
热门标签
热门文章
- 1【TI-CCS】工程编译配置 bin文件的编译和生成 各种架构的Post-build配置汇总_ccs生成bin文件
- 2BARF阅读笔记----NeRF与Pose的联合优化_barf nerf
- 3为什么开发人员不愿意写单元测试?
- 4解决Windows 10更新后无法连接网络的问题_一台 windows 10 计算机在一周前完成最新的 windows 更新后,突然开始出现网络连接
- 5桥接模式总结-java版_桥接模式是java虚拟机和jdbc
- 6《从零开始打造固定翼飞控》arduino平台esp32-c3芯片mpu6050 卡尔曼滤波kalman
- 7MATLAB中的矩阵操作与编程技巧_matlab如何把数据编程矩阵
- 8安装JDK1.8报错Error: could not find java.dll Error: Could not find Java SE Runtime Environment._jdk1.8 could not find java.dll
- 9CentOS7部署Kafka_centos kafaka
- 10【C++风云录】打破科研壁垒:药物设计与计算化学
当前位置: article > 正文
【yolov3】yolov3原理详解_yolov3锚框有多少
作者:weixin_40725706 | 2024-05-17 19:34:12
赞
踩
yolov3锚框有多少
yolov4,yolov5都是在yolov3的基础上做的更改。
一.yolov3骨干网络
52个卷积层,一个全连接层,并且里面加了残差连接。
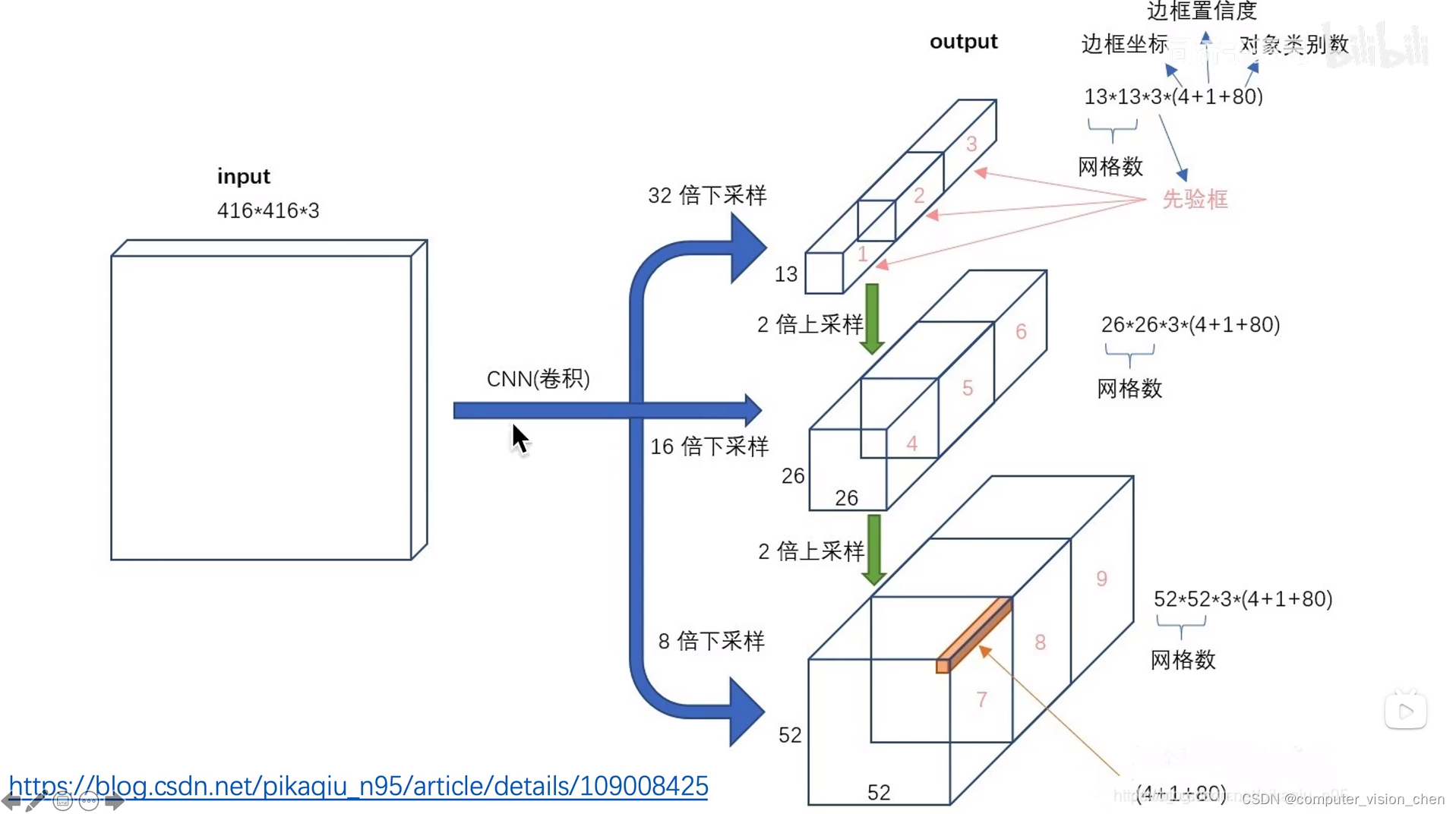

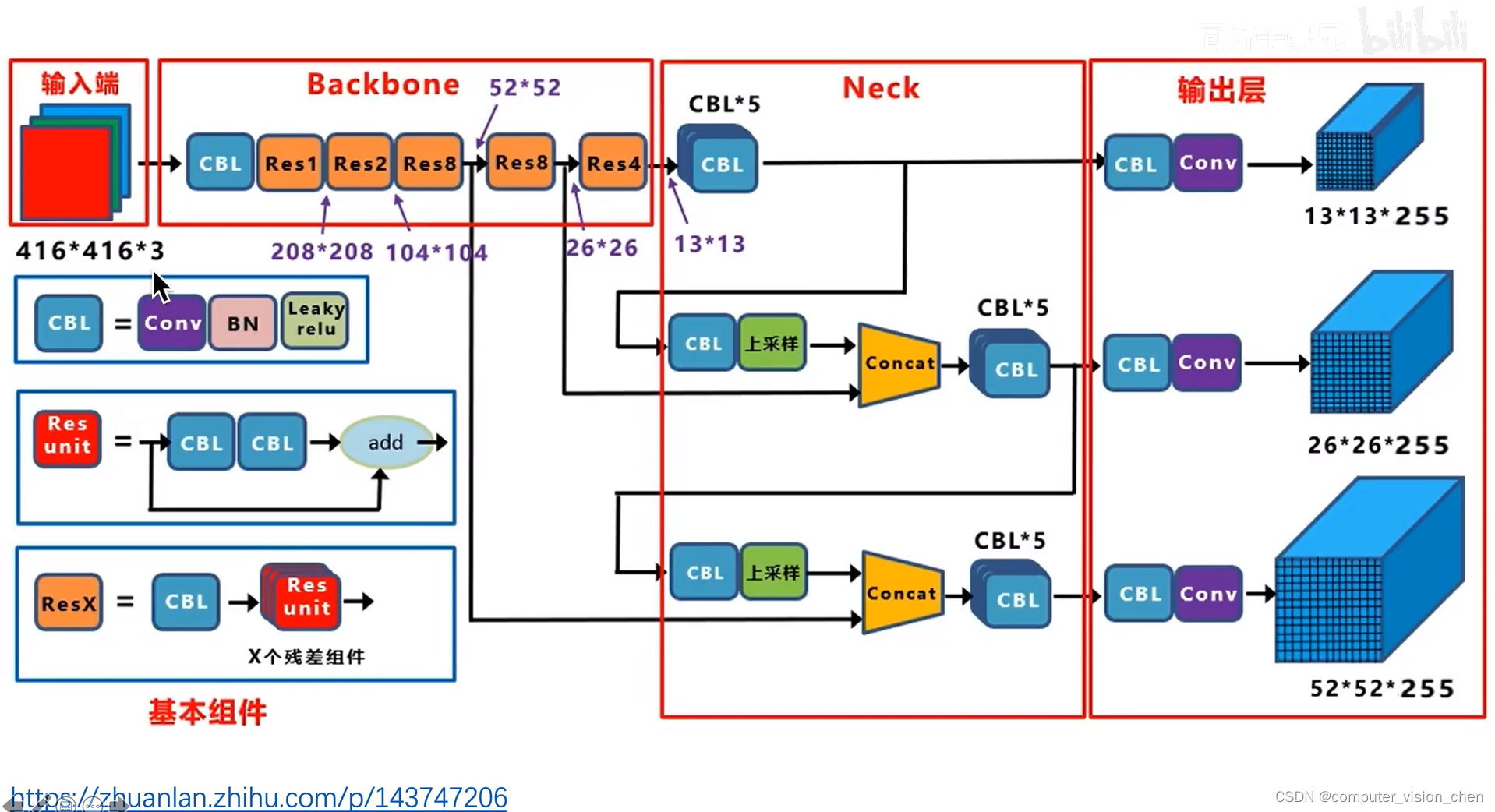
每一层的输入输出大小图
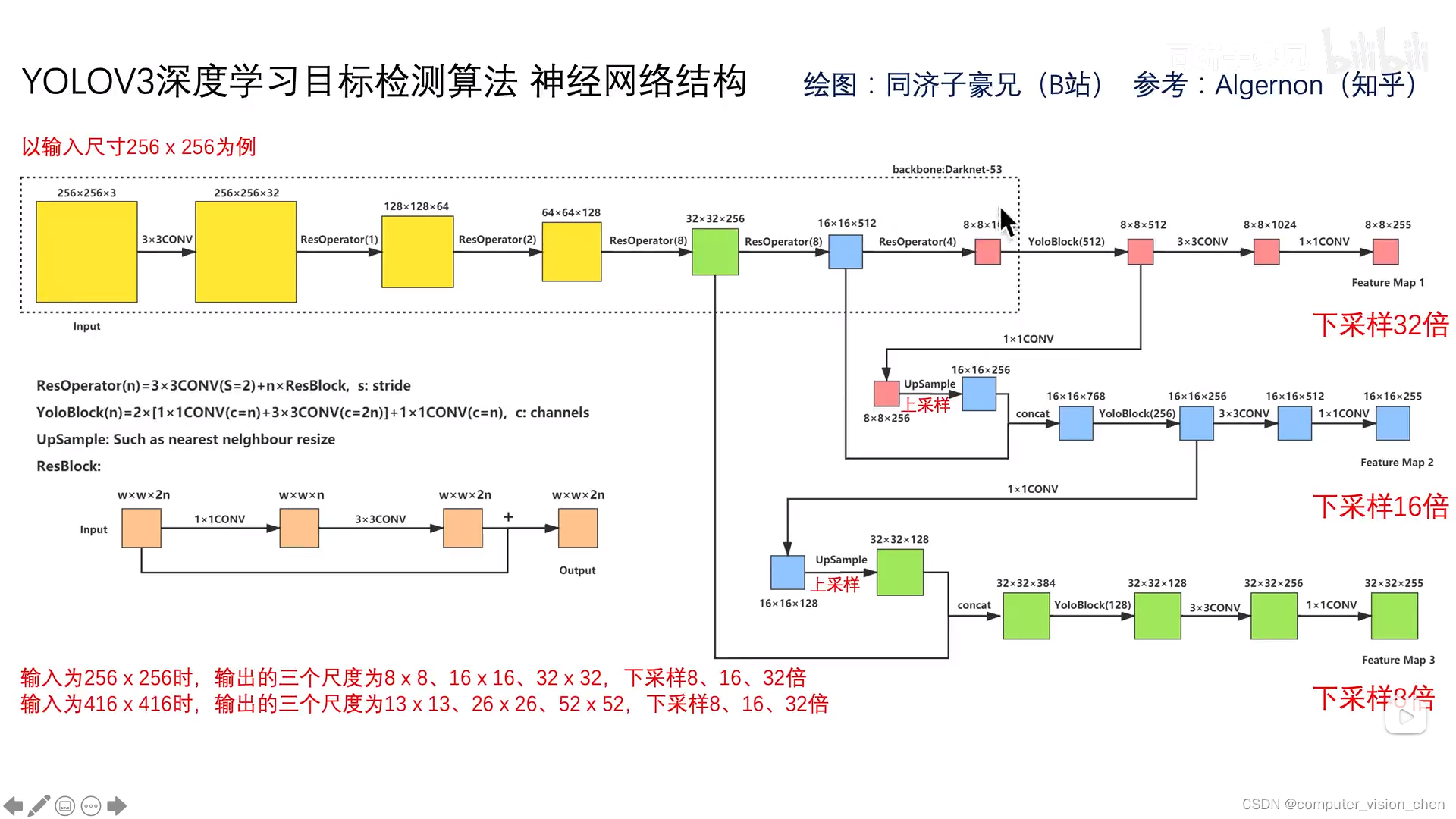
二.输入输出
如上图所示
输入 416x416x3
输出 三个 feature map
13x13x255
26x26x255
52x52x255
- 1
- 2
- 3
- 4
- 5
输出的255是怎么来的?
每个gred cell生成三个锚框,每一个锚框对应一个预测框,每一个预测框有 5(x,y,w,h,置信度) + 80(80个类别的条件概率)
3x85=255
- 1
- 2
多尺度输出的作用
一共9个锚框,一个尺度分配三个
grid cell为13x13,对应输入图像的感受野是32x32
grid cell为26x26,对应输入图像的感受野是16x16
grid cell为52x52,对应输入图像的感受野是8x8
- 1
- 2
- 3
- 4
13x13负责预测大物体,分配大的锚框。
26x26负责预测中等大小的物体,分配中等大小的锚框。
52x52负责预测小物体,分配小的锚框。
- 1
- 2
- 3
三.正样本负样本
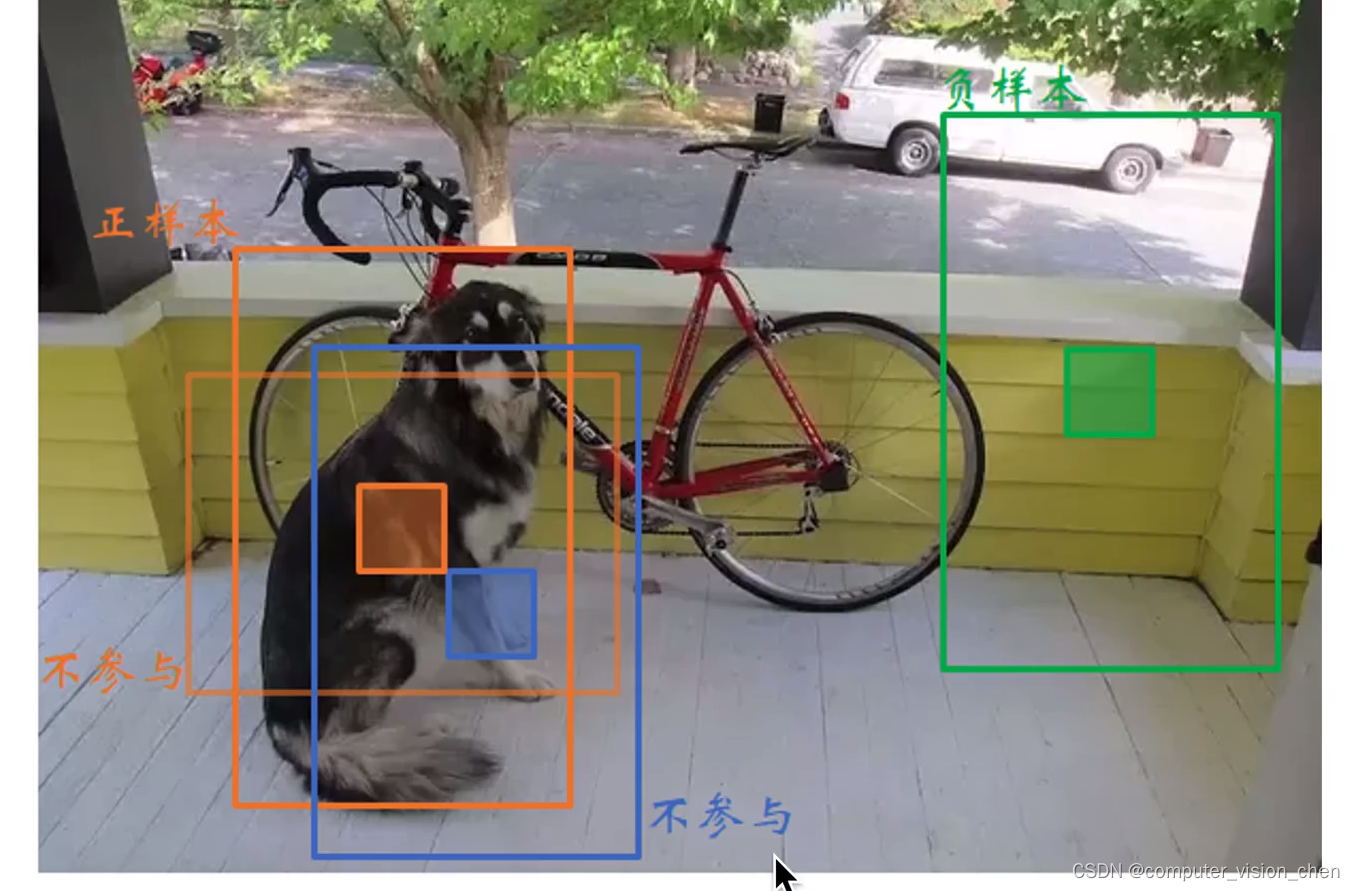
假如蓝框是真实框,那么与蓝框IOU最大的是正样本。
与蓝框IOU超过一个阈值,但IOU不是最大,则不参与
与蓝框IOU低于一个阈值,则为负样本
四.yolov3损失函数
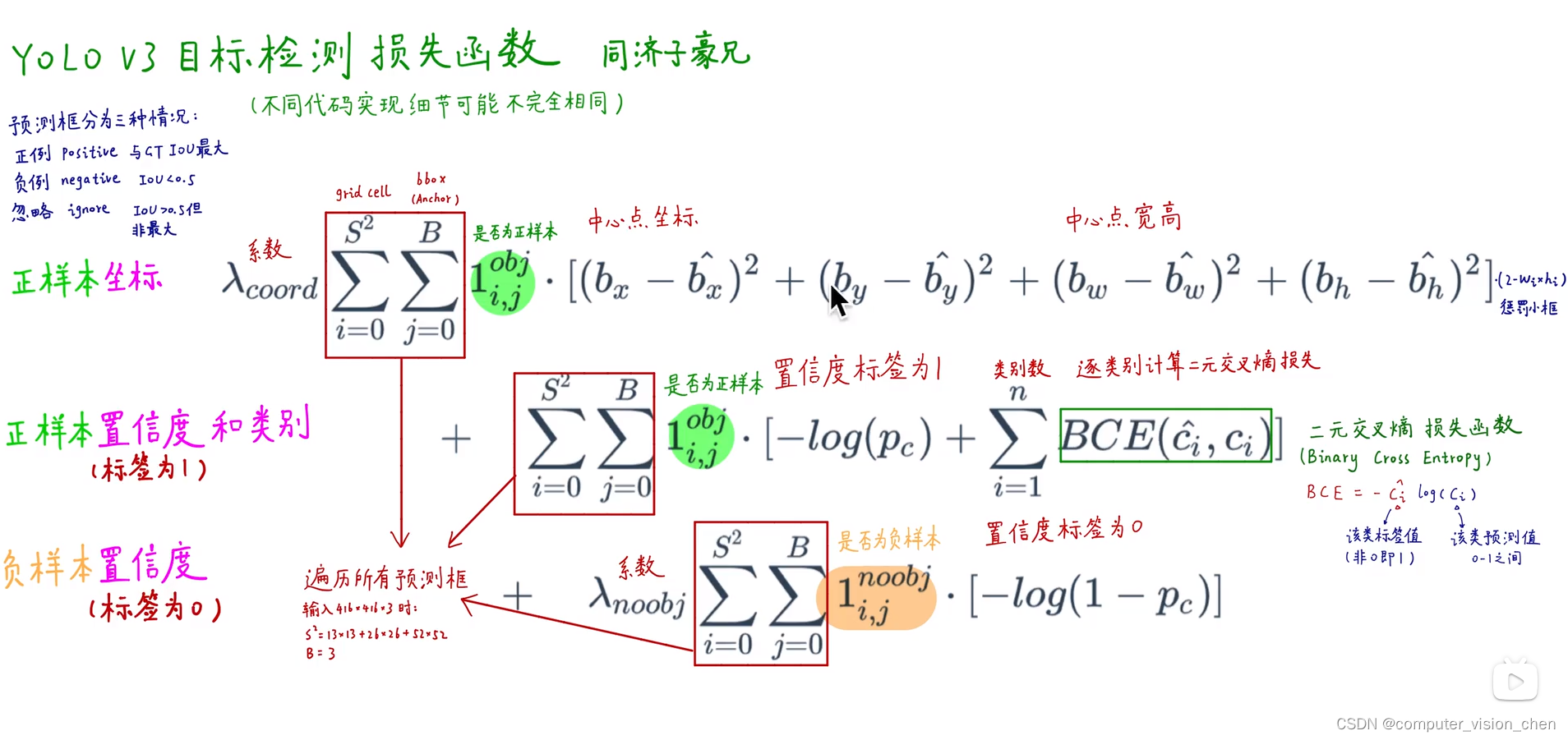
正样本对中心点坐标进行回归
正样本的置信度和类别损失:正样本置信度标签为1
负样本置信损失:负样本置信度标签为0
- 1
- 2
- 3
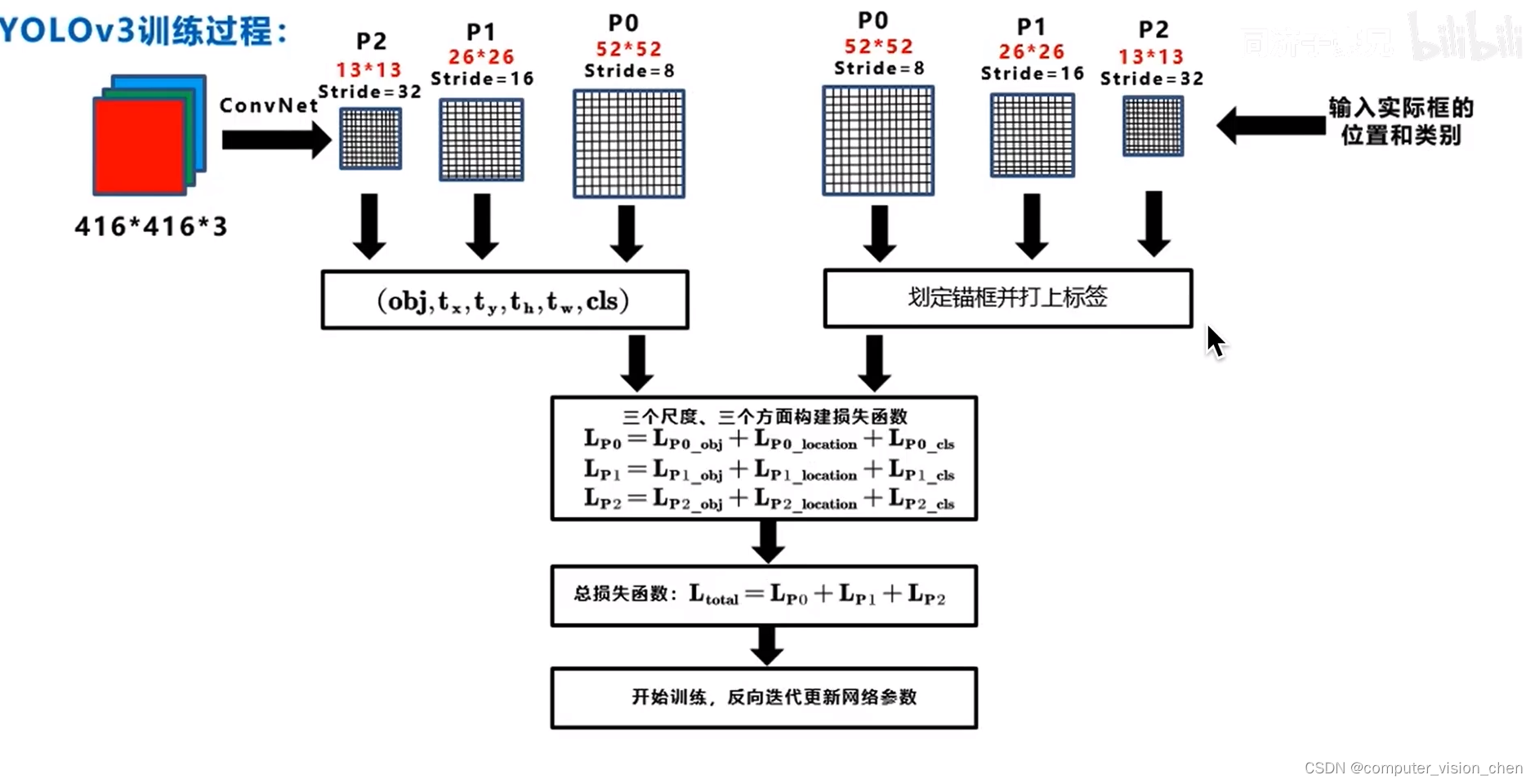
五.训练过程
六.测试过程
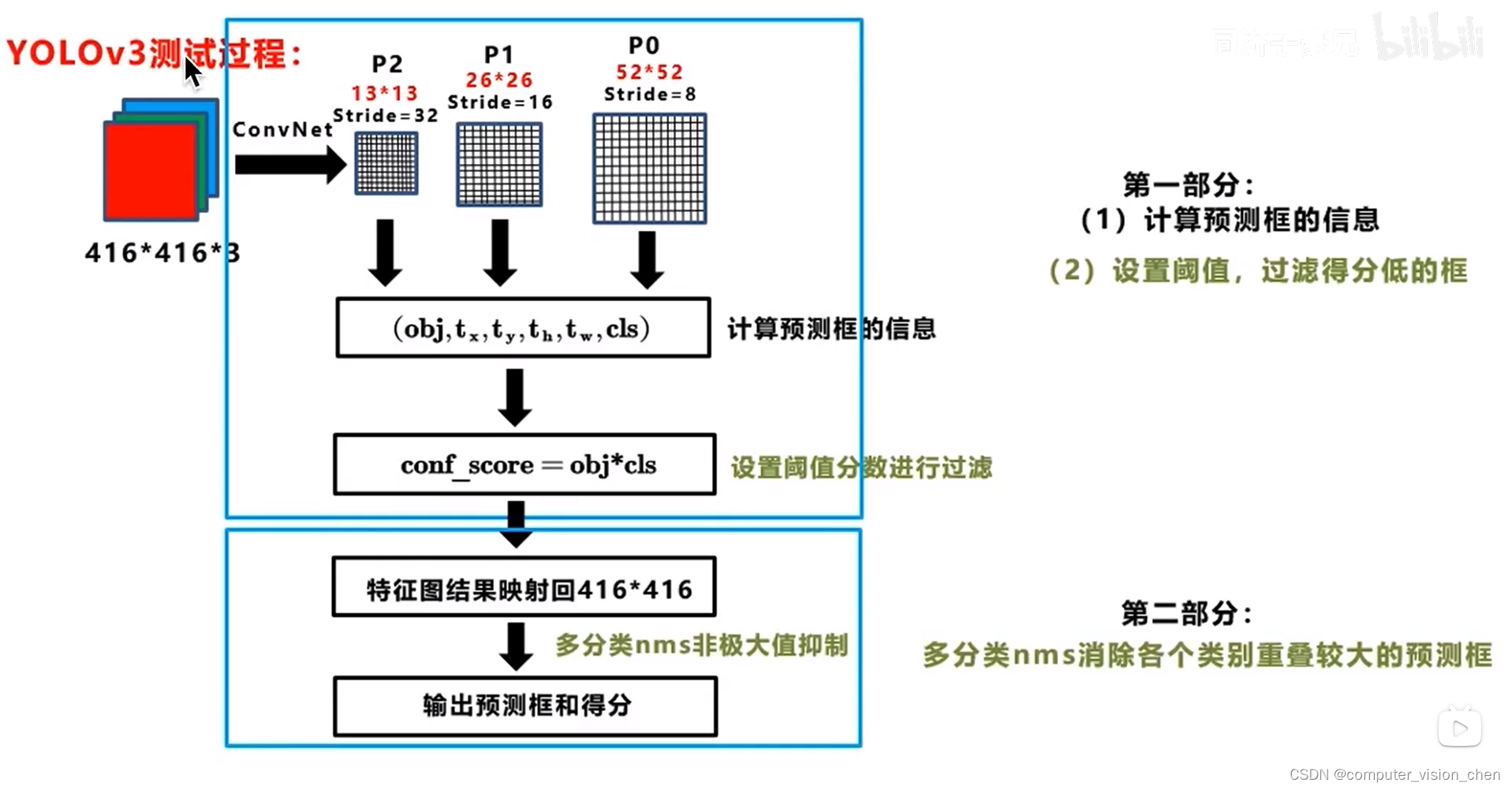
去掉置信度小于某个阈值的框
再用NMS将同一个物体重复预测的框去掉
- 1
- 2
NMS原理:按照置信度排序,取最大的置信度的框,让它与其它框做IOU,当IOU与置信度最大的框超过某个阈值,就视为与置信度最大的框重复预测,就把它去掉。然后再找出除上一个最大的置信度框之外最大的置信度框,重复上述过程
- 1
优点
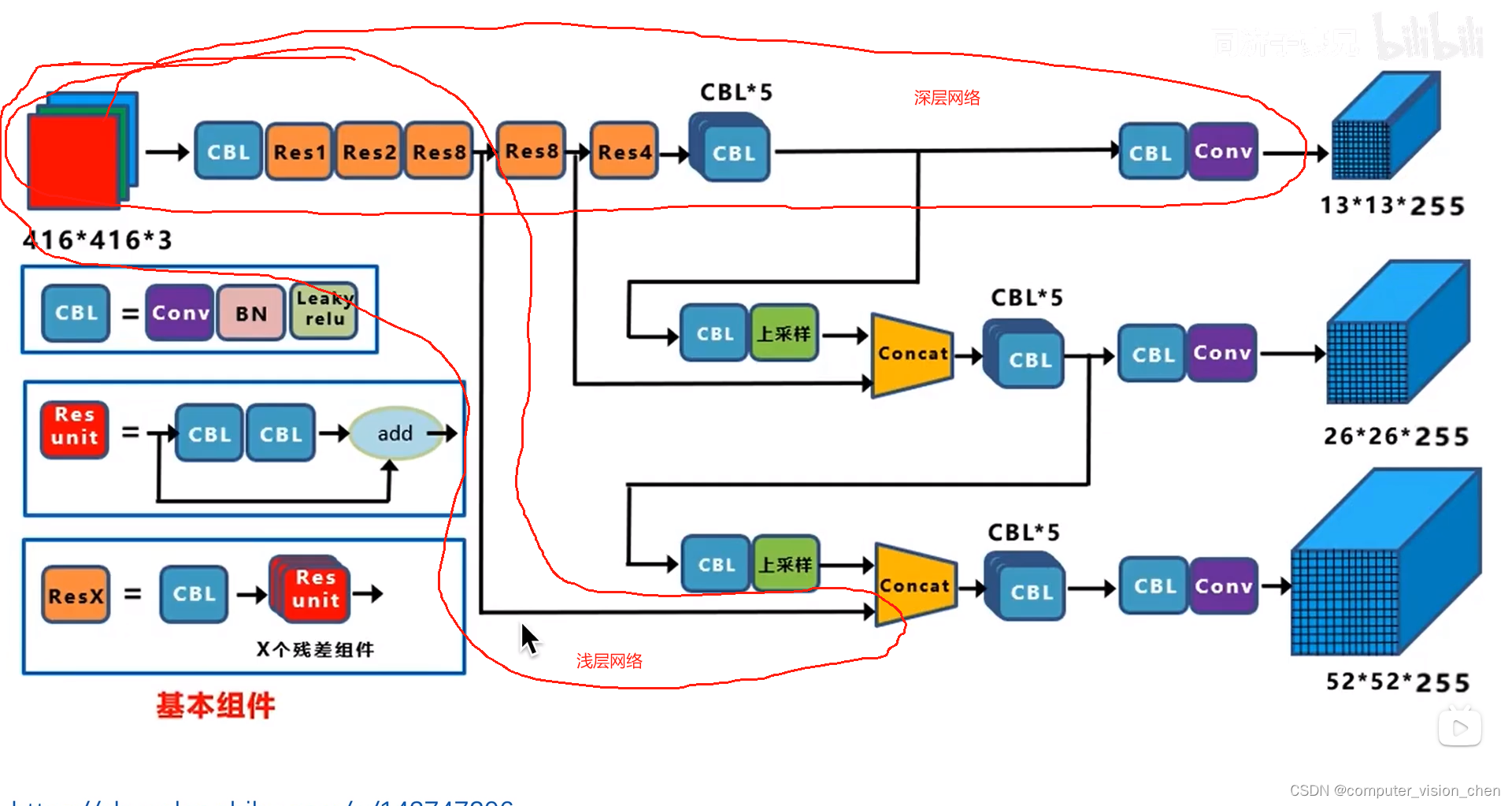
即发挥了深层网络抽象的特征。
也充分利用了浅层网络细粒度,像素级的信息。
可以对不同尺度的物体进行预测。
补充
下采样
在卷积神经网络中,下采样通常是指对输入数据进行降采样,以减少数据的维度和计算复杂度。下采样倍数表示采样后的数据相对于原数据的减少比例。
如果下采样倍数为3,那么采样后的数据量将是原数据量的1/3。下采样可以通过池化(pooling)或丢弃(discarding)数据等方式实现。
例如,对于一个输入数据为100x100的图像,如果进行3x3的下采样操作,那么采样后的图像大小将为33x33。这样可以减少网络的输入大小,从而减少计算量和过拟合的风险,同时保留重要特征,提高模型的泛化能力。
需要注意的是,下采样倍数并不是任意设定的,它通常根据具体任务和数据集来确定,同时也需要考虑采样的效果和计算资源之间的平衡。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
参考链接
https://www.bilibili.com/video/BV1Vg411V7bJ/?spm_id_from=333.788.recommend_more_video.0&vd_source=ebc47f36e62b223817b8e0edff181613
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/584967
推荐阅读
相关标签

