
- 1摸爬滚打半年,我是如何从小白进阶渗透测试工程师_渗透测试可以自己在家干吗
- 2Jenkins持续集成 解决的是什么问题?
- 3【python】基于python的在线电影网站的设计与实现_python电影网站
- 4AutoDIR: Automatic All-in-One Image Restoration with Latent Diffusion
- 5Automatically Learning Semantic Features for Defect Prediction
- 6Java 之父 James Gosling 最新访谈:JIT 很好,但不适合所有语言
- 7FPGA(二):Vivado 软件中RTL详细描述(RTL ANALYSIS)板块分析_fpga看每个模块的rtl
- 8FFMpeg 获取音频音量、提高音量_ffmpeg音量增强
- 9LeetCode力扣 136. 只出现一次的数字 Single Number 题解代码 JavaScript_力扣 136 js
- 10【保存chatTTS的音频】_couldn't find appropriate backend to handle uri ou
文献学习-28-Endora: 用于内镜仿真的视频生成模型_医学视频生成
赞
踩
Abstract
生成模型有望革新医疗教育、机器人辅助手术以及机器学习的数据增强。尽管在生成二维医疗图像方面有了进展,但临床视频生成这个复杂领域很大程度上还未实现突破。本文介绍了Endora,一种创新方法来生成模拟临床内窥镜场景的医学视频。提出了一个新领域的生成模型设计,它将精心设计的空间时间视频Transformer与先进的2D视觉基础模型先验结合起来,明确地在视频生成过程中建模空间时间动态。首次开创了以视频生成模型对内窥镜模拟进行的公开基准测试,并将现有国内外领先方法应用于这一领域。Endora在广泛测试中显示出在生成内窥镜视频中的非凡视觉品质,超过了国内外领先方法。此外,还探索了这个内窥镜模拟器如何支持下游视频分析任务,甚至可以有多视图一致性地生成3D医学场景。总之,Endora在将生成AI技术应用到临床内窥镜研究领域方面标志着一个重要的突破,为医学内容生成领域的继续进步奠定了坚实基础。
肠胃镜检查是研究肠胃疾病诊断、微创手术和机器人外科的前沿领域之一。尽管它在临床中的作用重要,但由于在人体内采集镜头图像本身就很困难,导致肠胃镜研究和训练资源相对短缺。有必要建立一个丰富多样且质量高的临床肠胃镜视频库,这亦提出了医学生成智能的迫切需求。目标是构建一个强大的肠胃镜视频模拟系统,并生成大量高质量的肠胃镜视频资源,以丰富医务工作者的学习资源,并改进外科机器人和 AI 算法的数据训练。这一研究提出以下几个重要问题:
-
建立视频基准测试:医学影像和文字数据已有自动生成报告和重构影像等应用作为基准。能否同样将这一成功应用于医疗视频,建立视频模拟质量的评估标准?
-
空间时间建模:目前诸如生成对抗网络(GAN)和扩散模型已经很好地生成真实医学 2D 影像,但视频的动态属性和空间时间相关性提出了更大挑战。模型是否能有效模拟真实手术过程的细节?
