35 岁毕业之后再就业的标兵,不服不行_程序员再就业
- 5MySQL总结--MVCC(read view和undo log)_mvcc read
- 6【记录】一个深度学习算法工程师的成长之路(思考和方法以及计划)
- 7转帖-仙剑奇侠传三 (同名剧情小说)_龙葵h文
- 8Docker实战教程 第2章 Docker基础
- 9python vector_不朽 C++ 为新贵 Python 应用提速 8000 倍!
- 10微信小程序 -- ios 底部小黑条安全距离兼容解决方案(转载)_微信小程序设置iphone安全距离不生效
当前位置: article > 正文
参数高效微调(PEFT)技术概览
作者:weixin_40725706 | 2024-04-21 13:11:21
赞
踩
参数高效微调(PEFT)技术概览
参数高效微调(PEFT)技术概览
在大型语言模型(LLMs)的世界里,参数量庞大,通常在70亿至700亿之间。这些模型的自监着训练成本高昂,对公司可能意味着高达1亿美元的支出。而对于资源相对有限的研究者和公司来说,如何以较低的成本改进这些模型成为了一个关键问题。参数效率微调(PEFT)技术因此应运而生,通过对模型的小部分进行精细调整,实现对特定任务的优化。
Sean Smith在其文章中综合介绍了Hugging Face、谷歌Vertex AI和OpenAI等机构使用的PEFT技术。通过这篇文章,读者能够基本了解PEFT技术的概念,并区分它们之间的不同。
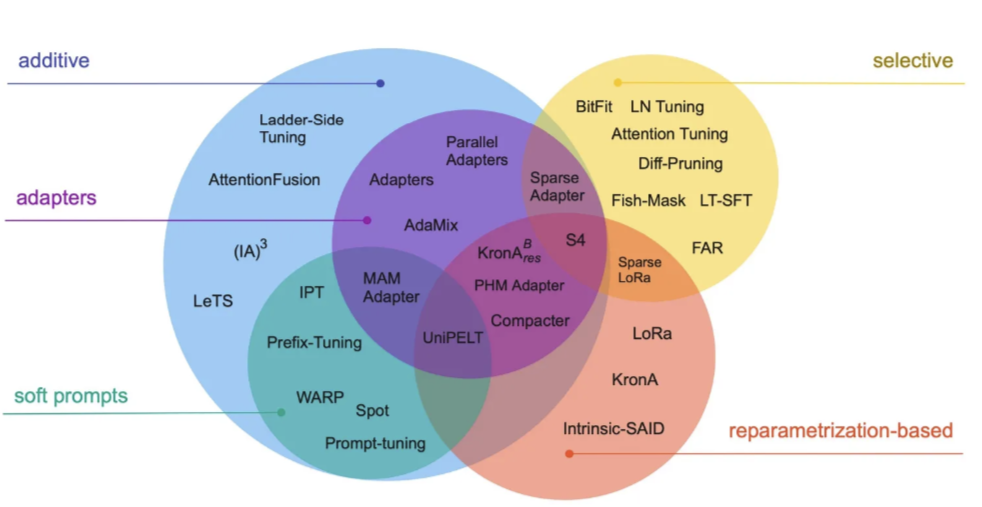
PEFT技术回顾与方法对比:
-
添加法(Additive Methods):最直接的方法,通过添加额外参数或网络层来增强模型。
- 适配器(Adapters):在Transformer子层后添加小型全连接网络。
- (IA)³法:通过新参数增强Transformer块以改善注意力机制。
-
软提示(Soft-Prompts):避免硬编码数据集的创建,采用连续表示法。
- 提示调整(Prompt-Tuning):通过可学习的张量优化软提示。
- 前缀调整(Prefix Tuning):与提示调整相似,但适用于模型的所有层。
- P调整(P-Tuning):使用LSTM编码提示,增强软提示之间的依赖关系。
-
重参数化方法(Reparameterization-Based Methods):寻找低维表示的权重矩阵。
- LoRa:通过学习较小维度矩阵来更新权重矩阵,减少需要学习的参数量。
-
选择性方法(Selective Methods):选择某些参数进行更新,不更新其他参数。
- AdaLoRa:结合重参数化和选择性方法的混合方法,通过重要性评分来动态分配参数预算。
文章最后,Smith鼓励读者通过Hugging Face等平台进行PEFT技术实践,旨在帮助读者实现成本效益较高的模型微调。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/463192
推荐阅读
相关标签

