
- 1java键盘输入_java 键盘输入语句怎么写
- 2低代码开发之腾讯云微搭工具
- 3Meta Llama3 炸裂登场:一夜刷屏AI界,基准测试中一骑绝尘,GPT-4 Turbo遭遇强劲对手_llama3 api
- 4对话蚂蚁李建国:当前AI写代码相当于L2.5,实现L3后替代50%人类编程
- 5git 本地与远程仓库出现代码冲突解决方法_git 本地库和远程库冲突
- 6Linux就这个范儿 第9章 特种文件系统
- 7SpringBoot 环境使用 Redis + AOP + 自定义注解实现接口幂等性
- 8国服浪潮服务器操作系统——KeyarchOS多容器架设体验心得_激活keyarchos
- 9租用AutoDL服务器+使用vscode进行SSH连接+解决连接好后无法使用code命令打开项目(报错内容:bash: code: command not found)
- 10Debezium系列之:Debezium2.X之Oracle数据库的Debezium连接器_io/debezium/connector/oracle/rest/debeziumoracleco
【AAAI2023】基于神经跨度的持续命名实体识别模型
赞
踩
论文标题:A Neural Span-Based Continual Named Entity Recognition Model
论文链接:https://arxiv.org/abs/2302.12200
代码:https://github.com/Qznan/SpanKL
- @inproceedings{zhang2023spankl,
- title={A Neural Span-Based Continual Named Entity Recognition Model},
- author={Zhang, Yunan and Chen, Qingcai},
- booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
- year={2023}
- }

导读
能够持续学习(CL)的命名实体识别(Named Entity Recognition,NER)在实际应用中特别有价值,尤其是在实体类型不断增加的领域,比如个人助手应用。与此同时,NER的学习范式不断发展,采用了新的模式,如基于跨度的方法。然而,这些新方法在持续学习方面的潜力尚未被充分探索。
我们提出了一种名为SpanKL的命名实体识别(NER)模型,该模型具备持续学习(CL)的能力。SpanKL模型是一种简单而有效的基于跨度的模型,结合了知识蒸馏(KD)以保留记忆和多标签预测以防止CL-NER中的冲突。与先前的序列标注方法不同,SpanKL在跨度和实体级别上具有固有的独立建模,通过设计的一致优化促进了每个增量步骤上的学习,并减轻了遗忘现象。
