
- 1软件测试工程师--面试题_uftuif
- 2用Python 开发植物大战僵尸游戏_python中怎么做植物大战僵尸
- 3在MAC系统中使用mysql,出现mysql: command not found的情况_command not found: mysql
- 4【点云论文速读】6D位姿估计
- 5共识问题:区块链如何确认记账权?_区块链候选记账权
- 6python sys os time random模块_pycharm安装sys os time 模块
- 7Git重修系列 ------ Git的使用和常用命令总结
- 8uniapp tabBar角标问题_uniapp再tabbar上添加动态的数字角标
- 915个超实用Python文本处理案例分享,快点码住!_python关于文件经典例子
- 10auditd 用户审计详解
基于Python和Spark的大数据音乐推荐系统的设计与实现_基于大数据的音乐推荐系统
赞
踩
基于Python和Spark的大数据音乐推荐系统的设计与实现
摘 要
随着科学技术的发展,人们对服务的要求也越来越高。为了能提高管理者的管理效能,现在的音乐推荐管理必须要脱离复杂的手工管理方式。随着信息化时代的到来,智能操作系统成为大数据音乐推荐系统的重要组成部分,为用户提供优质的服务。
该系统采用 Python编程语言,采用开放源码系统结构Django完成整个系统结构,以 Hive作为数据库进行存储。管理员具有的功能包括登录、权限管理、系统管理、系统监控管理、开发平台管理、数据分析管理。用户具有的功能包括注册登录、查看推荐歌单、数据分析、评论、歌单管理。
关键词:Python,Django,Hive
Big Data Music Recommendation System Based on Python and Spark
With the development of science and technology, people have higher and higher requirements for services. In order to improve the management efficiency of managers, the current music recommendation management must be separated from the complex manual management method. With the advent of the information age, the intelligent operating system has become an important part of the big data music recommendation system, providing users with high-quality services.
The system uses Python programming language, adopts open source system structure Django to complete the whole system structure, and uses Hive as the database for storage. The functions of the administrator include login, authority management, system management, system monitoring management, development platform management, and data analysis management. The functions that users have include registration and login, viewing recommended song lists, data analysis, comments, and song list management.
Key Words:Python,Django,Hive
目 录
1 绪论
1.1 研究背景
从上个世纪到现在,随着网络技术的飞速发展和网络的迅猛发展,人类的日常活动已经发生了巨大的改变。在日益庞大的信息量中,信息的生产者和信息的消费者的信息传递与使用费用日益增加,网路已步入资讯超载的年代。
在没有介绍推荐系统之前,用户一般都是利用搜索引擎来处理。搜索引擎是一种由用户积极参与的信息筛选活动,通过检索到的关键词进行检索。
然而,当使用者不能清楚地了解自己的需要,或者不能找到恰当的关键词描述自己的需要时,搜寻引擎就不能为其所用。正是在这样的情况下,提出了一个推荐机制对使用者的过去的行为进行分析,从而发现该使用者的潜在偏好,并向其提供相关的建议,以增加其对该网站的满意程度。
当前世界正处于高速发展阶段,信息的高效是社会生产力的重要组成部分。移动微信、支付宝等使用与宣传,是社会的资讯物化,方便了管理员与用户,节省了管理者管理的精力,提高了办事的速度。可见,信息化是一个必然的趋势,它能改变一个音乐公司的工作方式。
在如今的网络时代,便捷、快捷的音乐推荐管理成为很多人首选的选择。以往使用手工方式来管理音乐推荐,但是这种方式不仅错误率很高,参考数据也很少,所以,要想有效地进行管理音乐推荐,就必须要有一个更好的管理系统。
1.2 选题意义
在很多分支领域中,推荐系统是一个解决信息过载非常重要的方法。当前的流行音乐网站的音乐资源中,含有大量的歌曲,如语言、年代、情感、电台等。
对使用者来说,想要收听全部歌曲是不现实的,因为歌曲的搜寻很有限。
另外,在日常生活中,音乐也有很大程度上是一种背景音,可以让用户全神贯注地一边做其他事一边去听音乐,这让用户的需求变得更加模糊,而推荐系统就是挖掘用户的潜在偏好并推荐给用户。
21世纪属于大数据社会,由于在管理信息的层次上存在着海量的数据,所以管理者要对海量的数据进行管理。因为电脑具有自动化的优势,所以许多用户选择使用电脑来进行海量的数据,从而提高了大数据音乐推荐系统的工作效能与安全。一开始的时候,管理员们都会选择手工的方式来进行数据的管理,但是因为数据实在是太多了,很可能会导致系统的工作效率下降。
1.3 研究内容
以下是关于这篇文章的文献编目:
第一章为绪论部分。该章重点阐述了研究环境和意义,研究现状,以及本文的结构。
第二章主要介绍了该软件的开发平台和技术。本文对大数据音乐推荐系统的开发环境以及所使用的技术进行了较为详尽的阐述。
第三章为需求分析。该章对大数据音乐推荐系统的功能和功能要求进行了详尽的描述。
第四章为系统功能设计。进行了系统功能分析和数据库设计。
第五章为系统实现。该章主要讨论了大数据音乐推荐系统的功能实现。
第六章对本论文进行了详细的论述。这一章讨论了利用黑盒子进行系统的测试。
2 系统技术
2.1 MVC模式
采用 MVC方法不仅能动态地提高大数据音乐推荐系统的代码质量,而且减少了对 SQL语句的反复编写,使之具有通用性,从而实现了对数据库的特定的处理。MVC技术能够简化大数据音乐推荐系统的编码数量,从而达到改善的目的。
MVC三个主要模型分别是模型、视图和控制面板。
在MVC的设计模式下,控件可以根据用户对页面的需求进行处理,而视图则可以将用户的页面展示给用户。在 MVC模式下,可以将模型的数据转化为可视化。如果模型发生了变化,则可以在用户界面上显示转换后的数据。
2.2 Hive数据库
由于 Hive具有较高的运行速度和较高的运行速度,所以许多大型和中型的企业都采用了 Hive的数据库。Hive具有优秀的性能,并且它的源码开放源代码系统是完全自由的,这使得音乐公司可以大大降低开发费用。
2.3 Django框架
视图-控制板的目的并不在于明确地引导设计者如何设计模式,而是希望能够让软件开发商更好地开发模式。模式—视图—控件的目的是要使开发者尽量降低编写程序的复杂性,从而简化程序开发人员的程序。在商业过程中,数据模型是非常重要的。用户在前面网页上发送的用户需求可以在控制区内进行。
2.4 Spark
最近几年,随着大数据的广泛应用,Spark成为了人们的研究热点。Spark是UC Berkeley AMP自动驾驶汽车地图地图,SparkMapReduce。在Spark大数据计算系统的发展历程中,出现了大量的子系统。
伯克利将Spark的整个生态体系称作伯克利数据分析(BDAs),Spark音乐公司的核心业务包括四类:Spark Streaming、Graphx、MLbase、SparkSQL、Spark Streaming、Spark Streaming、Giraphx、以及基于Giraphx的并行图形运算架构、MLbase(MLbase),它是一个能够支撑SQL结构化数据的SQL检索和解析的检索工具。正是因为有了以上的子项,Spark的高级和丰富的运算方式。
2.5 Vue技术
在开发出一个新的应用程序之后,首先要做的就是前面的接口,以前的时候,前面的接口都要经过DOM的处理,但是现在,技术越来越成熟,MVVM的设计就出现了,可以方便地对前面的接口进行升级和升级。MVVM的设计模式是MVC模式的重大改进,用户通过修改View层的信息,可以即时进行Model的更新。
如果模型的信息发生变化,也可以在View层次上进行更新。JS文件可以在数据发生变化的时候,将其与DOM进行同步更新,这不仅简化了程序开发的开发过程,也节省了开发者的时间。在Vue系统结构中,Vue系统结构能够追踪依赖关系,如果功能发生了变化,则Vue通知变更。
3 需求分析
目前许多大数据音乐推荐系统的管理工作还存在许多问题,包括操作不便、功能不健全等问题,有些还采用了手工操作。在经济发展过程中,需要建立更加完善的大数据音乐推荐系统管理系统。
3.1 系统目标
本系统包括了服务管理等工作,采用 MVC的设计方法和 Hive数据库来实现对音乐推荐管理,目的在于方便用户,提高管理员的工作效率。
大数据音乐推荐系统的实施要结合实际,清楚用户的需要,分析用户的需要,制定出一个系统的目标,并对其进行分析,从而确定大数据音乐推荐系统的系统结构。
(1)各子系统应具有独立且平滑的特点,有利于各子系统的发展与维修。
(2)充分地顾及对经营过程中的责任划分,尽量将各职能子系统置于便于对子系统进行管理的责任范围内。
(3)用户对音乐推荐管理的特定业务不能过于繁杂,不同的用户具有不同的功能,需要在不同的用户表格中加以区分。
在用户的功能层次上,用户的功能界面应该更加友好,用户可以简单的使用。在开发过程中,要注意系统的开发费用,提高工作的效能。
3.2 系统可行性分析
本文在分析了该系统以后,从技术与经济学的角度分析了大数据音乐推荐系统管理系统的可行性。
(1)技术上是可行的。在开发大数据音乐推荐系统的时候,软件的要求相对较少,只要Win10就行了,不需要硬盘,所以硬件的价格要便宜一些。在软件方面,仅需在许多应用中使用的数据库及编译器环境即可运行,因此其开发费用相对低廉。
(2)在财务上可行。经济学上的可行性是指通过大数据音乐推荐系统所赚取的利润,可以超过软件的研发和设计费用。利用这个系统,可以极大地降低人力的实际工作,提高管理员的管理工作的质量。采用开放源系统结构,采用开放源系统结构可以降低开发费用。该大数据音乐推荐系统具有很好的扩展性和易于维修,从而降低了未来的维修费用。
(3)在实际应用中是可行的。大数据音乐推荐系统的发展目的就是要让用户能够方便地进行具体的运作,在系统的设计与实施中,一定要注意到用户在实际的运作中是否能起到作用。此次的大数据音乐推荐系统管理系统没有选择过分的专业化,采用的按键和接口用户更熟悉。
3.3 功能需求分析
3.3.1 用例概述
用户:注册登录、查看推荐歌单、数据分析、评论、歌单管理。
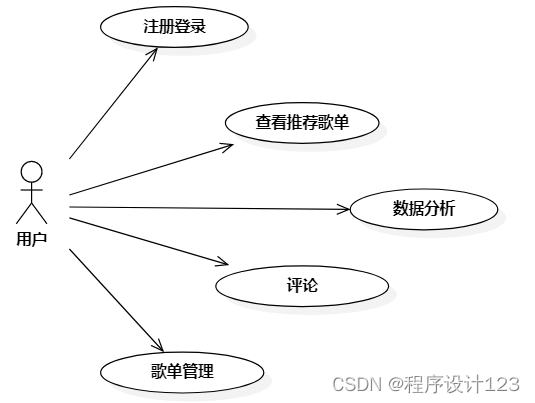
图3.1 用户用例图
管理员:登录、权限管理、系统管理、系统监控管理、开发平台管理、数据分析管理。
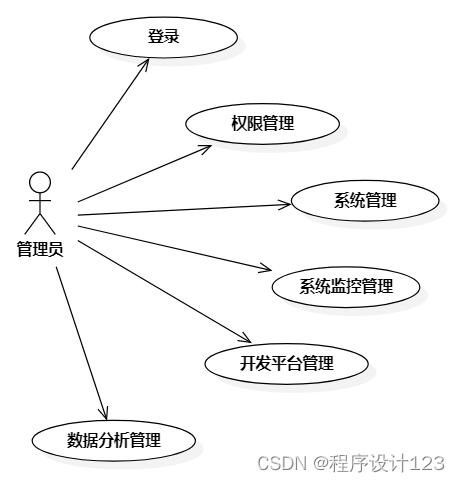
图3.2 管理员用例图
3.3.2 用例描述
(1)歌单信息管理
在表格3.1中给出了歌单信息管理案例的说明。
表3.1 歌单信息管理用例描述
| 用例标识 | 3.1歌单管理 |
| 用例名称 | 管理歌单信息 |
| 参与者 | 管理员 |
| 前置条件 | 管理员必须输入正确的帐号和密码以登录该系统 |
| 后置条件 | 管理歌单 |
| 用例概述 | 管理员管理歌单 |
| 基本事件流 | 1.管理员输入用户名和密码 2.管理员点击添加按钮,在歌单信息管理界面中提交新增加的歌单信息 3.只有歌单信息跟数据库信息不同,歌单信息才能够添加成功 |
| 备选事件流 | 4a 添加的信息需要注意字符合法性才能够成功添加 |
| 备注 |
(2)用户信息管理
用户信息管理用例描述如表3.2所示。
表3.2 用户信息管理用例描述
| 用例标识 | 3.2用户信息管理 |
| 用例名称 | 管理用户信息 |
| 参与者 | 管理员 |
| 前置条件 | 管理员必须输入正确的帐号和密码以登录该系统 |
| 后置条件 | 管理用户信息 |
| 用例概述 | 管理员管理用户信息 |
| 基本事件流 | 1.管理员输入用户名和密码 2.管理员点击修改按钮,在用户信息管理界面上提交修改后的用户信息 3.用户信息修改成功 |
| 备选事件流 | 4a 修改的信息需要注意字符合法性才能够成功修改 |
| 备注 |
(3)文件信息管理
文件信息管理用例描述如表3.3所示。
表3.3 文件信息管理用例描述
| 用例标识 | 3.3文件信息管理 |
| 用例名称 | 删减文件 |
| 参与者 | 管理员 |
| 前置条件 | 管理员登录系统 |
| 后置条件 | 删减文件 |
| 用例概述 | 管理员删减文件 |
| 基本事件流 | 1.管理员在系统中输入正确的帐号和密码 2.管理员按下删除键,将更改后的文件资料提交至文件信息管理界面 3.文件信息删除成功 |
| 备选事件流 | 4a 文件信息需要不与其他表格相联系,才能够删除文件 |
| 备注 |
(4)歌单分类信息管理
角色信息管理用例描述如表3.4所示。
表3.4 角色信息管理用例描述
| 用例标识 | 3.4角色信息管理 |
| 用例名称 | 搜索角色信息 |
| 参与者 | 管理员 |
| 前置条件 | 管理员需要输入正确的用户名和密码登录系统 |
| 后置条件 | 搜索角色信息 |
| 用例概述 | 管理员搜索角色信息 |
| 基本事件流 | 1.管理员输入正确的用户名和密码登录到系统当中 2.管理员在搜索框输入信息,在角色信息管理界面上提交信息 3.角色信息搜索成功 |
| 备选事件流 | 4a 输入的角色名称需要与数据库记录相同才能够成功搜索 |
| 备注 |
(5)登录
登录用例描述如表3.5所示。
表3.5 登录用例描述
| 用例标识 | 3.5登录用例描述 |
| 用例名称 | 登录 |
| 参与者 | 用户、管理员 |
| 前置条件 | 用户和管理员需要输入正确的用户名和密码 |
| 后置条件 | 登录 |
| 用例概述 | 用户和管理员登录 |
| 基本事件流 | 1.用户和系统管理员登录网页 2.管理员和使用者在系统中输入信息 |
| 备选事件流 | 4a 如果需要成功登录,必须输入与数据库信息相符的信息 |
| 备注 |
(6)个人中心
个人中心用例描述如表3.6所示。
表3.6 个人中心用例描述
| 用例标识 | 3.6个人中心用例描述 |
| 用例名称 | 个人中心 |
| 参与者 | 用户、管理员 |
| 前置条件 | 用户和管理员必须访问配置文件更改页 |
| 后置条件 | 修改个人信息 |
| 用例概述 | 用户和管理员管理个人信息 |
| 基本事件流 | 1.用户和系统经理登录网页 2.使用者及管理人员在该系统内输入使用者名称及密码 3.更改自己的个人信息到自己的个人信息更改页 |
| 备选事件流 | 4a 只有输入的信息合法才能够成功修改 |
| 备注 |
3.4 非功能需求分析
(1)用户在使用客户端进行系统访问时,需要检查是否具有良好的性能,并可以设置多台服务器,从而提高其功能。Hive具有高速缓存功能,它能根据大数据音乐推荐系统的数据进行高速缓冲,对数据库的主要性能进行调节,从而提高数据库的性能。如果使用了数据库的缓冲功能,那么用户在看到相同的信息时,就能立刻从高速缓存中读出信息,从而提高了数据的阅读速度。
(2)在运行过程中,大数据音乐推荐系统的运行需要有足够的稳定性,能够承受一些压力。在代码出现轻微错误时,大数据音乐推荐系统的操作应该不会受到任何的干扰。如果系统因为故障而导致了故障,那么这就说明了大数据音乐推荐系统的功能是否还能正常使用。
(3)当在进行大数据音乐推荐系统管理的时候,一定要注意它的维护性,它的实施要选择多个层次的架构来完成,在软件开发人员的分工下,要注意它的建立,以利于以后的维护。
(4)该大数据音乐推荐系统提供了一个灵活的查询控制功能,当管理员输入信息时,就可以生成一个查询,从而提高了查询的速度。
系统实现
5.1 用户注册登录
如果需要登记,就需要输入相应的用户数据,然后在注册完成后,就可以登录了,如果需要登录,就需要输入相应的身份,然后输入相应的信息。逻辑代码中的逻辑代码需要定义,用户的信息可以根据用户的姓名来查找,用户的个人数据可以被查询到,如果用户输入的用户名称与数据库记录不符,那么在后台的服务窗口就会提示用户。用户也可以选择重新设置的口令,激活 session包含的 invalidate来取消用户。

图5.1 登录界面
通过userService服务类的getOne方法获得用户的信息,如果用户输入的信息和数据库记录不一样则不能够登录。
/**
* 获取指定用户全部信息
* @return 用户信息
*/
{
SysUser user = userService.getOne(Wrappers.<SysUser>query().lambda().eq(SysUser::getUsername, username));
if (user == null) {
return R.failed(MsgUtils.getMessage(ErrorCodes.SYS_USER_USERINFO_EMPTY, username));
}
return R.ok(userService.findUserInfo(user));
}
5.2 部门管理
