
- 1CSDN原力值解析:功能作用、获取方法、积分对应等级关系详解
- 2iVX低代码平台系列详解 -- 概述篇(二)_ivx低代码平台 怎么 回调
- 3docker安装教程(详解)
- 4三分钟手把手带你 CleanMyMac X for Ma v4.15.1中文破解版安装激活图文教程_cleanmymacx 4.15
- 5【PHP】PHP代码审计基础知识
- 6探索Gin框架:快速构建高性能的Golang Web应用_gin 框架
- 7BGP/MPLS IP VPN跨域解决方案
- 8Flutter beta 1 重磅发布:开发精美的原生应用(1)
- 9ZooKeeper中节点的操作命令(查看、创建、删除节点)_zk创建节点命令
- 10Stable Diffusion安装教程、model导入教程以及精品promt指令_stable diffusion model
大模型学习路线(4)——大模型微调_p-tuning v2是全参微调吗
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
1.1. 全参微调(Full Parameter Fine-Tuning,FPFT)
1.2. 低参微调(Parameter Efficient Fine-Tuning,PEFT)
2.1. 上下文学习(In-Context learning,ICL)
2.2. 有监督微调(Supervised Fine-Tuning,SFT)
2.3. 基于人类反馈的强化学习(Reinforcement,RLHF)
3.1. 有监督微调(Supervised Fine-Tuning,SFT)
3.2. 指令微调(Instruction Tuning,IT)
前言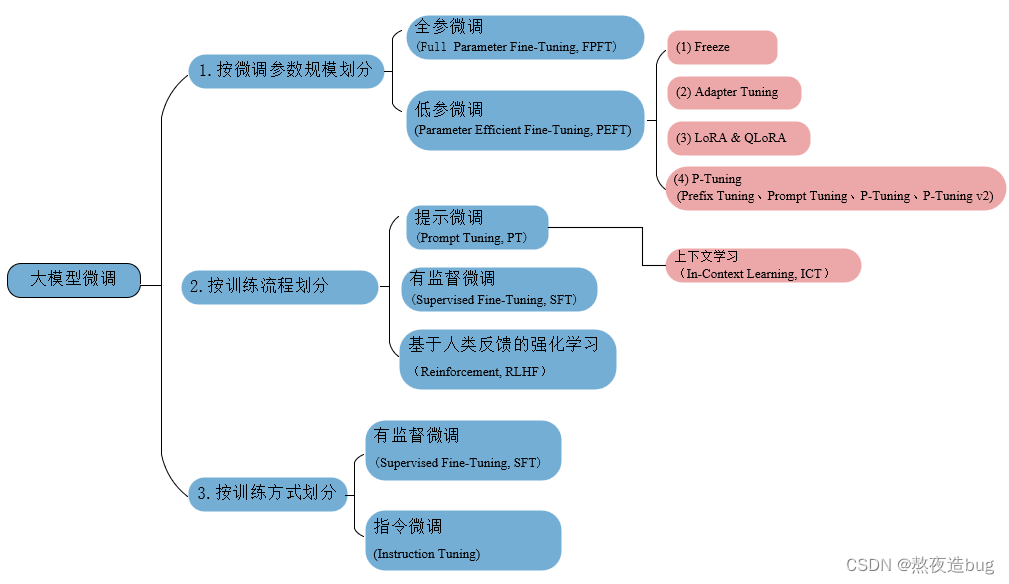
图1. 大模型微调技术分类
一、微调分类
1. 按微调参数规模划分
1.1. 全参微调(Full Parameter Fine-Tuning,FPFT)
用预训练权重作为初始化权重,在特定数据集上继续训练,全部参数都更新。
1.2. 低参微调(Parameter Efficient Fine-Tuning,PEFT)
用更少的计算资源完成参数的更新,只更新部分参数,或者通过对参数进行某种结构化约束,例如稀疏化或低秩近似解来降低微调的参数量。最小化微调网络模型中的参数数量和降低计算复杂度来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。使得即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习 Transfer Learning。
------------------------------------------------------------------ 分界线 ------------------------------------------------------------------
经典的低参微调方法:Adapter(谷歌2019)、LoRA(微软2021)、QLoRA(微软2023)、Prefix Tuning(斯坦福2021)、Prompt Tuning(谷歌2021)、P-Tuning(清华2022)、P-Tuning v2(清华2022)。以下将对如上多种低参微调技术进行整理(LLM岗必考题!!!)
1.2.1. Adapter
Adapter微调方法涉及向预训练模型中添加小型、任务特定的模块(适配器)。这些适配器被插入到原始模型的层之间,并使用任务特定的数据进行训练。原始模型保持相对不变,使其具有高效性并保留其通用知识,同时适应特定任务。
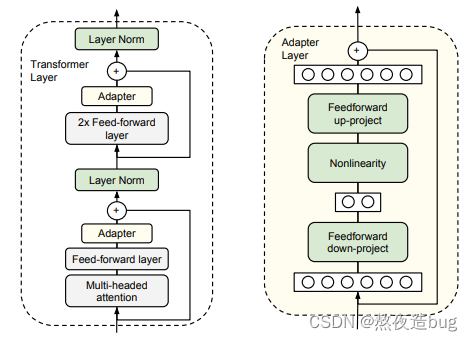
图2. Adapter微调原理
paper: https://arxiv.org/pdf/1902.00751v2.pdf
github: https://github.com/google-research/adapter-bert
1.2.2. LoRA
LoRA是一种基于低秩矩阵分解的微调策略。它通过向模型权重添加低秩矩阵来调整预训练模型的行为,而不是直接更新所有参数。这样可以显著减少需要训练的参数数量,并保持原始模型结构不变,以较小的成本实现对下游任务的良好适应。
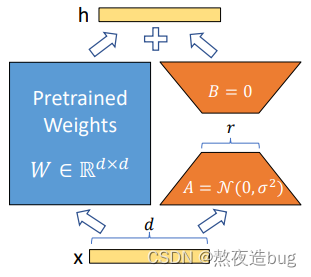
图3. LoRA微调原理
paper: https://arxiv.org/abs/2106.09685
github: https://github.com/microsoft/LoRA
1.2.3. QLoRA
LoRA方法的一种变体,特别针对量化场景设计。QLoRA同样采用低秩矩阵分解,但在此基础上结合了权重量化技术,进一步压缩模型大小并降低计算成本,使得模型能在资源受限的环境下高效地进行微调。
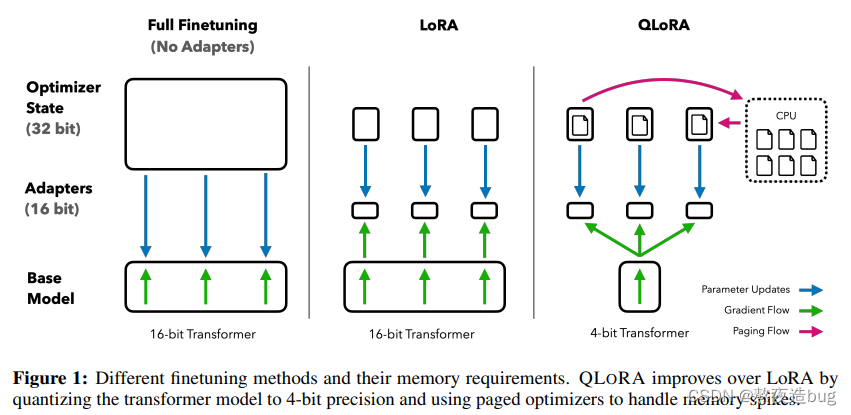
图4. QLoRA微调原理
paper: https://arxiv.org/pdf/2305.14314v1.pdf
github: https://github.com/artidoro/qlora
1.2.4. Prefix Tuning
该方法为预训练语言模型引入一个可学习的“前缀”向量序列,在生成过程中将其与输入文本拼接作为模型的额外输入。模型只需优化这个固定的长度的前缀向量,就能引导模型在不同的下游任务上产生合适的结果,避免了对模型主体参数的大规模更新。
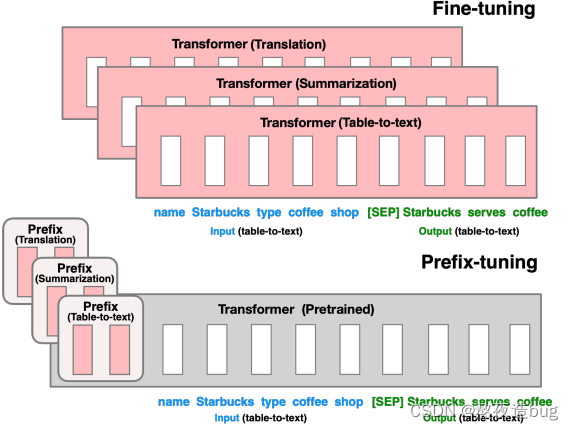
图5. Prefix Tuning微调原理
paper: https://arxiv.org/pdf/2101.00190v1.pdf
github: https://github.com/XiangLi1999/PrefixTuning
1.2.5. Prompt Tuning
Prompt Tuning专注于对提示(prompt)的微调,即将待解决的任务转化为预训练模型熟悉的格式(如同自然语言问答)。这种方法只更新少量被称为“prompt token”的参数,其余大部分参数保持固定,使模型能根据特定任务的需求生成相应输出。

图6. Prompt Tuning微调原理
paper: https://arxiv.org/pdf/2104.08691v2.pdf
github: https://github.com/google-research/prompt-tuning
1.2.6. P-Tuning
P-Tuning是Prompt Tuning的一种扩展形式,通过将连续的向量(称为“软提示”)插入到模型输入中,替代手工设计的离散提示词。这种连续的提示向量经过训练后,能够更灵活且有效地指导模型处理各种下游任务,同时大幅减少需要更新的参数量。

图7. P-Tuning微调原理
paper: https://arxiv.org/pdf/2103.10385v2.pdf
github: https://github.com/THUDM/P-tuning
1.2.7. P-Tuning v2
P-Tuning V2在P-Tuning V1的基础上进行了下述改进:
- 在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这与Prefix Tuning的做法相同。这样得到了更多可学习的参数,且更深层结构中的Prompt能给模型预测带来更直接的影响。
- 去掉了重参数化的编码器。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现。
- 针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,我们发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与Prefix-Tuning中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。
- 可选的多任务学习。先在多任务的Prompt上进行预训练,然后再适配下游任务。一方面,连续提示的随机惯性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。
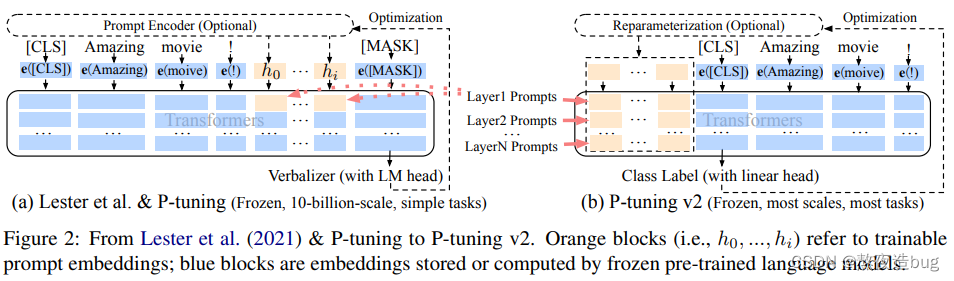
图8. P-Tuning v2微调原理
paper: https://arxiv.org/pdf/2110.07602v3.pdf
github: https://github.com/thudm/p-tuning-v2
以上是对Adapter、LoRA、QLoRA、Prefix Tuning、Prompt Tuning、P-Tuning、P-Tuning v2多种低参微调技术的整理(LLM岗必考题!!!)
------------------------------------------------------------------ 分界线 ------------------------------------------------------------------
2. 按训练流程划分
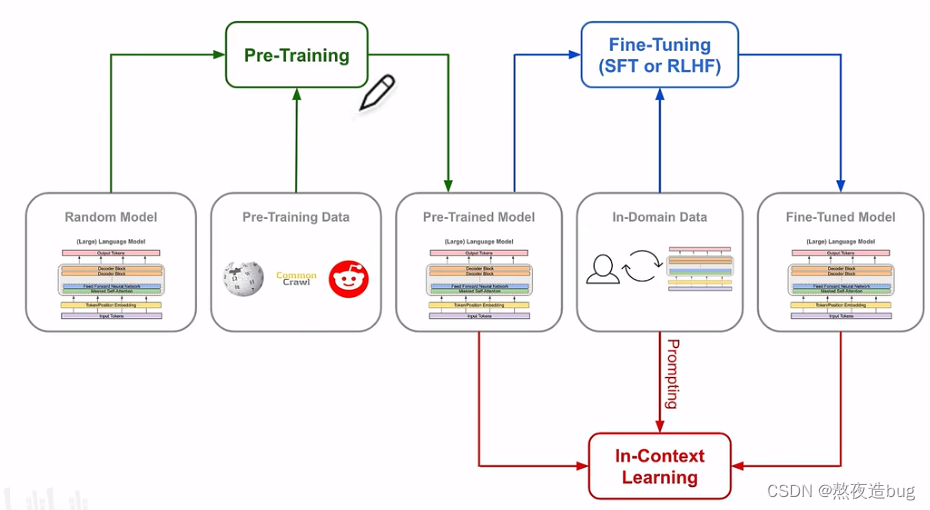
图9. LLM训练流程划分(Pre-Training、Fine-Tuning、Alignment)
2.1. 上下文学习(In-Context learning,ICL)
ICL区别于普通微调 Fine-Tuning,不对 LLMs 执行任何的微调,直接将模型的输入输出拼接起来作为一个prompt,引导模型根据输入的数据结构demo,给出任务的预测结果。 ICL能够基于无监督学习的基础上取得更好模型效果,并且不需要根据特定的任务重新微调 Fine-Tuning 更新模型参数,避免不同任务要重新进行真正的微调。
另外,提示微调(Prompt Tuning)属于ICL的方式之一。
2.2. 有监督微调(Supervised Fine-Tuning,SFT)
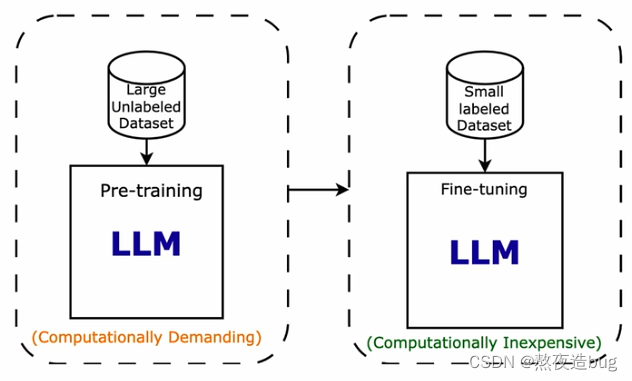
图10. 预训练-->有监督微调
在预训练基础上,使用标记数据对预训练模型进行微调的过程,以便模型能够更好地执行特定任务。
2.3. 基于人类反馈的强化学习(Reinforcement,RLHF)
(1)预训练模型的有监督微调
收集提示词集合,并要求 Label 人员写出高质量的答案,然后使用该数据集以监督的方式微调预训练模型。
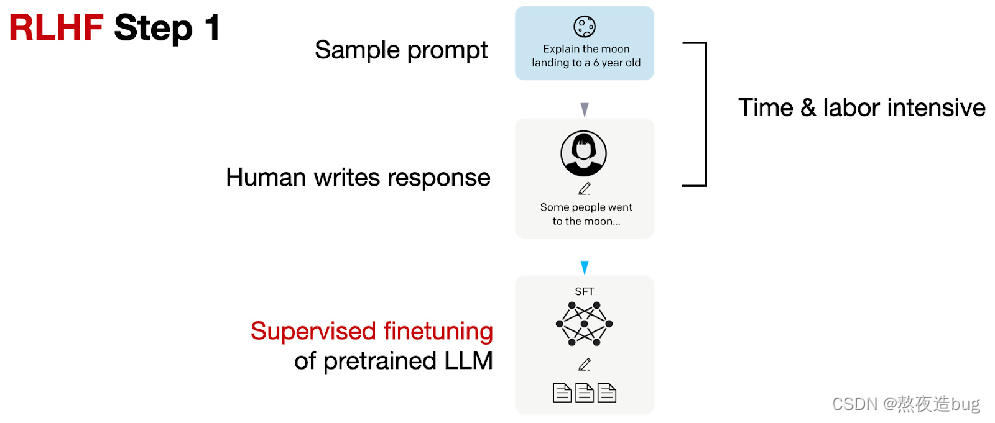
图11
(2)创建奖励模型
对于每个提示 Prompt,要求微调后的LLMs 生成多个回复,再由标注人员根据真实的偏好对所有回复进行排序,也可以称为Alignment。接着训练奖励模型 RM 来学习人类的偏好,用于后续优化。
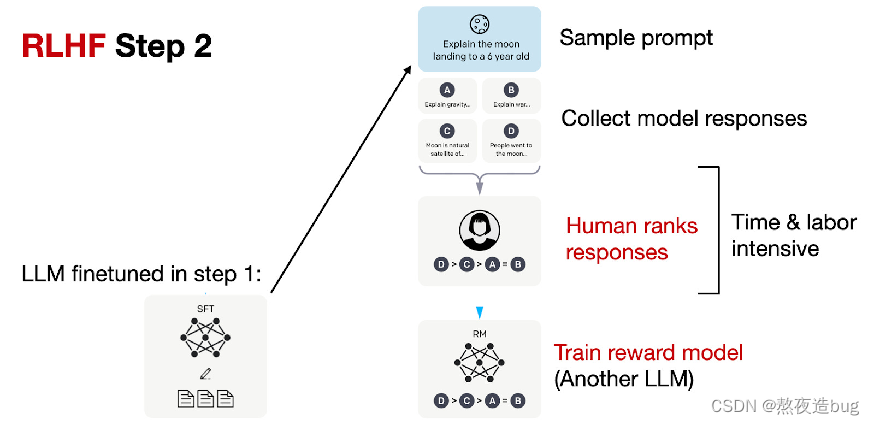
图12
(3)PPO微调
使用强化学习的算法(如PPO,proximal policy optimization),根据奖励模型 RM 提供的奖励分数,对SFT模型进一步优化用于后续的推理(文字生成)。
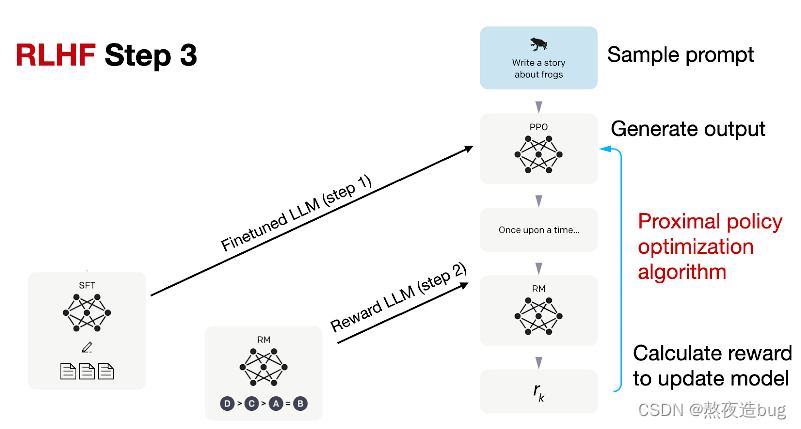
图13
3. 按训练方式划分
3.1. 有监督微调(Supervised Fine-Tuning,SFT)
使用标记数据对预训练模型进行微调的过程,以便模型能够更好地执行特定任务。
3.2. 指令微调(Instruction Tuning,IT)
指令微调Instruction Tuning可以被视为有监督微调SFT的一种特殊形式。通过构造特殊的数据集,即<指令,输出>对的数据集,进一步训练LLM的过程,以增强LLM能力和可控性。
由人类指令和期望的输出组成进行配对。这种数据结构使得指令微调专注于让模型理解和遵循人类指令。作为有监督微调的一种特殊形式,专注于通过理解和遵循人类指令来增强大型语言模型的能力和可控性。
4. 微调优势
4.1. 定制化模型
通过微调大模型,可以根据用户自身的具体需求定制模型,从而提高准确性和性能。
4.2. 提高资源利用率
通过减少从头开始构建新模型的方式进行预训练,从而来节省时间、算力资源和其他带来的成本。
4.3. 性能提升
微调的过程,可以使用用户的独特数据集,来增强预训练模型的性能。
4.4. 数据优化
可以充分利用客户的数据,调整大模型以更好地适应用特定数据场景,甚至在需要时合并新数据。
二、微调实践(以LoRA为例)
- import transformers
- import torch
- from torch.utils.data import Dataset
- from peft import LoraConfig, TaskType, get_peft_model
-
-
- # (1)加载微调前的原model & tokenizer
- model = transformers.AutoModelForCausalLM.from_pretrained(
- model_name_or_path, # 模型配置文件路径
- trust_remote_code=True, cache_dir=training_args.cache_dir)
- tokenizer = transformers.AutoTokenizer.from_pretrained(
- model_name_or_path,
- use_fast=False, trust_remote_code=True, model_max_length=training_args.model_max_length, cache_dir=training_args.cache_dir)
-
- # (2)LoRA微调参数配置
- peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM, target_modules=["W_pack"], inference_mode=False, r=1, lora_alpha=32, lora_dropout=0.1)
-
-
- # (3)给model配置上LoRA参数
- model.enable_input_require_grads()
- model = get_peft_model(model, peft_config)
- model.print_trainable_parameters()
-
- # (4)加载新的微调数据集
- dataset = SupervisedDataset(data_path, tokenizer, model_max_length)
-
- # (5)汇总model、tokenizer、training_args & dataset
- trainer = transformers.Trainer(model=model, tokenizer=tokenizer, train_dataset=dataset)
-
- # (6)模型微调训练 & 微调结果保存
- trainer.train()
- trainer.save_state()
- trainer.save_model(output_dir=training_args.output_dir)

总结
章节一对从微调参数规模、训练流程、训练方式三个角度对微调进行不同的划分,然后对每一分类的每一微调方法进行说明。章节二以github上的Baichuan+LoRA微调源码为例,分析了LLM微调的关键代码。
参考说明
2. 动画科普大模型微调技术总结:何谓Adapter/LoRA/各种Tuning/统一范式?_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1je411z7vg/?spm_id_from=333.999.0.0&vd_source=741fbd6a09f652574b8e335339fdc5703. Llama2—文字版微调教程(针对autodl平台) - 飞书云文档 (feishu.cn)
https://www.bilibili.com/video/BV1je411z7vg/?spm_id_from=333.999.0.0&vd_source=741fbd6a09f652574b8e335339fdc5703. Llama2—文字版微调教程(针对autodl平台) - 飞书云文档 (feishu.cn)![]() https://xtx0o8yn7x.feishu.cn/docx/XjvpdaeQcoF8d3xhpbCcoOJNn9b4.
https://xtx0o8yn7x.feishu.cn/docx/XjvpdaeQcoF8d3xhpbCcoOJNn9b4.
Baichuan2/fine-tune/fine-tune.py at main · baichuan-inc/Baichuan2 (github.com)![]() https://github.com/baichuan-inc/Baichuan2/blob/main/fine-tune/fine-tune.py
https://github.com/baichuan-inc/Baichuan2/blob/main/fine-tune/fine-tune.py

