
- 1一起运行脑电信号(EEG)源码(2)-deap dataset_deapdataset
- 2Prometheus接入AlterManager配置邮件告警(基于K8S环境部署)
- 3【计算机网络】计网学习——总览(超多图+超详解)_计算机网络结构图
- 4快速掌握MongoDB数据库(入门一条龙)_mongodb数据库入门
- 5Go 限流控制《滑动窗口&令牌桶》:time/rate、TokenLimit、PeriodLimit_go语言接口滑动窗口
- 6kafka下载安装
- 7基于springboot实现智能推荐的电影推荐小程序演示【附项目源码】_springboot智能推荐
- 8小航编程题库2022年NOC决赛图形化(小低组)(含题库教师账号)_noc编程大赛真题
- 9kitti之ros可视化_学习笔记--第10课:添加id到3d侦测盒上方_kitti_utils
- 10阿里云大学考试Java中级题目及解析-java中级
lstm原文_《基于序列和树结构的LSTM的端到端关系抽取》论文笔记
赞
踩

End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures
原文链接:https://blog.csdn.net/qq_32782771/article/details/88119042
一、Background
抽取实体之间的语义关系是信息抽取和NLP中一项很重要且经过充分研究的任务。传统的方法将这个任务以pipeline的方式分为两个子任务:NER和RE。但最近的研究表明端到端的联合抽取模型能取得更好的性能,因为实体与关系密切相关。之前的联合抽取模型大多采用基于特征的结构化学习。另一种方法是基于端到端的神经网络模型自动学习特征。
存在两种通过神经网络表示实体间关系的方法:基于RNN的和基于CNN的。RNN可以直接表示基本的语言结构信息,比如词的顺序信息,依存句法信息。尽管RNN可以表示上述信息,但是在关系分类任务中,之前的基于RNN的方法的性能低于基于CNN的方法。这些以前基于LSTM的系统主要包括有限的语言结构和神经架构,并且不会对实体及其关系共同建模。作者通过基于更丰富的LSTM-RNN架构的对实体和关系进行端到端建模,性能超过了state-of-the-art,这些架构包含互补的语言结构。
二、Motivation
在关系抽取中词序信息和树结构信息是可以互补的。比如,在句子“This is …, one U.S. source said”中,词之间的依存信息不足以预测‘source’和‘U.S.’之间的‘ORG-AFF’关系。很多传统的基于特征工程的关系分类方法从序列和解析树中抽取特征。然而,之前基于RNN的模型仅关注于这些语言结构的一种。
因此,作者提出了一种新颖的端到端模型,基于词序信息和依存树结构信息来抽取实体间的关系。该模型使用了双向的LSTM和tree-LSTM结构,同时抽取实体及其关系。 作者的模型首先检测实体,然后抽取检测到的实体的关系。与传统的增量式端到端关系抽取模型不同,我们的模型在训练中还加入了两个功能:实体预训练——预训练实体模型,预定抽样——在一定概率的情况下用gold labels来代替预测标签。这些功能缓解了训练早期阶段实体检测性能低的问题,并允许实体信息进一步帮助下游关系分类任务。
三、Model
模型的架构图如图一所示。模型主要由三层表示层组成:embedding layer、sequence layer、dependency layer。在解码过程中,首先是在sequence layer中从左到右检测实体,然后在dependency layer实现关系分类,其中每一颗基于LSTM的子树代表被检测实体的候选关系。解码整个模型结构后,通过BPTT更新参数。embedding layer和sequence layer的参数使共享的。
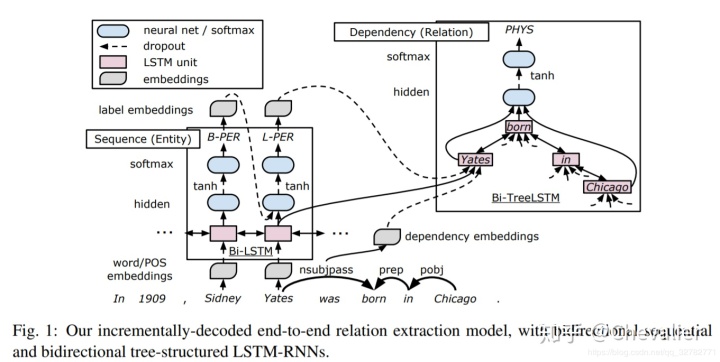
3.1 Embedding Layer
embedding layer处理向量表示。nw,np,nd,ne表示向量维度,v(w),v(p),v(d),v(e)分别将词转为词向量、POS标签、依存类型、实体标签。
3.2 Sequence Layer
序列层使用来自嵌入层的表示来表示线性序列中的单词,该层通过双向LSTM表示句子上下文信息。第t个单词的LSTM单元的输入是对应的词向量和POS向量的拼接:xt=[vt(w);vt(p)]
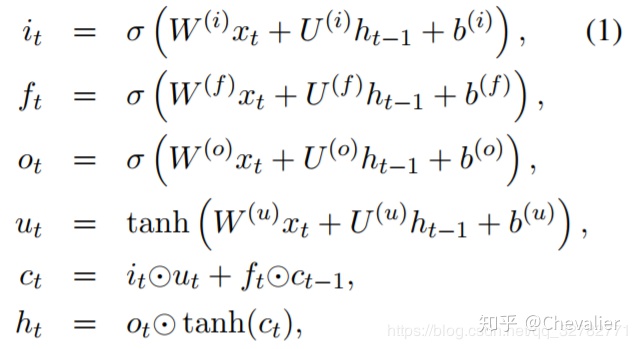
3.3 Entity Detection
将实体检测当做序列标注问题。标注机制为BILOU(Begin,Inside,Last,Outside,Unit),每个实体标签表示了实体的类型和单词在实体中的位置。经过sequence layer之后,紧接着全连接层和输出层进行实体检测。可以看到,考虑到标签依赖问题,在全连接层中的输入是双向LSTM的输出与上一个词的标签拼接在一起。
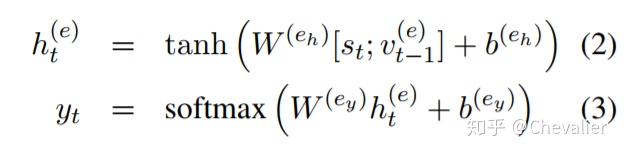
3.4 Dependency Layer
dependency layer在依存句法树中表示两个目标词的关系信息,并负责关系的特定表述。该层主要关注依存句法树中一对目标词的最短路径,因为这些路径信息已被证明对关系分类是有用的。
使用双向tree-LSTM结构通过捕捉目标词对周围的依赖结构来表示候选关系。这种双向结构不仅传播来自叶子节点的信息而且传播来自根节点的信息到每个节点。这对于关系分类来说是很重要的,它充分利用了树底部的参数节点。Tai el al.提出两种基于树结构的LSTM的变体,无法表示具有可变数量类型的孩子节点的目标结构:Child-Sum Tree-LSTM无法处理types和N-ary Tree,假定有固定数量的孩子节点。因此作者提出了一种新的基于树结构的LSTM:相同类型的孩子节点共享权重矩阵,允许可变数量的孩子节点。因此,对于拥有C(t)的孩子节点的t节点在LSTM单元的计算公式如下:
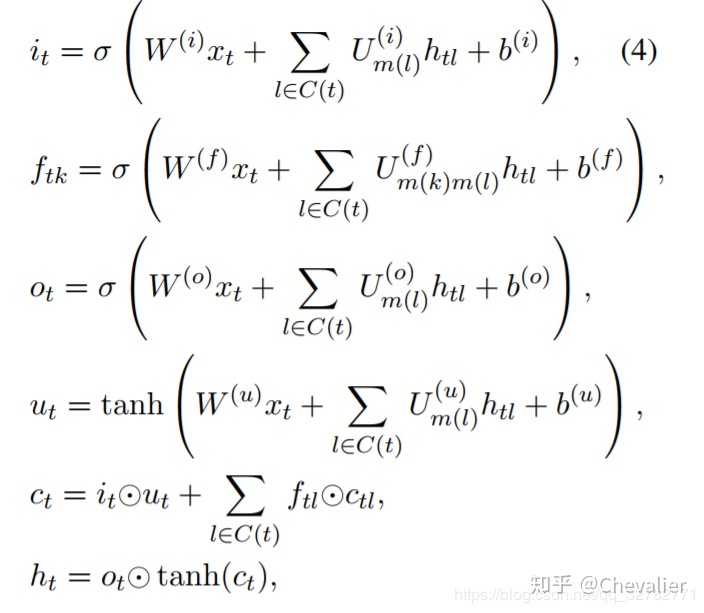
为了研究合适的结构来表示目标词对的关系,作者在三种结构上做了实验。最短路径结构(SP-Tree),捕捉了目标词对之间的核心依存路径信息,广泛地运用于关系分类模型中。作者还尝试了其它两种依存结构:SubTree和FullTree。SubTree表示目标词对的最低共同祖先下的子树。这为SPTree中的路径和单词对提供了额外的修饰符信息。FullTree是整颗依存句法树。这捕获了整个句子的上下文。
3.5 Stacking Sequence and Dependency Layers
将dependency layer堆叠到sequence layer上,将词序列和依存树的结构信息合并到输出中。dependency layer中的LSTM单元在第t个词的输入是:xt=[st;vt(d);vt(e)]
3.6 Relation Classification
我们使用检测到的实体的最后几个单词的所有可能组合来递增地构建候选关系。对每一个候选关系,我们实现了对应于候选关系中词对之间路径的依赖层,并且NN接收从依存句法树层的输出构造的关系候选向量,然后预测关系标签。如果检测到的实体是错的或者实体对之间没有关系,那么我们就词对的关系称作为负关系。我们按类型和方向表示关系标签,除了没有方向的负关系。
关系候选向量通过以下向量拼接构造形成:dp=[↑hpA;↓hp1;↓hp2]
和实体检测类似,经过dependency layer后,紧接着全连接层和输出层:
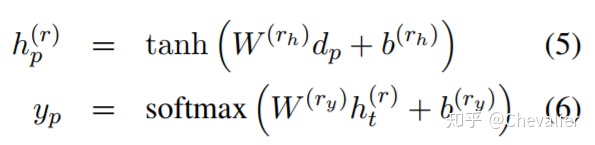
关系分类模块的输入dp是从堆叠在sequence layer的tree-LSTM构造而成,所以sequence layer对输入的贡献是间接的。此外,我们的模型使用单词来表示实体,因此它不能完全使用实体信息。为了缓解这个问题,我们直接将sequence layer的每个实体的隐藏层向量求平均后与输入dp拼接在一起,dp'=[dp;Ip11∑i∈Ip1si;Ip21∑i∈Ip2si],Ip1和Ip2分别表示第一个实体和第二个实体的单词的索引
四、Experiment
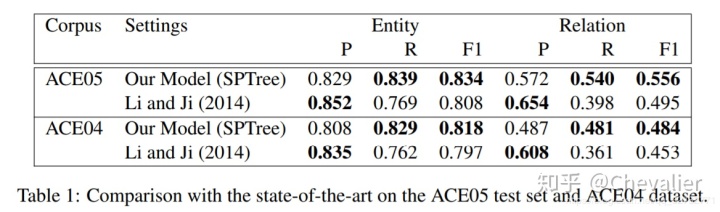
作者的模型与state-of-the-art的基于特征工程的模型在数据集ACE05和ACE04的对比。
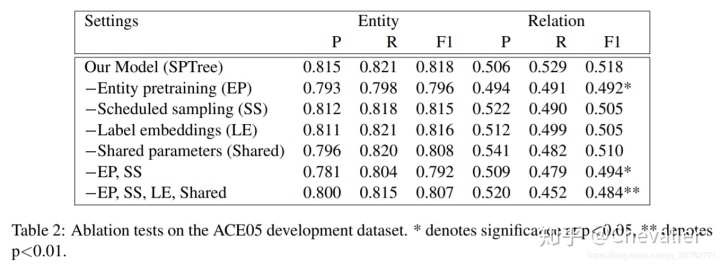
消融实验
五、Conclusion
作者提出了一个新颖的端到端的关系抽取模型,通过双向LSTM和双向tree-LSTM表示词序信息和依存信息。在一个模型中同时抽取实体及其关系,性能优于基于特征工程的模型,跟基于CNN的模型相媲美。
根据实验结果可以发现,词序信息和依存信息是有效的;共享参数提高了关系抽取的准确率;最短路径,被广泛用于关系分类中,很适合在LSTM模型中表示树结构信息。

