
热门标签
热门文章
- 1在IDE中刷LeetCode,编码调试一体化,刷题效率直线up!
- 2Python深度学习十大核心算法!_深度学习算法
- 3【Flutter】Flutter CLI (4):命令 flutter build 构建应用_flutter build 命令
- 4LSTM分类模型
- 5R3LIVE代码详解(一)_r3live代码解析
- 6spring中的事务传播机制_propagation.not_supported
- 7python3爬取网易云歌单数据清洗_实例 | 使用网易云音乐数据演示数据整合与数据清洗...
- 8探究flask中的celery后台任务_flask_celeryext
- 9用过Apifox这个API接口工具后,确实感觉postman有点鸡肋......_apifox接口生成太垃圾了
- 10springboot+mysql+微信小程序点餐系统-计算机毕业设计源码65933_面馆点餐小程序mysql源代码
当前位置: article > 正文
GPT-SoVITS 本地搭建踩坑_gpt-sovits本地部署
作者:weixin_40725706 | 2024-04-24 20:08:28
赞
踩
gpt-sovits本地部署
前言
传言GPT-SoVITS作为当前与BertVits2.3并列的TTS大模型,于是本地搭了一个,简单说一下坑。
搭建
下载
到GitHub点击此处下载
https://github.com/RVC-Boss/GPT-SoVITS
解压
解压到全英文目录
VSCode打开
使用VSCode打开,切到conda并clone一个之前BertVits的环境(没环境的自己先做一个Python3.10的配好PyTorch的)
安装依赖包
使用下面语句安装依赖
pip install -r requirements.txt
- 1
修改内容
根据issues内大家讨论的结果,这样操作是实测可行的,但是之后作者应该会优化,截止发文这么改是没问题的,以后可能不用改了
https://github.com/RVC-Boss/GPT-SoVITS/issues/26
1.重新安装版本
输入下面的指令重新安装一下对应版本的
pip install funasr==0.8.7
pip install modelscope==1.10.0
- 1
- 2
2.修改文件内容
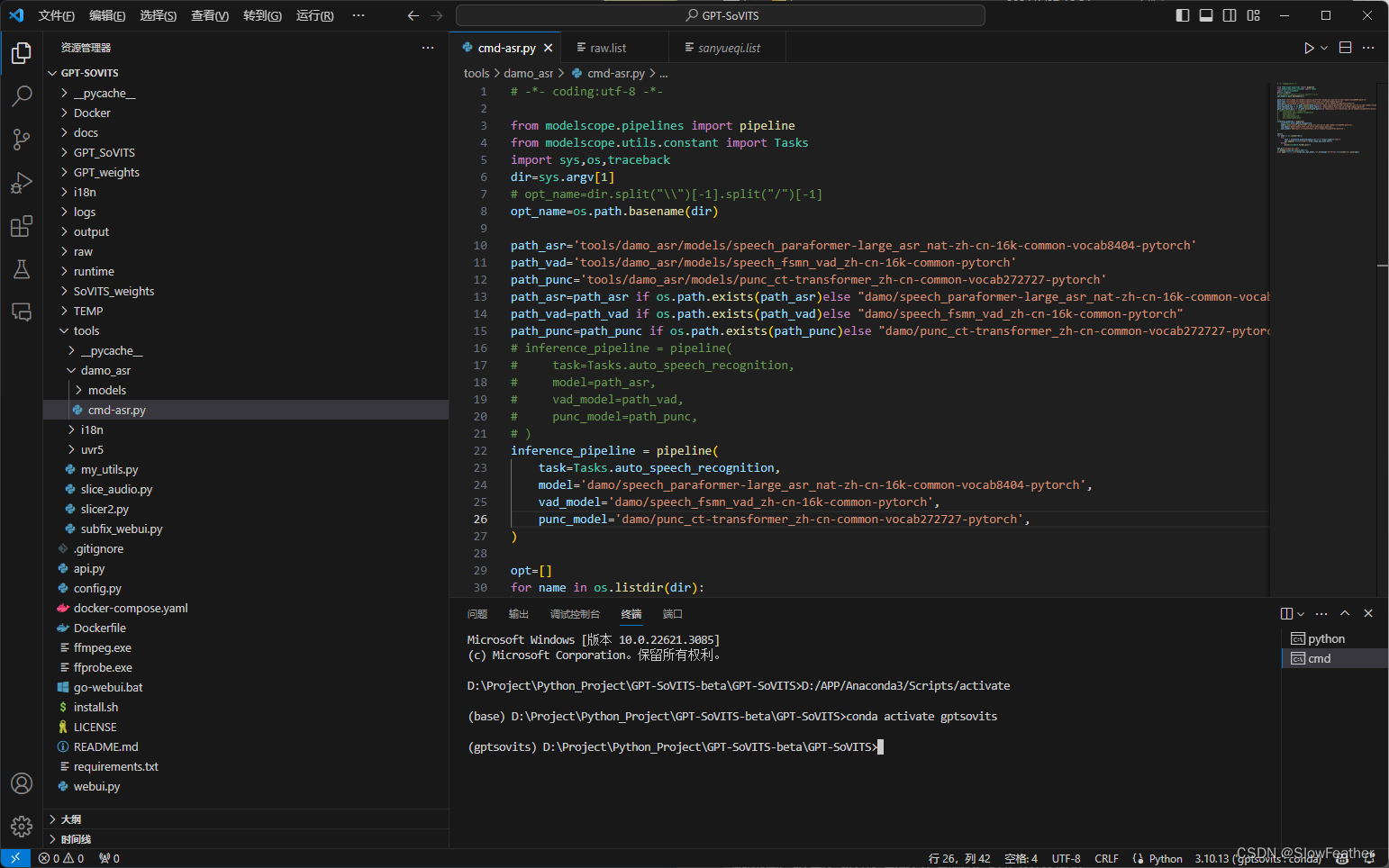
将 tools\damo_asr\cmd-asr.py 文件中的
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='tools/damo_asr/models/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch',
vad_model='tools/damo_asr/models/speech_fsmn_vad_zh-cn-16k-common-pytorch',
punc_model='tools/damo_asr/models/punc_ct-transformer_zh-cn-common-vocab272727-pytorch',
)
- 1
- 2
- 3
- 4
- 5
- 6
改成
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch',
vad_model='damo/speech_fsmn_vad_zh-cn-16k-common-pytorch',
punc_model='damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch',
)
- 1
- 2
- 3
- 4
- 5
- 6
根据我的研究,原因是 git clone 的那几个模型的配置文件和它自动下载的内容不一样
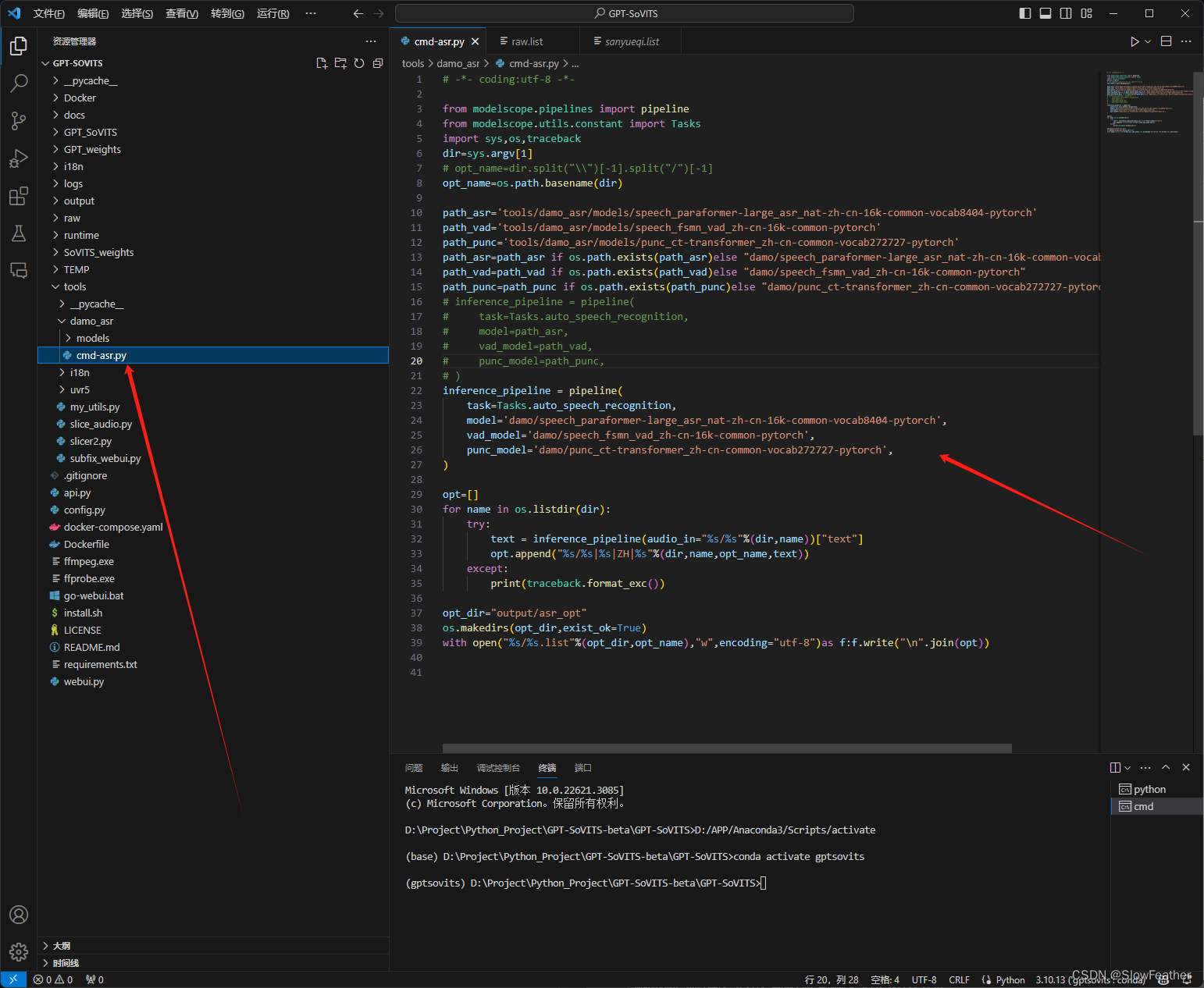
修改后源码如下
# -*- coding:utf-8 -*- from modelscope.pipelines import pipeline from modelscope.utils.constant import Tasks import sys,os,traceback dir=sys.argv[1] # opt_name=dir.split("\\")[-1].split("/")[-1] opt_name=os.path.basename(dir) path_asr='tools/damo_asr/models/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch' path_vad='tools/damo_asr/models/speech_fsmn_vad_zh-cn-16k-common-pytorch' path_punc='tools/damo_asr/models/punc_ct-transformer_zh-cn-common-vocab272727-pytorch' path_asr=path_asr if os.path.exists(path_asr)else "damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch" path_vad=path_vad if os.path.exists(path_vad)else "damo/speech_fsmn_vad_zh-cn-16k-common-pytorch" path_punc=path_punc if os.path.exists(path_punc)else "damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch" # inference_pipeline = pipeline( # task=Tasks.auto_speech_recognition, # model=path_asr, # vad_model=path_vad, # punc_model=path_punc, # ) inference_pipeline = pipeline( task=Tasks.auto_speech_recognition, model='damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch', vad_model='damo/speech_fsmn_vad_zh-cn-16k-common-pytorch', punc_model='damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch', ) opt=[] for name in os.listdir(dir): try: text = inference_pipeline(audio_in="%s/%s"%(dir,name))["text"] opt.append("%s/%s|%s|ZH|%s"%(dir,name,opt_name,text)) except: print(traceback.format_exc()) opt_dir="output/asr_opt" os.makedirs(opt_dir,exist_ok=True) with open("%s/%s.list"%(opt_dir,opt_name),"w",encoding="utf-8")as f:f.write("\n".join(opt))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
运行
在环境中输入,即可正常启动
python webui.py
- 1
总结
能够有感情的朗读了,不错
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/481336
推荐阅读
相关标签

