- 1一款简单的Java分词插件:apdplat word_org.apdplat.word
- 2五 Python 字典、字节、集合_python 字节型字典
- 3Centos7搭建Hadoop HA完全分布式集群(6台机器)(内含hbase,hive,flume,kafka,spark,sqoop,phoenix,storm)_centos7 hbase安装
- 4购物网站HTML(首页)_简单购物网站代码html
- 5xcode打包mac桌面程序_xcode打包mac应用
- 6单片机设计_单路测温系统(AT89C51、DS18B20温度传感器、LCD1602)_单片机测温系统温度系统采集电路设计知乎
- 7Python Matplotlib绘图知识总结_python画图的库matplot
- 8【独家】RediSearch - Redis强大的搜索引擎
- 9强化SSH服务安全的最佳实践
- 10Golang入门
C4.5算法_c4.5算法原理
赞
踩
1. C4.5算法简介
C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。
C4.5由J.Ross Quinlan在ID3的基础上提出的。ID3算法用来构造决策树。决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点存放一个类标号。一旦建立好了决策树,对于一个未给定类标号的元组,跟踪一条有根节点到叶节点的路径,该叶节点就存放着该元组的预测。决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。
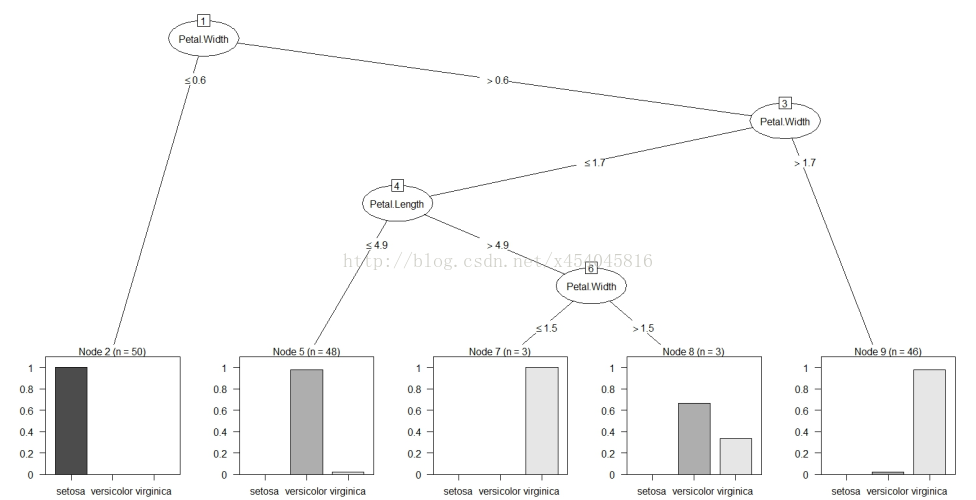
从ID3算法中衍生出了C4.5和CART两种算法,这两种算法在数据挖掘中都非常重要。下图就是一棵典型的C4.5算法对数据集产生的决策树。
数据集如图1所示,它表示的是天气情况与去不去打高尔夫球之间的关系。
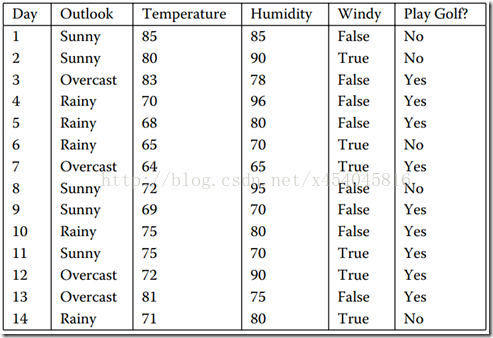
图1 数据集
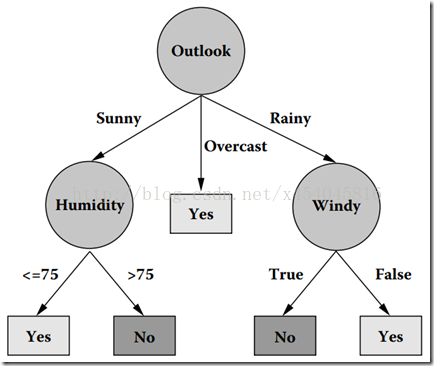
图2 在数据集上通过C4.5生成的决策树
2. 算法描述
C4.5并不一个算法,而是一组算法—C4.5,非剪枝C4.5和C4.5规则。下图中的伪代码将给出C4.5的基本工作流程:

图3 C4.5算法流程
我们可能有疑问,一个元组(数据集)本身有很多属性,我们怎么知道首先要对哪个属性进行判断,接下来要对哪个属性进行判断?换句话说,在图2中,我们怎么知道第一个要测试的属性是Outlook,而不是Windy?其实,能回答这些问题的一个概念就是属性选择度量。
3. 属性选择度量
属性选择度量又称分裂规则,因为它们决定给定节点上的元组如何分裂。属性选择度量提供了每个属性描述给定训练元组的秩评定,具有最好度量得分的属性被选作给定元组的分裂属性。目前比较流行的属性选择度量有--信息增益、增益率和Gini指标。
(1)信息增益
信息增益实际上是ID3算法中用来进行属性选择度量的。它选择具有最高信息增益的属性来作为节点N的分裂属性。该属性使结果划分中的元组分类所需信息量最小。对D中的元组分类所需的期望信息为下式:
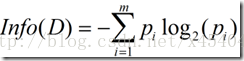
Info(D)又称为熵。
现在假定按照属性A划分D中的元组,且属性A将D划分成v个不同的类。在该划分之后,为了得到准确的分类还需要的信息由下面的式子度量:
