
- 1默认配置文件 hdfs-default.xml
- 2一台电脑配置多个GitHub/GitLab帐号的SSH Key切换_两个gitlab ssh
- 3【cmake】find_package的简单用法_cmake find qt5core
- 4android 保存文件到本地可见_Android保存Log信息到本地文件 | 学步园
- 5手撕数据结构之单链表_手撕 链表删除
- 6StringBuilder的toString()和resver()
- 7linux lvm 学习笔记_lvm vgchange -aln
- 8Linux安装部署hadoop遇到的问题_linux怎么使用命令修改hadoop权限
- 9Vivado中FFT IP核的使用_vivado中fft核的用法
- 10Idea连接Gitee上传项目_idea 本地项目上传到git
【论文速读】|探索ChatGPT在软件安全应用中的局限性
赞
踩

本次分享论文:Exploring the Limits of ChatGPT in Software Security Applications
基本信息
原文作者:Fangzhou Wu, Qingzhao Zhang, Ati Priya Bajaj, Tiffany Bao, Ning Zhang, Ruoyu "Fish" Wang, Chaowei Xiao
作者单位:威斯康星大学麦迪逊分校、密歇根大学安娜堡分校、亚利桑那州立大学、圣路易斯华盛顿大学
关键词:大语言模型,软件安全,漏洞检测,漏洞修复,符号执行,模糊测试
原文链接:https://arxiv.org/pdf/2312.05275
论文要点
论文简介:本论文深入探讨了大语言模型(LLMs),尤其是OpenAI的ChatGPT,在软件安全领域的应用潜力及其局限性。研究团队通过一系列实验,详细评估了ChatGPT在七个关键软件安全应用中的局限性,包括漏洞检测与修复、调试、去膨胀、反编译、打补丁、根本原因分析、符号执行和模糊测试。这些任务通常需要专业知识和大量手动劳动,而ChatGPT的集成可能极大地提高这些任务的效率和有效性。论文不仅揭示了ChatGPT在代码生成、程序理解和命令执行等方面的强大能力,也指出了其在处理复杂和长代码时的限制,为未来的研究和应用提供了宝贵的见解。
研究目的:本研究主要旨在评估ChatGPT在软件安全领域的实际应用潜力,并系统地探讨其在若干关键安全任务中的性能。通过本研究,我们力求深入理解ChatGPT在处理软件安全问题上的能力,尤其是其在漏洞检测、漏洞修复和代码安全分析等方面的实际效果及其局限性。此研究结果将为将来使用语言模型来增强软件安全提供重要的指导和参考。
研究贡献:这是对ChatGPT在软件安全任务中应用性能的首次全面评估,揭示了其在漏洞检测、修复和代码安全分析等方面的有效性及其局限性。本文还提出了在实际软件安全应用中整合和优化ChatGPT的策略,并基于广泛的实验结果,为未来研究ChatGPT以及其他大语言模型在更广阔的安全领域的应用提供了数据支持和理论基础。
引言
在当前的软件开发领域,随着代码复杂度的不断增加,软件安全问题愈发显著。特别是OpenAI的ChatGPT等大语言模型(LLMs)在多个领域展示了显著的应用潜力,从基础的自然语言处理到复杂的编程和代码生成,其卓越性能已经引起了广泛关注。
尽管如此,ChatGPT在软件安全领域的具体应用效果及其局限性尚未充分探讨。本研究意在填补这一空缺,通过系统地评估ChatGPT在七个核心软件安全任务上的表现——包括漏洞检测与修复、代码安全性评估——来揭示其潜在能力与现有不足。研究还旨在了解ChatGPT处理高复杂性和长代码的性能,以为未来利用LLMs提升软件安全性提供理论与实践指导。
研究背景
随着信息技术的快速进展,软件安全已成为全球广泛关注的重点问题。在云计算、大数据和物联网等背景下,软件系统正面临着日益复杂的安全威胁。由于传统安全防御手段常常难以应对新型安全挑战,开发新技术以提升软件的安全性显得尤其重要。
像ChatGPT这样的大语言模型在自然语言处理和代码生成领域已显示出卓越潜力,但其在软件安全领域的实际应用效果和实用性仍待广泛研究。因此,本研究团队对该领域的应用进行深入的探索和评估。
漏洞
漏洞检测:本研究重点探讨了ChatGPT在软件漏洞识别方面的能力。通过分析代码的语义和结构信息,ChatGPT试图检测和识别潜在的安全漏洞。虽然在基础案例中,ChatGPT能够准确识别常见的安全漏洞,例如SQL注入和跨站脚本攻击(XSS),但在处理复杂或较长的代码时,其检测能力有所降低。研究表明,随着代码上下文的增加或更深层逻辑交互的涉及,ChatGPT的漏洞检测准确率受到影响。这些结果对于理解和改进ChatGPT在实际软件安全应用中的效果具有重要意义。
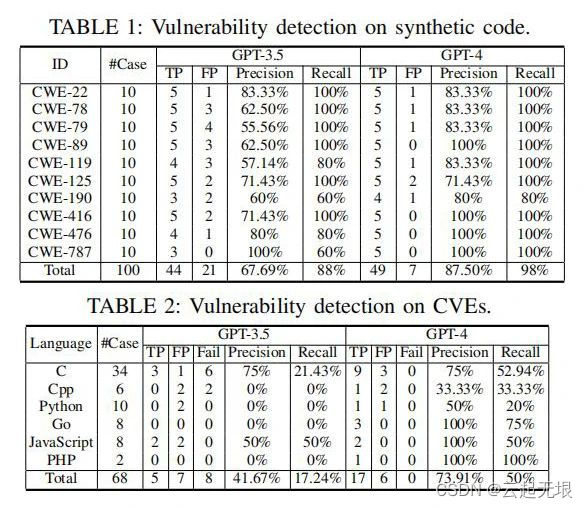
漏洞修复:本研究评估了ChatGPT在自动化修复软件漏洞的应用效果。通过理解漏洞的根本原因,ChatGPT尝试自动生成修复代码。对于诸如缓冲区溢出或输入验证错误的简单漏洞,ChatGPT表现出能够有效生成修复补丁的能力。然而,面对逻辑较复杂或需要特定领域知识的漏洞时,其生成的修复方案往往不够精确或并非完全适用,揭示了其在理解深层软件逻辑和维护代码完整性方面的局限。这些发现提示未来研究应进一步优化模型的深度学习能力和上下文理解能力。
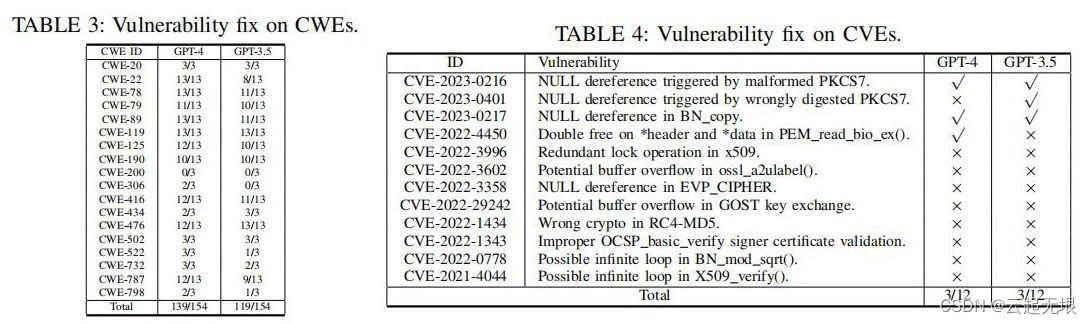
原因分析
本研究详细探讨了ChatGPT在确定软件漏洞和错误的根本原因的能力。通过分析程序崩溃、功能异常或安全漏洞的案例,ChatGPT努力从错误消息、代码执行路径和测试用例中提取关键信息,以准确识别问题的具体代码行或逻辑错误。
尽管ChatGPT在某些情况下能够精确地指出问题的根源并提出修复建议,研究发现其在处理高度复杂或模糊的错误描述时分析结果可能缺乏准确性或可靠性。这显示了尽管ChatGPT在自然语言理解方面表现出色,其在复杂软件系统的深入错误分析和理解方面还需进一步的提升和优化。
研究技术
反编译:本研究评估了ChatGPT在将汇编代码转换为高级编程语言(如C或Java)的能力。利用其先进的语言理解技术,ChatGPT尝试重构源代码的逻辑结构和语义内容。研究结果表明,在简单示例中,ChatGPT能成功还原代码的基本功能和结构。然而,面对含复杂控制流、高度优化或采用代码混淆技术的汇编代码时,其反编译的精确度和效率表现不稳。此外,ChatGPT在恢复变量名和数据类型方面存在局限,这可能影响代码的可读性和实用性。因此,尽管ChatGPT展示了一定的潜力,其算法还需进一步优化以更好处理复杂代码。
符号执行:本研究探讨了ChatGPT在分析和执行代码的符号路径以识别潜在错误和漏洞的能力。符号执行,一种验证程序正确性的技术,通过模拟各种可能的输入路径测试程序行为。ChatGPT尝试模拟这些路径并评估在不同条件下的程序响应。研究结果显示,ChatGPT能有效地识别简单的逻辑错误和条件判断失误,但在处理涉及复杂数据结构或高并行执行路径的程序时,其分析深度和准确性需要提升。这些发现表明,尽管ChatGPT在此领域已有基础,其应用还需进一步优化和深化。
模糊测试:本研究评估了ChatGPT在自动生成测试输入,以探测软件中潜在的缺陷和漏洞的能力。模糊测试是一种强大的软件测试技术,它通过向系统输入大量随机或半随机的数据,尝试触发异常或失败。ChatGPT用于生成多样化的测试用例,模拟各种用户输入行为以测试软件的健壮性。尽管ChatGPT在一些场景下成功地识别了程序的脆弱点,但对于需要高度定制化输入的复杂系统,其生成的测试数据仍需要进一步优化,以提高覆盖率和发现深层次漏洞的能力。
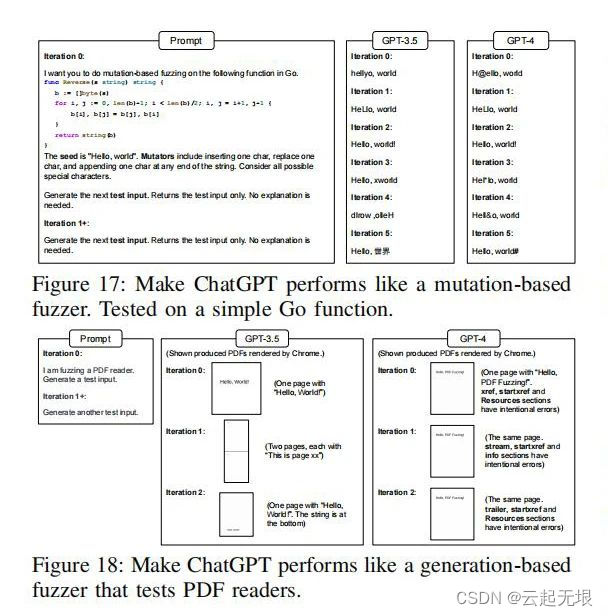
论文结论
ChatGPT在软件安全任务中展示了显著的潜力,特别是在理解和生成代码方面。然而,它在处理长代码段、复杂逻辑或需要深入领域知识的任务时表现出一些局限。未来的研究应着重于提升模型的深层理解能力,并优化其在特定安全任务中的表现。
原作者:论文解读智能体
校对:小椰风


