
- 1Java_从入门到JavaEE_07
- 2利用android studio制作简单的QQ的注册、登录、忘记密码的页面_android studio注册qq页面
- 3三天学会MySQL(八)子查询 & 索引_子查询 索引
- 4带你深入了解NPM——NPM初学者指南_npm ci hook
- 5【Git】提交代码详细流程_git提交代码的流程
- 6特斯拉自动驾驶技术原理_特斯拉正升级自动驾驶可视化技术 以识别周围各种车型...
- 7seafile windows客户端安装、浏览器登陆方式及手机端下载地址_seafile服务器怎么登录
- 8ffmpeg命令操作 合并视频 取图片帧数 获取音频_-q:v
- 9腾讯6面,成功唬住试官拿了23K,感觉测试面试也不太难..._腾讯几面最难
- 10【web安全】-- 命令执行漏洞详解
Java-Spark系列7-Spark streaming介绍_java spark streaming
赞
踩
一.Spark streaming介绍
1.1 Spark streaming简介
Spark Streaming是Spark API的核心扩展,支持实时数据流的可扩展、高吞吐量和容错流处理。数据可以从Kafka、Kinesis或TCP套接字等多种来源中获取,并且可以使用复杂的算法进行处理,这些算法用高级函数表示,如map、reduce、join和window。最后,处理过的数据可以推送到文件系统、数据库和实时仪表板。事实上,您可以在数据流上应用Spark的机器学习和图形处理算法。
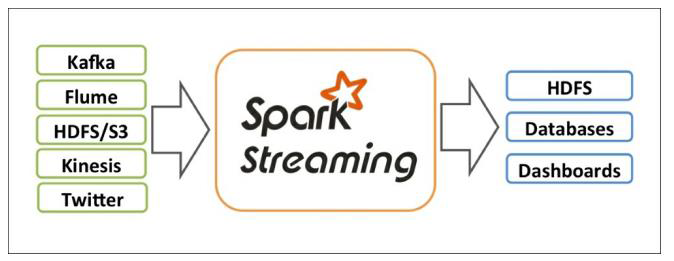
在内部,它的工作方式如下。Spark Streaming接收实时输入的数据流,并对数据进行分批处理,由Spark引擎进行处理,生成最终的批量结果流。

Spark Streaming提供了一种高级抽象,称为离散流或DStream,它表示连续的数据流。Dstream可以通过来自Kafka和Kinesis等源的输入数据流创建,也可以通过在其他Dstream上应用高级操作来创建。在内部,DStream表示为rdd序列。
1.2 Spark 与storm区别
Storm
- 流式计算框架
- 以record为单位处理数据
- 也支持micro-batch方式(Trident)
Spark
- 批处理计算框架
- 以RDD为单位处理数据
- 也支持micro-batch流式处理数据(Spark Streaming)
两者异同
- 吞吐量: Spark Streaming 优于Storm
- 延迟: Spark Streaming差于Storm
1.3 一个简单的例子
在我们深入了解如何编写自己的Spark Streaming程序之前,让我们快速了解一下简单的Spark Streaming程序是什么样的。
首先,我们导入StreamingContext,它是所有流功能的主要入口点。我们创建一个具有两个执行线程的本地StreamingContext,批处理间隔为1秒。
import org.apache.spark.*;
import org.apache.spark.api.java.function.*;
import org.apache.spark.streaming.*;
import org.apache.spark.streaming.api.java.*;
import scala.Tuple2;
// Create a local StreamingContext with two working thread and batch interval of 1 second
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
为了初始化一个Spark Streaming程序,必须创建一个StreamingContext对象,它是所有Spark Streaming功能的主要入口点。
appName参数是应用程序在集群UI上显示的名称。master是Spark、Mesos或YARN集群的URL,或者是一个特殊的“local[*]”字符串,在本地模式下运行。实际上,当在集群上运行时,您不希望在程序中硬编码master,而是使用spark-submit启动应用程序并在那里接收它。但是,对于本地测试和单元测试,可以通过“local[*]”来运行Spark Streaming in-process(检测本地系统中的核数)。
在定义了上下文之后,必须执行以下操作:
- 通过创建输入DStreams来定义输入源。
- 通过对DStreams应用转换和输出操作来定义流计算。
- 开始接收数据并使用streamingContext.start()处理它。
- 使用streamingContext.awaitTermination()等待处理停止(手动或由于任何错误)。
- 可以使用streamingContext.stop()手动停止处理。
注意:
- 一旦启动了Context,就不能再设置或向其添加新的流计算。
- 一旦停止了Context,就不能重新启动它。
- 同一时间,JVM中只能有一个StreamingContext是活动的。
- StreamingContext上的stop()也会停止SparkContext。要只停止StreamingContext,请将stop()的可选参数stopSparkContext设置为false。
- 一个SparkContext可以被重用来创建多个StreamingContext,只要在创建下一个StreamingContext之前停止前一个StreamingContext(不停止SparkContext)。
二.Spark Streaming的组件介绍
Spark Streaming的核心组件有2个:
- Streaming Context
- Dstream(离散流)
2.1 Streaming Context
Streaming Context是Spark Streaming程序的起点,生成Streaming Context之前需要生成SparkContext,SparkContext可以理解为申请Spark集群的计算资源,Streaming Context可以理解为申请Spark Streaming的计算资源
2.2 Dstream(离散流)
Dstream是Spark Streaming的数据抽象,同DataFrame,其实底层依旧是RDD。
Discretized Stream或DStream是Spark Streaming提供的基本抽象。它表示一个连续的数据流,要么是从源接收的输入数据流,要么是通过转换输入流生成的处理数据流。在内部,DStream由一系列连续的rdd表示,这是Spark对不可变的分布式数据集的抽象。DStream中的每个RDD都包含一定时间间隔的数据,如下图所示:

在DStream上应用的任何操作都转换为在底层rdd上的操作。
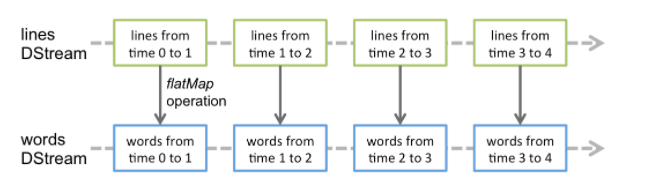
这些底层RDD转换是由Spark引擎计算的。DStream操作隐藏了大部分细节,并为开发人员提供了更高级的API。
DStream存在如下概念:
- Receiver
- 数据源: 基本源、高级源
- 可靠性
- Dstream的操作
- 缓存
- Checkpoint
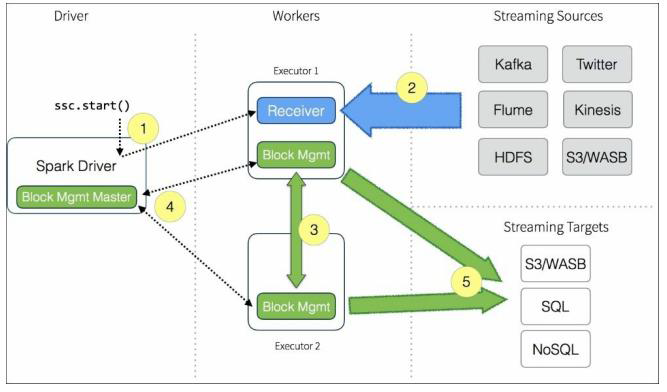
2.1 Receiver
每个输入DStream(文件流除外)都与一个Receiver (Scala doc, Java doc)对象相关联,接收来自源的数据并将其存储在Spark的内存中进行处理。
2.2 数据源
Spark Streaming提供了两类内置流源:
- 基本源:在StreamingContext API中直接可用的源。例如文件系统和套接字连接。
- 高级资源:像Kafka, Kinesis等资源可以通过额外的实用程序类获得。这些需要根据链接部分中讨论的额外依赖项进行链接。
注意,如果希望在流应用程序中并行接收多个数据流,可以创建多个输入Dstream。这将创建多个接收器,这些接收器将同时接收多个数据流。但是请注意,Spark worker/executor是一个长期运行的任务,因此它占用分配给Spark Streaming应用程序的一个核心。因此,Spark Streaming应用程序需要分配足够的内核(或者线程,如果在本地运行的话)来处理接收到的数据,以及运行接收端,记住这一点很重要。
记住
在本地运行Spark Streaming程序时,不要使用“local”或“local[1]”作为主URL。这两种情况都意味着只有一个线程用于本地运行任务。如果你使用一个基于接收器的输入DStream(例如,socket, Kafka等),那么单线程将被用来运行Receiver ,不留下任何线程来处理接收的数据。因此,当本地运行时,总是使用“local[n]”作为主URL,其中要运行n个>数量的Receiver 。
将逻辑扩展到集群上,分配给Spark Streaming应用的内核数必须大于接收端数。否则系统将接收到数据,但无法进行处理。
2.3 可靠性
根据数据源的可靠性,可以有两种数据源。源(如Kafka)允许传输的数据被确认。如果从这些可靠来源接收数据的系统正确地确认了接收的数据,就可以确保不会由于任何类型的故障而丢失数据。这就产生了两种接收者:
1). 可靠的接收端—当数据被接收到并存储在Spark中并进行复制时,一个可靠的接收端会正确地向一个可靠的源发送确认。
2), 不可靠的接收者——不可靠的接收者不向源发送确认。这可以用于不支持确认的来源,甚至当一个人不想或需要进入确认的复杂性时,用于可靠的来源。
对于不可靠的接收者,Spark streaming有自己的可靠机制,来保证数据的可靠性。
2.4 Dstream的操作
与rdd类似,转换允许修改来自输入DStream的数据。DStreams支持许多普通Spark RDD上可用的转换。下面是一些常见的.
Transformations on DStreams

Output Operations on DStreams:

2.5 缓存
与rdd类似,DStreams也允许开发人员在内存中持久化流数据。也就是说,在DStream上使用persist()方法将自动在内存中持久化该DStream的每个RDD。如果DStream中的数据将被计算多次(例如,对同一数据的多次操作),这是有用的。对于基于窗口的操作,如reduceByWindow和reduceByKeyAndWindow,以及基于状态的操作,如updateStateByKey,这是隐式true。因此,由基于窗口的操作生成的DStreams会自动持久化到内存中,而不需要开发人员调用persist()。
对于通过网络接收数据的输入流(例如,Kafka, socket等),默认的持久性级别被设置为将数据复制到两个节点以实现容错。
注意,与rdd不同,DStreams的默认持久性级别将数据序列化保存在内存中。
2.6 Checkpoint
流应用程序必须全天候运行,因此必须对与应用程序逻辑无关的故障(例如,系统故障、JVM崩溃等)具有弹性。为了使这成为可能,Spark Streaming需要对容错存储系统进行足够的信息检查点,以便从故障中恢复。有两种类型的数据是检查点的:
-
元数据检查点——将定义流计算的信息保存到像HDFS这样的容错存储中。这用于从运行流应用程序驱动程序的节点的故障中恢复(稍后将详细讨论)。元数据包括:
1.1) 配置—用于创建流应用程序的配置。
1.2) DStream操作-定义流应用程序的DStream操作集。
1.3) 未完成批-作业已排队但尚未完成的批。 -
数据检查点——将生成的rdd保存到可靠的存储中。在一些跨多个批组合数据的有状态转换中,这是必要的。在这种转换中,生成的rdd依赖于以前批次的rdd,这导致依赖链的长度随着时间不断增加。为了避免恢复时间的无限增长(与依赖链成正比),有状态转换的中间rdd会定期被检查到可靠的存储(例如HDFS),以切断依赖链。
总之,元数据检查点主要用于从驱动程序失败中恢复,而数据或RDD检查点即使是用于基本功能(如果使用有状态转换)也是必要的。
三.一个简单的测试用例
3.1 linux服务器安装nc服务
yum -y install netcat.x86_64 -- centos7 正确
yum -y install nc.x86_64 -- centos7 错误
nc -lk 9999
- 1
- 2
- 3
- 4
[root@hp2 yum.repos.d]# nc -help usage: nc [-46cDdFhklNnrStUuvz] [-C certfile] [-e name] [-H hash] [-I length] [-i interval] [-K keyfile] [-M ttl] [-m minttl] [-O length] [-o staplefile] [-P proxy_username] [-p source_port] [-R CAfile] [-s sourceaddr] [-T keyword] [-V rtable] [-W recvlimit] [-w timeout] [-X proxy_protocol] [-x proxy_address[:port]] [-Z peercertfile] [destination] [port] Command Summary: -4 Use IPv4 -6 Use IPv6 -C certfile Public key file -c Use TLS -D Enable the debug socket option -d Detach from stdin -e name Required name in peer certificate -F Pass socket fd -H hash Hash string of peer certificate -h This help text -I length TCP receive buffer length -i interval Delay interval for lines sent, ports scanned -K keyfile Private key file -k Keep inbound sockets open for multiple connects -l Listen mode, for inbound connects -M ttl Outgoing TTL / Hop Limit -m minttl Minimum incoming TTL / Hop Limit -N Shutdown the network socket after EOF on stdin -n Suppress name/port resolutions -O length TCP send buffer length -o staplefile Staple file -P proxyuser Username for proxy authentication -p port Specify local port for remote connects -R CAfile CA bundle -r Randomize remote ports -S Enable the TCP MD5 signature option -s sourceaddr Local source address -T keyword TOS value or TLS options -t Answer TELNET negotiation -U Use UNIX domain socket -u UDP mode -V rtable Specify alternate routing table -v Verbose -W recvlimit Terminate after receiving a number of packets -w timeout Timeout for connects and final net reads -X proto Proxy protocol: "4", "5" (SOCKS) or "connect" -x addr[:port] Specify proxy address and port -Z Peer certificate file -z Zero-I/O mode [used for scanning] Port numbers can be individual or ranges: lo-hi [inclusive] [root@hp2 yum.repos.d]# [root@hp2 yum.repos.d]# [root@hp2 yum.repos.d]# [root@hp2 yum.repos.d]# nc -lk 9999

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
3.2 Java spark代码
maven配置:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
代码:
package org.example; import org.apache.spark.SparkConf; import org.apache.spark.streaming.*; import org.apache.spark.streaming.api.java.*; import scala.Tuple2; import java.util.Arrays; public class SparkStreaming1 { public static void main(String[] args) throws Exception{ // Create a local StreamingContext with two working thread and batch interval of 1 second SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount"); JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1)); // Create a DStream that will connect to hostname:port, like localhost:9999 JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999); // Split each line into words JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator()); // Count each word in each batch JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1)); JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2); // Print the first ten elements of each RDD generated in this DStream to the console wordCounts.print(); jssc.start(); // Start the computation jssc.awaitTermination(); // Wait for the computation to terminate } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
运行spark程序代码:
spark-submit \
--class org.example.SparkStreaming1 \
--master local[2] \
/home/javaspark/SparkStudy-1.0-SNAPSHOT.jar
- 1
- 2
- 3
- 4
测试记录:
滚动太快,只能从日志中找到记录
参考:
1.http://spark.apache.org/docs/latest/streaming-programming-guide.html

