
热门标签
热门文章
- 1[CodeX] 输入文本即可生成代码_codex代码
- 2利用开源AI引擎平台:实现企业客户对话分析与优化中的应用|可本地化部署_优化ai对话
- 3简单入门linux【一】初识linux_linuk
- 4HTML基础之form表单_html form表单
- 5计算机通信与网络 沈金龙 北京邮电大学出版社 笔记,参考资料
- 6SLAM导航机器人零基础实战系列:(四)差分底盘设计——2.stm32主控软件设计
- 7RAG 修炼手册|如何评估 RAG 应用?_rag评估
- 8探索AlphaCodium:从提示工程到流程工程的代码自动生成新境界
- 9判断推理——图形推理
- 10ChatGPT王炸升级!更强版GPT-4上线,API定价打骨折,发布现场掌声没停过
当前位置: article > 正文
百度ERNIE系列预训练语言模型浅析(4)-总结篇
作者:weixin_40725706 | 2024-05-30 15:03:10
赞
踩
百度ERNIE系列预训练语言模型浅析(4)-总结篇
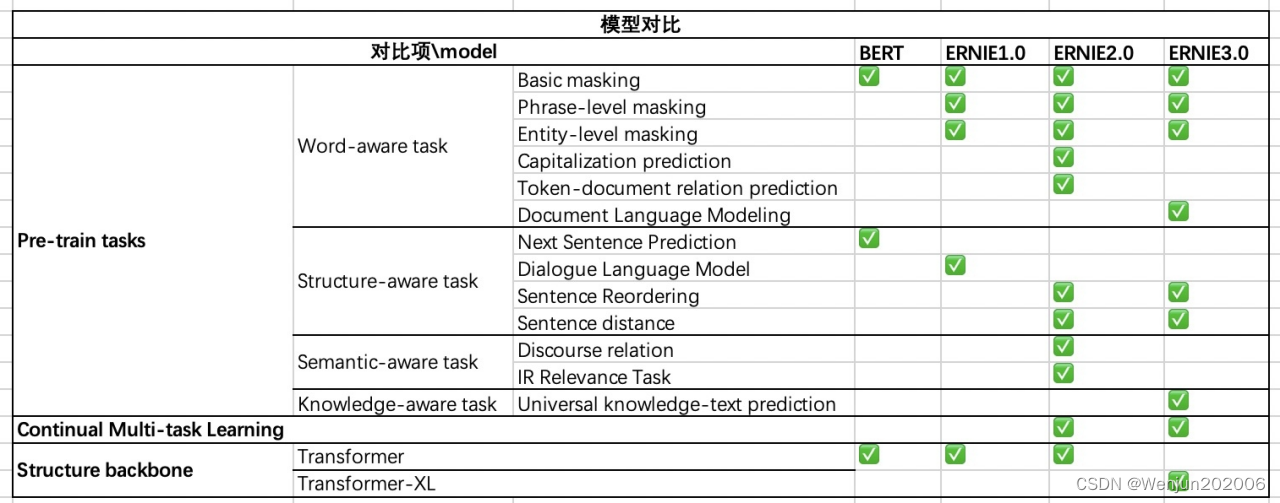
总结:ERNIE 3.0与ERNIE 2.0比较
(1)相同点:
采用连续学习
采用了多个语义层级的预训练任务
(2)不同点:
ERNIE 3.0 Transformer-XL Encoder(自回归+自编码), ERNIE 2.0 Transformer Encoder(自编码)
预训练任务的细微差别,ERNIE3.0里增加的知识图谱
ERNIE 3.0考虑到不同的预训练任务具有不同的高层语义,而共享着底层的语义(比如语法,词法等),为了充分地利用数据并且实现高效预训练,ERNIE 3.0中对采用了多任务训练中的常见做法,将不同的特征层分为了通用语义层(Universal Representation)和任务相关层(Task-specific Representation)。
参考
- Sun Y, Wang S, Li Y, et al. Ernie: Enhanced representation through knowledge integration[J]. arXiv preprint arXiv:1904.09223, 2019.
- Sun Y, Wang S, Li Y, et al. Ernie 2.0: A continual pre-training framework for language understanding[C]//Proceedings of the AAAI * Conference on Artificial Intelligence. 2020, 34(05): 8968-8975.
- Sun Y, Wang S, Feng S, et al. ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and * Generation[J]. arXiv preprint arXiv:2107.02137, 2021.
- 冯仕堃《百度知识增强技术ERNIE最新进展及其应用实践》 DataFun
- 常见的 BERT Mask 策略
- 自回归语言模型 VS 自编码语言模型
- 【论文极速看】ERNIE 3.0 通过用知识图谱加强的语言模型
- ERNIE3.0 Demo试玩,被卷到了
- 刷新50多个NLP任务基准,百度ERNIE 3.0知识增强大模型显威力
- 什么是 One/zero-shot learning?
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/647462
推荐阅读
相关标签

