- 1论文阅读笔记《Squeeze-and-Excitation Networks》_独热激活
- 2基于微信小程序毕业设计选题200例【题目新颖】_什么小程序适合当毕设
- 3git stash 常用命令_git stash 备注
- 4公众号榜单 | 2020·5月公众号行业排行榜重磅发布_2020微信公众号影响力排行榜类别
- 5计算机专业选择银行必须知道的20个问题_面试问题对银行it有什么了解
- 6java RSA 加密 解密
- 7oracle自定义字符串分割函数
- 8LLMs之GPT-4 Turbo:11月6日OpenAI重磅更新—在DevDay上宣布的新模型和开发者产品(全新的GPT-4 Turbo、128K上下文窗口、视觉功能)_gpt-4 turbo llm
- 9学生成绩管理系统设计报告python,学生成绩管理系统(Python学习)
- 10【正点原子STM32连载】 第九章 STM32启动过程分析 摘自【正点原子】MiniPro STM32H750 开发指南_V1.1_正点原子stm32h7驱动
TextCNN原理、结构、代码_textcnn结构
赞
踩
有个需求,给短文本分类,然后看了下文本分类的算法
- 传统机器学习算法:分为特征提取、分类两部分
- 深度学习算法:融合特征提取和分类,fastText、TextCNN、TextRNN、TextRCNN以及最近很火的bert算法,本文主要记录一下TextCNN。
参考
深度学习:TextCNN
TextCNN模型原理和实现
原理
将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的ngram),从而能够更好地捕捉局部相关性。
网络
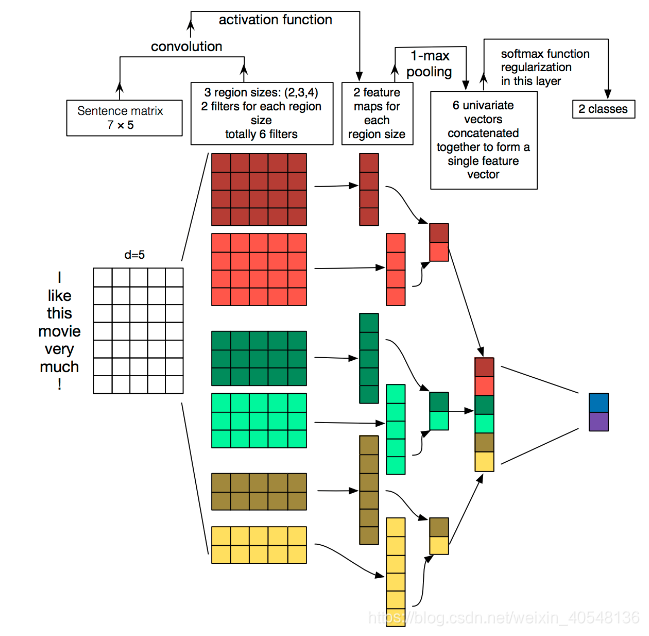
TextCNN包含四部分:词嵌入、卷积、池化、全连接+softmax,其实结构相比于图像领域简单很多。
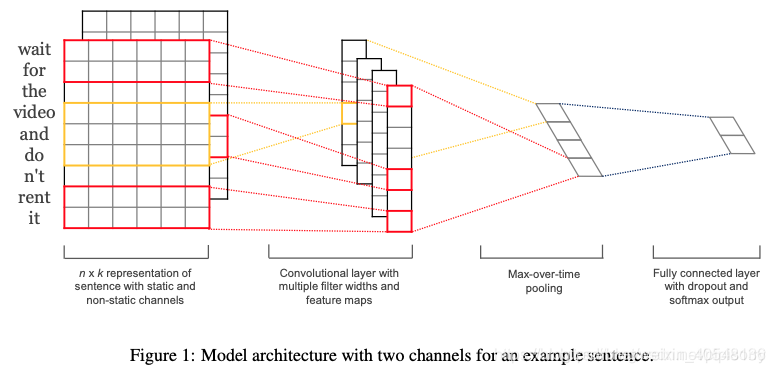
- Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
- Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
- MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
- FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
embedding
将每一个词表征为一个向量。可以采用预训练的模型,也可以随机初始化。训练过程中可以是static或non-static。感觉上,预训练的词向量可以先static再non-static。还有一种multichannel,两个channel通过预训练的词向量,一个为static一个为non-static,在fine-tune时只有一个通道更新参数。
convolution and pooling
输入一个包含s个单词的句子,假设每个单词预训练的词向量为d维,则输入为sxd,将该输入看做一幅图像,卷积提取相邻单词的特征,采用一维卷积,卷积核的宽度为词向量的维度d,则卷积核大小为wxd,卷积计算后特征为(s-h+1)x1xfilter_num,filter_num为卷积核的数目。这里h也是一个超参数可以取{2,3,4,5,…}
