
- 1鸿蒙HarmonyOS实战-ArkTS语言基础类库(并发)_arkts线程_harmonyos arkts代码例子
- 2共识机制汇总ing_21.共识机制结果值目标值的判定是如何判定
- 3linux查看zookeep进程,zookeeper可以查看进程启动,但是状态显示报错:Error contacting service. It is probably not running...
- 4【Hydro】SCS-CN方法中径流曲线数的确定(下)_scs曲线
- 5RK3568-emmc控制器_emmc adma3
- 6海思SD3403,SS928/926,hi3519dv500,hi3516dv500移植yolov7,yolov8(3)_ss928移植
- 7消费者人群画像—信用智能评分 :信用分预测_一、消费者人群画像—信用智能评分器
- 8Go语言框架中如何快速集成限流中间件_goframe 限流中间件
- 9datawhale动手学大模型应用开发-第一章-大模型简介_datawhale rag
- 10Java面试宝典-2017_java面试宝典是什么
大数据基础与应用_大数据应用基础
赞
踩
该内容是笔者学习华为大数据基础认证课程的前三章所做笔记,感兴趣的朋友可以查看此链接有视频课程
一、初识大数据与Python语言
1.1大数据的定义
- 大数据由规模巨大(Volume)、种类繁多(Variety)、增长速度快(Velocity)和变化多样(Variability),且需要一个可扩展体系结构来有效存储、处理和分析的广泛数据集组成。
- 大数据是以容量大、类型多、速度快、价值密度低为主要特征的数据集合,由于这些数据本身规模巨大、来源分散、格式多样、所以需要新的体系架构、技术、算法和分析来对这些数据进行采集、存储和关联分析,以期望能够从中抽取隐藏的有价值的信息。
- 大数据与传统数据分析不同
| 传统数据分析(BI) | 大数据分析 |
|---|---|
| 描述性分析、诊断性分析 | 预测性分析 |
| 有限的数据集、干净的数据集、简单模型 | 大规模数据集、多类型原始数据、复杂数据模型 |
| Causation:事件及其原因 | Correlation:新的规律和知识 |
1.2.大数据的应用场景
- 大数据与销售:网购进行一些商品的浏览、购买等数据行为,系统会自动为其推荐相似的商品
- 大数据与交通:地图公司收集大量的交通状况数据,数据来源主要是出租车司机(GPS设备)、用户导航(百度、高德导航实时记录相应时间和地点,将相关信息上传到地图系统),短时收集大量数据,所有数据汇总到地图系统后台,经过实时处理,综合分析之后显示到导航界面上
- 传染病预测与分析
- 大数据与足球:赛前对运动员进行各项指标分析,才能给出对应指导和意见
- 大数据与天文
- 大数据与政治:奥巴马选举总统利用大数据分析在哪里举行选举活动,把握用户的政治态度和立场,进行精准的政治广告
- 智慧城市与智能家庭
……
1.2.大数据分析流程
- 数据:加工处理的对象
- 平台:加工处理的载体
- 算法:加工处理的具体流程和方法
- 处理平台

- 大数据分析流程:数据获取–>数据清洗–>数据管理–>数据分析–>数据呈现
从算法角度看,大数据分析的流程可以看作是一个持续和迭代的过程,因为算法的适配是需要经过大量尝试和调整之后才能完成

(1)数据获取:不同数据来源,数据采集的手段不同
(2)数据清洗:补充部分数据缺失的属性值;统一数据格式、编码和度量;检测和删除异常数据;研究表明数据准备大概占80%的工作量
(3)数据管理:对数据进行分类、编码、存储、索引和查询;经历了文件管理、数据库、数据仓库、大数据时代新型数据管理系统;向着低成本、高效率的存储查询技术方向发展;数据安全与隐私保护受到广泛关注
(4)数据分析:一般的统计查询(00后最喜欢买的东西);从已有数据中挖掘特定的模式(啤酒与尿布的故事);利用机器学习进行预测性分析(明天的天气)
(5)数据呈现:利用可视化图形呈现数据中隐藏的信息和规律;建立从输入数据到符合认知规律的可视化表征;能够创建可交互的视图;具体包括高维数据可视化、网络和层次数据可视化、时空数据可视化、文本数据可视化等
二、Python大数据基础
2.1数据类型
内置数据类型(一)
-
Python简介:Python语言简单易学,功能强大,是一门适合用于大数据和人工智能的语言;可以处理从“小”数据到大数据,从简单数据到复杂数据;Python是一门弱类型(Python不强制规定变量类型,用户自己定义类型即可)的面向对象(任何类型的数都是对象)的解释型语言
-
Python内置类型对象int:
(1)整数类型的四种进制表示:
十进制,不需要引导符,0-9
二进制,0b或0B,0-1
八进制,0o或0O,0-7
十六进制,0x或0X,0-9到A-F
(2)普通用户无需区分有符号和无符号数
(3)整数类型理论上没有取值范围限制,与C语言不同
(4)支持算术运算 -
Python内置类型对象float:
(1)所有浮点数必须带小数部分,小数部分可以为零或者省略,如5.0或5.
(2)浮点数和整数在计算机内部表示不同,如0.0和0,Python没有double类型,用float类型代替
(3)浮点数表示方法
十进制,如3.1415
科学计数法,如4.3e-5
(4)Python浮点数的取值范围和小鼠精度受不同计算机系统的限制
(5)可以用sys.float_info列出所用计算机系统的各项参数,一般为15个数字的准确度
(6)Python支持无限制且准确的整数计算,建议使用整数而非浮点数
(7)支持算术运算 -
Python内置类型对象complex
(1)表示数学中的复数概念
(2)实部+虚部,表示为:a+bj
(3)实部和虚部均为浮点数
(4)对于复数z,可以用z.real和z.imag获取实部和虚部(获取时要注意适当使用小括号) -
Python内置类型对象bool
(1)python中布尔值使用常量True和False来表示,注意大小写
(2)用于逻辑判定,比较,常用在if和while语句中
(3)bool是int的子类(继承自int),True1 False0返回Ture
(4)下列表达式均会被判定为False
None
False
任意数字类型的0,如0,0.0,0j等
任意空的序列结构,如‘’,(),[ ],空字典等
用户自定义类中给出了__bool__()或__len__()方法,并返回整数0或布尔值False -
Python内置类型对象str
(1)字符串对象:单引号、双引号、三引号,其中单双引号可以交叉使用
(2)字符串和其他类型的区别之一:长度差异很大
(3)Python内部以Unicode比那吗存储字符串,Unicode是真正的字符串,而用ASCII、UTF-8、GBK等字符编码表示的是字节串
(4)可以用len(s)计算出字符串的长度 -
查看类型对象
(1)dir产看对象类型,了解可用方法,用help来获取帮助
(2)判断字符是否为数字:ch.isdight() -
数据类型与输入输出
(1)input():从键盘输入的任何信息,都被转换为字符串
(2)eval():去引号,计算Python表达式,返回运算结果(对应的对象)
(3)type():查看对应的数据类型
(4)举例:

-
强制类型转换(注意精度损失)
(1)int()
(2)float()
(3)str()
(4)complex
(5)chr()支持ASCII码和Unicode
(6)ord()取得ASCII/Unicode值
(7)hex()
(8)oct()
内置数据类型(二) -
Python内置类型对象str(字符串基本操作)
连接:x+y
复制:xn或nx
子串判断:c in s
索引:s[i]通过未知,正向索引和反向索引,如a[2]和a[-2]
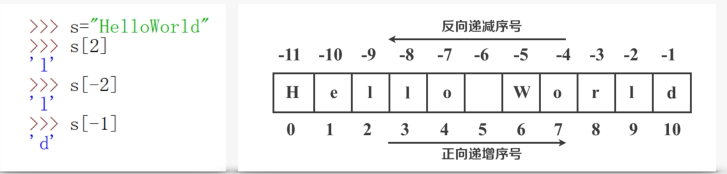
切片:s[i:j:m](i和j可以省略)
slice:[::步长](正负整数)左闭右开
- 字符串对象的方法
(1)常用方法
切割 split(sep=None)
联合 join(iterable)
截取 strip()
计数 count(sub)
替换 replace(old,new)
(2)字符串中的元素是只读的
(3)只能对变量重新赋值而不能修改其中的某些部分

(4)字符串对象方法返回一个新的对象
-
字符串的格式化
(1)Slot槽位:{<槽位标识>:<格式控制标记>}
(2)槽位的位置序号或变量名(包括词典、列表等)
(3)‘公司包括:{0},{1}和{other}’.format(‘google’,‘ali’,other=‘taobao’)
(4)格式控制标记用来控制参数显示时的格式
(5)格式控制标记包括:<填充><对齐><宽度>,<.精度><类型>6个字段,这些字段都是可选的,可以组合使用

(6)举例:手机号中间四位隐藏处理
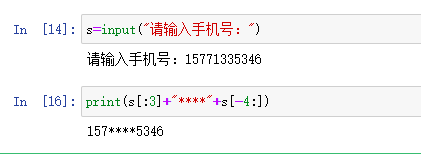
扩展数据类型 -
dtype类型对象简介
(1)dtype不是python内置的数据类型对象
(2)dtype在第三方库Numpy库中定义的数据的类型
(3)Numpy是Numerical Python的简称,是目前Python数值计算中最重要的基础包(array引入多维数组,Python中没有数组)
(4)学习大数据处理必须了解dtype类型对象 -
NumPy为什么重要
(1)与Python本身的数据结构不同,NumPy在内部将数据存储在连续的内存块上
(2)NumPy的算法库是C语言写的,无需类型坚持和其他管理操作
(3)NumPy的数组使用的内存量小于其他Python内建序列(同样的运算量,NumPy所用的时间快100倍左右)
(4)NumPy可以针对全量数组进行复杂计算 -
dtype对象介绍
(1)Dtype对象描述与数组对应的内存区域如何使用
数据的类型(如:整数、浮点数或Python对象)
数据的大小(如:整数使用多少个字节存储)
数据的字节顺序(如:小端法或大端法)
如果是结构化类型,指定每个字段的名称、数据类型和对应的内存块
如果是数据类型是子数组,则指定其形状和数据类型
(2)字节顺序是通过对数据类型预先设定“<”或“>”来决定的
“<”表明使用小端法,即低位组放在最前面
“>”表明使用大端法,即高位组放在最前面
(3) -
dtype可以使用的数据类型
(1)Numpy支持的数据类型比Python内置数据类型要多很多,基本上可以和C语言的数据类型对应,其中部分类型对应Python内置类型
(2)Python中的float使用8字节或64位存储,在dtype中表示np.float64
(3)Numpy提供更精确的类型,如float16,float32,float64,float128,分别表示为f2,f4,f8,f16
(4)Numpy支持int8/uint8/16/32/64(有符号数和无符号数),分别表示i1/2/4/8和u1/2/4/8
(5)字符串支持String_,表示为大写S
(6)Unicode_,表示为大写u,如果长度为20,则表示为U20,S20等
(7)小写o表示object,其他类型 -
使用dtype()函数构造数据类型
(1)numpy.dtype(object,align,copy)
object–要转换为的数据类型对象
align–如果为true,填充字段使其类似C结构体
copy–复制dtype对象,如果false,则是对内置数据类型对象的引用
(2)S20表示20位ASCII码,i1表示int8,f4为32位标准精度浮点 -
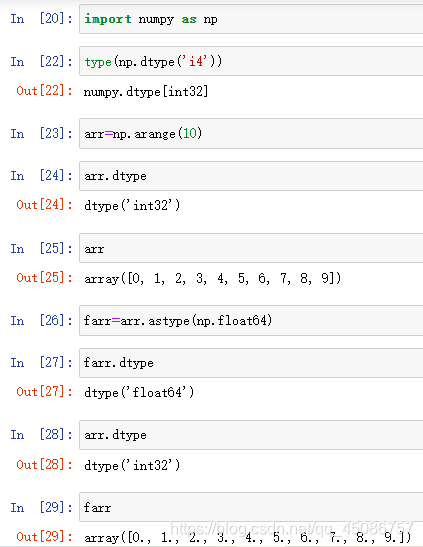
使用dtype的astype()方法转换数据类型
(1)把多维数组对象里面的数据类型转变成其他类型
(2)如从int32到float64
(3)举例:
2.2在线实验–数据类型
内置数据结构(一)
- Python中的内置数据结构
(1)序列类型结构:元组tuple,列表list,字符串str(特殊只读)
(2)集合类型结构:集合set
(3)映射类型结构:字典dict
(4)这些结构的元素一般无类型限制,而且大多可以多层嵌套
(5)Python内置数据结构中没有类似C语言中的数组(其中元素为同种数据类型)
(6)这些内置数据结构让Python的学习和使用变得简单,强大,但也有不足之处,比如性能较低,内存开销较大等
-
序列类型结构之列表list
(1)列表list是一个数据容器,数据项之间存在先后关系,通过序号访问,数据项可重复,数据类型可以多样
(2)字符串可以看作是特殊(内容类型相同,只读)的列表list
(3)列表list内的数据可以修改 -
生成列表list
(1)通过中括号[ ]赋值产生
(2)通过list()函数可以将一个可迭代对象强制转换为列表

(3)列表推导式生成,如[c for c in s if c.isdigit()],表达的是在从字符串s中选出c,并判断c是否为数字,如果是就形成一个新的序列
推导式又称为解析式,是Python的一种独有特性
推导式可以从一个数据序列构建另一个新的数据序列的结构体

-
列表的使用
(1)in和not in,用于判断某元素是否在列表内
(2)列表索引,如ls[i]=x,根据位置访问(读写)列表内的元素
(3)切片,如ls[m:n:k]
(4)ls.append(x),可在列表ls最后增加一个元素x
(5)ls.remove(x),将列表中出现的第一个元素x删除
(6)遍历列表元素:for<元素> in<列表> : 语句 -
列表元素的排序(默认升序)
(1)list.sort(key,reverse)排序,改变原列表
(2)newls=sorted(ls,key,reverse)排序,生成新列表
(3)sorted()方法可以用在任何数据类型的序列中,返回的总是一个列表形式
(4)key用复杂对象的某些值来对复杂对象的序列排序
(5)key参数来指定函数,此函数将在每个元素比较前被调用,此函数只有一个参数且返回一个值用来进行比较
(6)Reverse参数True或False

-
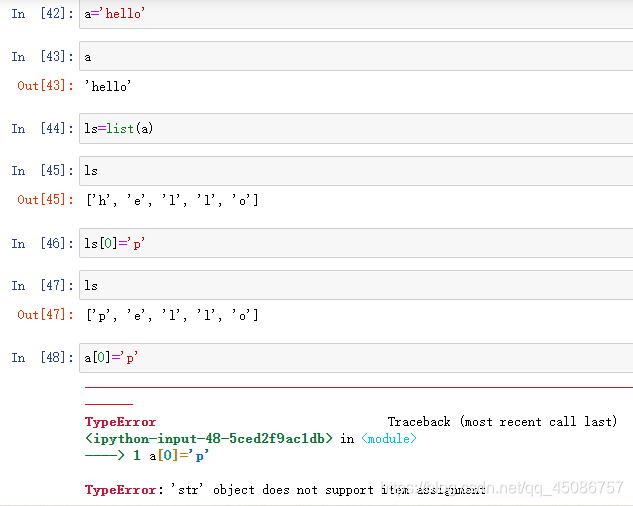
字符串和列表的可变性(只读)比较(即字符串元素只读,列表元素可修改)
-
字符串对象的方法
(1)字符串为不变类型,相同值指向同一内存空间

(2)列表为可变类型,即使值相同(ls1==ls2),也需要额外分配空间
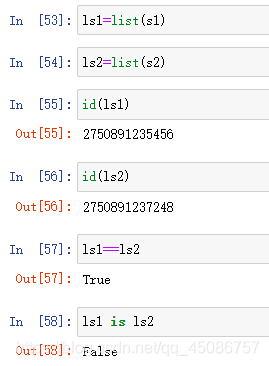
-
元组的生成和限制
(1)元组采用逗号和圆括号(可选)来表示
(2)通过赋值或tuple()函数强制转换
(3)元组生成后其他元素不可修改和删除,即不可remove(),不可append()
(4)其他功能和列表相似,如可以索引和切片
(5)用dir()看一下tuple对象的方法,只有count和index两个
(6)举例


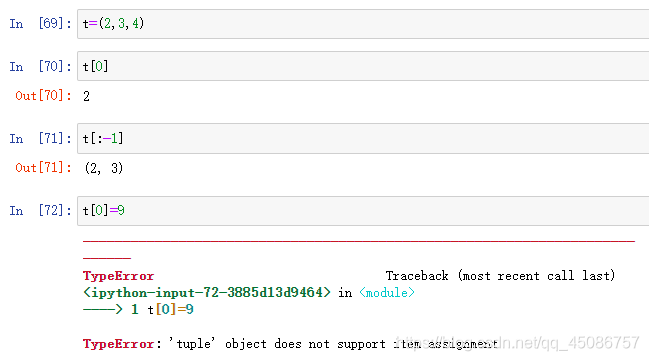
-
元组的使用
主要用于表达固定数据项、函数返回值return、多变量同步赋值、循环遍历等
内置数据结构(二)
-
集合类型结构:集合set
(1)集合类型与数学中集合的概念一致,即包含0个或多个数据项的无序组合
(2)集合中元素不可重复,元素类型只能是固定数据类型,例如:整数、浮点数、字符串、元组等
(3)列表、字典和集合类型本身都是可变数据类型,不能作为集合的元素出现
(4)由于集合是无序组合,他没有索引的位置的概念,不能分片,集合中元素可以动态增加或删除 -
集合的生成
(1)集合用大括号表示
(2)可以用赋值语句生成一个集合,如s={3,"4"5.0}
(3)可以用set(x)函数生成集合,x为序列类型(字符串、list或元组)
(4)集合的打印效果与定义顺序可以不一致
(5)举例

