
- 1ModuleNotFoundError: No module named‘ pymysql ‘异常的正确解决方法
- 2一个Boss直聘机器人, 自动回复发简历
- 3毕业设计:基于深度学习的图像分类识别系统 人工智能_深度学习图像识别毕设总体概述
- 4数字逻辑电路复习资料_数字逻辑电路空翻和反转的区别
- 5uniapptabbar的高度是多少_Uniapp-tabbar选择及适配
- 6揭秘爬虫个股投资机会,轻松赚钱!_爬虫炒股有用吗
- 7【无人机编队】基于matlab二阶一致性多无人机协同编队控制(考虑通信半径和碰撞半径)【含Matlab源码 4215期】_多无人机协同任务规划matlab
- 8Dubbo源码(4)-Zookeeper注册中心源码解析_o.a.d.r.zookeeper.zookeeperregistry.unsubscribe -
- 9Adobe Lightroom Classic v13.1 (macOS, Windows) - 桌面照片编辑器_lightroom 13.1
- 10Seagull License Server 9.4 SR3 2781 完美激活(解决不能打印问题)
使用scrapy框架抓取手机商品信息(1)_scarpy爬取京东数据
赞
踩
目录
1.准备工作
1.1 启动pycharm
打开Terminal,输入
scrapy startproject jdcrawler可以看到scrapy自动为我们生成了项目地址

我们进入到jdcrawler的目录下,接着输入
scrapy genspider jdphone jd.com
可以看到我们已经在 spider 目录下创建了一个名为 jdphone 的爬虫,并且设置了这个爬虫的名称是 jdphone ,允许爬取的目录是 jd.com ,并且设置了一个默认的开始url
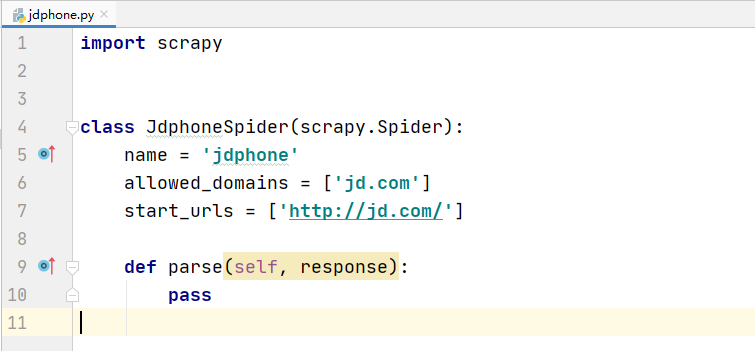
1.2 setting.py 配置
首先要设置UA头,直接把注释取消后,到京东的网站上刷新后在network随便一个资源里就可以看到

我也不知道为啥要改这个

我这里将LOG_LEVEL设置为了WARING,这就意味着除了waring以上等级的讯息都不会打印在控制台里,如果你想看到具体scrapy的运行流程,可以不需要添加这一条
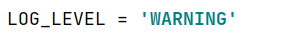
这边是设置了 scrapy 的爬虫中间件,这个中间件位于浏览器返回来的 response 之后和爬虫的页面处理函数之前(具体的 scrapy 框架的运行流程可以去网上查看,这边就不重复了),其实这边我本来是想着可能京东的页面是js动态渲染的,在中间件这里设置一个 selenium 来获取直接请求获取不到的内容,结果发现京东并没有js动态渲染,,所以这里可设可不设。不过我后面会讲如果当前要爬取的页面是动态渲染的该如何去添加 selenium

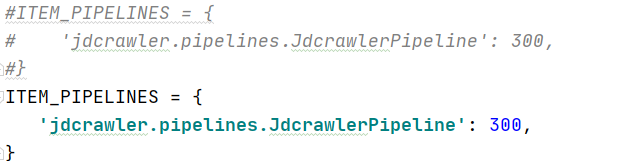
这边是设置了 scrapy 的 piplines 功能是否打开,这个 piplines 的作用是可以将提取的item保存到不同的储存器中去,包括mongodb ,mysql ,redis等,我这边选用的是mongodb来储存数据,后续的具体代码在
piplines.py 中书写
1.3爬取页面分析
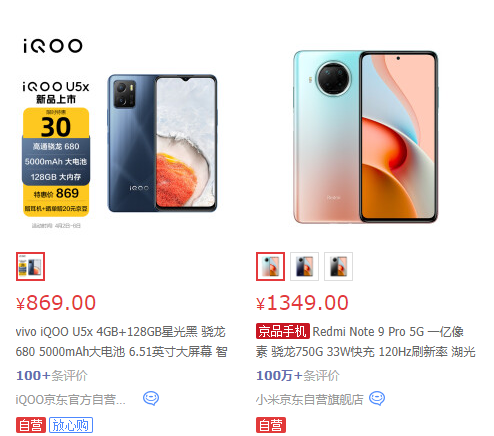
我们来到京东页面在搜索框输入手机,可以看到手机的商品页面都是分块的,初始页面上只有简单的名字,图片,价格等信息,所以我们需要进入到具体的商品页面:也就是点击商品名后进入的页面,来获取到我们想要的信息
进入到商品页面后我们可以看到具体的商品信息,那我们的主要目标就确认下来了

接下来我们要思考爬取下一页的逻辑,我一开始想的是通过主页面的下一页按钮来获取下一页的地址,发现不行后,我就开始观察主页面的页面逻辑,发现其实一个页面是由两页来组成的,我们翻页的时候其实就是跳了两页,那我们就可以直接通过拼接页面链接的page数来获取下一页的地址了


可以看到page=从1跳到了3
那我们的爬取思路就十分清晰了
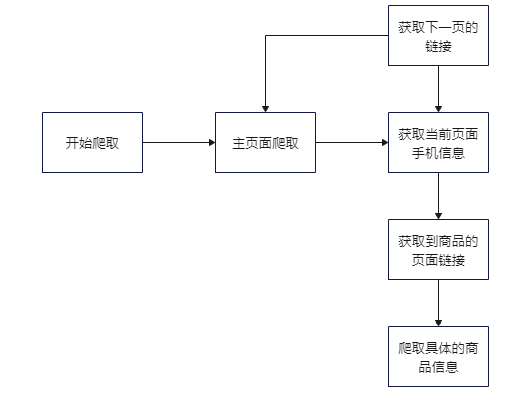
接下来正式开始写代码!
2.代码编写
2.1 爬虫代码
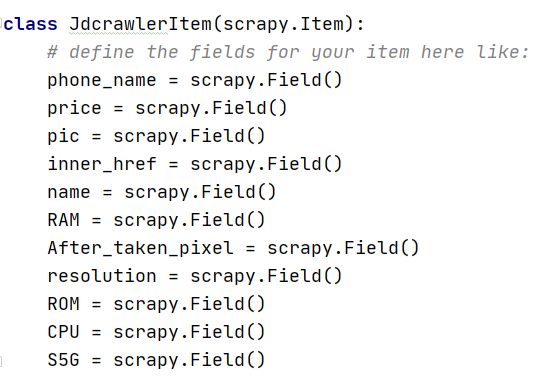
首先我们来到 item.py ,这里设置了我们之后需要获取到并且保存的字段名称,我这边设置了我想要获取的几个参数,之后这些字段,可以在 jdphone.py 里面被赋值和使用
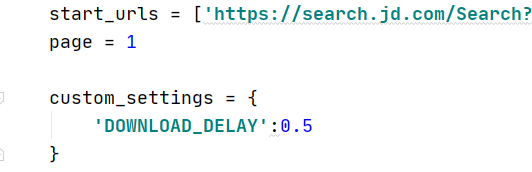
之后我们来带 jdphone.py 页面,将 start_urls 改为我们京东手机商城页面的第一页的链接,设置page为1,并将 custom_settings 里的 DOWNLOAD_DELAY设置为 0.5(这应该是我试过不会被ban的极限延迟了)
custom_settings = {
'DOWNLOAD_DELAY':0.5
}
我们将 item.py 里的字段导入进来,方便后面使用
from jdcrawler.items import JdcrawlerItem
开始对response的内容进行分析,我们需要主页面的三个信息分别是price(价格),pic(商品图片),inner_href(商品页面),一个页面一般有60个商品,我们就循环60次,通过找到xpath的规律来获取这个页面所有的手机信息,并且对一些特殊的空值情况做出处理,在我们获取到信息后,使用
item[' '] = info 的方式将数据存放在 item 中,同时不要忘记对链接的处理
- def parse(self, response):
- for i in range(1,61):
- item = JdcrawlerItem()
- price = response.xpath(f'//*[@id="J_goodsList"]/ul/li[{i}]/div/div[3]/strong/i/text()').extract_first()
- pic = response.xpath(f'//*[@id="J_goodsList"]/ul/li[{i}]/div/div[1]/a/img/@data-lazy-img').extract_first()
- inner_href = response.xpath(f'//*[@id="J_goodsList"]/ul/li[{i}]/div/div[4]/a/@href').extract_first()
-
-
- if pic == None:
- pic = "none"
- if inner_href == None:
- inner_href = "none"
-
- item['price'] = price
- item['pic'] ='https:' + pic
- item['inner_href'] = 'https:' + inner_href

同时在我们循环爬起主页面的商品信息的时候,也可以对商品内页面的信息进行处理,通过上面爬取到的inner_href 链接进入到商品的内页面,不过我们需要一个新的处理函数来分析商品内页面的response,所以我们需要写一个新的函数,那我们如何将 inner_href 传到新的函数中去呢,可以这么来写
- yield scrapy.Request(
- item['inner_href'],
- callback=self.parse_inner,
- cookies=self.cookies,
- meta={"item": item},
- )
我们重新发起了一个scrapy.Request,将inner_href传了进去,将处理函数定义为parse_inner,同时也将item传入了处理函数内,这样我们在新页面获取的信息也可以保存到item中
关于 parse_inner的函数我们最后来写,首先要处理下一页的爬取逻辑,我们在上面的观察中可以发现下一页的链接逻辑,于是我们就可以通过循环拼接url来获取每一页的链接
- next_url = f'https://search.jd.com/Search?&...page={self.page}'
- if self.page <= 160: #实际是80页
- yield scrapy.Request(
- next_url,
- callback=self.parse,
- cookies=self.cookies
- )
- self.page = self.page + 1
这里同样也发送了一个scrapy.Request的请求,我设置了爬取80页的限制,将爬取的url设置为下一页的链接,同时回调函数设置为自己,这样就形成了闭环,当我爬完这一页之后重新调用自身,开始爬取下一页
最后我们来处理 parse_inner() 的代码,一开始我觉得还是很简单的通过xpath获取就行了,结果发现基本所有手机商品介绍里的信息都是不一样的,而且很多都少了信息,所以通过xpath,bs这种偏找规律的方法是肯定不行了,于是我就想到了使用正则表达式来匹配到我想要的信息


最后的代码就是这样,使用正则表达式匹配到具体的内容,然后判断是否为空后保存到传入的item中,最后使用 yield item 将item保存的内容传入到下一个模块
- item = response.meta['item']
-
- result = re.findall(r'商品名称:(.*?)<', response.text)
- item['name'] = "未知商品名" if result == [] else result[0]
-
- result = re.findall(r'运行内存:(.*?)<', response.text)
- item['RAM'] = "未知运行内存" if result == [] else result[0]
-
- result = re.findall(r'机身内存:(.*?)<', response.text)
- item['ROM'] = "未知机身内存" if result == [] else result[0]
-
- result = re.findall(r'后摄主摄像素:(.*?)<', response.text)
- item['After_taken_pixel'] = "未知后摄像素" if result == [] else result[0]
-
- result = re.findall(r'分辨率:(.*?)<', response.text)
- item['resolution'] = "未知分辨率" if result == [] else result[0]
-
- result = re.findall(r'CPU型号:(.*?)<', response.text)
- item['CPU'] = "暂无型号" if result == [] else result[0]
-
- result = re.findall(r'移动5G', response.text)
- item['S5G'] = "不支持5G" if result == [] else "支持5G"
-
- yield item
到此所有的爬虫代码就完成了
2.2 piplines.py代码编写
在上一步中,我们获取到了爬虫爬取到的信息,并且保存在了item中,而我们在 piplines.py 文件下可以看到 process_item() 函数中已经提供给了我们item参数,那我们就可以直接利用他来做信息的保存了

我们导入pymongo,将数据库设置为本地localhost(不设置就是默认本地),然后指定jdcrawler数据库里的jdphone集合(如果没有会自动创建),设置一个变量a来查看爬取进度
- from pymongo import MongoClient
-
- client = MongoClient()
- collection = client['jdcrawler']['jdphone']
- a = 0
之后就简单的使用insert来将item数据传入mongodb就可以了,其中需要注意一下格式的转换

piplines.py代码编写就到这里,这个函数的功能还有很多,以后有机会再使用
3 运行及收尾
到此我们的代码部分就基本写完了,那么我们要如何运行呢?其实有两种方法
第一种是使用命令行运行,指定了运行的爬虫名和输出文件,这里我选择了csv,也可以导出json和xml格式
scrapy crawl jdphone -o temp.csv第二种是在项目目录下创建一个文件,命名为 main.py 在文件下写入如下命令
- from scrapy.cmdline import execute
-
- execute(['scrapy','crawl','jdphone','-o','temp.csv'])
- #或者 execute('scrapy crawl jdphone -o temp.csv'.split())
之后运行main.py就可以了
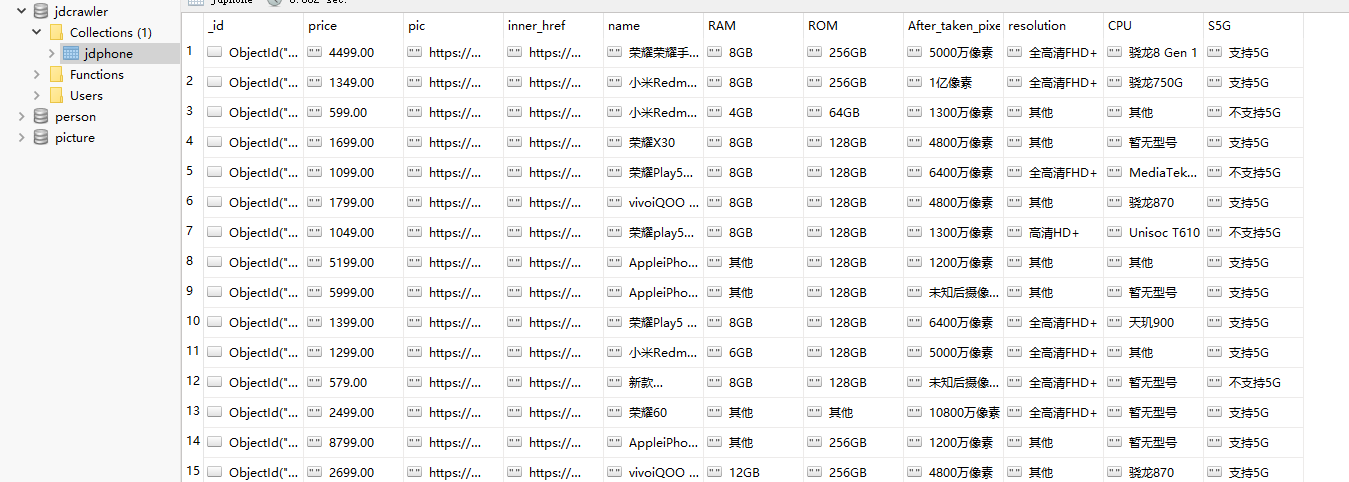
最后是运行的结果
终端里:

csv文件中:
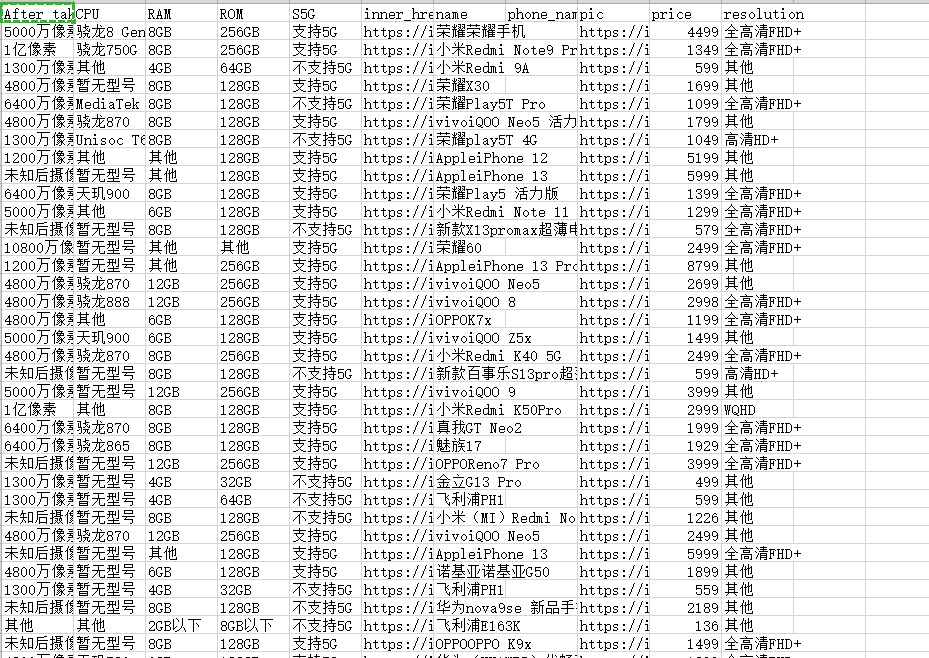
mongodb中:
到此为止,项目的第一部分就完成了
追加
我们上文说到京东本身是没有js动态渲染的,所以这里没有使用到 selenium 库,那当我们碰到了动态渲染的页面时,该如何将这个库使用到 scrapy 框架中呢?
首先我们将爬虫中间件的注释取消掉,这边后面的数字代表的是中间件执行的顺序,数字越小越先执行
之后我们来到 middlewares.py 文件下,将其他的两个中间件都删除(如果不用的话),设置一个新的中间件名为 seleniumMiddleware ,同时,将上面 setting.py 里的中间件名字也修改成这个
![]()
之后写一个 process_request() 函数(也可以从之前的 JdcrawlerDownloaderMiddleware 里复制过来),
可以看到这里给我们提供了两个参数,request和spider,request就是我们一开始发出的请求,我们可以通过他来获取要通过 selenium 处理的url,spider我们后面再说,这里我们用到了scrapy给我们的一个方法,我们可以通过 return HtmlResponse 来将处理之后的数据再返回爬虫文件进行处理,于是我们的中间件可以这么写
- from scrapy.http import HtmlResponse
- def process_request(self, request, spider):
- url = request.url
- spider.chrome.get(url)
- html = spider.chrome.page_source
-
- return HtmlResponse(url=url,body=html,request=request,encoding='utf-8')
ps:本来可以直接在这个文件里写入selenium方法获取数据,但是每次请求都会开启一个页面会导致速度变慢,所以我们还是直接回到爬虫里去写入selenium
之后我们回到爬虫文件 jdphone.py 上去,首先我们导入 selenium 相关的组件,设置无头选项(不开启浏览器),之后写入一个方法叫 from_crawler()的方法,这个方法可以返回一个spider对象并且使这个对象带有 setting.py 里的配置属性,同时这个spider也会返回给我们的中间件,我们可以通过设置spider的chrome属性来将这个他传递到中间件上去,之后中间件调用spider.chrome属性来解析页面,最后返回js动态渲染之后的数据,最后设置的spider_closed是为了在爬虫结束的时候关闭浏览器
- from selenium import webdriver
- from selenium.webdriver.chrome.options import Options # 使用无头浏览器
-
- chrome_options = Options()
- chrome_options.add_argument("--headless")
- chrome_options.add_argument("--disable-gpu")
- @classmethod
- def from_crawler(cls, crawler, *args, **kwargs):
- spider = super(HitomiMangaSpider, cls).from_crawler(crawler,*args,*kwargs)
- spider.chrome = webdriver.Chrome(options=chrome_options)
- crawler.signals.connect(spider.spider_closed,signal=spider.spider_closed)
- return spider
-
- def spider_closed(self,spider):
- print("over")
- self.browser.quit()
后面我们将使用tkinter处理获取到的数据