为解决这些问题,提出一个框架来生成时空连贯且现实可信的肠胃镜视频,模拟临床场景。这超越了传统医学内容生成只针对文本和静态 2D 影像的范围,旨在为医学视频生成定下更全面性的基准。具体来说,设计的 Endora 模型通过预训练的变分自编码器将视频编码到潜变量空间,然后通过变换器块处理特征,同时采用基于 DINO 模型的特征匹配来保证不同视角下的一致性。测试表明 Endora 能生成高真实度的肠胃镜视频,具有很好的效果和潜在应用前景。总体来说,Endora 为医学生成智能在探索复杂高维的外科视频内容生成奠定了基础。
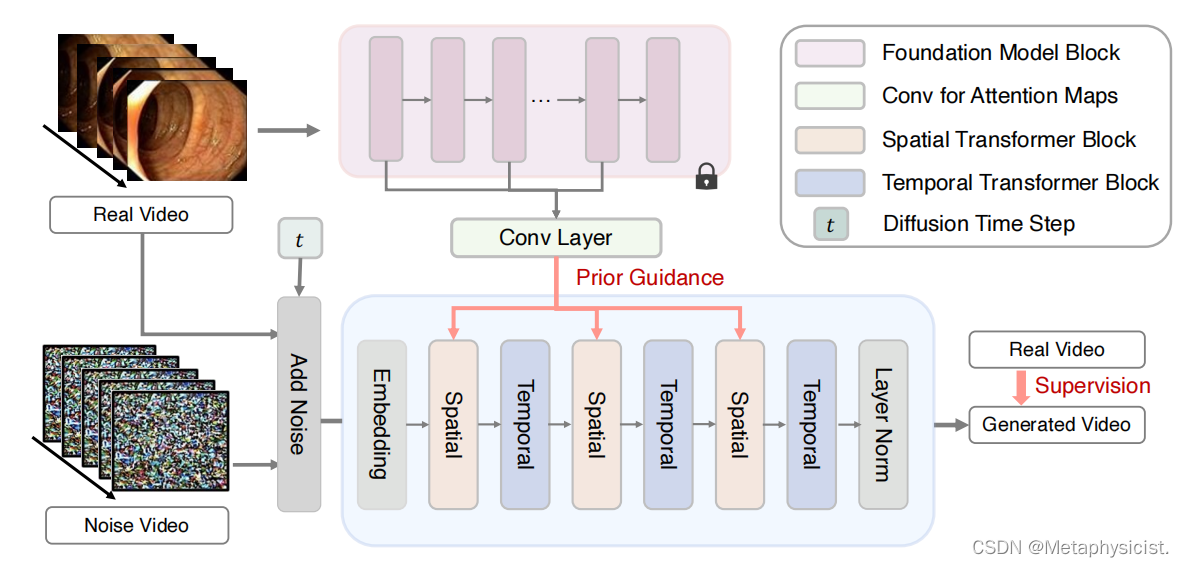
图1。Endora训练概述。扩散模型从噪声输入的视频序列开始,迭代地去除噪声,恢复干净的序列。长期时空动力学是由交错级联的时空变压器块。进一步注入了基于二维视觉基础模型(DINO)来指导特征提取。
Methodology
视频生成的扩散模型
基于去噪扩散概率模型(DDPM)的生成扩散模型专门用于将无序噪声转化为理想样本。这些模型通过逐步从高斯噪声中去除噪声,生成与目标数据分布一致的样本。前向扩散步骤
将高斯噪声添加到图像
中。相应的边际分布可表示为:
其中和
在前向过程结束时设计为收敛到$N(0,I)$。反向扩散过程
被设计为噪声估计器
,用于从噪声图像估计噪声。训练过程包括优化加权证据下界(ELBO):
其中, 时间步
服从均匀采样,而
是加权函数。
将扩散模型提升到视频会增加计算开销和表示复杂性。潜在扩散模型在编码的潜在空间而非像素空间执行扩散过程,提高了模型效率。另一种策略同时训练视频和图像生成以提高视频生成质量。框架采用了类似策略,但进一步提出了新的创新,详述如下。
时空Transformer
借鉴ViT在捕获空间相关性方面的见解,引入了一个专门从共享相同时间索引的token中提取空间信息的空间转换器。采用patch embedding策略为这个空间转换器指示位置嵌入。
进一步引入了一个时间转换器来捕获视频帧之间的时间信息。使用绝对位置编码策略整合时间位置嵌入,该策略将不同频率的正弦函数相结合。这种策略使得模型能够准确地确定每个帧在视频序列中的确切位置。
特别地,给定一个潜在空间中的视频片段,其中
分别表示视频帧数、潜在特征图的高度、宽度和通道数。将
转换为一序列token
。视频片段潜在空间中总token数为
,
表示每个token的维度。将时空位置嵌入$PE$整合到
中,因此
作为转换器主干的输入。将
reshape为
,作为空间转换器块的输入,用于捕获空间信息。这里
表示每个时间索引的token数。然后,包含空间信息的
被reshape为
,作为时间转换器块的输入,用于捕获时间信息。通过交替堆叠一系列空间和时间转换器,模型能够全面地建模长程空间相关性和时间动态。
实验
实验设置
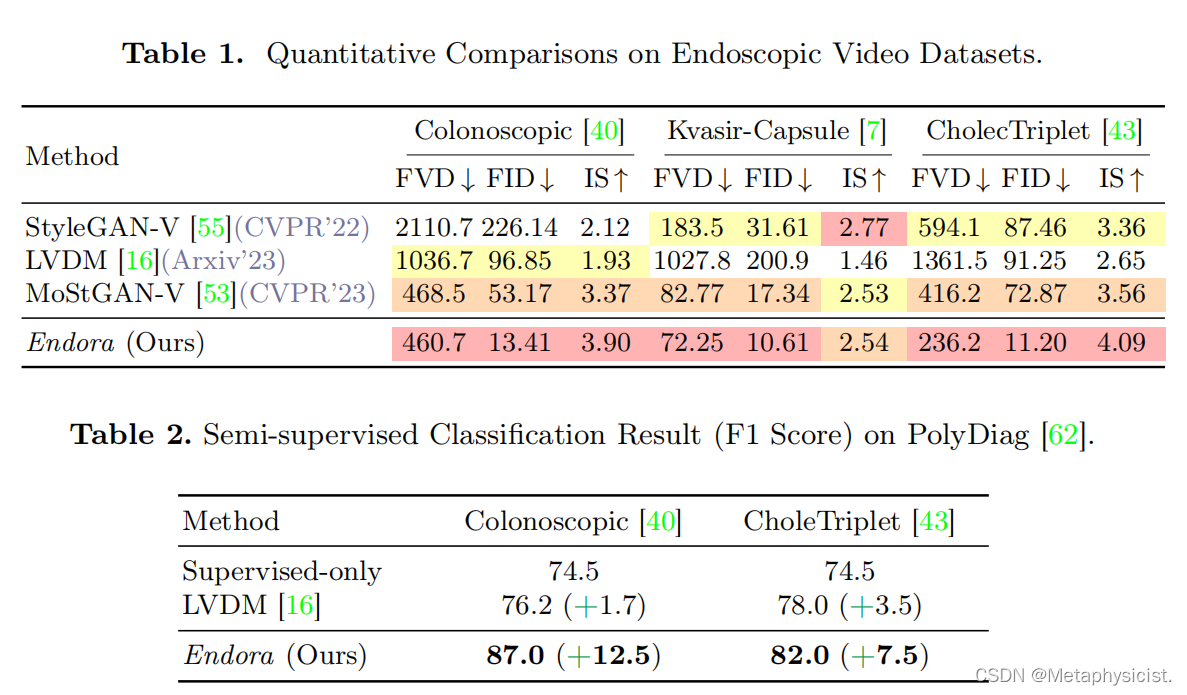
数据集和评估指标。在三个公开的内窥镜视频数据集Colonoscopic、Kvasir-Capsule和CholecTriplet上进行了全面的实验。根据常见做法,以特定的采样间隔从这些数据集中提取16帧视频clips,并将每一帧调整到128×128的分辨率用于训练。在定量比较评估中,采用三种评估指标:Fréchet视频距离(FVD)、Fréchet初始距离(FID)和Inception分数(IS)。遵循StyleGAN-V的评估规则,通过分析2048个每个包含16帧的视频clips来计算FVD分数。
实现细节。使用AdamW优化器,学习率为1×10^-4训练所有模型。简单应用了水平翻转的基本数据增强。跟随生成模型的标准做法,使用了指数移动平均(EMA)策略,并报告了EMA模型的最终结果取样性能。直接使用了Stable Diffusion预训练的变分自动编码器。模型由n=28个Transformer块构建,隐藏维度为d=1152,每个块有n=16个多头注意力,遵循ViT结构。
与现有技术的对比
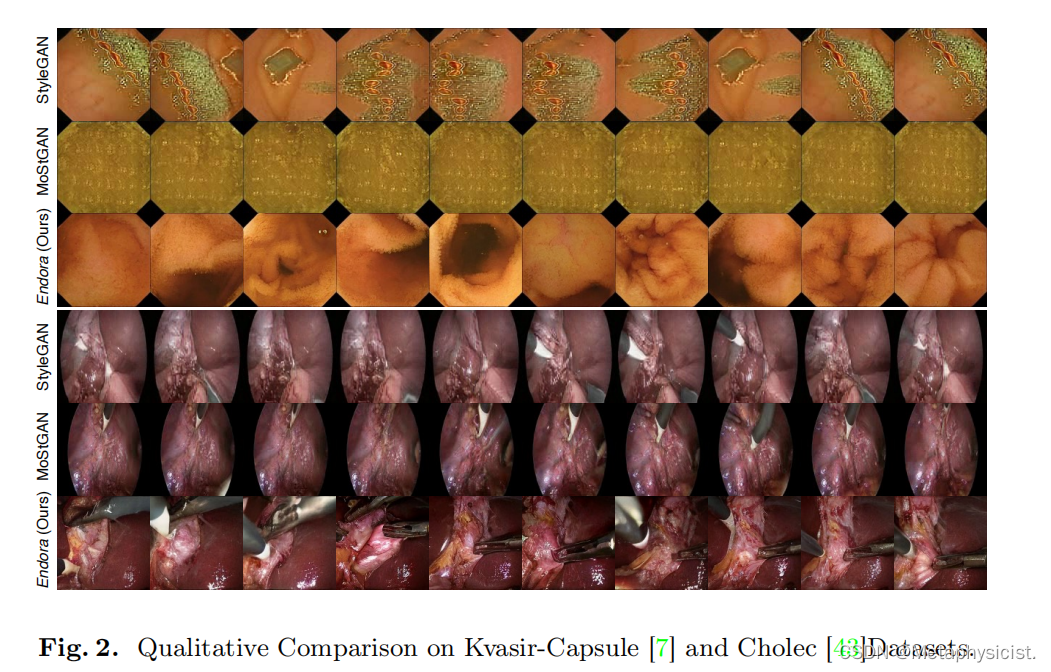
通过在内窥镜视频数据集上复现几种针对一般场景设计的先进视频生成模型,包括StyleGAN-V、MoStGAN-V和LVDM,来进行性能对比。如表1所示,在所有三种指标上,Endora在内窥镜视频生成的视觉保真度方面优于基于GAN的最新方法。此外,Endora还在所有方面超越了先进的基于扩散的LVDM方法,表明Endora能有效地生成内窥镜场景的准确视频表示。图2进一步展示了Endora和之前技术的定性结果。可以观察到,其他技术导致视觉上的违和扭曲(第1行)、内容变化受限(第2和4行)以及帧间过渡不连续(第5行,手术器械的突然闯入)。相比之下,Endora生成的视频帧(第3和6行)避免了视觉违和的扭曲,保留了更多视觉细节,并提供了更优秀的组织表示。
进一步的实证研究
本节阐述了利用Endora生成视频进行几种潜在应用,并对关键策略进行了严格的消融研究。
案例一:Endora作为时间数据扩充器。探索了使用生成视频作为无标签实例进行半监督训练(通过FixMatch)的情况,评估在视频疾病诊断基准PolyDiag上的性能。特别地,使用PolyDiag训练集中随机选择的nl=40个视频作为有标签数据,并分别使用nu=200个从Colonoscopic和CholecTriplet生成的视频作为无标签数据。表2给出了疾病诊断的F1分数,显示了相比仅使用有标签训练实例(Supervised-Only基线)和其他视频生成方法,使用Endora生成的数据能够明显提高下游性能,证实了Endora作为可靠视频数据扩充器用于下游视频分析的有效性。
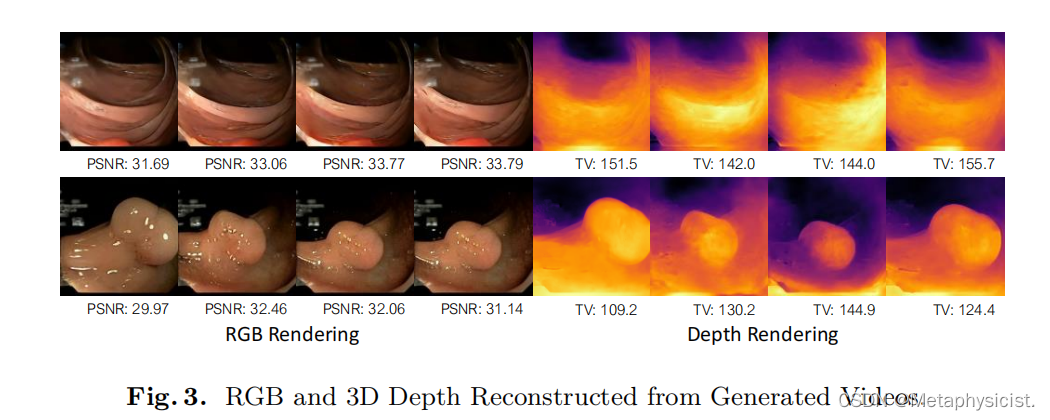
案例二:Endora作为手术世界模拟器。生成内容中新出现的多视角一致性启发探索生成的手术视频中是否存在类似的几何一致性。特别地,从生成的视频中,取一些帧作为训练数据(训练视角),保留其他帧作为测试数据(新视角)。然后使用COLMAP对训练视角进行预处理,再运行现成的3D重建管线(EndoGaussian)获得重建的3D内窥镜场景。图3给出了在新视角下渲染的RGB图像和深度图的可视化,并标注了图像PSNR和深度全变分(TV)。可以观察到,从生成的视频重建的3D场景展现了逼真连续的几何结构,显示了Endora以多视角一致的方式有效执行手术世界模拟的潜力。
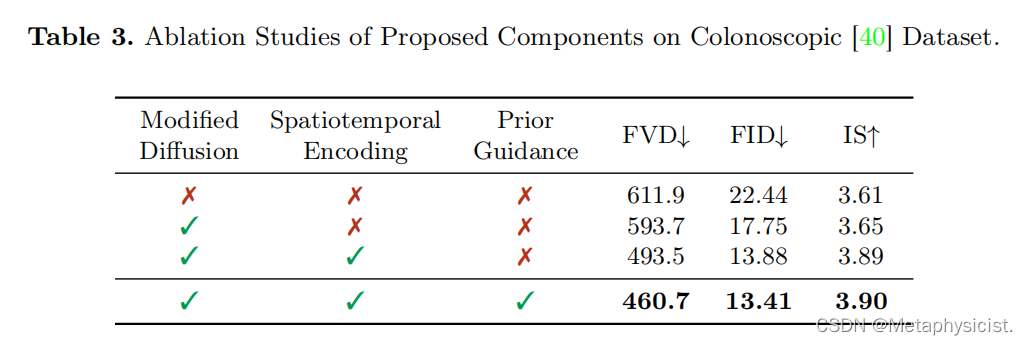
消融研究。表3给出了对Endora提出的关键组件的消融研究。最初,使用一个不带任何提出策略的普通视频扩散模型作为基线。随后,一次添加三种提出的设计策略:修改后的扩散、时空编码和先验引导。可以观察到它们导致了模型性能的稳定进展,确认了设计的策略在提高整体内窥镜视频生成模型的效率和效果方面的关键作用。
Reference
[1] Li, C., Liu, H., Liu, Y., Feng, B. Y., Li, W., Liu, X., ... & Yuan, Y. (2024). Endora: Video Generation Models as Endoscopy Simulators. arXiv preprint arXiv:2403.11050.