如果在部门管理接口中显示了信息,则可以采用网页的形式进行展示,如果网页上的数据比较多,则可以进入下一页,使用网页特定的工具类别来完成上一页和下一页的效果。当管理员在输入框中输入的部门名称时,需要将其传递给后端逻辑代码的query函数,并且,在得到该部门的信息时,需要将该消息输入到前面的接口中。
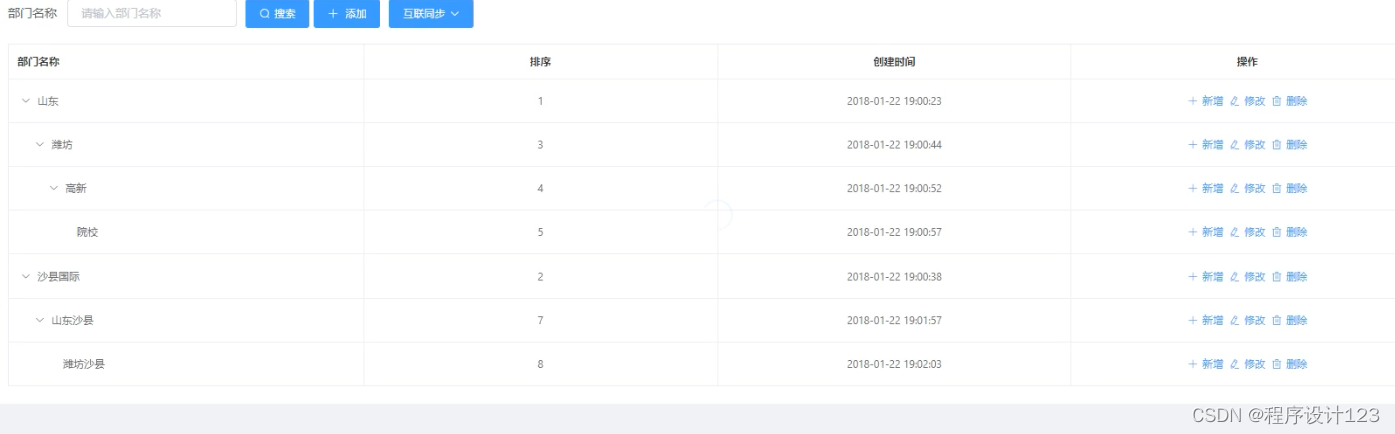
图5.2 部门管理界面
在部门管理功能中年需要定义save方法处理部门的添加信息,通过return语句返回部门的信息。
/**
* 添加
* @param sysDept 实体
* @return success/false
*/
@SysLog("添加部门")
@PostMapping
@PreAuthorize("@pms.hasPermission('sys_dept_add')")
public R save(@Valid @RequestBody SysDept sysDept) {
return R.ok(sysDeptService.saveDept(sysDept));
}
5.3 角色管理
管理员在管理角色的数据时,需要定义后端接口,从而可以对角色进行增、删、查。前面的角色显示需要使用列表函数,并且在前面和后端的数据是由请求对象来传递的。角色的信息被包装成页面,而前端的接口使用规则运算来对页面进行解析。管理员要添加角色数据需要登录后台管理系统点击添加按键,再加上按键时需要绑定按键点击,之后逻辑上的代码和绑定相关的接口才能满足用户的需求。
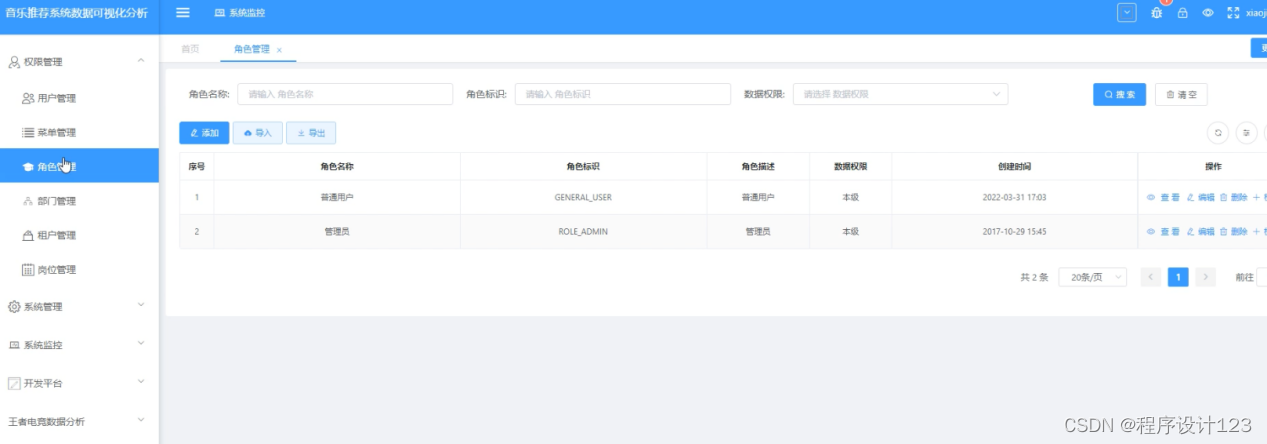
图5.3 角色管理界面
在修改角色功能中需要定义update方法,通过return语句返回角色的相关信息。
/**
* 修改角色
* @param sysRole 角色信息
* @return success/false
*/
@SysLog("修改角色")
@PutMapping
@PreAuthorize("@pms.hasPermission('sys_role_edit')")
@CacheEvict(value = CacheConstants.ROLE_DETAILS, allEntries = true)
public R update(@Valid @RequestBody SysRole sysRole) {
return R.ok(sysRoleService.updateById(sysRole));
}
5.4 用户管理
如果在用户管理接口中显示了信息,则可以采用网页的形式进行展示,如果网页上的数据比较多,则可以进入下一页,使用网页特定的工具类别来完成上一页和下一页的效果。当管理员在输入框中输入的用户名称时,需要将其传递给后端逻辑代码的query函数,并且,在得到该用户的信息时,需要将该消息输入到前端的接口中。
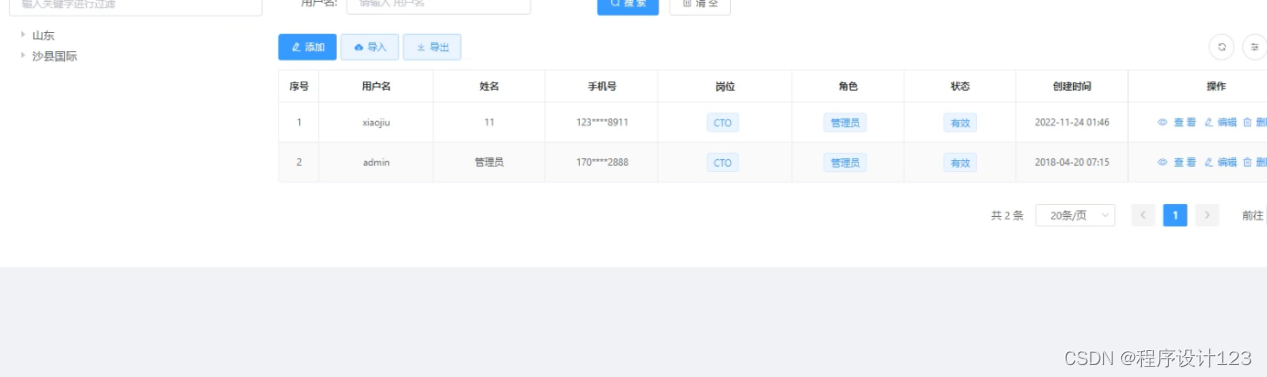
图5.4 用户管理界面
管理员可以查询用户信息,通过定义user方法处理用户信息,return语句返回用户信息。
/**
* 通过ID查询用户信息
* @param id ID
* @return 用户信息
*/
@GetMapping("/{id}")
public R user(@PathVariable Long id) {
return R.ok(userService.selectUserVoById(id));
}
/**
* 根据用户名查询用户信息
* @param username 用户名
* @return
*/
@GetMapping("/details/{username}")
public R user(@PathVariable String username) {
SysUser condition = new SysUser();
condition.setUsername(username);
return R.ok(userService.getOne(new QueryWrapper<>(condition)));
}
5.5 歌单管理
管理员在管理歌单的数据时,需要定义后端接口,从而可以对歌单进行增、删、查。前端的歌单显示需要使用列表函数,并且在前端和后端的数据是由请求对象来传递的。

图5.5 歌单管理界面
管理员可以添加歌单信息,定义save方法处理歌单的新增信息,通过return语句返回信息。
/**
* 新增
* @param adsSongList
* @return R
*/
@PreAuthorize("@pms.hasPermission('yinyue_adssonglist_add')" )
public R save(@RequestBody AdsSongList adsSongList) {
return R.ok(adsSongListService.save(adsSongList));
}
5.6 歌单展示
在歌单展示页面上,可以显示歌单的详细数据,登录后点击浏览,点击歌单的页面就会自动切换到歌单页面,在页面上设置对应的功能,满足用户的需求,而前端的接口则可以对服务端发送的数据进行解析,然后显示在接口上。在歌单的信息一定要与对应的点击活动相结合,用户点击后可以进行跳跃到对应的界面。
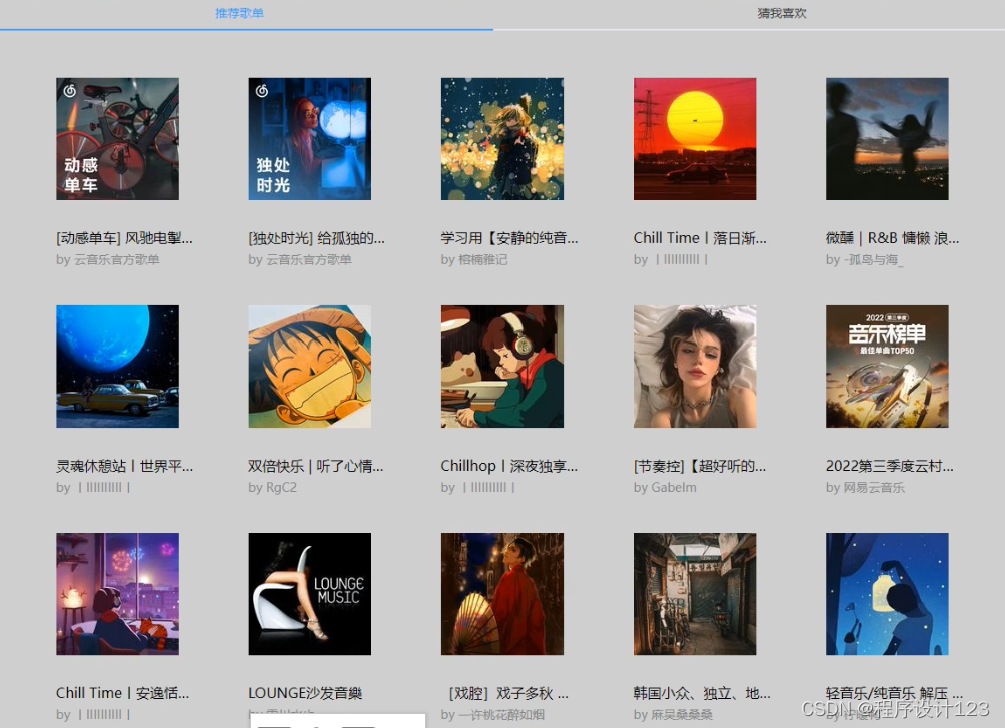
图5.6 歌单展示界面
用户可以查看歌单信息,在getByid方法中可以获得歌单的信息,return语句返回歌单信息。
/**
* 通过id查询
* @param id id
* @return R
*/
@ApiOperation(value = "通过id查询", notes = "通过id查询")
@GetMapping("/{id}" )
@PreAuthorize("@pms.hasPermission('yinyue_adssonglist_view')" )
public R getById(@PathVariable("id" ) Long id) {
return R.ok(adsSongListService.getById(id));
}
5.7 数据分析详细信息
用户可以进入到详细的数据分析信息界面。从数据分析展示接口进入到详细的数据分析页面,需要将数据分析的代码传递给服务端,然后再用 SQL语句将其详细的数据传递给用户。

图5.7 数据分析详细信息界面
数据分析界面中信息的展示需要解析排行榜,获得排行榜靠前的歌曲、收藏数量、转发数量、评论数量、播放数量,最后获得歌曲信息。
# 解析排行榜
def parseRank(self,driver,time):
# 获取排行榜名称
rank_name=driver.find_element(By.XPATH, '//*[@id="toplist"]/div[2]/div/div[1]/div/div[2]/div/div[1]/h2').text
# 获取收藏数量
rank_collectCount=driver.find_element(By.XPATH, '//*[@id="toplist-fav"]').text.replace('(', '').replace(')','')
# 获取转发数量
rank_shareCount=driver.find_element(By.XPATH, '//*[@id="toplist-share"]').text.replace('(', '').replace(')','')
# 获取评论数量
rank_commentCount = driver.find_element(By.XPATH,'//*[@id="toplist"]/div[2]/div/div[1]/div/div[2]/div/div[3]/a[6]').text.replace('(', '').replace(')', '')
# 获取播放数量
rank_playCount = driver.find_element(By.XPATH, '//*[@id="play-count"]').text
# 获取歌曲数量
rank_songCount=driver.find_element(By.XPATH, '//*[@id="toplist"]/div[2]/div/div[2]/div[1]/span/span').text
try:
trs=driver.find_element(By.CLASS_NAME, 'm-table').find_element(By.TAG_NAME, 'tbody').find_elements(By.TAG_NAME, 'tr')
5.8 添加歌单
在添加歌单展示页面上,可以显示添加歌单的详细数据,登录后点击浏览,点击添加歌单的页面就会自动切换到添加歌单页面,在页面上设置对应的功能,满足用户的需求,而前端的接口则可以对服务端发送的数据进行解析,然后显示在接口上。在添加歌单的信息一定要与对应的点击活动相结合,用户点击后可以进行跳跃到对应的界面。
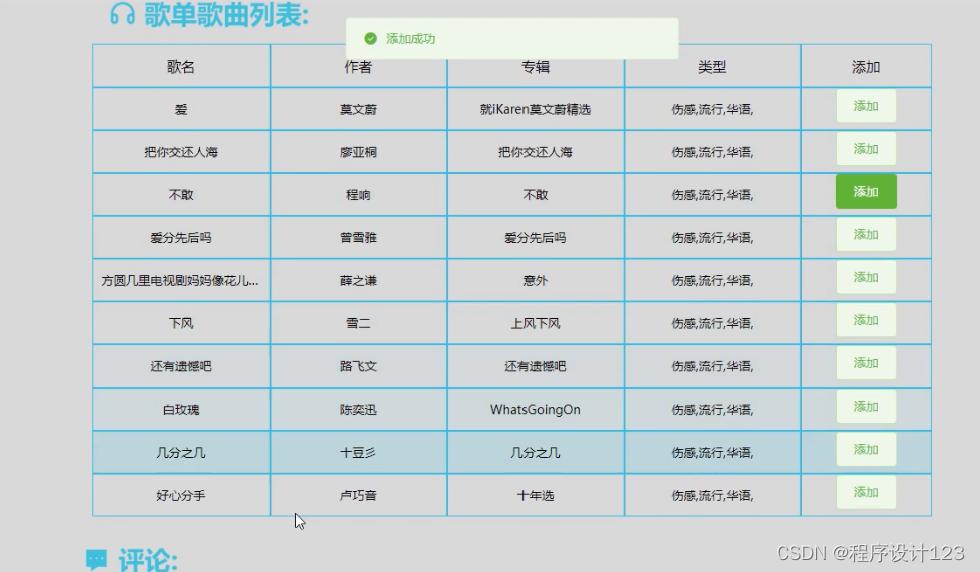
图5.8 添加歌单界面
管理员可以添加歌单信息,在getAdsSongListPage方法中定义分页查询的信息。
/**
* 分页查询
* @param page 分页对象
* @param adsSongList
* @return
*/
@ApiOperation(value = "分页查询", notes = "分页查询")
@GetMapping("/page" )
@PreAuthorize("@pms.hasPermission('yinyue_adssonglist_view')" )
public R getAdsSongListPage(Page page, AdsSongList adsSongList) {
return R.ok(adsSongListService.page(page, Wrappers.query(adsSongList))); }
5.9 评论
用户可以进入到详细的评论信息界面。从评论展示接口进入到详细的评论页面,需要将评论的代码传递给服务端,然后再用 SQL语言将其详细的数据传递给用户。

图5.9 评论界面
用户可以评论歌曲,需要定义save方法,通过user接口获取评论信息。
/**
* 新增
* @param fatherComment
* @return R
*/
@ApiOperation(value = "新增", notes = "新增")
@SysLog("新增" )
@PostMapping
@PreAuthorize("@pms.hasPermission('yinyue_fathercomment_add')" )
public R save(@RequestBody FatherComment fatherComment) {
return R.ok(fatherCommentService.save(fatherComment)); }