池化层:
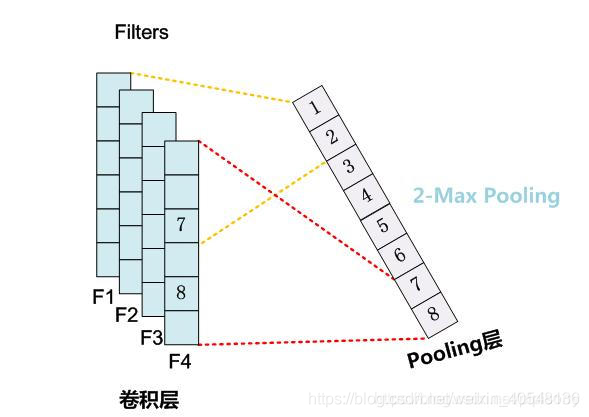
1-max pooling,即提取feature map最大的值(这里有一个缺点是只取最大值,将位置信息就忽略了),很大程度上减少了模型参数数量。
average-pooling每个维度取均值。
k-max pooling取所有特征值top-k,并保留特征的先后顺序。
Dynamic Pooling之Chunk-MaxPooling。把某个Filter对应的Convolution层的所有特征向量进行分段,切割成若干段后,在每个分段里面各自取得一个最大特征值,比如将某个Filter的特征向量切成3个Chunk,那么就在每个Chunk里面取一个最大值,于是获得3个特征值。因为是先划分Chunk再分别取Max值的,所以保留了比较粗粒度的模糊的位置信息;当然,如果多次出现强特征,则也可以捕获特征强度。至于这个Chunk怎么划分,可以有不同的做法,比如可以事先设定好段落个数,这是一种静态划分Chunk的思路;也可以根据输入的不同动态地划分Chunk间的边界位置,可以称之为动态Chunk-Max方法。Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks这篇论文提出的是一种ChunkPooling的变体,就是动态Chunk-Max Pooling的思路,实验证明性能有提升。Local Translation Prediction with Global Sentence Representation 这篇论文也用实验证明了静态Chunk-Max性能相对MaxPooling Over Time方法在机器翻译应用中对应用效果有提升。
Dynamic Pooling卷积时如果碰到triggle词,可以标记下不同色,max-pooling时按不同标记划分chunk。
模型图
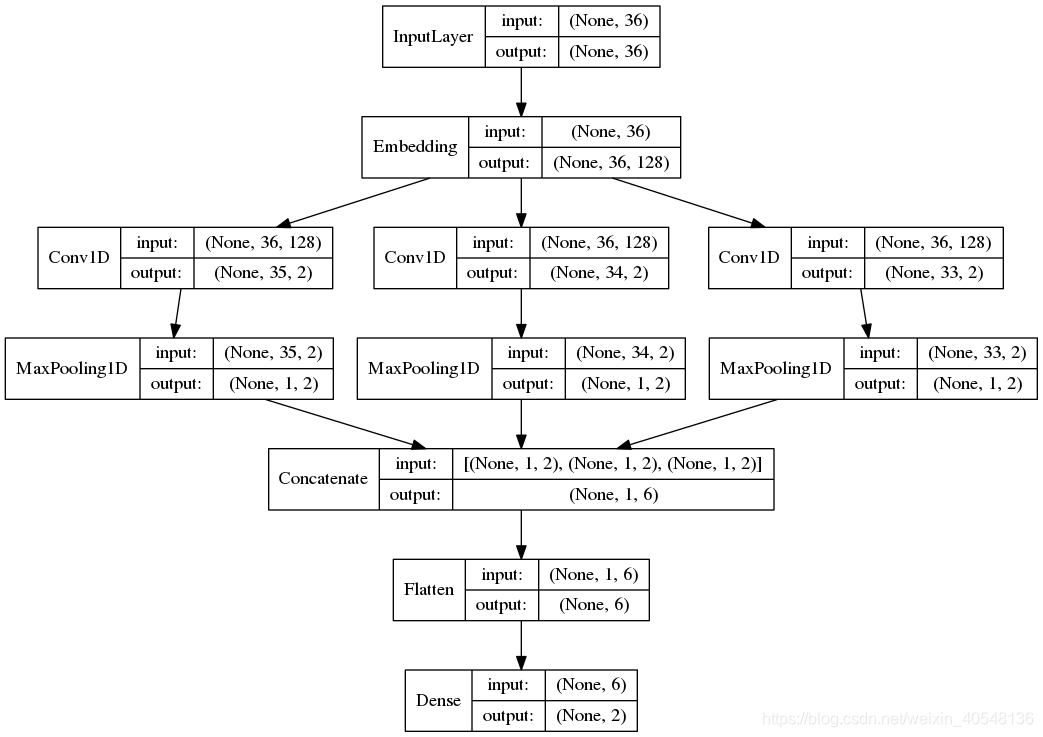
详看下图,画的真好,一目了然。
代码
以下是基于Keras的代码,代码我还没有细看,先贴上来。
import logging from keras import Input from keras.layers import Conv1D, MaxPool1D, Dense, Flatten, concatenate, Embedding from keras.models import Model from keras.utils import plot_model def textcnn(max_sequence_length, max_token_num, embedding_dim, output_dim, model_img_path=None, embedding_matrix=None): """ TextCNN: 1. embedding layers, 2.convolution layer, 3.max-pooling, 4.softmax layer. """ x_input = Input(shape=(max_sequence_length,)) logging.info("x_input.shape: %s" % str(x_input.shape)) # (?, 60) if embedding_matrix is None: x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length)(x_input) else: x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length, weights=[embedding_matrix], trainable=True)(x_input) logging.info("x_emb.shape: %s" % str(x_emb.shape)) # (?, 60, 300) pool_output = [] kernel_sizes = [2, 3, 4] for kernel_size in kernel_sizes: c = Conv1D(filters=2, kernel_size=kernel_size, strides=1)(x_emb) p = MaxPool1D(pool_size=int(c.shape[1]))(c) pool_output.append(p) logging.info("kernel_size: %s \t c.shape: %s \t p.shape: %s" % (kernel_size, str(c.shape), str(p.shape))) pool_output = concatenate([p for p in pool_output]) logging.info("pool_output.shape: %s" % str(pool_output.shape)) # (?, 1, 6) x_flatten = Flatten()(pool_output) # (?, 6) y = Dense(output_dim, activation='softmax')(x_flatten) # (?, 2) logging.info("y.shape: %s \n" % str(y.shape)) model = Model([x_input], outputs=[y]) if model_img_path: plot_model(model, to_file=model_img_path, show_shapes=True, show_layer_names=False) model.summary() return model

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
训练有以下几点:
- 数据量较大:可以直接随机初始化embeddings,然后基于语料通过训练模型网络来对embeddings进行更新和学习。
- 数据量较小:可以利用外部语料来预训练(pre-train)词向量,然后输入到Embedding层,用预训练的词向量矩阵初始化embeddings。(通过设置weights=[embedding_matrix])。
- 静态(static)方式:训练过程中不再更新embeddings。实质上属于迁移学习,特别是在目标领域数据量比较小的情况下,采用静态的词向量效果也不错。(通过设置trainable=False)
- 非静态(non-static)方式:在训练过程中对embeddings进行更新和微调(fine tune),能加速收敛。(通过设置trainable=True)
模型如如下: