
热门标签
热门文章
- 1HASH和HMAC(5):SHA-384、SHA-512、SHA-512/224和SHA-512/256算法原理_sha-512流程图
- 2如何一键展示全平台信息?Python手把手教你搭建自己的自媒体展示平台
- 3【C++】位图 | 布隆过滤器_c++实现布隆过滤器
- 4C++生产者消费者模式(条件变量和互斥锁)
- 5python查找及安装本地数据包_python拉取本地安装包
- 6【MYSQL学习】数据库系统_修改主键改变的是逻辑模式
- 7数据结构与算法面试题80道
- 8社保个税新政全解读(工资表政策变化收入对比社保常见问题实用工具)
- 9Spark 10年,作者 Matei 在 Spark + AI Summit 2020 上深情回顾,Photon 引擎首次曝光
- 10Anconda + CUDA + torch安装教程(python3.8)_cuda11.8 python3.8d
当前位置: article > 正文
BERT、BART、T5 等LLM大语言模型的比较分析_bart模型和t5
作者:weixin_40725706 | 2024-04-23 12:15:31
赞
踩
bart模型和t5
探索语言模型
介绍
在这篇博文中,我将讨论 BERT、BART 和 T5 等大型语言模型。到 2020 年,法学硕士领域取得的重大进展包括这些模型的开发。BERT和T5是Google开发的,BART是Meta开发的。我将根据这些型号的发布日期按顺序介绍它们的详细信息。在上一篇博客文章自然语言处理的自回归模型中,我讨论了生成式预训练 Transformer 的自回归性质。在这篇博客中,我将比较这些模型与自回归模型的不同之处。因此,如果您还没有查看过上一篇文章,请去查看一下。BERT 论文于 2018 年发布,BART 于 2019 年发布,T5 于 2020 年发布。我将按照相同的顺序介绍论文的详细信息。
Transformer 的双向编码器表示 (BERT)
BERT模型基于多层双向Transformer编码器。BERT 旨在通过在所有层中联合调节左右上下文来预训练未标记文本的深度双向表示。因此,只需一个额外的输出层即可对预训练的 BERT 模型进行微调,以创建最先进的模型。BERT 使用屏蔽语言模型预训练目标来克服单向性约束。BERT的预训练也是通过下一句预测来完成的。
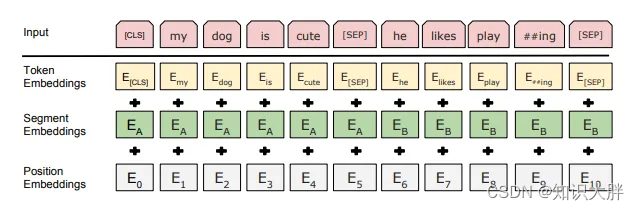
与 Transformer 相比,BERT 的输入表示是 token 嵌入、段嵌入和位置嵌入的总和。还添加了特殊分类标记和句子分隔符标记。令牌嵌入是词汇量为 30,000 的词块嵌入。预训练时使用的数据集是BookCorpus和Wikipedia。
屏蔽语言模型
在MLM预训练中,取输入序列的15%的单词。其中 80% 被屏蔽,10% 被随机单词替换,10% 保持不变。因此&#
推荐阅读
相关标签

