
- 1第十四届蓝桥杯真题EDA设计跟画笔记_14届蓝桥杯国赛eda
- 2【前端开发】基于vue+element-ui开发的流程设计器解决方案_vue 流程设计器
- 3TransE模型的python代码实现_transe代码实现
- 4微信小程序开发|基于微信小程序的健身陪练系统的设计与实现_设计一个微信小程序健身管理系统需要用到哪些技术
- 5复杂高维医学数据挖掘与疾病风险分类研究_疾病风险模型的分类研究
- 6利用HttpServletRequestWrapper来支持可重复读取HttpServletRequest中的请求输入流且不影响Controller层的参数获取_java request 流改成可重复读流的性能影响
- 7通过Docker Compose安装MQTT_docker mqtt
- 8alexnet学习笔记(代码篇)_alexnet代码
- 9偶然发现了Python的一个BUG。。。
- 10解决docker运行redis报错:Fatal error, can‘t open config file /etc/redis/redis.conf以及启动redis后自动退出容器_fatal config file error (redis 6.2.1)
深度分析分布式文件系统(Hadoop HDFS)客户端写入机制_setuppipelineforappendorrecovery
赞
踩
1. 开篇
Hadoop分布式文件系统(HDFS)是Hadoop大数据生态底层的数据存储设施。因其具备了海量数据的分布式存储能力,并针对不同批处理业务的大吞吐数据计算承载力,使其综合复杂度要远远高于大多数存储系统。
本文重点从客户端文件向HDFS写数据的角度切入,通过架构体系的分析绘制,源代码的层层分析,逐渐深入Hadoop内部机制,使其流程逐渐明朗化。HDFS数据写入过程是Hadoop核心技术中最复杂的流程之一,对其原理的掌握需要花费一些时间和精力,但这部分内容也是分布式文件系统架构机制的精髓所在。
首先我先列出一些HDFS的专业名词,方便阅读理解:
- namenode:命名空间管理节点,负责HDFS元数据的管理,以及数据块读取和写入过程中的资源管理与分配等
- datanode:数据任务节点,负责存储数据文件,负责与客户端之间、数据块之间的文件读取和写入
- block:数据块,HDFS数据存储按照数据块(block)为单位,Hadoop2.x之后默认大小为128M
- packet:数据包,每次在管道中传输数据需要将数据封装成一个packet,默认为64KB,包含了packet包头、校验chunk和数据chunk
- pipeline:管道或流水线,应客户端请求,namenode提供存储block副本的datanodes,顺序建立数据副本传输管道,形成链式数据流的传输、存储和写入确认(ACK)
2. HDFS客户端数据写入综述
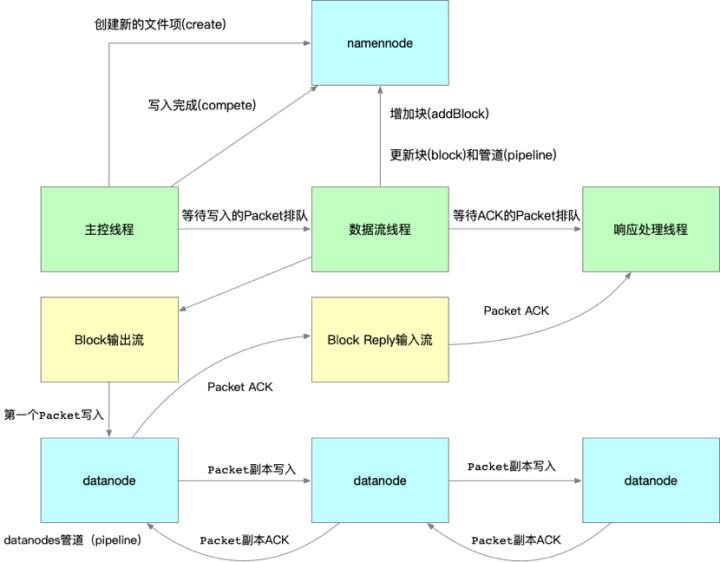
图1. HDFS客户端写入流程概括图
HDFS客户端写入流程架构的综合情况 如图1 所示。我们先通过此图从整体上简化了解,能一窥其全貌。代码实现与细节机制层面的情况要复杂得多,源代码层面的研究我们稍后再说。
首先我们可以看到HDFS客户端写入数据的过程安排给了三个线程去做:主控线程、数据流线程、响应处理线程。主控线程就是启动main入口进行HDFS API调用的主线程,在上一篇文章中,我们主要讲客户端向HDFS读取数据过程:深度探索Hadoop分布式文件系统(HDFS)数据读取流程。这个过程就只是使用到了主控线程:主控线程根据namenode提供好的副本节点,按照文件位移顺序下载block对应的各个副本节点数据,直到HDFS数据文件下载完成。
但是客户端文件向HDFS写入过程又增加了数据流线程和响应处理线程,形成了异步写入协作过程,就具有一定复杂度了,这种架构设计的目的是为了更好的写入性能,同时也兼顾数据写入的可靠性。大家可以想想,若客户端向HDFS传输一段数据还要同步等待网络上所有副本节点的接收完成,虽然这么做可靠性很高,但是客户端写入过程会非常慢,很容易形成客户端的写入堵塞,因为低效率写入是不满足HDFS作为大吞吐数据读写的设计目标,所以通过管道思路,客户端与各个datanode在传输上的异步分工才是更合理的选择。
HDFS实现高性能写入的做法分成了以下几个步骤:
(一)主控线程是第一个环节,由客户端采集数据,并止步于packet的构造和排队。packet进入内存数据队列(LinkedList)中,回头继续下一个packet的封装和排队,很像一个码头装卸工人;packet的包头信息大部分来自从namenode申请到的文件元信息,例如:包头具有一个数据块的最大长度,就能通过packet的包头信息得知是不是到了该数据块(block)的最后一个packet了,就需要重新向namenode申请新的datanode数据块(block)。
(二)数据流线程负责下一个环节,循环取出数据队列里面的packet,通过网络输出流(socketOutputStream)连接管道(pipeline)进行packet传输与写入,然后继续取数据队列下一个packet,以此循环操作,就好像始发的运输船,朝着下一个数据港口起航。
(三)datanodes节点会以管道(pipeline)方式形成packet的副本传输链:前一个副本节点继续向下一个副本节点传输packet与写入,直到所有副本都完成了对block的packet写入。就好像多个数据港口,上一个港口拿到运输船的packet入仓储后,copy一份packet再由此港口发往下一个港口。
(四)响应处理线程负责第三个环节,在上个环节中Packet会排队进ACK队列,响应处理线程循环与block reply输入流建立通信,等待管道(pipeline)中的datanodes依次回传Packet ACK,并取出ACK队列中的Packet序列号与block reply输入流回传的Packet ACK序列号进行比对,若一致,该Packet写入block工作确认完成,移除队列,更新客户端相关参数。就好像运输链的末端港口返航一定给上一个港口带一封完成收货的信件,接着每个港口依次收信,带信返航,直到始发地港口收到下一个港口的返航回信后,才能确认所有港口都收到了packet并存储。
上述从整体上进行了HDFS客户端写入流程综述,通过上面的三个环节的任务分工,保证客户端采集封装、客户端连接管道传输、数据管道链式传输、数据管道ACK链式确认,互相之间不形成制约影响,使传输写入全过程都是在高性能情况下完成。
3. Hadoop源代码分析
接着将会从源代码分析的角度,从更具体的细节上分析和展示
(一) 主控线程对象初始化过程分析
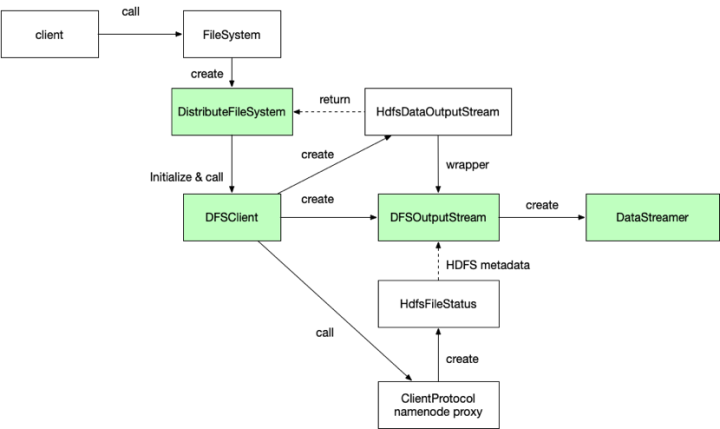
图2 HDFS写入的对象初始化关系图
如 图2 所示HDFS在客户端文件写入准备阶段需要进行的对象初始化。绿色部分是整个写入过程中起到关键作用的对象,实线代表对象间直接调用关系,虚线代表对象间接关系。关于DistributeFileSystem对象、DFSClient对象以及namenode proxy对象初始化过程更具体详细的描述,可以看上一篇读取流程,将不再赘述,本篇重点放在DFSOutputStream对象和DataStreamer对象在写入过程中的关键实现逻辑。
首先我们看看DFSOutputStream被创建的newStreamForCreate方法代码片段:
- static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src,
- FsPermission masked, EnumSet<CreateFlag> flag, boolean createParent,
- short replication, long blockSize, Progressable progress,
- DataChecksum checksum, String[] favoredNodes, String ecPolicyName)
- throws IOException {
- ……
- HdfsFileStatus stat = null;
- ……
- stat = dfsClient.namenode.create(src, masked, dfsClient.clientName,
- new EnumSetWritable<>(flag), createParent, replication,
- blockSize, SUPPORTED_CRYPTO_VERSIONS, ecPolicyName);
- ……
- final DFSOutputStream out;
- if(stat.getErasureCodingPolicy() != null) {
- out = new DFSStripedOutputStream(dfsClient, src, stat,
- flag, progress, checksum, favoredNodes);
- } else {
- out = new DFSOutputStream(dfsClient, src, stat,
- flag, progress, checksum, favoredNodes, true);
- }
- out.start();
- ……
- }

我们来挑拣出代码中重要的部分,一个是namenode proxy调用部分,一个是DFSOutputStream实例创建和启动部分,这里面蕴含的逻辑信息量比较大,需要我们细细解读。
第一段代码部分通过namenode proxy创建了HdfsFileStatus实例,该实例是向namenode服务申请的一个空的文件项,包含了namenode服务为此次写文件而分配的一组元数据,包括:副本数量、块(block)大小、文件ID、存储策略等信息,这些元数据信息为写入数据提供了操作控制和资源约束要求。
下一段代码逻辑是个条件选择,判断到底是创建DFSStripedOutputStream实例,还是创建DFSOutputStream的实例(DFSStripedOutputStream是DFSOutputStream的子类),这取决于元数据中是否启用ErasureCodingPolicy策略,该策略叫Erasure Coding纠删码,简单点理解就是通过一种容错保护技术,让HDFS不用副本翻倍机制来实现数据的容错恢复(默认一份数据三分副本),这样太占用空间了,而是通过校验数据的Encoding and Decoding技术进行数据的容错恢复。但是由于这样过于消耗CPU资源,就需要硬件上的支持,也就是需要Intel提供ISA-L指令集优化加速,因此需要hadoop主机启用Intel ISA-L的本地库。好了多说了一点,该策略不是咱们本篇的重点,因此我们的目标是朝着创建父类DFSOutputStream对象方向去延伸分析,对于支持纠删码策略的DFSStripedOutputStream对象在这里就不深入去细究了。
最后一段是DFSOutputStream实例进行了start启动,在DFSOutputStream实例创建的过程中,另一个关键对象DataStreamer也会被创建,就是数据流线程对象,它包含了一个内隐类ResponseProcessor对象,就是响应处理线程对象,启动DataStreamer线程后,它负责数据管道和数据块的申请和维护,数据块的阶段管理,以及向管道传输数据,启动ResponseProcessor线程后,负责Packet ACK序号的接收确认,堵塞节点(congested datanode)发现,错误节点(bad datanode)发现,数据完成量累计等。所以解析清楚DataStreamer的程序逻辑,就解开了HDFS客户端写入数据的核心复杂过程。
(二) DFSPacket对象构建封装分析
接着我们看看DFSOutputStream对DFSPacket对象的创建、封装过程:
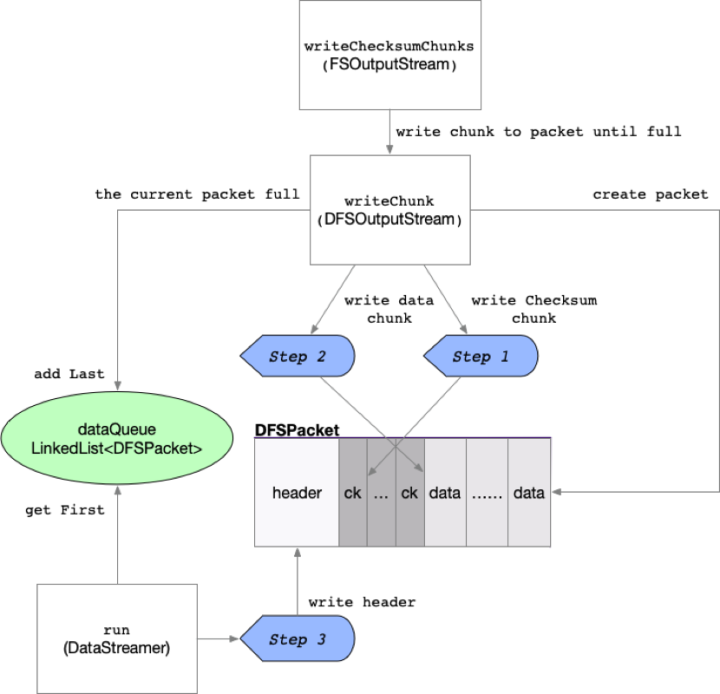
图3 DFSPacket数据包过程构建图
HDFS数据传输的单位是数据包(Packet),代码中为DFSPacket对象。我们根据 图3 所示,看看DFSPacket对象的创建与数据封装过程,我们先贴出来关键部分的代码,然后再做详细的分析和描述,如下是DFSOutputStream的writeChunk方法源代码部分:
- protected synchronized void writeChunk(byte[] b, int offset, int len,
- byte[] checksum, int ckoff, int cklen) throws IOException {
- //准备阶段,创建Packet
- writeChunkPrepare(len, ckoff, cklen);
- //向Packet写入checksum chunk
- currentPacket.writeChecksum(checksum, ckoff, cklen);
- //向Packet写入data chunk
- currentPacket.writeData(b, offset, len);
- currentPacket.incNumChunks();
- getStreamer().incBytesCurBlock(len);
-
- // If packet is full, enqueue it for transmission
- if (currentPacket.getNumChunks() == currentPacket.getMaxChunks() ||
- getStreamer().getBytesCurBlock() == blockSize) {
- enqueueCurrentPacketFull();
- }
- }
客户端调用write的入口在FSOutputStream对象,它是DFSOutputStream的父类,writeChunk是个abstract抽象方法,实际逻辑上它在writeChecksumChunks方法中以循环步进的方式,对子类DFSOutputStream的writeChunk方法进行调用,传入Packet进行chunk数据写入。
每次writeChecksumChunks会根据循环次数(默认9次,全局量BUFFER_NUM_CHUNKS),调用writeChunk,为packet循环生成数据chunk。
DFSOutputStream的writeChunk方法是Packet构建封装的关键部分,首先DFSPacket实例被创建,然后完成 图3 步骤1和步骤2,为Packet填充checksum和data的chunk数据,若一个Packet的chunk写满了,就增加到dataQueue队列。
最后由数据流线程(DataStreamer)取出Packet,完成步骤3,写入Packet header。
写入过程中packet chunk,checksum和data的位移计算公式挺复杂,我就做了简单的程序打印,列出相应公式和参数,并做了注释,以供参考。
- #默认packet的长度64kb
- default packet size = 65536B
- #默认packet header长度
- PacketHeader size = 33B
- #packet的数据体长度 = default packet size - PacketHeader size
- bodySize = 65503B
- #bytePerChecksum为计算校验和的数据,默认512B。
- #checksumSize默认为CRC32的长度4B
- #chunk的长度 = bytePerChecksum + checksumSize = 512+4
- chunkSize = 516B
- #每个packet的chunk数量 = bodySize/chunkSize
- chunksPerPacket = 126个
- #不包括header的packet长度 = chunkSize * chunksPerPacket
- packetSize = 65016
-
- #writeChecksumChunks方法循环第一次,packet内的data偏移量和checksum偏移量
- data offset : 537, data length : 512, checksum offset : 33, checksum length : 4
- data offset : 1049, data length : 512, checksum offset : 37, checksum length : 4
- data offset : 1561, data length : 512, checksum offset : 41, checksum length : 4
- data offset : 2073, data length : 512, checksum offset : 45, checksum length : 4
- data offset : 2585, data length : 512, checksum offset : 49, checksum length : 4
- data offset : 3097, data length : 512, checksum offset : 53, checksum length : 4
- data offset : 3609, data length : 512, checksum offset : 57, checksum length : 4
- data offset : 4121, data length : 512, checksum offset : 61, checksum length : 4
- data offset : 4633, data length : 512, checksum offset : 65, checksum length : 4
另外有个需要注意的多线程等待唤醒机制:主控线程保证dataQueue队列满的情况停止工作等待(wait),队列有空余后再被数据流线程或响应处理线程唤醒(notifyAll)。主线程将继续为队列增加Packet,且看下图:

图4 数据队列多线程控制示意图
如 图4 所示,主控线程发现dataQueue和ackQueue的队列之和大于配置中指定的最大packet数(writeMaxPackets默认是80)了,就调用dataQueue.wait让主控线程停下来,dataQueue也释放锁状态,数据流线程或响应处理线程在run循环处理中,remove掉自己控制的队列Packet后都会调用dataQueue.notifyAll()一次,也就再次唤醒了主控线程,主控线程就继续加锁dataQueue,完成packet排队工作。
(三) 管道(Pipeline)构建过程分析
接下来就到了数据流线程(DataStreamer)的Thread的run()方法核心部分了,run方法写得非常的长,也算是HDFS最复杂的方法之一了吧,我们一样是挑出最关键的内容进行了梳理分析,其中管道(pipeline)的构建过程是个复杂又关键的部分,本小节主要分析这部分机制。
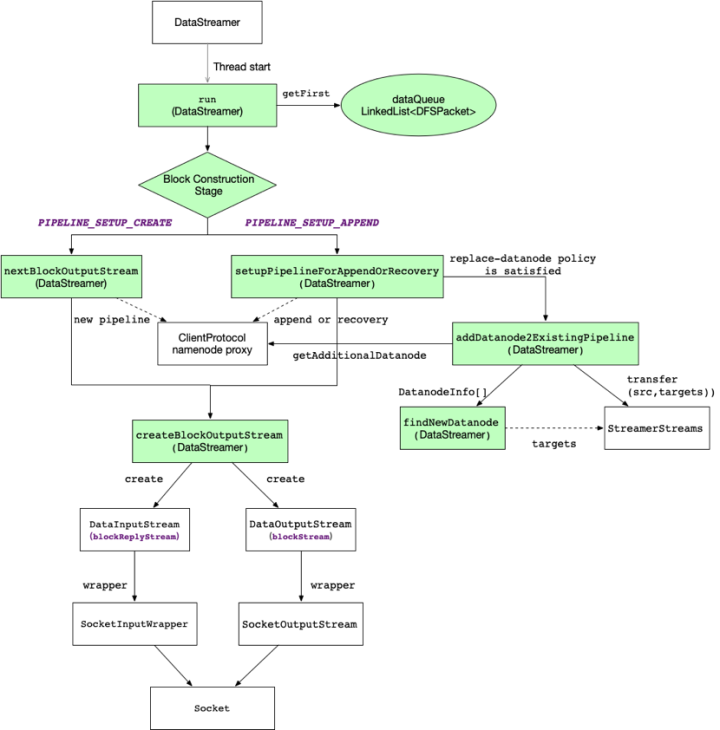
图5 管道(Pipeline)构建过程与对象关系图
如 图5 所示展示了客户端对管道(Pipeline)构建过程的概览,为了做到通过一张图更容易理解,该图实际上是对流程图和对象关系图进行了混合,白色方框为涉及到的对象,绿色方框为run过程中所调用的DataStreams方法。实线代表对象或方法间直接关系,虚线则为间接关系。
管道(Pipeline)的构建关键是BlockConstructionStage对象,该对象是枚举类型,它是标志了写入block的不同阶段,具体阶段情况描述下一小节再说,我们重点要关注的是它的两个阶段PIPELINE_SETUP_CREATE,PIPELINE_SETUP_APPEND。如下是摘录的源代码逻辑部分
- if (stage == BlockConstructionStage.PIPELINE_SETUP_CREATE) {
- LOG.debug("Allocating new block: {}", this);
- setPipeline(nextBlockOutputStream());
- initDataStreaming();
- } else if (stage == BlockConstructionStage.PIPELINE_SETUP_APPEND) {
- LOG.debug("Append to block {}", block);
- setupPipelineForAppendOrRecovery();
- if (streamerClosed) {
- continue;
- }
- initDataStreaming();
- }
PIPELINE_SETUP_CREATE阶段其实比较好理解,第一种情况通常发生在客户端对FileSystem对象的create()方法调用,初始化阶段被设置为PIPELINE_SETUP_CREATE。
另一种情况发生在block的最后一个packet,数据流线程通过调用endBlock方法将阶段从DATA_STREAMING重新设置回PIPELINE_SETUP_CREATE。
数据流线程只要判断为PIPELINE_SETUP_CREATE阶段,就会调用nextBlockOutputStream(DataStream对象)方法,通过nameonode proxy的addblock方法,申请新的block,构建新的管道,分配新的datanodes副本,新产生的Packet将写入新的block。
PIPELINE_SETUP_APPEND阶段会进入到setupPipelineForAppendOrRecovery方法,append的情况比较复杂,将文件追加和数据节点错误恢复情况放到了一个地方解决。
第一种情况发生在客户端对文件追加append(FileSystem对象)方法调用发起,通过namenode proxy,根据HDFS上需要追加的文件,获取到datanode原来的管道,建立数据流连接,继续向文件追加数据。
另一种情况是在数据流连接出现失败的情况,通常是管道中的datanode节点出现错误,客户端会判断是否满足替换datanode替换策略,若满足,要在原有管道的基础上更新管道节点设置,可以在 图5 中看到addDatanode2ExistingPipeline方法调用nameonode proxy的getAdditionalDatanode方法,在原有管道基础上再增加一个新的datanode节点进来,并且通过StreamerStreams对象,挑一个管道中可用的原数据节点,copy副本数据给新的datanode节点,替换掉损坏的datanode节点,实现转移(transfer)。
两种阶段处理过程最终都会通过Socket与管道建立输出流和输入流——(1)创建用于连接管道的blockStream输出流,主要提供给数据流线程写数据使用;(2)创建用于接收管道回复的blockReplyStream输入流,主要提供给响应处理线程的ACK过程使用。
(四) 数据流线程处理过程分析
说完数据流现场处理中上述复杂的管道建立过程,我们再简单分析一下数据流处理过程,看看整个处理过程都经历了哪些阶段。
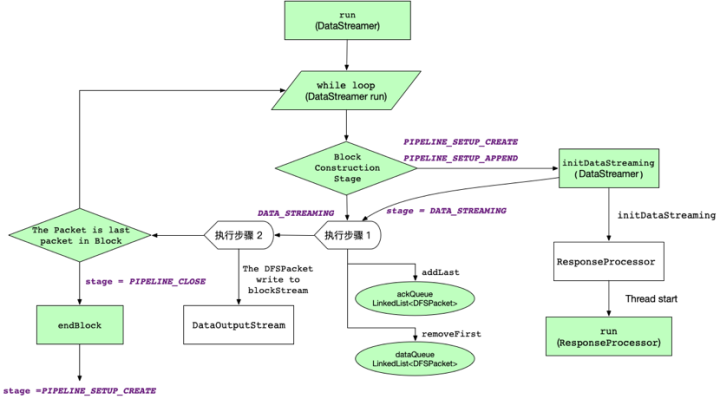
图6 数据流处理过程与对象关系图
如 图6 所示展示了数据流线程处理过程的概览。下面摘录了DataStreamer线程run的一小段代码逻辑部分:
- @Override
- public void run() {
- long lastPacket = Time.monotonicNow();
- TraceScope scope = null;
- while (!streamerClosed && dfsClient.clientRunning) {
- ......
- }
我们可以看到进入数据流线程的run方法后,实际上就进入了packet的不断循环处理的过程,除非数据流处理关闭或客户端不再运行了!
首先无论是PIPELINE_SETUP_CREATE阶段或PIPELINE_SETUP_APPEND阶段,都会通过initDataStreaming方法的调用,创建响应处理线程(ResponseProcessor对象)实例,并启动(start)该线程。并且当前阶段状态进入到了DATA_STREAMING阶段,即数据流传输与ACK确认阶段了。
紧接着数据流线程执行步骤1,取出dataQueue队列中的第一个Packet,准备进行管道传输,并且将此Packet从dataQueue中删除,加入到ackQueue队列中,由响应处理线程ACK确认过程使用。
在执行步骤2中,开始调用blockStream的管道输出流,进行当前packet的管道传输。执行完此步骤后,判断当前packet是否是block的最后一个packet,若是,阶段状态从DATA_STREAMING变成PIPELINE_CLOSE,之后,调用endblock方法后实现一系列对象清理和管道资源释放过程,阶段状态又从PIPELINE_CLOSE重置为PIPELINE_SETUP_CREATE。最终会进入下一个packet处理循环。
需要注意的两个处理操作是没有在此图中列出,
(1)若出现堵塞节点(congestedNodes),利用退避算法(BackOff)的线程,对堵塞节点采取线程等待重试机制,随着重试次数越多,线程休眠时间越长,目标是增强分布式传输的可用性。
(2)dataQueue在一次循环中,若还没有收到新的数据包时,就产生心跳包(heartbeat packet)来保活管道连接。大家若是有兴趣,可以分析一下此处源代码。
(五) 响应处理线程ACK过程分析
最后一部分就是响应处理线程对管道节点Packet ACK确认过程了,我们看一个ACK过程的简单图示,忽略了几处异常处理过程,主要是让我们更直观的看清楚它的过程与步骤
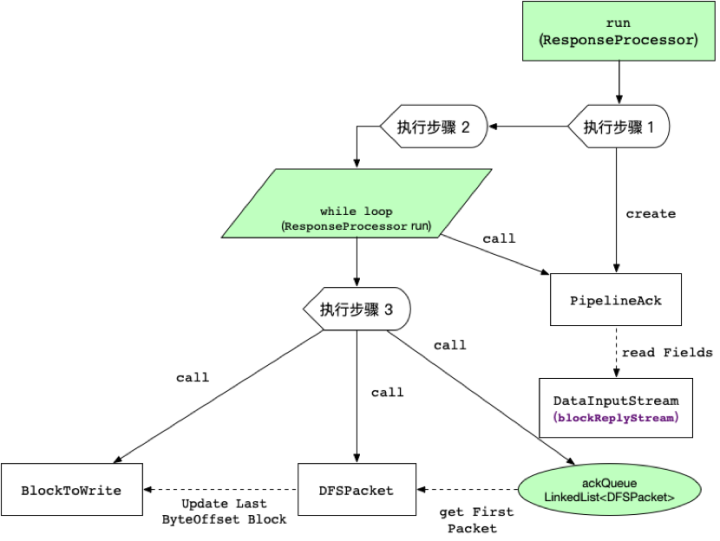
图7 数据流处理过程与对象关系图
如 图7 所示展示了响应处理线程ACK确认过程的概览,参考该图后我们将Packet ACK确认过程按照源代码步骤,顺序列出来进行描述:
(1)获取管道ACK实例(PipelineACK对象)的RPC回应。
(2)根据回应序号排除心跳包(HEART_BEAT_SEQNO = -1L)
(3)根据管道ACK实例发现阻塞节点(congestedNodes),加入阻塞列表,由数据流线程backoff重试等待解决。
(4)根据管道ACK实例发现节点重启状态或错误状态,进行errorstate的badNodeIndex设置
(5)取出ackQueue队列的第一个Packet与回应序号做比对,确认是该Packet已经完成管道datanodes副本的写入,否则发出异常。
(6)比对正常情况下更新Block实例中的实际写入完成的数据量(numBytes)
4. 结束
Hadoop分布式文件系统HDFS的客户端写入过程是Hadoop最复杂的过程之一了,我们通过本文了解到了HDFS写入过程中涉及到客户端的关键对象初始化过程,传输数据包的构建封装过程,传输管道构建过程,数据流处理过程和数据写入后ACK响应过程。通过这些过程的深入分析,让我们能更有信心的去掌握HDFS与客户端的交互过程。