在来自OntoNotes和Few-NERD的合成CL数据集上进行的实验证明,SpanKL在许多方面明显优于先前的最先进方法,同时在从CL到上限的差距方面表现最小,显示出其高实用价值。
本文贡献
我们构建了一个简单的基于跨度的体系结构,以实现CL-NER中的连贯优化,这可以作为一个即时和强大的经验基线。
我们对最近的模型的不同合成设置的比较,并通过未来研究的一个新的基准来探索更现实的CLNER场景。
本文方法
问题定义
我们遵循最近的工作,在类增量设置下形式化CL-NER。给定一系列的任务
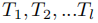
和相应的实体类型
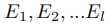
,为了持续学习,第 l 个任务有自己的训练集
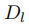
,只注释的实体类型
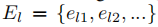
。不同任务中的实体类型是不重叠的,例如,如果在T1中学习的,那么在其他任务中就不会学习。但是,无论是从一个还是不同的任务中学习到的,对不同实体类型的提及都允许重叠,也就是说,对嵌套实体的任何情况都没有任何限制。
在第一步(l = 1)中,我们从头开始在D1上训练模型M1,以识别类型为E1的实体。在随后的第l个增量步骤(l > 1)中,我们在Dl上训练Ml,基于先前学到的模型
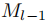
,以识别到目前为止学到的所有实体类型的实体
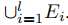
。这种形式化为持续学习命名实体识别提供了清晰的框架,使得模型能够逐步学习新任务和实体类型,确保了任务和实体类型之间的一致性。
SpanKL NER 模型
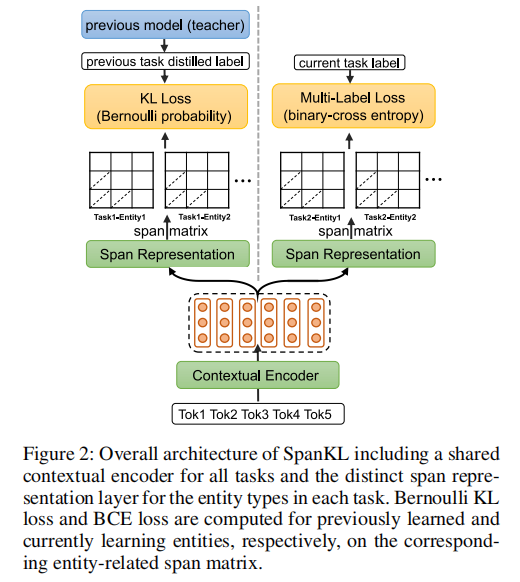
我们引入了简单而有效的SpanKL(见图2),以便顺序学习每个任务。给定一个包含n个标记[x1,x2,…,xn]的输入句子X,我们定义
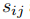
为由以 xi 开始且以 xj 结束的连续标记组成的跨度,其中1⩽i⩽j⩽n。假设在第 l 个增量步骤有 K 个实体类型需要学习,SpanKL 的目标是通过跨度建模将每个跨度表示为
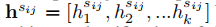
,并对这K个实体类型执行二元分类。它包括上下文编码器、跨度表示层和带有知识蒸馏的多标签损失层,如下所述。
上下文编码器(Contextual Encoder)捕捉输入句子中标记之间的依赖关系,可以使用广泛使用的CNN、RNN或PLM模型实现。我们使用
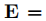
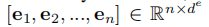
表示嵌入 X 后的输入的嵌入向量,然后将其馈送到上下文编码器以获得每个标记的上下文化隐藏向量
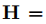
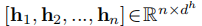
,如下所示:
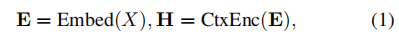
编码器对所有任务共享。
Span Representation Layer执行跨度建模,如下所示:
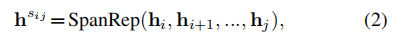
其中跨度表示是从相关的标记表示生成的,各种设计都得到了充分的探索。
由于实体的边界标记最具信息性,Yu、Bohnet和Poesio(2020年)使用biaffne交互模型同时对组成跨度的标记的开始和结束特征空间进行建模。Xu等人(2021年)进一步将实体类型的特征空间建模为多头(加法)注意力中的头部,Su(2021年)使用多头(点积)注意力。我们采用后者的简单方式,完全将这三个特征空间的权重分离。
具体而言,对于每个实体类型,在缩放的点积交互之前使用两个不同的单层前馈网络(FFN)进行开始和结束建模(总共有2K个不同的FFN),如下所示:
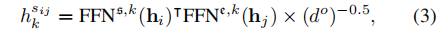
其中s、e、k表示开始、结束和第k个实体类型。
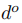
是所有2K个FFN的输出维度。我们相信,对于每个跨度(即在跨度和实体级别),对每个实体类型进行清晰分离的建模可以促进学习和蒸馏,并减轻多个任务之间的干扰。
随着任务的增加,我们简单地添加更多专门用于新任务的跨度表示层(基本上是内部的FFN)。Span Matrix 的概念引入是为了更好地描述(见图2)。我们将所有与第k个实体相关的hsijk组织成矩阵Mk的上三角区域,其中
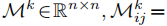
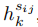
。
多标签损失层
为了确保前向可比性,我们期望将最终的跨度分类制定为多标签预测。具体而言,在跨度矩阵中,我们在预测的logit上使用sigmoid激活,然后计算与真实标签的二元交叉熵(BCE)损失。
与常见的多类方式(即使用softmax激活的交叉熵损失)相比,该方法在将logit标准化为单个或多个任务的概率时,可以将不同的实体类型分离开来。每个实体类型都是独立进行二元分类,BCE损失的计算方式如下:

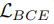
仅在当前实体类型的跨度矩阵上进行计算。
知识蒸馏
为了确保向后的可比性,我们使用知识蒸馏(KD)来防止遗忘旧的实体。在第 1 个增量步( l > 1),我们使用先前学习的模型
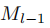
(教师)对整个当前训练集
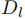
到
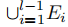
学习的实体类型进行一次性预测。这就产生了伯努利分布,作为每个旧实体类型的每个跨度的软蒸馏标签
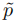
。这些伪标签用于计算伯努利KL散度损失,当前的模型ML(学生)为:

在每个步骤进行一次性预测后,用于多个时期的训练的最终损失是两个损失的加权和:
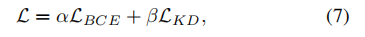
其中,α和β是两个损失的权重。这种损失的组合有助于确保对新任务的学习的同时,保留对旧实体类型的知识。
实验
实验结果
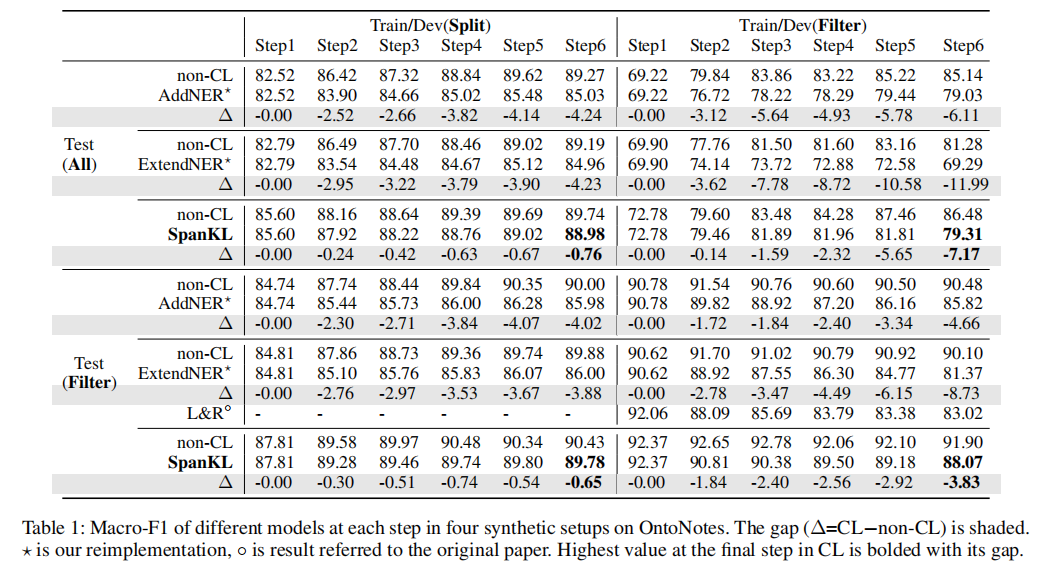

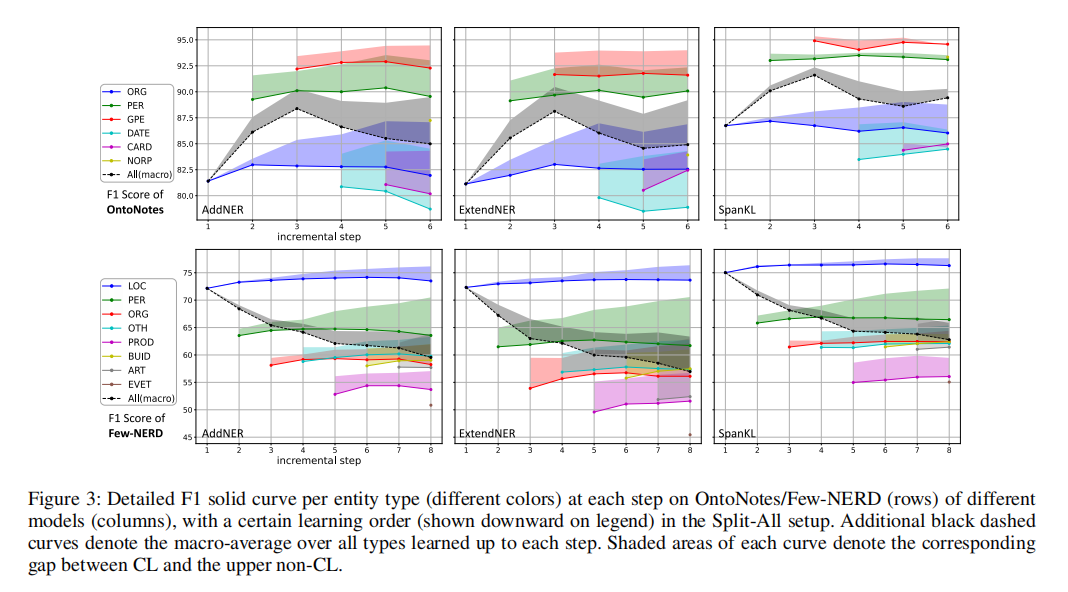
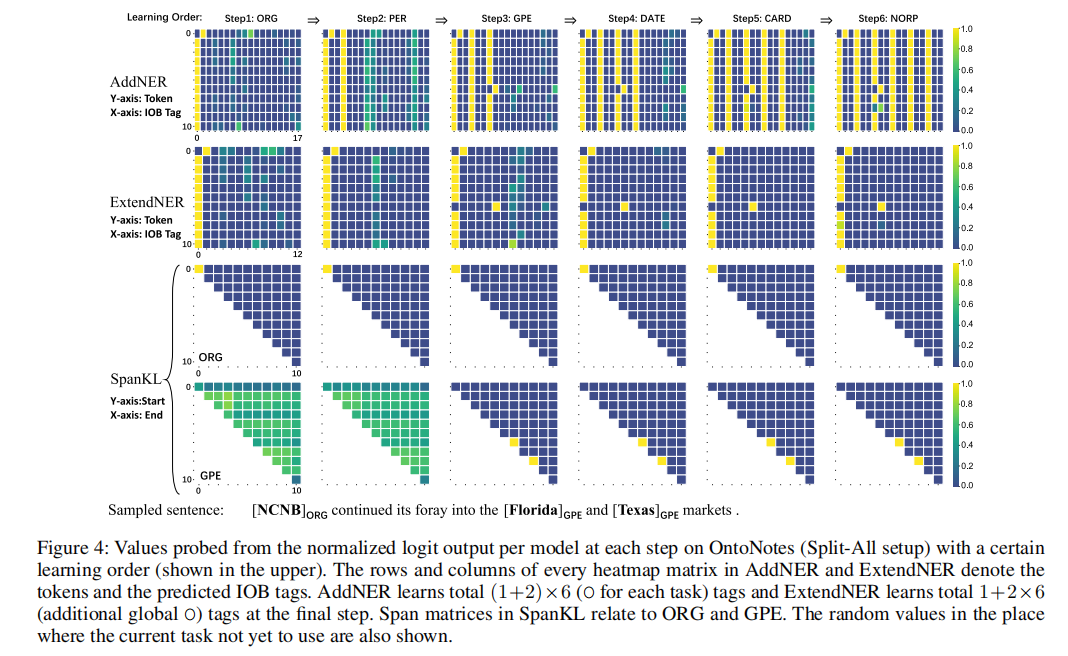
结论
在本文中,我们提出了一个名为SpanKL的神经跨度模型,作为类增量设置下持续学习命名实体识别(CL-NER)的强大基线。我们在实证研究中发现,跨度和实体级别的独立建模在顺序学习实体类型时是适用的,特别是当与知识蒸馏技术和多标签预测协同使用时,可以轻松实现一致的优化。SpanKL在OntoNotes上几乎接近持续学习的上限,尤其是在每个任务通常只有一个实体的情况下,显示了其在实际应用中的潜力。在更为复杂的FewNERD数据集上仍然是最优秀的。
此外,我们还对现有的不同合成设置进行了对齐和比较,从而验证了AddNER相对于其他序列标注模型更可取,为未来的研究提供了有力的参考。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓


