
- 1Android开发:如果有选择,千万别去外包!_android 外包公司能去吗?
- 2Spring Boot 面试题_spribf boot 面试
- 3云计算-设置 Java 在 Cloud9 中的配置 (Setting-up Java in Cloud9)
- 4【计算思维题】少儿编程 蓝桥杯青少组计算思维真题及详细解析第3套_数学思维题浩浩的左手边是谁
- 5【设计模式深度剖析】【1】【结构型】【代理模式】| 玩游戏打怪、升级为例加深理解
- 6携程面试题库,python爬虫爬取腾讯视频,Python面试题2024答案_python爬取试题
- 7盘点与编程机器人相关的教育部白名单赛事_目前wedo可以参赛的的机器人比赛有哪些
- 8SpringBoot整合Kafka报错:org.apache.kafka.common.errors.TimeoutException: Timeout expired while fetching_timeout expired whilefetch
- 9成为一名合格的自动化测试工程师所要知道的学习步骤及学习误区_测试工程师学习步骤先学什么在学习什么
- 10iOS踩坑App Store Connect Operation Error_sdk version issue. this app was built with the ios
RabbitMQ,RocketMQ,Kafka 消息模型对比分析_rocket mq、rabbit mq和kafka分别是通过什么形式获取消息?
赞
踩
消息模型
消息队列的演进
消息队列模型
早期的消息队列是按照”队列”的数据结构来设计的。
生产者(Producer)产生消息,进行入队操作,消费者(Consumer)接收消息,就是出队操作,存在于服务端的消息容器就称为消息队列。

当然消费者也可能不止一个,存在的多个消费者是竞争的关系,消息被其中的一个消费者消费了,其它的消费者就拿不到消息了。
发布订阅模型
如果一个人消息想要同时被多个消费者消费,那么上面的队列模式就不适用了,于是又引出了一种新的模式,发布订阅模型。
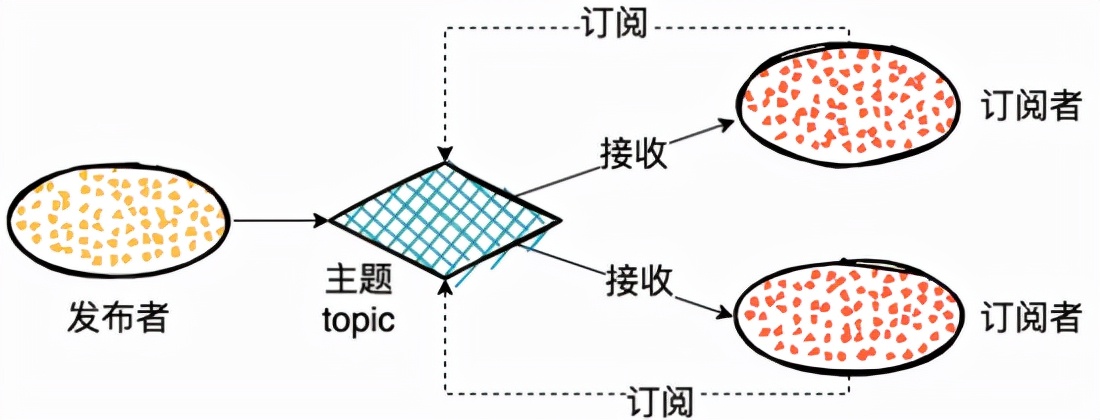
在发布-订阅模型中,消息的发送方称为发布者(Publisher),消息的接收方称为订阅者(Subscriber),服务端存放消息的容器称为主题(Topic)。
发布者发送消息到主题中,然后订阅者需要先订阅主题。订阅主题的订阅者之后就可以收到发送者发送的消息了。
发布订阅也是兼容消息队列模型的,如果只有一个订阅者,就是消息队列模型了。
RabbitMQ的消息模型
RabbitMQ 使用的还是消息队列这种消息模型,不过它引入了一个 exchange 的概念。
exchange 也就是交换器,位于生产者和队列之间,生产者产生的数据是直接发送到 exchange 中,然后 exchange 根据配置的策略将消息发送到对应的队列中。
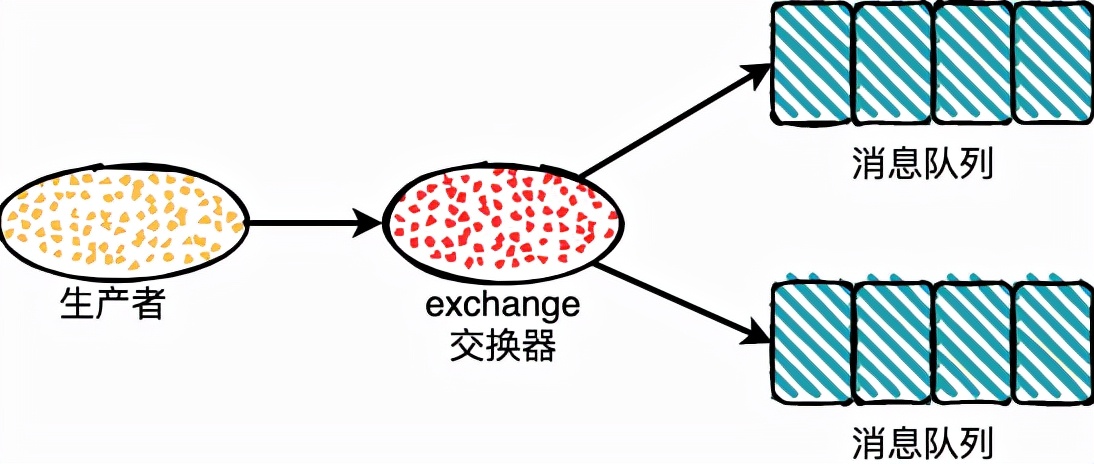
RabbitMQ 中通过绑定将交换器和队列关联起来,绑定的时候一般会指定一个绑定键(BindingKey)。
生产者发送消息的时候会指定一个 RoutingKey ,当 RoutingKey 和 BindingKey,一样的时候就会被发送的对应的队列中去。
交换器的类型
RabbitMQ 中肠道常用的交换器有 fanout、direct、topic、headers 四种,这里来一一分析下
direct
direct 根据发送消息的 RoutingKey ,然后发送到和 RoutingKey 匹配的 BindingKey 对应的队列中去。
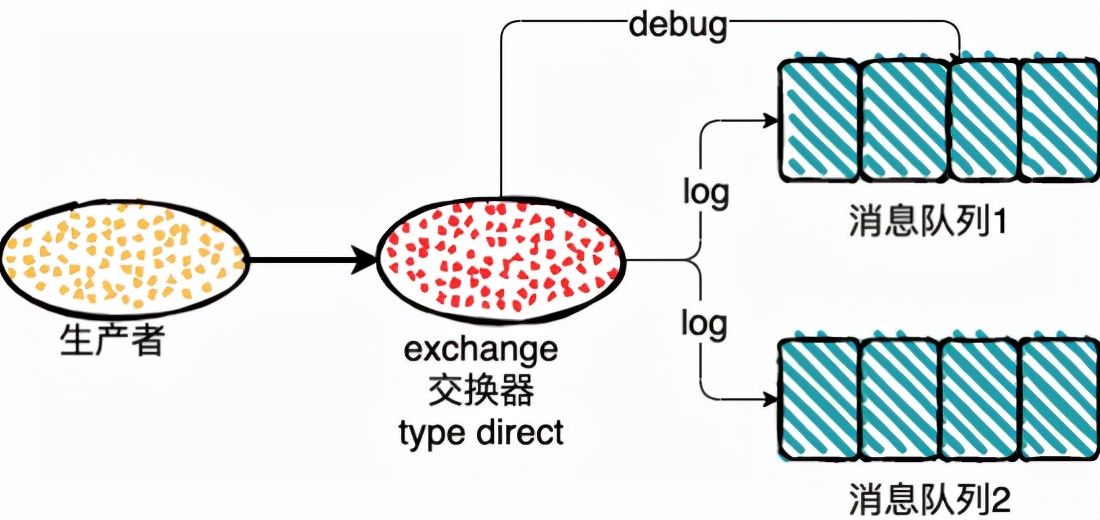
如果发送消息的路由键也就是 RoutingKey,为 log 的时候,两个消息队列都会收到消息,如果路由键为 debug ,exchange 只会把消息发送到消息队列1中。
topic
direct 中的 RoutingKey 和 BindingKey 是完全匹配才能发送消息的,topic 中在此基础之上做了扩展,也就是引入了模糊匹配机制。
- RoutingKey 和 BindingKey 中使用 . ,来分割字符串,被 . 分割开的每一段字符串就是一个匹配字符;
- BindingKey 中主要通过 * 和 # ,用于模糊匹配,* 表示一个单词,# 代表任意0个或多个单词;
- BindingKey 中单独使用 # 时,会接收所有的消息,这与类型 fanout一致;
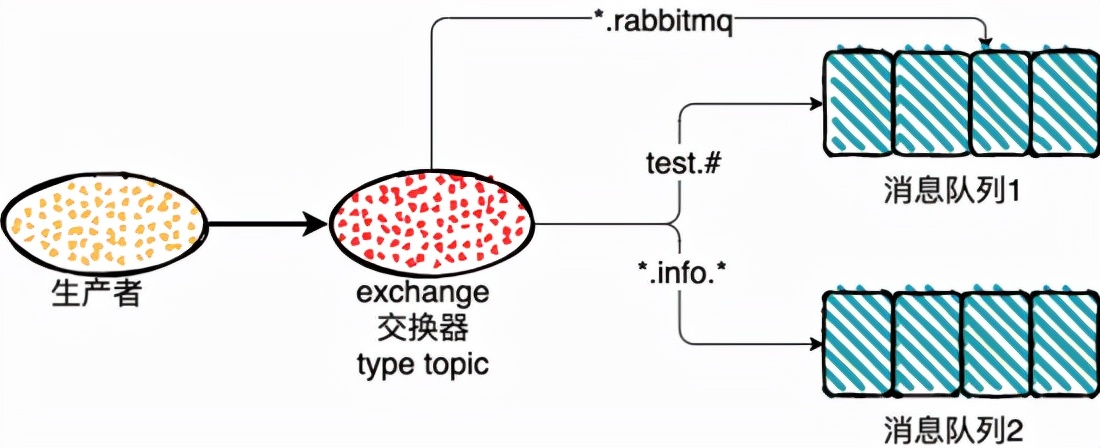
栗子:
1、路由键为 test.rabbitmq 消息队列1和消息队列2都会收到消息;
2、路由键为 rabbitmq 没有人能收到消息;
3、路由键为 test 消息队列2会收到消息;
4、路由键为 rr.info.ww 消息队列2会收到消息;
5、路由键为 info 没有队列能收到消息;
fanout
该交换器收到的信息会被发送到所有与该交换器绑定的队列中。
headers
headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中 headers 属性进行匹配。在绑定队列和交换器时制定一组键值对当发送消息到交换器时,RabbitMQ 获取到该消息的人 headers (也是一个键值对的形式) ,对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列 headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
Kafka的消息模型
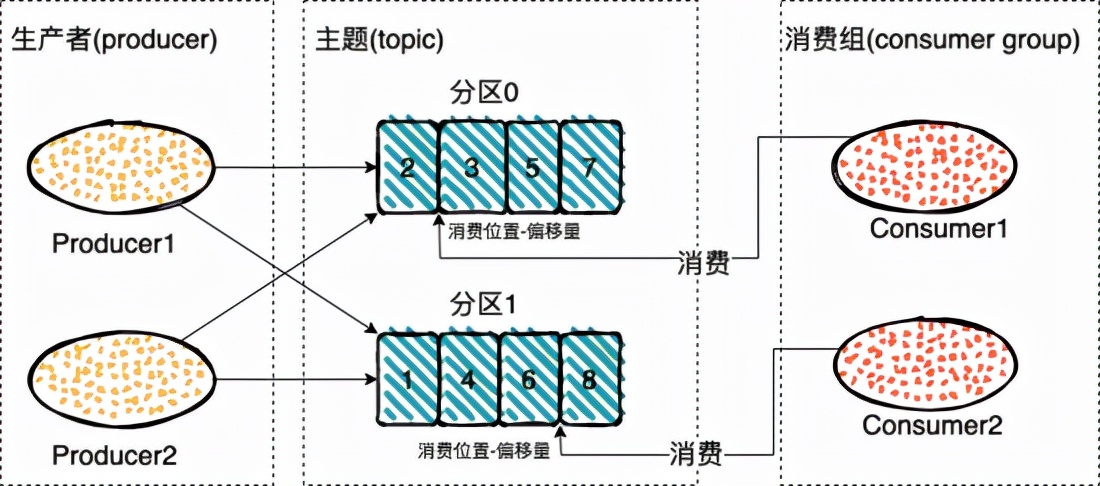
Kafaka 中引入了一个 broker。broker 接收生产者的信息,为消息设置偏移量,并且保存的磁盘中。broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
同时 broker 也会对生产者和消费者进行消息的确认。
生产者发送消息到 broker,如果没有收到 broker 的确认就可以选择继续发送;
消费者同理,在消费端,消费者在收到消息并完成自己的消费业务逻辑(比如,将数据保存到数据库中)后,也会给服务端发送消费成功的确认,broker 只有收到消费确认后,才认为一条消息被成功消费,否则它会给消费者重新发送这条消息,直到收到对应的消费成功确认。
如果一个主题中,每次只有一个消费实例在处理,同时我们也要保持消息的有序性,当前消息没有被消费掉就不能接着消费下一个消息。那么,消费的性能将是极低的,这时候引入了一个分区的概念。
主题可以被分为若干个分区,一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。要注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
同时引入了消费者组,消费者是消费者组中的一部分,这样会有一个或者多个消费者读一个分支,不过群组会保证一个分区只能被一个消费者消费,通过多消费者,这样消费的性能就提高了。
每个消费组都消费主题中一份完整的消息,不同消费组之间消费进度彼此不受影响,也就是说,一条消息被 Consumer Group1 消费过,也会再给 Consumer Group2 消费。不过同组内是竞争关系,同组内一个消息只能被同组内的一个消息消费。
消费者通过偏移量来确认读过的数据,他是个不断累加的数据,每次成功消费一个数据这个偏移量就加一。在给定的分区中,每个消息的偏移量都是唯一的。消费者会把每个分区读取的消息偏移量保存在 Zookeeper 或 Kafka 上,如果消费者关闭或重启,它的读取状态不会丢失。
RocketMQ的消息模型
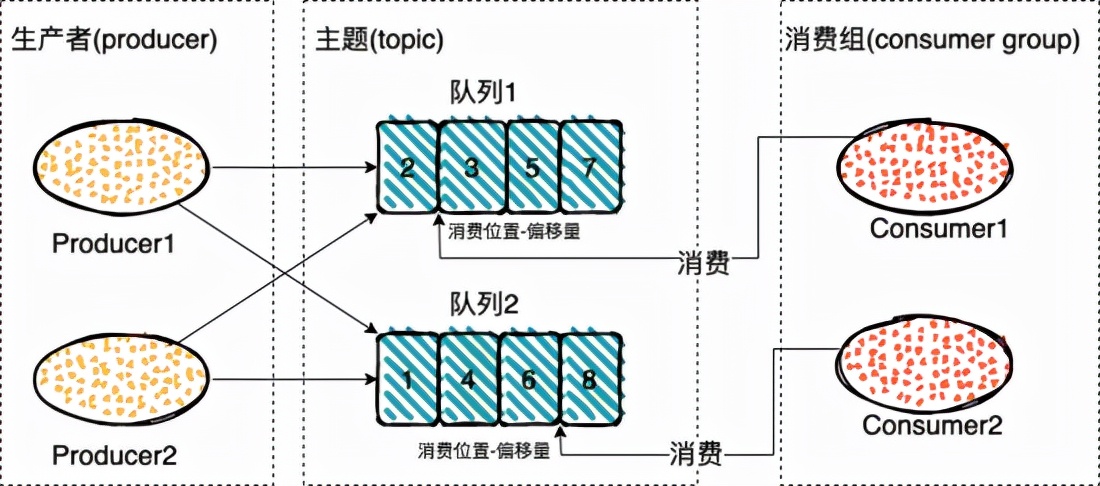
RocketMQ 中的消息模型和 Kafaka 类似,把 Kafaka 中间的分区换成队列,就是 RocketMQ 的消息模型了。
不过虽然消息模型类似,但是实现方式还是有很大的差别的。