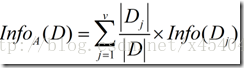
信息增益定义为原来的信息需求(即仅基于类比例)与新需求(即对A划分之后得到的)之间的差,即
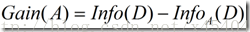
我想很多人看到这个地方都觉得不是很好理解,所以我自己的研究了文献中关于这一块的描述,也对比了上面的三个公式,下面说说我自己的理解。
一般说来,对于一个具有多个属性的元组,用一个属性就将它们完全分开几乎不可能,否则的话,决策树的深度就只能是2了。从这里可以看出,一旦我们选择一个属性A,假设将元组分成了两个部分A1和A2,由于A1和A2还可以用其它属性接着再分,所以又引出一个新的问题:接下来我们要选择哪个属性来分类?对D中元组分类所需的期望信息是Info(D) ,那么同理,当我们通过A将D划分成v个子集Dj(j=1,2,…,v)之后,我们要对Dj的元组进行分类,需要的期望信息就是Info(Dj),而一共有v个类,所以对v个集合再分类,需要的信息就是公式(2)了。由此可知,如果公式(2)越小,是不是意味着我们接下来对A分出来的几个集合再进行分类所需要的信息就越小?而对于给定的训练集,实际上Info(D)已经固定了,所以选择信息增益最大的属性作为分裂点。
但是,使用信息增益的话其实是有一个缺点,那就是它偏向于具有大量值的属性。什么意思呢?就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性。例如一个训练集中有10个元组,对于某一个属相A,它分别取1-10这十个数,如果对A进行分裂将会分成10个类,那么对于每一个类Info(D_j)=0,从而式(2)为0,该属性划分所得到的信息增益(3)最大,但是很显然,这种划分没有意义。
(2)信息增益率
正是基于此,ID3后面的C4.5采用了信息增益率这样一个概念。信息增益率使用“分裂信息”值将信息增益规范化。分类信息类似于Info(D),定义如下:
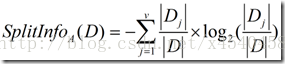
这个值表示通过将训练数据集D划分成对应于属性A测试的v个输出的v个划分产生的信息。信息增益率定义:
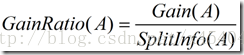
选择具有最大增益率的属性作为分裂属性。
(3)Gini指标
Gini指标在CART中使用。Gini指标度量数据划分或训练元组集D的不纯度,定义为:
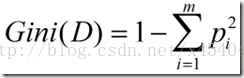
这里通过下面的数据集(均为离散值,对于连续值,下面有详细介绍)看下信息增益率节点选择:
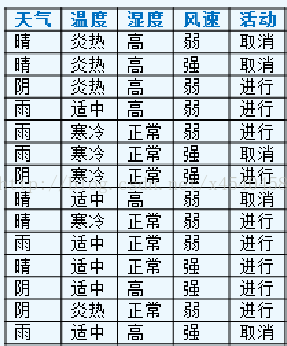
上面的训练集有4个属性,即属性集合A={OUTLOOK, TEMPERATURE, HUMIDITY, WINDY};而类标签有2个,即类标签集合C={Yes, No},分别表示适合户外运动和不适合户外运动,其实是一个二分类问题。
数据集D包含14个训练样本,其中属于类别“Yes”的有9个,属于类别“No”的有5个,则计算其信息熵:即公式(1)的值
1 | Info(D) = -9/14 * log2(9/14) - 5/14 * log2(5/14) = 0.940 |
下面对属性集中每个属性分别计算信息熵,如下所示:
1 | Info(OUTLOOK) = 5/14 * [- 2/5 * log2(2/5) – 3/5 * log2(3/5)] + 4/14 * [ - 4/4 * log2(4/4) - 0/4 * log2(0/4)] + 5/14 * [ - 3/5 * log2(3/5) – 2/5 * log2(2/5)] = 0.694 |
2 | Info(TEMPERATURE) = 4/14 * [- 2/4 * log2(2/4) – 2/4 * log2(2/4)] + 6/14 * [ - 4/6 * log2(4/6) - 2/6 * log2(2/6)] + 4/14 * [ - 3/4 * log2(3/4) – 1/4 * log2(1/4)] = 0.911 |
3 | Info(HUMIDITY) = 7/14 * [- 3/7 * log2(3/7) – 4/7 * log2(4/7)] + 7/14 * [ - 6/7 * log2(6/7) - 1/7 * log2(1/7)] = 0.789 |
4 | Info(WINDY) = 6/14 * [- 3/6 * log2(3/6) – 3/6 * log2(3/6)] + 8/14 * [ - 6/8 * log2(6/8) - 2/8 * log2(2/8)] = 0.892 |
根据上面的数据,我们可以计算选择第一个根结点所依赖的信息增益值,计算如下所示:
1 | Gain(OUTLOOK) = Info(D) - Info(OUTLOOK) = 0.940 - 0.694 = 0.246 |
2 | Gain(TEMPERATURE) = Info(D) - Info(TEMPERATURE) = 0.940 - 0.911 = 0.029 |
3 | Gain(HUMIDITY) = Info(D) - Info(HUMIDITY) = 0.940 - 0.789 = 0.151 |
4 | Gain(WINDY) = Info(D) - Info(WINDY) = 0.940 - 0.892 = 0.048 |
接下来,我们计算分裂信息度量SplitInfo,此处记为H(V):
- OUTLOOK属性
属性OUTLOOK有3个取值,其中Sunny有5个样本、Rainy有5个样本、Overcast有4个样本,则
1 | H(OUTLOOK) = - 5/14 * log2(5/14) - 5/14 * log2(5/14) - 4/14 * log2(4/14) = 1.577406282852345 |
- TEMPERATURE属性
属性TEMPERATURE有3个取值,其中Hot有4个样本、Mild有6个样本、Cool有4个样本,则
1 | H(TEMPERATURE) = - 4/14 * log2(4/14) - 6/14 * log2(6/14) - 4/14 * log2(4/14) = 1.5566567074628228 |
- HUMIDITY属性
属性HUMIDITY有2个取值,其中Normal有7个样本、High有7个样本,则
1 | H(HUMIDITY) = - 7/14 * log2(7/14) - 7/14 * log2(7/14) = 1.0 |
- WINDY属性
属性WINDY有2个取值,其中True有6个样本、False有8个样本,则
1 | H(WINDY) = - 6/14 * log2(6/14) - 8/14 * log2(8/14) = 0.9852281360342516 |
根据上面计算结果,我们可以计算信息增益率,如下所示:
1 | IGR(OUTLOOK) = Info(OUTLOOK) / H(OUTLOOK) = 0.246/1.577406282852345 = 0.15595221261270145 |
2 | IGR(TEMPERATURE) = Info(TEMPERATURE) / H(TEMPERATURE) = 0.029 / 1.5566567074628228 = 0.018629669509642094 |
3 | IGR(HUMIDITY) = Info(HUMIDITY) / H(HUMIDITY) = 0.151/1.0 = 0.151 |
4 | IGR(WINDY) = Info(WINDY) / H(WINDY) = 0.048/0.9852281360342516 = 0.048719680492692784 |
根据计算得到的信息增益率进行选择属性集中的属性作为决策树结点,对该结点进行分裂。从上面的信息增益率IGR可知OUTLOOK的信息增益率最大,所以我们选其作为第一个节点。
4. 算法特性
4.1 决策树的剪枝
在决策树的创建时,由于数据中的噪声和离群点,许多分枝反映的是训练数据中的异常。剪枝方法是用来处理这种过分拟合数据的问题。通常剪枝方法都是使用统计度量,剪去最不可靠的分枝。
剪枝一般分两种方法:先剪枝和后剪枝。
先剪枝方法中通过提前停止树的构造(比如决定在某个节点不再分裂或划分训练元组的子集)而对树剪枝。一旦停止,这个节点就变成树叶,该树叶可能取它持有的子集最频繁的类作为自己的类。先剪枝有很多方法,比如(1)当决策树达到一定的高度就停止决策树的生长;(2)到达此节点的实例具有相同的特征向量,而不必一定属于同一类,也可以停止生长(3)到达此节点的实例个数小于某个阈值的时候也可以停止树的生长,不足之处是不能处理那些数据量比较小的特殊情况(4)计算每次扩展对系统性能的增益,如果小于某个阈值就可以让它停止生长。先剪枝有个缺点就是视野效果问题,也就是说在相同的标准下,也许当前扩展不能满足要求,但更进一步扩展又能满足要求。这样会过早停止决策树的生长。
另一种更常用的方法是后剪枝,它由完全成长的树剪去子树而形成。通过删除节点的分枝并用树叶来替换它。树叶一般用子树中最频繁的类别来标记。后剪枝一般有两种方法:
第一种方法,也是最简单的方法,称之为基于误判的剪枝。这个思路很直接,完全的决策树不是过度拟合么,我再搞一个测试数据集来纠正它。对于完全决策树中的每一个非叶子节点的子树,我们尝试着把它替换成一个叶子节点,该叶子节点的类别我们用子树所覆盖训练样本中存在最多的那个类来代替,这样就产生了一个简化决策树,然后比较这两个决策树在测试数据集中的表现,如果简化决策树在测试数据集中的错误比较少,并且该子树里面没有包含另外一个具有类似特性的子树(所谓类似的特性,指的就是把子树替换成叶子节点后,其测试数据集误判率降低的特性),那么该子树就可以替换成叶子节点。该算法以bottom-up的方式遍历所有的子树,直至没有任何子树可以替换使得测试数据集的表现得以改进时,算法就可以终止。
第一种方法很直接,但是需要一个额外的测试数据集,能不能不要这个额外的数据集呢?为了解决这个问题,于是就提出了悲观剪枝。悲观剪枝就是递归得估算每个内部节点所覆盖样本节点的误判率。剪枝后该内部节点会变成一个叶子节点,该叶子节点的类别为原内部节点的最优叶子节点所决定。然后比较剪枝前后该节点的错误率来决定是否进行剪枝。该方法和前面提到的第一种方法思路是一致的,不同之处在于如何估计剪枝前分类树内部节点的错误率。
把一颗子树(具有多个叶子节点)的分类用一个叶子节点来替代的话,在训练集上的误判率肯定是上升的,但是在新数据上不一定。于是我们需要把子树的误判计算加上一个经验性的惩罚因子。对于一颗叶子节点,它覆盖了N_i个样本,其中有E个错误,那么该叶子节点的错误率为(E+0.5)/N_i。这个0.5(详细请参考连续性校正)就是惩罚因子,那么一颗子树,它有L个叶子节点,那么该子树的误判率估计为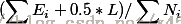
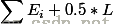
那么一棵树对于一个数据来说,错误分类一个样本值为1,正确分类一个样本值为0,该树错误分类的概率(误判率)为e_1(可以通过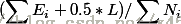
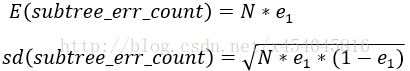
其中,
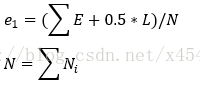
把子树替换成叶子节点后,该叶子的误判次数也是一个伯努利分布,其中N是到达该叶节点的数据个数,其概率误判率e_2为(J+0.5)/N,因此叶子节点的误判次数均值为
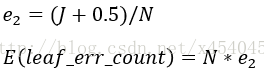
使用训练数据,子树总是比替换为一个叶节点后产生的误差小,但是使用校正后有误差计算方法却并非如此,当子树的误判个数大过对应叶节点的误判个数一个标准差之后,就决定剪枝:
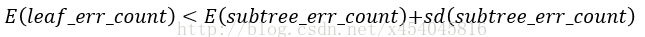
这个条件就是剪枝的标准。
通俗点讲,就是看剪枝后的错误率会不会变得很大(比剪枝前的错误率加上其标准差还大),如果剪枝后的错误率变得很高,则不剪枝,否则就剪枝。下面通过一个具体的实例来看一下到底是如何剪枝的。
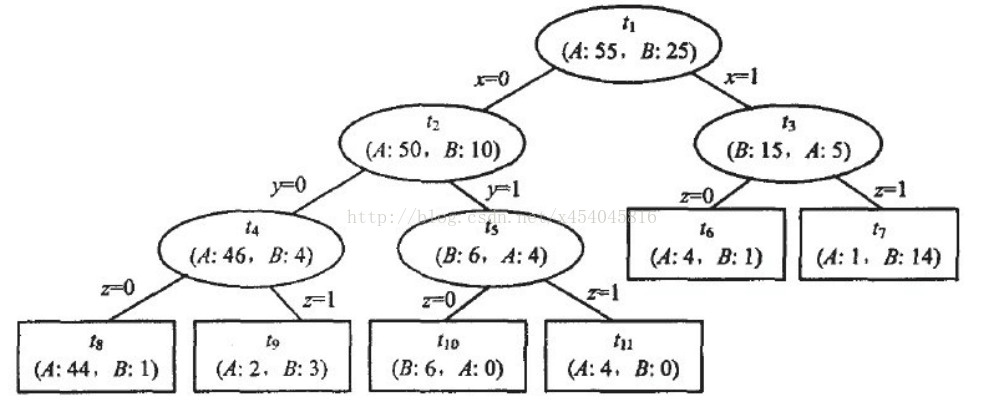
例如:这是一个子决策树,其中t1,t2,t3,t4,t5为非叶子节点,t6,t7,t8,t9,t10,t11为叶子节点,这里我们可以看出来N=样本总和80,其中A类55个样本,B类25个样本。
|
节点
|
E(subtree)
| sd(subtree) |
E(subtree)+
sd(subtree) |
E(leaf) | 是否剪枝 |
|
t1
|
8
|
2.68
|
10.68
|
25.5
|
否 |
|
t2
|
5
|
2.14
|
7.14
|
10.5
|
否 |
|
t3
|
3
|
1.60
|
4.60
|
5.5
|
否
|
|
t4
| 4 |
1.92
|
5.92
|
4.5
| 是 |
|
t5
|
1
|
0.95
|
1.95
|
4.5
|
否 |
此时,只有节点t4满足剪枝标准,我们就可以把节点t4剪掉,即直接把t4换成叶子节点A。
但是并不一定非要大一个标准差,该方法被扩展成基于理想置信区间(confidence intervals, CI)的剪枝方法,该方法将叶节点的错误率e建模成为服从二项分布的随机变量,对于一个置信区间阈值CI,存在一个上界e_max,使得e<e_max以1-CI的概率成立(对于C4.5算法中默认的CI值为0.25),若p(e<e_max)>1-CI,则剪枝。更近一步,我们可以用正态分布来逼近e(只要N足够大),基于这些约束条件,C4.5算法的期望误差的上界e_max(一般用Wilson score interval)为: