
- 1[图解]SysML和EA建模住宅安全系统-04_sysml案例 ea
- 2idea 换maven项目jdk版本_idea maven 更换项目的jdk
- 3fpga快速入门书籍推荐_fpga入门书推进
- 4实验 5 Spark SQL 编程初级实践
- 5Git忽略已经上传的文件和文件夹_git 忽略文件以及忽略已上传文件
- 6解决哈希碰撞:选择合适的方法优化哈希表性能
- 7idea java 插件开发_IDEA插件开发之环境搭建过程图文详解
- 8《五》Word文件编辑软件调试及测试
- 9ubuntu下faster-whisper安装、基于faster-whisper的语音识别示例、同步生成srt字幕文件_装faster whisper需要卸载whisper吗
- 10大疆 植保无人机T60 评测_大疆t60无人机参数
OceanBase V4.3 发布—— 迈向实时分析 AP 的重要里程_oceanbase版本差异
赞
踩
OceanBase在2023年初,发布了4.x架构的第一个重要版本,V4.1。该版本采用了单机分布式一体化架构,并在该架构的基础上,将代表数据库可靠性的RTO降低至 8 秒以内,从而确保在意外故障发生后,系统能够在极短时间内恢复运行。此外,4.1版本还突破了3.x版本中,在分区数上限的瓶颈,大幅提升了大事务的处理能力;同时,新增的仲裁副本等核心特性也有效地降低了成本。
同年 9 月,OceanBase 发布了 4.x 系列首个长期支持版本(LTS),4.2.1 LTS 全面补齐 3.x 主要能力,并在稳定性、扩展性、小规格、诊断易用性等多方面全面提升,发布半年后,已有数百家客户将 LTS 版本应用于生产业务稳定运行。
为了满足用户对易用性和多样化负载的业务需求,经过深入地研讨、开放地设计、严谨地实现,我们推出面向实时分析 AP 业务的里程碑版本,OceanBase 4.3!
4.3 版本是 OceanBase 迈向实时分析 AP 场景的重要里程。该版本基于 LSM-Tree 架构推出列存引擎,实现行存、列存数据存储一体化,同时推出基于 Column 数据格式描述的新版向量化引擎和基于列存的代价模型,支持高效处理大宽表,显著提升 AP 场景查询性能,并兼顾 TP 业务场景,适用于复杂分析、实时报表、实时数仓或联机交易等混合负载场景。该版本新增物化视图功能,通过预计算存储视图的查询结果提升实时查询性能,支撑快速报表生成和数据分析场景。新版本内核也扩展了 Online DDL、支持了租户克隆等功能,优化性能和资源使用,提升了系统易用性。经测试,OceanBase 4.3 在同等硬件环境下,在大宽表场景下的查询性能达到了业内主流列存大宽表数据库的水平。
接下来,我们将详细介绍 4.3 的主要特性:
○ TP & AP一体化产品形态
○ 全面增强的内核特性
○ 显著增强的计算性能
○ 持续提升的易用性
一、TP & AP一体化的产品形态
OceanBase 4.3 在 4.2 版本的基础上进一步扩展了 AP 产品形态,保持了行级数据的高并发实时更新、主键索引点查的支持,同时具备分布式架构下可扩展、高可用、强一致、异地容灾的能力。新增支持列式存储引擎,增强向量化执行、并行计算和分布式计划优化等能力,使得一个产品同时支撑 TP & AP 两种业务。
(一)行存 & 列存一体化
在大规模数据复杂分析或海量数据即席查询场景中,列式存储是 AP 数据库的关键能力之一。列式存储是一种数据文件组织方式,区别于行式存储,它将表中的数据按照列进行物理排列。数据进行列式存储时,分析场景可仅扫描用于查询计算的列数据,避免整行扫描,减少 IO 和内存等资源使用,提升计算速度。此外,列式存储天然具备更好的数据压缩条件,能够获得较高的压缩比,减少存储空间和网络传输带宽。
常见的列存存储引擎在实现上往往假设不会有大量随机更新, 尽量保证列存组织数据是静态的。当真正伴随大量数据随机更新时,也会不可避免的存在系统性能问题。OceanBase LSM-Tree 架构可以将基线数据和增量数据分别处理,正好可以解决这一场景问题。因此 4.3 版本在当前架构基础上继续扩展支持了列存引擎,在一套代码一个架构一个 OBServer 上,实现了列存和行存数据存储一体化,兼顾 TP 和 AP 类查询性能。
为了让有分析诉求的用户顺畅使用新版本,围绕列存引擎,从优化器到执行器、从 DDL 到事务处理等多模块都进行了适配优化。包括基于列存的新的代价模型和向量化引擎,查询下压功能的扩展和增强,Skip Index,新的列式编码算法,自适应 Compaction 等。
在 OceanBase 的 MySQL 兼容模式或 Oracle 兼容模式的租户下执行下面的命令,可以默认建立列存表,是分析场景建议的使用方式:
alter system set default_table_store_format = "column"业务上,用户也可根据负载类型灵活设置表为行存表、列存表或行列冗余表,也支持为行存表指定列存索引,从而满足不同业务场景下的需求。
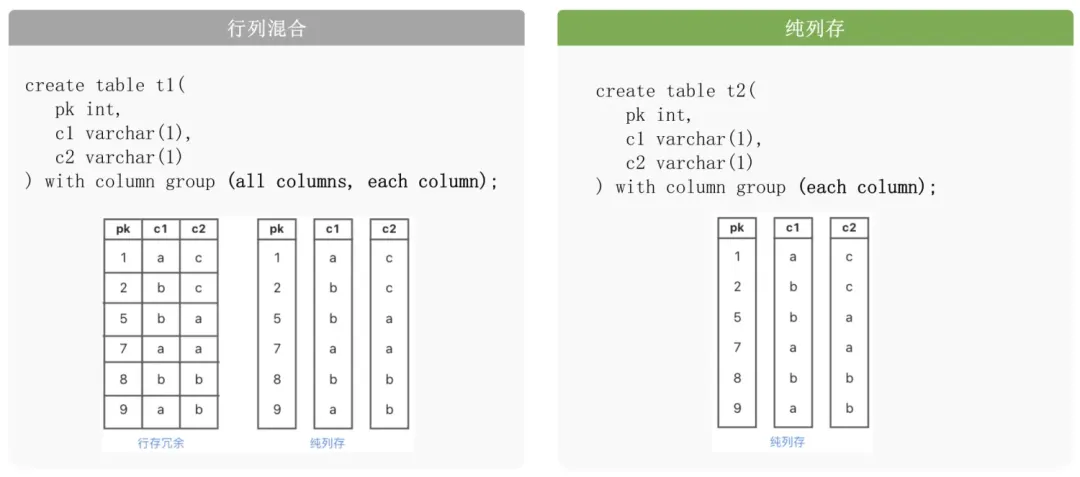

同时,优化器会根据代价计算进行决策使用行存还是列存。

(二)新向量化引擎
OceanBase 在早期版本已经实现了基于 Uniform 数据描述方式的向量化引擎,性能较非向量化引擎有了明显提升,但在深度 AP 场景,还有一些性能上的不足。4.3.0 版本实现了向量化引擎 2.0 版本,更改为 Column 数据格式描述,避免了 ObDatum 维护带来的内存使用、序列化和读写访问开销。基于数据格式描述重构,新版本也对一批常用算子和表达式进行了重新实现,如 HashJoin、AGGR、HashGroupBy、Exchange(DTL Shuffle)等 10 余项算子,关系运算、逻辑运算、算数运算等 20 余项 MySQL 表达式。在后续的 4.3.x 版本也会基于新的向量化引擎,持续补充完善其他算子和表达式的实现,以便获得更优性能。
(三)物化视图
4.3.0 版本新增物化视图(Materialized View)功能。物化视图是支撑 AP 业务的一个关键特性,它通过预计算和存储视图的查询结果,减少实时计算来提升查询性能,简化复杂查询逻辑,常用于快速报表生成和数据分析场景。
因为物化视图需要存储查询结果集来优化查询性能,而物化视图与基础表之间存在数据依赖关系,每当基础表数据发生变动时,物化视图中的数据必须进行相应更新以保持同步,所以新版本也引入了物化视图刷新机制,包括全量刷新和增量刷新两种策略。全量刷新是一种较为直接的方式,每次执行刷新操作时,系统会重新执行物化视图对应的查询语句,完整地计算并覆盖原有的视图结果数据,这种方式适用于数据量相对较小的场景。相对来讲,增量刷新仅需处理自上次刷新以来发生变更的部分。为了实现精确的增量刷新,OceanBase 实现了类似 Oracle MLOG(Materialized View Log)的物化视图日志功能,通过日志详细跟踪记录基础表的增量更新数据,从而确保物化视图能够进行快速增量刷新。增量刷新方式尤其适用于数据量庞大且变更频繁的业务场景。
二、全面增强的内核特性
新版本内核强化了代价模型,扩展了 Online DDL,支持了租户克隆等特性,并重构会话管理模块,优化日志流状态机,增加 S3 备份恢复介质支持,优化系统资源使用,提升数据库在关键业务负载中的性能和稳定性。
(一)估行系统增强
随着 OceanBase 版本的不断演进,优化器代价估计的方式也越来越丰富。涉及到每个算子估行,目前已经支持了存储层估行、统计信息估行、动态采样、默认统计信息等算法,使用上缺少清晰的策略和完善的控制手段。4.3.0 版本重构估行系统,根据不同场景,指定不同的估行策略优先顺序,并提供 HINT、系统变量等手工干预估行策略选择的方式。同时新版本对谓词选择率和 NDV 计算框架也做了进一步增强,以此提高优化器代价估计的准确性。
(二)统计信息增强
4.3.0 版本进一步完善了统计信息功能、改善了统计信息收集性能、提升了统计信息兼容性和易用性。主要包括重构离线统计信息收集流程,提升统计信息收集效率;优化统计信息收集策略,默认自动收集索引直方图,使用推导统计信息收集方式;保证在线统计信息收集的事务一致性;兼容 Oracle DBMS_STATS.COPY_TABLE_STATS 功能,用于统计信息拷贝场景;兼容 MySQL ANALYZE TABLE 功能,提供更丰富的语法支持;新增取消统计信息收集的命令,丰富统计信息收集进度监控,增强运维易用性;提供统计信息并行删除能力等。
(三)自适应代价模型
OceanBase 历史版本代价模型是使用内部机器测算的常量参数来代表硬件系统统计信息,通过一系列公式与常量参数来描述每个算子的执行开销。而真实的业务场景中,不同硬件环境可能具备不同的 CPU 时钟频率、不同的顺序读或随机读的速度、不同的网卡带宽等,可能存在代价估算偏差,这些偏差会使得优化器无法在不同的业务环境总是生成最优计划。新版本优化代价模型实现,支持通过 DBMS_STATS 包来收集或设置系统统计信息系数,以达到代价模型自适应硬件的目的。同时也提供了 DBA_OB_AUX_STATISTICS 视图,用于展示当前租户的系统统计信息系数。
(四)函数索引 SESSION 变量固化
创建函数索引时,会向主表添加一个隐藏的虚拟生成列,定义为函数索引的索引键,然后再将虚拟生成列的值存储到索引表中。一些内置系统函数的结果会受到 SESSION 变量的影响,不同 SESSION 变量取值,即使函数入参相同,计算结果也是不同的。为提高生成列/函数索引的稳定性,新版本在创建函数索引和生成列时,会将依赖的 SESSION 变量固化至索引列和生成列的 column schema 中。后续计算索引列和生成列的取值时,使用固化值,不受当前 SESSION 下变量取值的影响。4.3.0 版本支持固化的系统变量包含 timezone_info、nls_format、nls_collation、sql_mode 等。
(五)MySQL 模式下 Online DDL 扩充
4.3.0 版本对列类型变更一类的 DDL 拓展了更多 Online 场景,包括:
○ 整型转换:对于主键列/索引列/生成列/被生成列依赖的列/有 Unique 或 Check 约束的列,列类型修改为取值范围更大的整型的场景,从 Offline DDL 变更为 Online DDL。
○ Decimal 类型转化:对于支持使用 Decimal 数据类型的列,Precision 在以下某个区间([1,9]、[10,18]、[19,38]、[39,76])内增长,且 Scale 不变的场景,全部为 Online DDL。
○ Bit 或 Char 类型转换:对于支持使用 Bit 或 Char 数据类型的列,宽度增长均为 Online DDL。
○ Varchar 或 Varbinary 类型转换:对于支持使用 Varchar 或 Varbinary 数据类型的列,宽度增长均为 Online DDL。
○ Lob 类型转换:对于支持使用 Lob 数据类型的列,除了 Tinytext 和 Tinyblob 向上增长是 Offline DDL 流程,其他类型修改为取值范围更大的 Lob 类型时,均为 Online DDL 流程。
○ Tinytext 与 Varchar 类型转换:对于支持使用 Tinytext 数据类型的列,在 Varchar(x) 转换为 Tinytext 类型时,如果 x <= 255,为 Online DDL,否则为 Offline DDL;对于支持使用 Varchar 数据类型的列,在 Tinytext 转换为 Varchar(x) 类型时,如果 x >= 255,为 Online DDL,否则为 Offline DDL。
○ Tinyblob 与 Varbinary 类型转换:对于支持使用 Tinyblob 数据类型的列,在 Varbinary(x) 转换为 Tinyblob 类型时,如果 x <= 255,为 Online DDL,否则为 Offline DDL;对于支持使用 Varbinary 数据类型的列,在 Tinyblob 转换为 Varbinary(x) 类型时,如果 x >= 255,为 Online DDL,否则为 Offline DDL。
(六)全局唯一 Client Session ID
在 OBServer 4.3.0 版本和 ODP V4.2.3 版本之前,Client 端通过 ODP 执行 show processlist 时,查询到的是 ODP 本机上的 Client 端会话 ID,通过 connection_id 等表达式或系统视图查询到的为 Server 端会话 ID。Client 端会话 ID 和 Server 端会话 ID 存在一对多的关系,难以在全链路统一,Session 信息查看容易混淆,不方便进行用户会话管理。新版本重构 Client Session ID 生成和维护流程,在 OBServer 版本不低于 4.3.0 且 ODP 版本不低于 V4.2.3 时,通过各种渠道如 show processlist 命令、information_schema.PROCESSLIST 或 GV$OB_PROCESSLIST 等视图、connection_id、userenv('sid')/userenv('sessionid')、sys_context('userenv','sid')/sys_context('userenv','sessionid') 等表达式,查询到的会话 ID 均为 Client 端会话 ID,用户可通过指定 SQL 或 PL 中的 kill 命令来管理用户端会话。OBServer 或 ODP 版本不满足要求时,将退化为老版本的处理方式。
(七)日志流状态机改造
新版本将日志流的状态拆分成了内存和持久化状态。持久化状态用于表示日志流的生命周期,宕机重启以后会根据持久化状态决定日志流是否应该存在,以及内存状态应该是什么。内存状态是日志流运行时状态,用于表示日志流整体状态和关键子模块状态。根据日志流明确的状态和状态 sequence,底层模块可判断日志流哪些操作是安全的,是否发生过 ABA 类型的状态变更。对于备份恢复或迁移流程,在日志流宕机重启后,也优化了工作状态表现。该特性提升了日志流相关功能的稳定性,强化了日志流并发控制能力。
(八)租户克隆
4.3.0 版本新增租户克隆特性,用户可在 SYS 租户下对指定租户快速克隆出一个新租户。租户克隆任务执行完成后,新克隆租户为备租户,用户也可将其转为主租户提供服务。新克隆租户和原始租户在初始状态下共享物理宏块,但新的数据变动和资源使用会按租户进行隔离。当用户需要对在线租户进行高资源消耗的临时数据分析或其他高风险操作时,为了避免对在线租户造成影响,可使用克隆租户完成分析或验证。同时也可将克隆租户作为容灾手段,若原始租户发生了难以恢复的误操作,可使用克隆租户进行数据回滚。
(九)备份恢复支持 S3
OceanBase 的备份恢复功能已经支持两类存储介质:文件存储(NFS)和对象存储(OSS/COS)。新版本备份恢复扩展支持了 S3 及兼容 S3 协议的对象存储(如 OBS、GCS)作为备份介质,可以将 S3 及兼容 S3 协议的对象存储作为日志归档和数据备份的目的端,也可以使用 S3 及兼容 S3 协议的对象存储上的备份数据执行物理恢复。
(十)Tablet Location 主动广播/刷新
OceanBase 早期版本已具备 Location Cache 周期性刷新机制,确保日志流 Location 信息更新的实时性和最终一致性。但 Tablet Location 只具备被动刷新能力,在 Tablet 和日志流的映射关系发生变化时,有概率触发 SQL 重试和读写报错。4.3.0 版本增加 Tablet Location 主动广播能力,减少 Transfer 后映射关系变化导致的 SQL 重试和读写报错;并提供主动刷新能力兜底,避免不可恢复的读写报错问题。
(十一)Transfer 搬迁活跃事务
单机日志流设计中, 数据的单位是分片(tablet),日志的单位是日志流(logstream), 多个分片聚合在一个日志流上使得单个日志流内部的事务避免了两阶段提交的高额代价。为了可以均衡不同日志流间的数据与流量, 我们需要允许分片在不同日志流间可以灵活地迁移(即 Transfer)。然而在 Transfer 过程中, 活跃事务依旧可能在数据上活动, 简单的操作会破坏事务的 ACID 能力。举例来说, Transfer 源端的活跃事务数据若无法在并发过程中完整地迁移到目的端, 事务的原子性就无法保证。在该版本之前,Transfer 执行过程中会主动杀掉活跃事务来避免产生事务问题,一定程度影响了事务的正常执行。为了优化这一问题,新版本支持了 Transfer 搬迁活跃事务的能力, 允许活跃事务并发执行, 并保证并发事务不会因为 Transfer 导致异常回滚或产生一致性问题。
(十二)内存限速机制
在 4.x 版本之前,需要依赖冻结转储释放内存的模块并不多,Memtable 是其中最大的一部分。因此,之前版本对 Memtable 本身设定了内存使用上限,并通过限速逻辑使其在内存使用量接近上限的过程中运行尽可能平滑,避免突然耗尽内存导致系统停写。4.x 版本之后,随着更多依赖冻结转储释放内存的模块(如事务数据模块)被引入,新版本提供了更细致的手段来控制多个模块的内存使用,新增 TxData 和 MDS 模块内存上限控制,和 Memtable 共享内存空间,当累积内存达到 “租户内存 * _tx_share_memory_limit_percentage% * writing_throttling_trigger_percentage% ”时,触发整体限速。同时,新版本也增加了时间维度触发事务数据表冻结转储的功能,默认 1800 秒触发一次事务数据表的冻结,降低事务数据模块的内存占用。
(十三)DDL 临时结果空间优化
在 DDL 过程中,会有很多把临时结果暂存物化结构中的流程。典型的例子有以下两个:1) 创建索引从数据表扫数据插入到索引表的时候,会需要对数据表扫出来的数据进行排序。排序的过程中如果内存不足,就会把当前内存中的数据暂存到物化结构中,释放内存空间以供后续的扫描,最后对这些物化结构中的数据进行归并排序。2) 列存旁路导入时,会先把需要插入每个 column group 的数据暂存在物化结构中,后续对每个 column group 进行插入的时候,都从物化结构中取数据。这些暂存数据的物化结构在 sort 算子中可以用来存储外部排序需要用到的中间数据,在插入 column group 的时候可以缓存数据从而避免重复扫表导致的额外开销。但是现有的 DDL 过程存在临时文件使用磁盘空间放大的问题,新版本针对性地梳理和去除了数据流中的冗余结构,并支持了临时结果落盘的编码压缩,有效降低 DDL 临时结果占用的磁盘空间。
三、显著提升的计算性能
新版本 OLAP 计算能力全面增强,TPC-H 1T、TPC-DS 1T 均有明显性能提升。同时新版本也优化了 PDML、OBKV 读写、LOB 类型旁路导入性能,提升了节点重启效率。
(一)TPC-H 1T 查询提升 25%
在 80C 500GB 租户规格下,各版本 TPC-H 1T 性能对比如下:4.3.0 版本相对 4.2.0 版本总体提升 25% 左右。
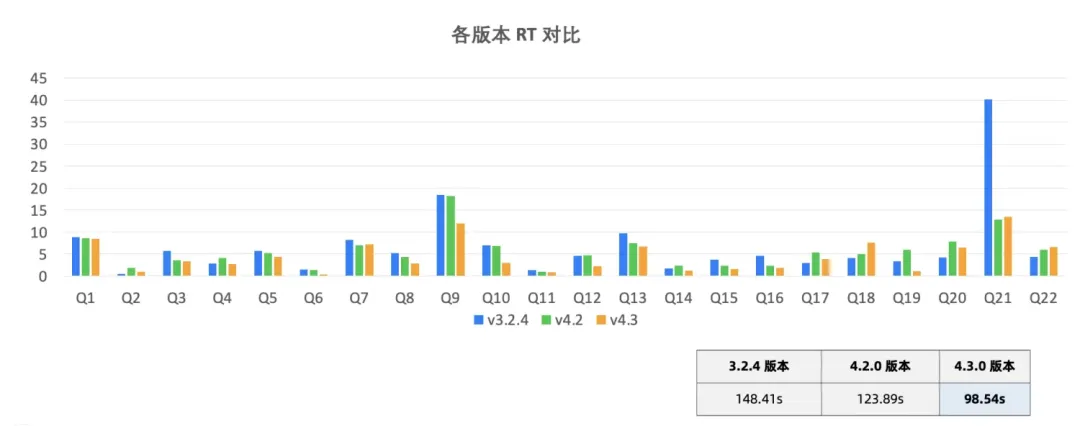
图1:TPC-H 1T 性能对比(4.3.0 vs. 4.2.0)
(二)TPC-DS 1T 查询提升 111%
在 80C 500GB 租户规格下,各版本 TPC-DS 1T 性能对比如下:4.3.0 版本相对 4.2.0 版本总体提升 111% 左右。
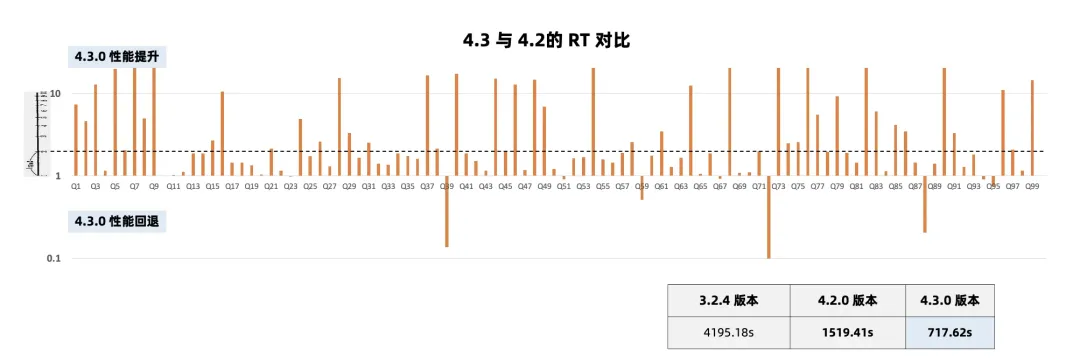
图2:TPC-DS 1T 性能对比(4.3.0 vs. 4.2.0)
(三)OBKV 性能优化
相对 4.2.1 版本,OBKV 单行读写性能提升约 70%,批量读写性能提升 80% - 220%。
(四)PDML 事务优化
新版本在事务层通过支持并行提交和回放日志、增加事务参与者内部分区级别回滚等实现优化,相对 4.x 早期版本,明显提升高并发场景下 PDML 执行性能和 PDML 并行执行的扩展性。
(五)Tablet 元数据加载 IO 使用优化
OceanBase 4.x 版本支持了单机百万分区,因百万 Tablet 元数据可能无法全部放入内存之中,又支持了元数据按需加载。按需加载包括分区和分区内部子类两种级别,分区内部会拆成多种不同子类的元数据分层存储,在后台任务需要较深层次元数据的场景下,读取需要耗费较多的 IO。在本地 SSD 磁盘上,这些 IO 开销不是问题,但在机械磁盘和云盘的场景,可能影响系统性能。新版本针对需要频繁访问的元数据做了聚合存储,这类元数据访问降低为只需要 1 次 IO,大大减小空载情况下 IO 开销,不会因后台任务的 IO 开销影响到前台查询性能。同时也优化了 OBServer 重启时元数据加载流程,修改为按宏块粒度批量加载 Tablet 元数据,大大减少离散读 IO,数倍至数十倍提升重启速度。
四、持续提高的产品易用性
新版本支持了索引使用监控功能用于简单识别和删除无效索引,支持了客户端本地导入功能用于丰富小批量数据的导入方式。同时提供了 Lob INROW 的阈值配置、RPC 认证证书管理、配置项重置等功能提升系统易用性。
(一)索引使用监控
我们对数据库执行查询操作时,往往通过创建索引来优化查询性能。但随着数据表使用的时间增长,业务场景和操作人员不断增加,很可能会存在索引越建越多的问题。未使用的索引会浪费存储空间,也会加重 DML 操作的开销。对于这种情况,需要持续观察,删除无用的索引来给系统减负。但是仅靠人力很难识别哪些索引是无用索引,因此 OceanBase 在 4.3.0 版本新增索引使用监控功能,用户可选择打开该功能并设置采样方式,在普通租户下会将符合规则的索引使用信息记录到内存,并以 15 分钟为周期刷新到内部表中,可通过 DBA_INDEX_USAGE 视图访问,以此来感知表上的索引是否有被引用,进而选择删除无用的索引表来释放空间。
(二)客户端本地导入
4.3.0 版本新增客户端本地导入(LOAD DATA LOCAL INFILE)功能,通过流式文件处理方式完成本地文件导入,丰富了原有的数据文件导入方式。基于该功能,开发人员无需上传文件至服务器或对象存储也可进行本地文件导入测试,提高少量数据导入的工作效率。
注意:如果需要使用客户端本地导入功能,需要保证:
a. OBClient 版本不低于 2.2.4;
b. ODP 版本不低于 3.2.4(直连 OBServer 无此要求);
c. OBJDBC 版本不低于 2.4.8 (如果使用Java + OBJDBC);
另外,可以直接使用 MySQL 或 MariaDB 原生客户端,对版本没有特殊要求。
关于 SECURE_FILE_PRIV 变量,是用来控制 OBServer 访问服务端机器路径的权限,对客户端本地导入功能无影响,不需要做设置。
(三)LOB INROW 阈值配置
当前 LOB 数据小于等于 4KB 时,会 inrow 存储(即行内存储),大于 4KB 时,会存入 LOB 辅助表。部分场景相比于存入辅助表,inrow 整存整取性能更好。因此该版本提供 LOB 存储模式动态配置能力,不超过行级存储规格限制的前提下,用户可根据业务需求动态调整 inrow 大小。
(四)RPC 安全认证证书管理
集群开启 RPC 认证时,如果有客户端(如仲裁、主备库、OBCDC 等)访问需求,需要先将客户端的 CA 根证书依次放入集群每台节点部署目录下,再做相关配置,操作较为复杂。4.3.0 版本新增内部证书管理功能,SYS 租户下提供 DBMS_TRUSTED_CERTIFICATE_MANAGER 系统包,用于添加、删除、修改受 OBServer 集群信任的 CA 根证书。同时 SYS 租户下新增 DBA_OB_TRUSTED_ROOT_CERTIFICATE 视图,用于展示 OBServer 集群已添加的客户端 CA 根证书列表及证书过期时间等信息。
(五)配置项 RESET
当配置项修改后,如果希望重置为默认值,目前需要先查询配置项的默认值是什么,再手动设置,易用性较差。新版本新增 “ALTER SYSTEM [RESET] parameter_name [SCOPE = {MEMORY | SPFILE | BOTH}] {TENANT [=] 'tenant_name'} ” 语法,用于重置配置项默认值,默认值来源于执行语句节点。SYS 租户下可重置集群级配置项或指定业务租户的配置项,业务租户可重置本租户配置项。在 OBServer 中,SCOPE 这个选项在实现上并没有差异,对于静态生效的配置项,只将配置项默认值落盘,不更新内存值。对于动态生效的配置项,更新内存值并落盘。
五、写在最后
4.3.0 版本是 OceanBase 迈向实时分析 AP 场景的重要里程碑,我们也会在后续的 4.3.x 版本进一步完善 AP 特性,解决业务场景的真实问题。
在此,我们由衷地感谢所有用户和开发者们在 OceanBase 4.3 版本中所做出的贡献。你们的宝贵意见和建议,是 OceanBase 不断进步的强大动力。攻克关键业务负载、构建现代数据架构,希望与每位用户、开发者携手同行,一起打造更好用、更易用的分布式数据库!
感兴趣的用户可以查看 Release Notes,探索全新的 OceanBase 4.3。

