
- 1WebStorm: Emmet语法快速创建无意义的文字_webstorm lorem
- 2数据库大作业——基于qt开发的图书管理系统 (一)环境的配置与项目需求的分析
- 3云和恩墨zData X与星瑞格SinoDB完成产品兼容互认证
- 4JDK版本新特性介绍&JDK1.6_jdk1.6后的编译器与之前的版本的编译器有什么不同?
- 5yolov8添加ca注意力机制_yolov8+ca注意力机制
- 6Android P使用pm install安装apk报错_adb system server has no access to read file conte
- 7GitHub下载项目并运行_github的项目依赖下载
- 8GIT常用操作
- 9h5与原生app通讯(WebViewJavascriptBridge)_h5使用webviewjavascriptbridge
- 10上门服务小程序源码 家政小程序源码 同城到家小程序源码
【论文阅读笔记】HermesSim(Code is not Natural Language) (Security 24)
赞
踩
个人博客地址
HermesSim [Security 24]
论文:《Code is not Natural Language: Unlock the Power of Semantics-Oriented Graph Representation for Binary Code Similarity Detection》
仓库:https://github.com/NSSL-SJTU/HermesSim
提出的问题
二进制代码相似性检测(BCSD)是确定两个二进制函数之间的语义相似性的基本任务。
现有的BCSD方法主要分为两种:基于指令流的方法和基于控制流图(CFG)的方法。基于指令流的方法将指令流视为自然语言句子,并应用自然语言处理技术。这些方法虽然先进,但预训练过程昂贵,且侧重于学习代码的有限方面。而基于CFG的方法则侧重于利用图神经网络捕获控制流特征,但同样受限于对基于NLP方法的依赖。
作者提出,指令流与自然语言句子在语法上相似,但它们在结构、语义和约定上有本质的不同:
- 自然语言是模糊和弱结构化的,而二进制代码具有明确定义的结构和语义
- 在自然语言中重新排序单词可能改变语义,而在二进制代码中重新排序指令或在基本块间移动指令是可行的,不会影响语义。
- 第三,自然语言旨在有效地交换信息,而二进制代码旨在简化机器执行。
这些差异表明,将代码视为自然语言并不是最理想的。
作者建议开发一种二进制代码表示,能够:
- 显示指令内部结构,显示操作符如何使用操作数
- 显示指令间关系,例如定义使用、控制流程和必要的执行顺序
- 排除与语义无关的元素,例如用于临时缓存数据的寄存器和不必要的执行顺序限制
- 编码其他隐式知识,例如调用约定。
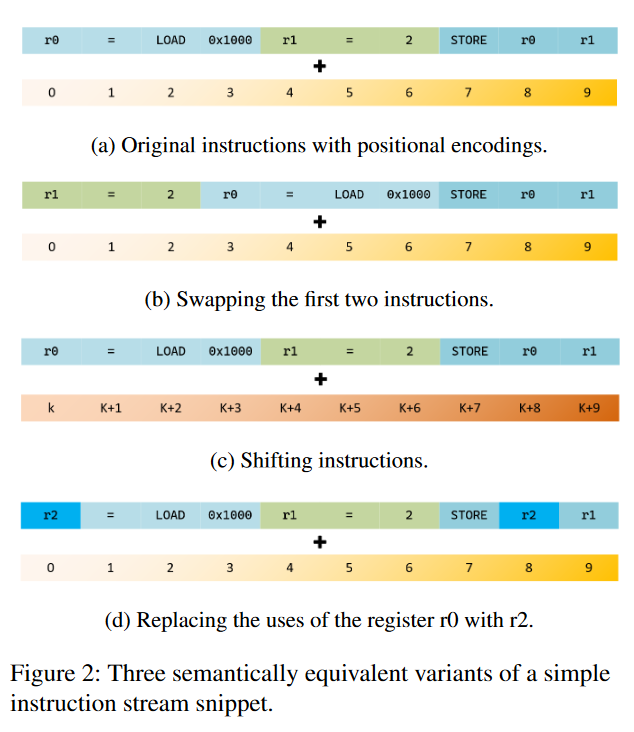
作者列举了三种简单的、语义上等效的转换,这些转换对NLP模型来说是必须学习的:
- 交换指令顺序: 代码片段中的前两个指令可以交换而不改变代码语义。然而,这种转换会改变产生的嵌入集,因此模型需要学习哪些指令的顺序可以调整而不改变语义。(如(b))
- 改变代码片段的位置: 整个代码片段可能由于在序列开始处插入了一些虚拟指令而被放置在不同的位置。这会改变所有token的位置嵌入,导致一个完全不同的嵌入集,模型需要学习不同位置的相同子序列在语义上是等价的。(如(c))
- 替换寄存器使用: 使用的寄存器r0可以被以前未使用的寄存器r2替换。模型需要学习所选择的确切寄存器是与语义无关的。相反,通过寄存器传递的数据流则是代码语义的一个组成部分。(如(d))
故学习这些附加的语义使得基于NLP的方法变得更加昂贵且难以泛化。
实现背景
二进制代码的隐含结构
作者先讨论了二进制代码的隐含结构,可以分为三个类别:指令内部结构、指令间关系和函数级别的约定。
-
指令内部结构(Intra-instruction Structures):指令有其内部结构。例如,MIPS架构中的指令
add r1, r2, r3可以解释为add操作符使用存储在寄存器r2和r3中的值,并将产生的值存储在寄存器r1中。同时,x86-64架构中的指令add rax, rdx可以解释为add操作符使用存储在寄存器rax和rdx中的值,但其输出存储在rax和eflags寄存器中。 -
指令间关系(Inter-instruction Relations):这些关系可以分为data (def-use relations), control (branches), and effect (execution order)。
-
Data relations:揭示了一些指令使用由其他指令定义的值。
-
Control relations:在基本块级别定义控制流。
-
Effect relations:之前的研究往往忽略了这一点,建立了指令间执行顺序的限制。(如Figure3(a)的第4行和第5行)
-
一种类似于传统控制流图表示的方法是将每个基本块中的指令序列化,以限制执行顺序。然而,这种表示方式施加了过多的限制。(第4行的指令不能与前面的两条指令交换,但第2行和第3行的指令可以交换而不影响代码语义)
-
为了追求效果和效率,作者的目标是在最终表示中仅包含必要的执行顺序。故采用the effect model:将额外的执行顺序限制建模为潜在的数据流。在上述示例中,STORE指令修改了一个内存槽,而CALL指令调用的子程序Foo可能读取或写入同一个内存槽,这构成了一个潜在的数据流。作者使用一个抽象的临时变量来代表每一组相关的内存槽。可能从该内存槽组读取值或写入值的指令被认为使用或定义相应的临时变量。
值得注意的是,构建的效果流与分析能力有关。例如,在(d)中,如果确定被调用的子程序不与内存交互,或STORE指令仅修改当前堆栈帧,而任何子程序都不会访问它,那么在它们之间就不需要引入效果关系。
-
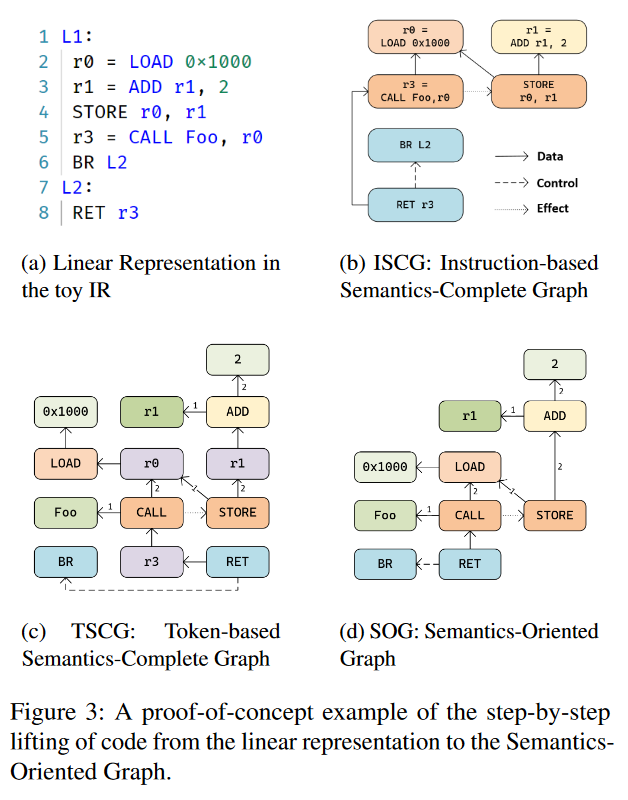
图 3a 中代码片段的语义解释如下。第 1 行的标签 L1 和第 7 行的标签 L2 分别表示两个基本模块的开始。指令 r0 = LOAD 0x1000 加载地址为 0x1000 的内存槽值,并将其放入寄存器 r0。随后,r1 = ADD r1, 2 将表达式 r1 + 2 的值存储到寄存器 r1 中。STORE r0, r1 将 r1 的值存储到 r0 所指示的内存地址中。指令 r3 = CALL Foo, r0 以 r0 为唯一参数调用子程序 Foo,并将返回值存入 r3。BR L2 直接跳转到标签 L2 标记的基本程序块。最后,RET r3 将控制权返回给调用者,返回值设置为存储在 r3 中的值。
-
-
函数级别的约定(Function-level Conventions):调用约定定义哪些寄存器用作调用参数和返回值,这有助于恢复调用指令的定义使用关系。此外,函数将临时变量存储在自己的堆栈帧中,其他函数不会访问这些临时变量。这种理解有助于完善Effect relations。
Semantics-Oriented Graph
故提出的SOG(Semantics-Oriented Graph)将通过处理三个关键方面,有效捕获二进制代码的语义:
- 位置独立性:SOG不会为每个指令或token分配位置标识符,因为二进制代码的语义与位置无关。因此,图表示被认为更适合此目的。
- 选择性执行顺序:SOG避免完全采用执行顺序来限制指令,因为大部分执行顺序限制是机器相关的,但与语义无关。SOG使用“效果模型”仅限制必要的执行顺序。
- 消除与语义无关的token:SOG旨在去除与语义无关的token,同时对携带语义意义的指令或token之间的关系进行建模。
SOG的构建包括三个步骤:
- 基于指令的完整语义图(ISCG):第一步将指令序列提升为图形表示,展示指令之间的关系作为边。这种表示增强了数据流图(DFG),增加了额外的control flow 和 effect flow边。指令是节点,图不指定指令属于哪个基本块,允许指令在基本块之间“浮动”,而不改变语义。
- 基于token的完整语义图(TSCG):第二步涉及将指令分解为token,以揭示指令内部结构,这简化了节点嵌入并消除了与语义无关的元素。这个过程根据引入它们的特定指令token来细化指令间关系。
- 最终的SOG表示:最后一步涉及去除代表临时存储(如寄存器或堆栈插槽)的节点,这些存储在语义上是独立的,并直接连接它们的输入和输出。此步骤保留了未初始化存储的使用,因为它们携带语义信息(未初始化的存储大多携带从调用者例程传递的值。如果当前函数的调用约定已知,则可以使用未初始化存储的名称来推断参数在参数列表中的位置)。
SOG能够编码各种函数级约定,例如调用参数和堆栈帧。例如,它可以通过从调用节点到参数节点添加数据边来揭示调用参数,并使用抽象临时变量来模拟堆栈帧的效果。
实现
SOG的构建
SOG 的构建可以通过与将线性 IR 转换为 SSA 形式类似的过程来完成。
将 SOG 分为三个子图:
control子图构建:
- 在基本块的末尾插入虚拟分支(BR)指令,以确保每个基本块以branch指令结束。
- branch指令作为基本块的代表,转化为图的节点。
- 从branch targets到branches添加控制流边。
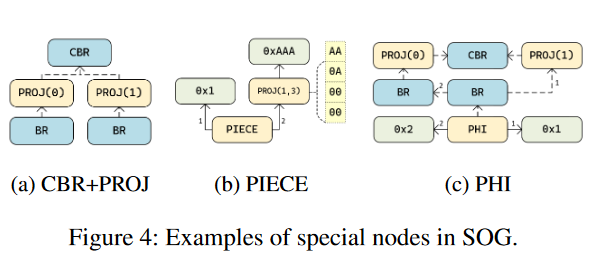
- 为了避免歧义,每个节点被视为只为每种类型的关系定义单一值
- 对于有多个后继者的条件或间接分支指令,将其输出视为连接值,并为每个后继者引入一个投影(PROJ)节点,将连接值投影为该特定后续者的单元值。
data子图构建:
- 通过定义-使用(def-use)分析来构建。
- 为每个指令操作符创建一个节点,并为每个操作数添加指向定义该操作数值的前一个节点的有向边。
- 如果找不到定义操作数的前一个节点(如整数文字或未初始化的寄存器),则引入代表该整数文字或未初始化寄存器的新节点。这样,所有引用同一未定义操作数的指令都连接到同一操作数节点。
- 这个过程还包括解决对齐挑战,例如多个指令同时定义一个操作数值。为此引入了一个特殊的节点类型,PIECE,用于抽象地连接多个值。
effect子图构建:
- effect子图的构建与data子图类似,将effect视为特殊类型的由特殊指令使用和定义的值。
- 识别两种效果模型:内存effect和I/Oeffect。
- 内存 effect:从内存加载值的指令使用内存effect,改变内存状态的指令使用并定义内存effect。
- I/O effect:以类似方式构建。
此外,还在SOG中集成phi节点。SOG的构建自然与静态单赋值(SSA)形式一致,因为它为每个指令定义了一个节点。为了保持简洁,需要为data值和effect值引入必要的phi指令。
- 由于 phi 指令的语义取决于控制流,因此首次引入 phi 节点时,将其设置为 phi 指令所在基本块的分支节点。
- 其他位置引用phi 节点时,按照分支节点的出边的顺序进行设置:当分支节点通过它的第 i 条出边接收到控制流时,使用该分支节点的phi节点就会选择第 i+1 个输入作为输出。
论文的Appendix A中提供了图构建算法的伪代码。
系统框架
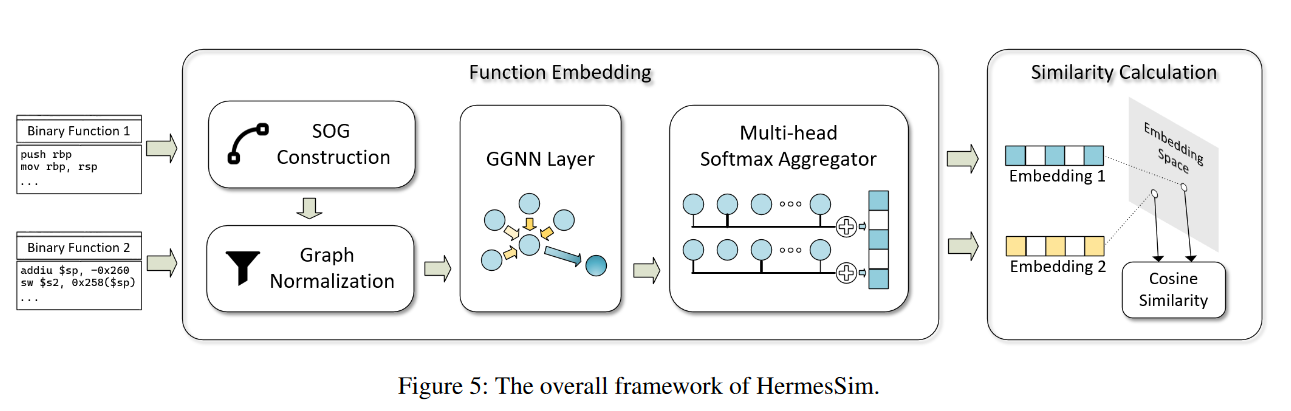
SOG的每个节点都有一个token,每条边都有一个类型label和一个位置label。
训练
我们采用基于边际的成对损失[21]和距离加权负采样策略[41]进行训练。
通过首先对 N 个不同的函数符号进行采样,然后对每个符号具有不同编译设置的 2 个函数进行采样来收集小批量。
使用余弦相似度的负值作为距离度量。
函数嵌入
图归一化和编码
每个节点都有一个token,直接
映射到可学习的嵌入向量。
每条边都有一个类型属性(data、control或effect)和一个位置属性(相应操作数的索引)。分别将类型和位置属性转换为两个嵌入,并将它们相加形成最终的边嵌入。
模型需要学习包括token和label在内的词汇表。一些token和label在词汇表之外,故:
- 为每个token分配一个token类型,共三种(instruction tokens, integer literals, and register tokens)
- 由于不同的架构有不同的寄存器使用习惯,我们进一步根据架构将register tokens分为几种子类型。
- 对于每种类型的token,识别最常见的token并将它们包含在模型的词汇中。其他不常见的token进行归一化。
局部结构捕捉
使用双向 GGNN 层来捕捉每个节点的邻接结构。
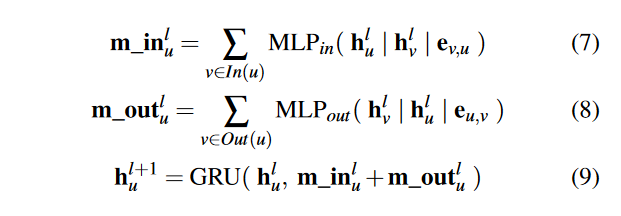
Multi-head Softmax Aggregator
采用Multi-head Softmax Aggregator,将所有节点嵌入聚合成图嵌入,它改编自 softmax 聚合器 [19]。
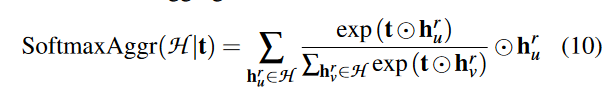
- (10)定义了如何计算一个节点的加权嵌入向量,其中 t 是一个可学习的参数向量,H 是所有节点嵌入向量的集合。它通过Softmax函数对所有节点嵌入进行加权求和,得到最终的图嵌入。
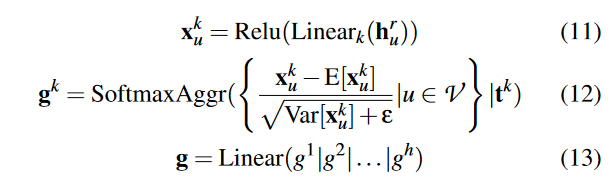
-
公式(11) :每个头的节点嵌入首先通过一个线性层转换到不同的表示空间,然后通过ReLU函数进行非线性变换。
-
公式(12) :通过Softmax聚合器对每个节点的特征进行选择性加权,其中每个头的输出 x^k_u 会减去平均值并除以标准差,实现了特征的归一化处理。ε 是一个小数,用来保证数值稳定性。
-
公式(13) :最终,所有头的输出嵌入向量被拼接起来,并通过另一个线性层来生成最终的图嵌入 g。
实现工具
图构建模块基于 Ghidra
- 利用 Ghidra 来反汇编二进制函数并将它们提升到其 Pcode IR,然后基于该 Pcode IR 构建 SOG。
图嵌入模块: Pytorch 和 PyG 。
效果
参数设置和结果图表详见论文。
数据集: 使用先前研究发布的Dataset-1,包含三种不同架构(x86、ARM和MIPS)、两种位模式(32位和64位)、5个优化级别(O0、O1、O2、O3和Os)的257K训练、13K验证和522K测试二进制函数,由两个不同的编译器家族(GCC和CLANG)编译。
**对比实验:**Table 1、Figure 7
- **结果:**HermesSim在各种设置下都明显优于所有基准方法。
- 不同子任务的性能:GMN通常在涉及跨体系结构的CFG的任务中优于基于NLP的方法,如SAFE、Asm2Vec和Trex。然而,在使用大型池大小的某些任务中,GMN的性能不如Trex。这可能是因为在大型池中搜索时,CFG可能会发生冲突。
- 模型参数:基于NLP的方法与基于图表示的方法相比具有更多的参数,至少多一个数量级。
- 稳定性和可扩展性:HermesSim的性能在池大小增加时保持稳定,并且在池大小增加时甚至比最先进的基准方法,如jTrans和GMN,表现得更好。
**消融研究:**Table 2、Figure 8
- SOE表示方法在BCSD任务中具有较好的性能,相对于其他基准方法和表示方法,它在召回率和效果方面都表现出色
- 多头softmax聚合器也表现出色。
运行时效率:
-
运行时成本:

-
图表示的大小和推断时间:
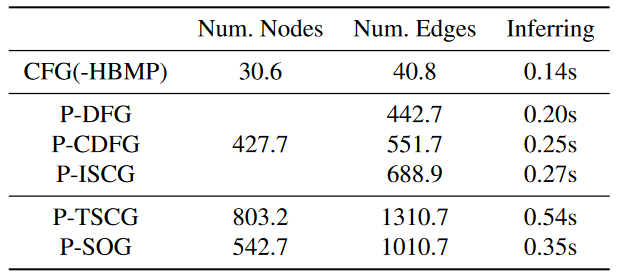
CFGs和ISCGs平均而言比SOGs小,这意味着在本地结构捕捉阶段具有更低的内存和时间成本,但会增加节点属性提取的复杂性
现实世界漏洞搜索:
-
研究人员收集了来自三个供应商(TP-Link、Mercury和Fast)的12个RTOS固件图像,进行了1天漏洞搜索任务。他们构建了一个包含62605个函数的存储库,跨两种不同架构(ARM32和MIPS32)。在TP-Link WDR7620固件中手动识别了5个CVE和10个易受攻击函数,并将这些易受攻击函数用作查询。
-
对于每个查询函数,研究人员将存储库中的函数分为三组:c1代表与查询函数具有完全相同源代码构建的函数,c2代表与查询函数具有相同符号但源代码略有不同的函数,c3代表其他从不同源代码编译的函数。
-
通过使用HermesSim和其他基准方法进行相似性搜索,并手动检查前20个结果。
理想情况下,BCSD 系统应将 c1 中的函数排在 c2 和 c3 中的函数之前,并将 c2 中的函数排在 c3 中的函数之前。
-
结果:HermesSim在失败次数、RECALL@1和MRR方面明显优于其他基准方法。它能够有效地识别和排名易受攻击函数,包括那些在源代码略有不同或不同架构之间的情况。
Appendix B 展示漏洞的详细信息
讨论(潜在改进)
Dirty Effect Problem:
-
编译器引入与effect相关的指令
-
堆栈临时变量的数量取决于体系结构和优化级别,在effect flow中包含堆栈内存访问可能没有好处
-
解决方案:load-store elimination analysis
I/O Effect Model:**本文只研究了memory effect model。 ** I/O Effect 涉及到与I/O设备交互的指令。
Extra Information and Encoding Ability:本研究不处理对字符串、整数、外部函数符号和其他相关实体的引用。
Addressing Analysis Failures:
-
当前的传统程序分析算法可能无法完全恢复间接分支的控制流关系,这一限制影响了SOG表示。
-
探索如何向深度神经网络提供必要的信息(例如,引用的数据),以使它们能够推断间接分支的控制流,可能是值得的。
结论
在本文中,作者提出了一种语义完整的二进制代码表示方法,即语义导向图(SOG),用于二进制代码相似性检测(BCSD)。这种表示方法不仅利用了代码结构、语义和约定的明确定义,而且还清除了嵌入在低级机器代码中与语义无关的元素。作者详细介绍了SOG的构建过程,并讨论了对这种表示方法的潜在改进。为了充分发挥SOG在BCSD中的潜力,作者提出了一种新颖的多头softmax聚合器,它允许有效融合图的多个方面。通过整合所提出的技术,作者构建了一个有效且高效的BCSD解决方案,HermesSim,该解决方案依赖于图神经网络(GNN)模型来捕获SOG的结构信息,并采用先进的训练策略。广泛的实验表明,HermesSim在实验室实验和现实世界的漏洞搜索中都显著优于现有的最先进方法。此外,评估证明了揭示二进制代码的完整语义结构和清除与语义无关的元素的价值。作者还展示了所提出的聚合器的有效性和HermesSim的高效性。
附:部分基础概念解释
基于边距的成对损失 (Margin-based Pairwise Loss)
- 定义与目的: 这种损失函数主要用于学习数据点之间的相对距离或相似度。它通常用于诸如人脸识别、推荐系统等领域,其中需要判断两个数据点是否相似或不同。
- 工作原理: 基于边距的损失函数会考虑成对的数据点(例如,两个不同的图像)。对于每一对相似的点(正样本对),它试图将它们的表示拉近;对于不相似的点(负样本对),则推远它们的表示。
- 边距 (Margin): 损失函数中的“边距”是一个预设的阈值,用于区分正样本对和负样本对之间的距离。如果一对数据点的距离小于这个边距,模型会受到惩罚,因此模型会学习使正样本对的距离尽可能小,而负样本对的距离大于这个边距。
距离加权负采样策略 (Distance-Weighted Negative Sampling Strategy)
- 背景: 在训练过程中,选择合适的负样本对(即不相似的数据点对)对模型性能至关重要。
- 策略含义: 距离加权负采样是一种选择负样本对的方法。这种策略根据数据点之间的距离来加权选择负样本。与随机选择不同,这种方法倾向于选择那些与正样本对距离相近但实际上是负样本的数据点。
- 优势: 这种策略可以提高模型对困难负样本(即那些与正样本在特征空间中较为接近的负样本)的识别能力。通过这种方式,模型可以更好地学习区分相似但不同的数据点,从而提高泛化能力。
图神经网络(GNN)
- 基本概念:图神经网络是一种专门处理图结构数据的神经网络。在图神经网络中,图由节点(代表实体)和边(代表实体间的关系)组成。
- 功能:GNN的目标是学习节点的表示(embedding),这些表示可以捕捉节点的特征以及它们与其他节点的关系。
门控图神经网络(GGNN)
- 门控机制:GGNN引入了门控机制,类似于LSTM(长短期记忆)网络中的门控。这种机制可以帮助网络更有效地控制信息的流动,特别是在处理图中的长距离依赖时。
- 工作原理:在GGNN中,每个节点根据其邻居节点的信息来更新自己的状态,这个过程涉及到信息的聚合和门控操作。
间接分支的几个典型例子
- 基于变量的跳转:例如,C语言中的
switch语句可能被编译成使用跳转表的间接跳转,其中具体的跳转目标取决于switch语句的条件变量。 - 函数指针调用:当通过函数指针调用函数时,具体调用哪个函数是在运行时决定的,这也是一种间接分支。
- 虚拟调用:在面向对象编程中,如C++或Java,虚函数的调用通常是间接的,因为直到运行时才能确定具体调用哪个派生类的方法。
附
SOG Construction Algorithm

2: 输入是一个二进制函数f,是汇编语言或线性中间表示(IR)形式的函数。
3: 创建一个新的DefState对象,用于跟踪和管理在构建SOG过程中所有变量的定义状态。
4: 创建一个新的SOGConstructor对象,这是构建SOG的工具。
5: 调用GetAbstractEffectNodes函数获取所有抽象的效应节点,这些节点代表程序中可能影响状态的操作(如内存写操作)。
6: 计算函数f的控制流图(CFG)的支配树(Dominator Tree),它是理解代码结构的一种方法,可以确定某个特定节点必须通过哪些路径才能被到达。
7: 在函数f中插入Phi节点,Phi节点用于合并来自支配树中不同路径的变量定义。
8: 准备函数f的控制流相关数据,可能涉及到设置控制流节点和边的关系。
9: 处理函数f的每个基本块,使用defState来跟踪定义状态,f.start是处理的起始点,effectNodes包含了所有需要考虑的effect节点。
10: 返回构建的语义导向图g

13: 遍历函数f中的所有基本块(bb)。
14-15: 检查每个基本块是否以分支指令结束。如果不是,添加一个虚拟的分支指令,这是为了确保每个基本块在图中都正确地表示其控制流。
16: 创建一个新的节点(node)来表示基本块中的最后一条指令,这里假设基本块的最后一条指令是与控制流相关的。
17: 在defState中记录这个基本块与新创建的节点之间的关系。

20: 提交当前的定义状态,这相当于在处理每个基本块之前保存当前的变量定义状态。
21: 调用BuildInBlock函数,为当前的基本块bb构建内部结构
22-23: 对于基本块的每个子节点,递归地调用ProcessBlock函数来处理。
24: defState.revert()回滚到最后一次提交的定义状态。这是为了在处理完当前基本块及其子代后,能够恢复到进入基本块之前的状态,以便准确地处理其他基本块。

28: 遍历基本块bb中的每一条指令inst。
29: 为每条指令创建一个对应的SOG节点node。
30: 将创建的节点node添加到SOG中。
data flow
32-34: 对于指令的每个输入操作数,创建或获取一个对应的inpNode,并将其作为data-use添加到节点node。
35-36: 对于指令的每个输出操作数,更新defState以反映最新的定义状态
effect flow
38-39: 遍历所有的effect,如果节点node使用了这个effect,则添加一个effect-use关系。
40-42: 如果节点node定义了某个效应,则更新defState以反映这个effect的最新定义状态。
control flow
44-48:如果节点node是一个控制节点(例如条件分支),则对其前驱节点进行处理,可能包括用MayWrapWithProj包装多个后继的情况,并添加控制使用关系。
49-52:对于基本块的每个后继节点succ,处理与Phi节点相关的控制流,这可能涉及到在Phi节点中设置正确的输入顺序。
最后,过程返回,完成对当前基本块内部结构的构建。