-
集合的使用
(1)成员关系测试(in和not in)
(2)元素去重

(3)删除数据项

-
映射类型结构:字典
(1)通过任意键信息查找一组数据中值信息的过程叫映射,Python语言中通过字典实现映射
(2)Python语言中的字典可以通过大括号建立:{<键1>:<值1>,<键2>:<值2>,……,<键n>:<值n>}
(3)键和值通过冒号链接,不同键值对通过逗号隔开
(4)字典是集合类型的延续,各个元素并没有顺序之分
(5)字典打印出来的顺序与创建之初的顺序不同 -
字典中键的要求
(1)每个键只能对应一个值,不允许一键对应多个值
(2)当字典键重复赋值时,取最后的赋值
(3)键必须是可哈希的,可变类型对象如列表和字典不可哈希,所以不能作为字典的键

-
字典的生成
(1)赋值生成,如d={“name”:“Diego”,“age”:12}
(2)特殊字符串转字典dt=eval("{“a”:5}")
(3)推导式生成
(4)举例:有20个学生,成绩在60-100之间,请筛选出成绩在90分以上的学生

-
字典的主要方法

-
词典元素的遍历
与其他组合类型一样,字典可以通过for…in语句对其他元素进行遍历,基本语法结构:for<变量名>in<字典名>/keys()/values()/items():语句块

数据结构ndarray
-
数据对象ndarray
(1)多维数组ndarray是一个NumPy库中定义的通用多维同类型数据容器
(2)ndarray的出现是为了弥补Python自身没有类C数组存在的问题,提高数据容器的操作效率
(3)ndarray要求所有元素的数据类型必须一致
(4)NumPy会自动识别ndarray中的数据类型,如果数据类型不一致NumPy会将所有元素自动转换成一个合适的数据类型
(5)可以为ndarray指定类型

-
生成ndarray数组对象
(1)array()函数可以接收任意的序列型对象,如:np.array([1,2,3,4,5])和np.array([[1,2],[3,4],[5,6]])
(2)常用生成函数
zeros()函数

ones()函数
arange()函数:内置range()函数的数组版
empty()函数:创建没有初始化数值的数组
(3)生成高维数组常用生成函数
直接给生成函数传递一个合适的元组
低维数组进行reshape操作
-
ndarray的基本属性
(1)ndim属性:表示数组的维度
(2)shape属性:表示每个维度的数量(元组)
(3)dtype属性:描述数组元素的数据类型
(4)Itemsize属性:表示单个元素的大小(字节)
(5)size属性:表示数据量的大小 -
ndarray的基本方法
(1)reshape(shape),返回一个新数组,原数组不变
(2)flatten(),降为一维数组,原数组不变
(3)resize(shape),修改原数组
(4)tolist(),将数组转换为列表 -
数组的索引和切片
(1)一维数组索引,如arr[3],获取特定位置的元素
(2)二维数组索引,如arr2d[0][2]或arr2d[0,2]
(3)多维数组索引,如arr3d[1,2,3]
(4)各维度分别切片arr[m:n:k],左闭右开,从左到右依次为起点,终点和步长
(5)对多维数组的切片赋值时,整个切片都会被重新赋值

-
数组的切片
(1)不同于Python的列表,数组的切片是原数组的视图而非拷贝,任何对视图的修改都会反映到原数组上(原因:大数据的效率)
(2)需要拷贝时,应显式复制数组,如arr[5:8].copy()
(3)分析数组的切片:arr=np.arange(9).reshape((3,3))行列切片重叠区
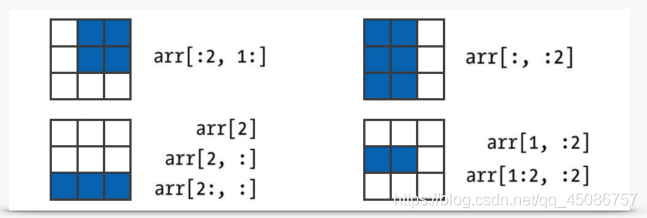

数据结构Series
- Series数据结构对象
(1)Series是在Pandas库中出现的数据结构,是用于科学计算
(2)每个Series对象实际上都有两个相互关联的数组组成,其中主数组用来存放数据。主数组的的每个元素都有一个与之相关联的标签,这些标签存储在另外一个叫做Index的数组中
(3)如果不指定索引,默认生成的索引是0到N-1
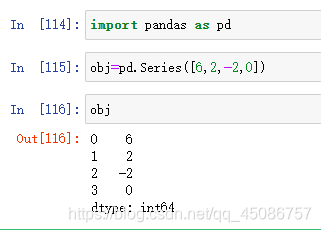
(4)通过Series对象的values和index属性分别获取对应的值和索引

-
带自定义索引的Series对象
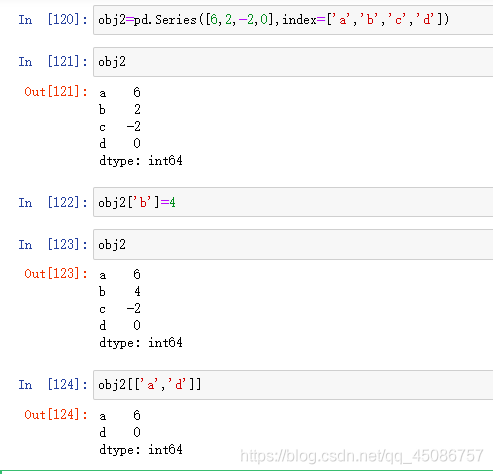
(1)obj2=pd.Series([6,2,-2,0],index=[‘a’,‘b’,‘c’,‘d’])
(2)通过使用索引来获取和设置对应的值
(3)默认索引和自定义索引均可,但不可混合使用
(4)通过索引和切片摘取出来的数据依然是Series对象
-
创建Series的方法
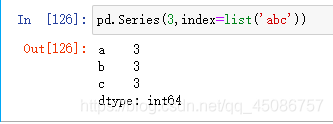
(1)利用实数,如pd.Series(3,index=list(‘abc’))
(2)利用列表,如pd.Series(list(‘Hello’))

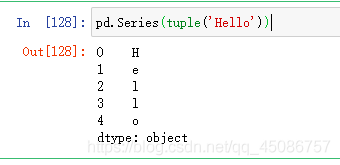
(3)利用元组,如pd.Series(tuple(‘Hello’))
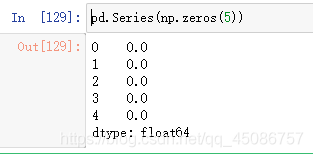
(4)利用ndarray数组,如pd.Series(np.zeros(5))
(5)利用字典,如pd.Series({‘name’:‘Diego’,‘age’:12})
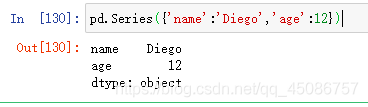
-
Series与字典
(1)Series不仅可以从字典创建,也可以认为Series是一个长度固定且有序的字典
(2)Series将索引值和数据值按位置配对
(3)在使用字典的上下文中都可以使用Series,如obj['b’为3]
(4)通过字典生成Series,默认自动排序,也可以指定索引顺序
(5)obj=pd.Series({‘e’:5,‘b’:3,‘f’:4},index=[‘a’,‘b’,‘e’])
(6)没有数据的补NaN,如a
(7)没有索引的排除,如f
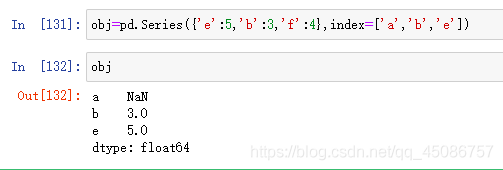
-
Series对象属性
(1)Series的name属性
(2)索引的name属性

(3)索引值也可以通过赋值方式改变
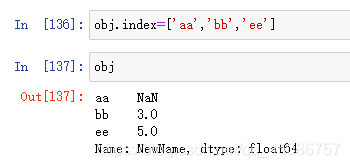
- Series对象的NumPy风格操作
(1)Series对象本质上是一个NumPy的数组,因此NumPy的数组处理函数可以直接对Series进行处理
(2)使用布尔值数组进行过滤
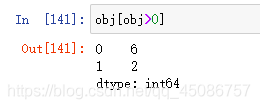
(3)与标量相乘
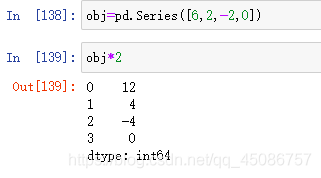
(4)应用数学函数

(5)索引值不会参与运算
数据结构DataFrame
-
数据结构:DataFrame对象
(1)DataFrame在Pandas中用于表示矩阵数据
(2)DataFrame包含了已排序的列集合
(3)每一列可以是不同的值类型(数值、字符串、布尔值等)
(4)DataFrame可以理解为一个共享相同索引的的字典
(5)DataFrame既有行索引index,也有列索引columns -
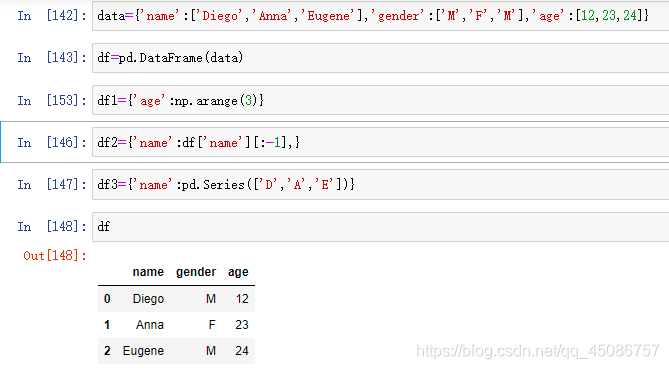
如何构建DataFrame
利用包含等长度列表/NumPy数组/Series的字典
-
用嵌套字典构建DataFrame
用嵌套字典构建DataFrame时,Pandas将字典的键作为列索引,将内部字典的键作为行进行索引

-
检索DataFrame
(1)若DataFrame数据量太大,可以用df.head()筛选出最前面的五行
(2)选择一列
类似字典的标记,如df[‘name’](任意列名)
列名为属性,如df.name(列名是有效的Python变量名)
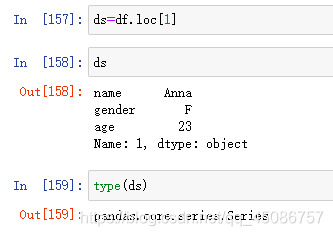
(3)选择一行,可以使用loc属性返回一个Series对象。如df.loc[1],其索引的名字即为当前的列索引“1”,索引名字为各列的名字
-
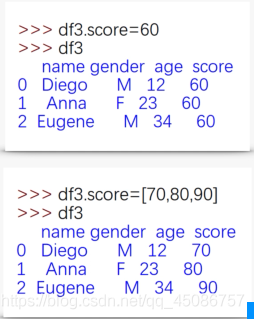
通过列修改数据
(1)标量值
(2)值数组(长度必须匹配)
(3)Series对象(其索引按DataFrame的索引重新排列,空缺处填充NaN)

- 重新索引
(1)重新索引方法reindex()
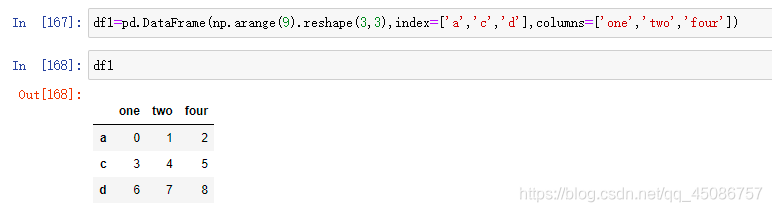
(2)默认对行进行重新索引,如

(3)可以同时对列和行进行索引,如
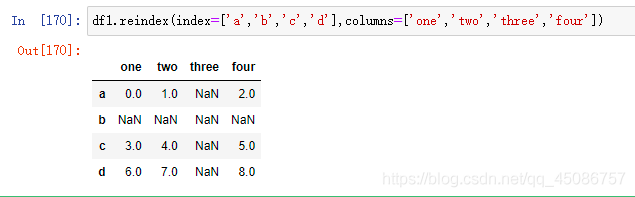
(4)缺失值自动用NaN填充
(5)使用参数fill_value=n,用n代替缺失值
- 索引对象
(1)索引对象用于存储轴标签和其他元数据
(2)用pd.index()生成索引对象,或从Series和DataFrame的行列索引
labels=pd.index(np.arange(3))
labels=df.index或labels=df.columns
obj=pd.Series([1.3,-3.4,0],index=labels)
(3)同一个索引对象可以被不同数据结构共享
(4)索引对象不可变(只读)
(5)索引对象是一个容器,可以使用in或not in进行元素判断
三、Python大数据基础之数据交换、加工和展示
3.1数据交换
CSV和EXCEL数据交换
-
CSV文件格式
(1)CSV这种文件格式经常用来作为不同程序之间的数据交互的格式
每条记录占一行,以逗号为分隔符
逗号前后的空格会被忽略
字段中包含有逗号,该字段必须用双引号括起来
字段中包含有换行符,该字段必须用双引号括起来
字段中包含有空格,该字段必须用双引号括起来
字段中的双引号用两个双引号表示
字段中如果有双引号,该字段必须用双引号括起来
第一条记录可以是字段名 -
手动处理CSV文件
(1)使用Python的open函数读入CSV文件
(2)使用readlines()方法全部读入一个列表中,处理行尾的回车符
(3)使用字符串的split()进行切割,得到切割后的列表
with open('print.csv','r')as fr:
ls=[]
for line in fr:
line=line.strip()
ls.append(line.split(','))
print(ls)
- 1
- 2
- 3
- 4
- 5
- 6
- 使用CSV标准库
使用CSV标准库的优势
除了逗号,还有其他可以代替的分隔符:‘|‘和’\t‘很常见
有些数据会有转义字符序列,如果分隔符出现在一块区域内,则整块都要加上引号或者在他之前加上转义字符
文件可能有不同的换行符,Unix系统的文件使用’\n‘,Microsoft使用’\r\n‘,Apple之前使用’\r‘而现在使用’\n‘
在第一行可以加上列名
- 使用CSV库读写文件
(1)列表与CSV
import csv
keys=['a','b','c','d']
data=[[1,2,3,4],[5,6,7,8],[9,10,11,12]]
with open('data.csv','w',newline='')as file:
writer=csv.writer(file)
writer=writerow(keys)
# writer=writerows(data)一次写入多个
for row in data:
writer.writerow(row)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
with open('data.csv','r')as file:
reader=csv.reader(file)
for row in reader:
print(row)
- 1
- 2
- 3
- 4
(2)字典与CSV
data=[{'a':1,'b':2,'c':3},{'a':4,'b':5,'c':6},{'a':7,'b':8,'c':9}]
fieldnames=['a','b','c']
with open('data.csv','w',newline='')as file:
writer=csv.DictWriter(file,fieldnames=fieldnames)
writer.writer.writeheader()
writer.writerows(data)
- 1
- 2
- 3
- 4
- 5
- 6
(3)提取某行数据
data=[]
with open('data.csv','r')as file:
reader=csv.DicReader(file)
fieldnames=reader.fieldnames
print(fieldnames)
for row in reader:
data.append(dict(row))
print(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
读取EXCEL文件
(1)导入读取Excel库:import xlrd
(2)打开文件:data=xlrd.open_workbook(‘excel.xls’)
(3)获取工作表
通过索引顺序获取:table=data.sheets()[0]
通过索引顺序获取:table=data.sheet_by_index(0)
通过名称获取:table=data.sheet_by_name(u’Sheet1’)
(4)获取行列数据:table.row_values(i)或table.col_values(i)
(5)获取行数和列数:table.nrows和table.ncols
(6)获取单元格:table.cell(2,3).value -
写入Ecxcel文件
(1)加载模块:import xlwt
(2)创建:workbook:workbook=xlwt.Workbook(encoding=‘ascii’)
(3)创建表:worksheet=workbook.add_sheet(‘My Worksheet’)
(4)在单元格写入数据:worksheet.write(0,0,‘53.6’)
(5)保存数据:workbook.save(‘Excel_Workbook.xls’)
(6)一般处理数据时不建议直接操作excel,可以通过pandas的excel读取写入函数进行处理
(7)对于特殊的excel文件,或者需要生成Excel格式报告,可以花时间和精力研究如何更好的使用xlrd和xlwt库
json和xml数据交换
-
JSON格式
(1)JavaScript Object Notation(JSON)是源于JavaScript的当今很流行的数据交换格式,它是JavaScript语言的一个子集,也是Python合法可支持的语法
(2)简洁和清晰的层次结构使得JSON成为理想的数据交换语言。易于人阅读的编写,同时也易于机器解析和生成,并有效地提升网络传输效率
(3)Json采用完全独立于编程语言的文本格式来存储和表示数据
数据在名称/值对中
数据由逗号分隔
花括号保存对象
方括号保存数组 -
将Python数据结构转换为JSON
(1)可以将字典转化为JSON来发送,一般使用JSON库的dumps()方法
(2)data_json的类型为str(注意引号):’{“name”:“Nick”,“age”:20}’
(3)data_json为转换后的JavaScript对象,其key值默认为字符串格式
(4)data_json中的key的顺序与data字典中key的顺序不保证相同
(5)data还可以是str,list,tuple,int或对象等其他类型 -
将JSON转化为Python内置数据结构
(1)将JSON转化为Python的字典时,可以使用JSON库的loads()方法
(2)data=json.loads(data_json)
(3)data中的字符串默认均为unicode,JSON规定的编码为UTF-8
(4)对于文件的JSON处理,应使用dump()和load() -
Python与JSON类型转换

-
XML文件格式
(1)XML指可扩展标记语言
(2)XML被设计用来传输和存储数据
(3)XML是一套定义语义标记的规则,这些标记将文档分成许多部件,并对这些部件加以标识
(4)他也是元标记语言,即定义了用于定义其他与特定领域有关的、语义的、结构化的标记语言的句法语言 -
Python解析XML的方法
(1)SAX(simple API for XML):Python标准库包含SAX解析器,SAX用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件
(2)DOM(Document Object Model):将XML数据在内存中解析成一个树,通过对数的操作来操作XML
(3)ElementTree(元素树):ElementTree就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度快,消耗内存少(首推方法)
- 优先使用ET解析
import xml.etree.ElementTree
(1)ET提供了两个对象:ElementTree将整个XML文档转化为树,Element则代表着树上的单个节点。对整个XML文档的交互(读取、写入、查找需要的元素),一般是在ElementTree层面进行的。对单个XML元素及其子元素,则是在Element层面进行的。
将XML文档解析为树(tree)tree=ET.ElementTree(file=‘docl.xml’)
查找需要的元素for elem in tree.iter(tag=‘branch’):
支持通过XPath查找元素
(2)构建XML文档比较复杂,目前XML的应用场景逐渐被JSON取代(仅作了解即可)
Web数据交换
-
Web数据获取的形式
(1)第三方封装库,如Tushare,可以直接返回DataFrame对象
(2)各类API网站,返回JSON格式文件或字符串,通过简单爬虫获取
(3)普通静态Web页面,需要爬虫抓取并自行摘取数据
(4)动态页面中的数据往往是由JavaScript脚本根据用户交互的不同而动态生成普通的爬虫无法提供这种交互能力,在无真实用户交互的情况下,需要使用代码控制浏览器环境,模拟用户输入,从而才能得到所需数据 -
使用tushare财经库
(1)如果尝试分析金融大数据,可以使用TuShare三方库工具
(2)该三方库通过重新清洗公开免费的财经数据,提供了方便快捷的接入方式
(3)import tushare as ts
(4)Dir(ts)查看相关信息
(5)用help查看help(ts.get_gdp_year)
(6)data=ts.get_gdp_year()
(7)Tushare返回的数据格式是DataFrame
(8)可以使用索引、切片等各种方法进行数据选择和处理
(9)保存到数据库、本地CSV文件等
(10)data.to_csv(“gdp.csv”)或Data.to_excel(“gdp.csv”)
(11)通过dir(data)可以查看DataFrame的输出方法
(12) -
使用网站API接口
一些网站如豆瓣、百词斩等网站,提供API接口,根据用户查询信息,提供JSON格式的字符串或文件 -
从JSON串获取数据
(1)Requests库的json()方法可以直接生成一个字典
(2)即可按照字典的方法进行数据处理

-
普通静态页面数据获取
(1)通过requests库,可以很方便的获取静态页面数据
(2)Requests库只负责爬取页面数据转换成字符串,不负责解析
(3)BS4库是一个解析和处理HTML和XML的第三方库
(4)from bs4 import beautifulsoup -
通过bs4库查找需要的数据
(1)创建的BeautifulSoup对象是一个树形结构,它包含HTML页面里的每一个Tag(标签)元素,如、等
(2)通过BeautifulSoup的find()和find_all()方法遍历整个HTML文档
(3)通过tag对象的name、attrs和string属性获取相应内容

-
爬取动态网页内容
(1)动态网页与静态网页不同,一般是JavaScript由代码根据用户交互的不同,动态产生页面数据
(2)Selenium是一个原本用于测试的自动化程序,可以用于操控无头浏览器产生正式的浏览器环境
(3)需下载对应的driver,如chrome下chromedriver
3.2数据加工和展示
用Python加工数据
- 缺失值NaN
(1)数据缺失在很多数据中存在,是首先要解决的常见问题
(2)NaN(Not a Number)在NumPy中是浮点值,易检测
(3)Python的None关键字在数组中也被作为NaN处理
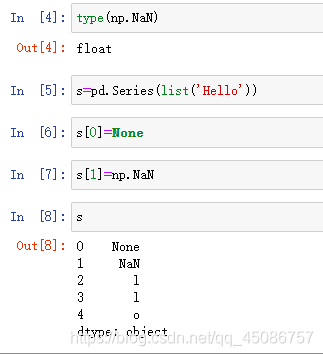
(4)补全空值:fillna()
-
判断是否存在空值
(1)Series和 DataFrame均可使用该方法
(2)判断是否为空值:isnull()或notnull()方法

-
过滤空值dropna()
(1)Series过滤空值
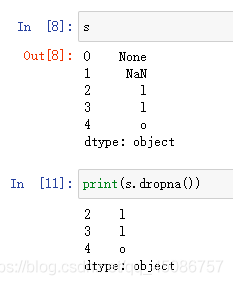
(2)DataFrame过滤空值时,dropna()默认会删除包含缺失值的行
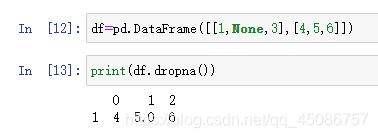
(3)传入how='all’参数时,删除所有值均为NaN的行
(4)传入axis=1,可以按照同样的方式删除列
-
补全空值
(1)Dropna()简单粗暴,抛弃了其他非空数据
(2)可以采取补全数据的方式,如fillna()
常数补全,如fillna(0)
字典补全,为不同的列设置不同的填充值,字典的键就是列的索引名,如fillna({1:0.5,2:0})
(3)fillna()返回一个新对象,或设定inplace=True修改原对象,如df.fillna(0,inplace=True)
(4)空值补全可能会污染数据
和reindex的插值方法一样,如前向填充,如fillna(method=“ffile”,limit=2)
将Series的平均值或中位数填充NaN,如data.fillna(data.mean()) -
删除重复值
(1)由于各种原因,DataFrame中会出现重复的行
(2)duplicated()用于判断某行是否重复,返回一个Series对象
(3)drop_duplicates()返回不重复的值
(4)可以指定特定列,如:drop_duplicates([‘K1’])

-
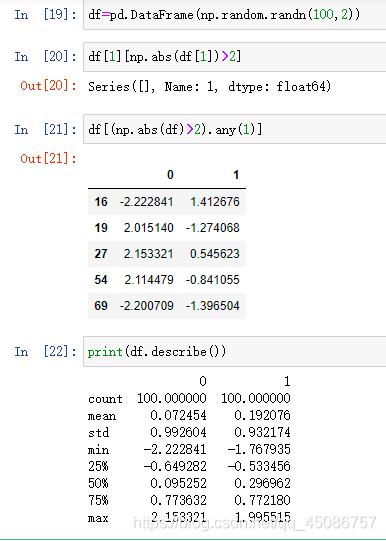
检测和过滤异常值
(1)异常值(outlier)的过滤或变换运算在很大程度上其实就是数组运算
(2)df=pd.DataFrame(np.random.randn(100,2))
(3)找出一列中绝对值大于2的值:df[1][np.abs(df[1])>2]
(4)使用any方法选出全部满足条件的行:df[(np.abs(df)>2).any(1)]
(5)一行中有1个数据满足即可
-
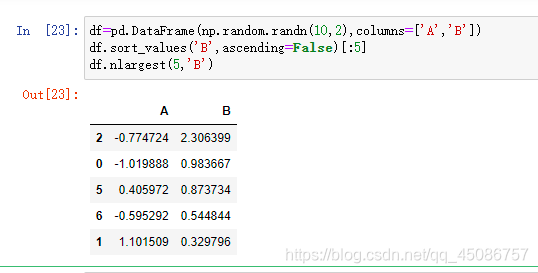
数据排序
(1)Sort_index()在指定轴上对索引排序,默认升序,默认0轴(行)
(2)Sort_values()在指定轴上根据数值进行排序,默认升序
(3)NaN排序末尾(最大或最小)
df=pd.DataFrame(np.random.randn(10,2),columns=[‘A’,‘B’])
df.sort_values(‘B’,ascending=False)[:5]
df.nlargest(5,‘B’)
(4)取前n行最大值Nlargest()
-
数据替换
(1)使用fillna填充空值是通用值替换的特殊例子
(2)不同的数据源,对控制标识不同,如-999标识空值
(3)单值:Df.replace(-999,np.NaN,inplace=True)
(4)列表:Df.replace([-999,-1000],np.NaN)
(5)列表对:Df.replace([-999,-1000],[np.NaN,0])
(6)字典:Df.replace({-999:np.NaN,-1000:0}) -
其他数据处理能力
(1)Pandas的数据处理功能非常强大
离散化和分箱
计算指标和虚拟变量
置换和随机抽样
分层索引
链接、重塑与透视
用Matplotlib展示数据
-
Matplotlib绘图
(1)Matplotlib是和numpy,pandas配合使用的一个非常优秀的第三方库
(2)Matplotlib用于在python环境下进行Matlab风格的绘图
(3)在数据分析和处理中,把数据可视化也是一个主要手段,如在发现数据异常值时,通过散点图就可以非常容易的看出哪些数据过于分散
(4)import matplotlib.pyplot as plt -
Matplotlib入门
(1)只需要一条语句即可绘图
(2)plt.plot(range(10))
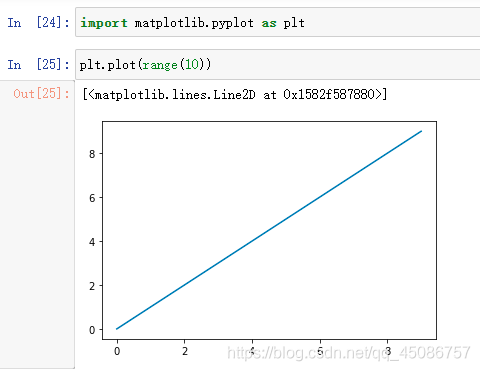
(3)plt.plot([x],y,[format],…)
(4)x和y为序列类型

-
控制字符串
(1)一次包括:颜色字符、风格字符和标记字符,如“go–”
颜色:r、g、b等,或数字格式#008080
风格:-、–、-.、|(实线、虚线、点画线等)
标记:.、,、v、<、>等
(2)也可以使用显示表达
color=‘g’
linestyle=‘dashed’
marker=‘o’
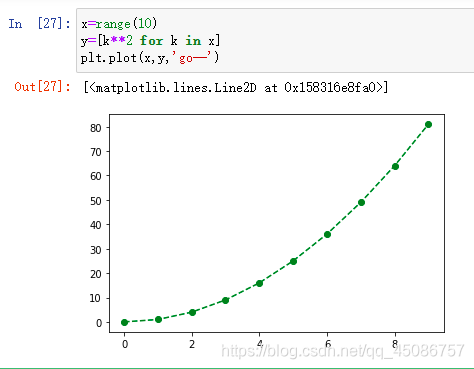
-
图形文本显示
(1)设置标题:title()
(2)图里标注:label
(3)X轴标注:xlabel()
(4)Y轴标注:ylabel()
(5)文本信息:text()
(6)默认不显示汉字,如果要显示汉字需要设置fontproperties参数
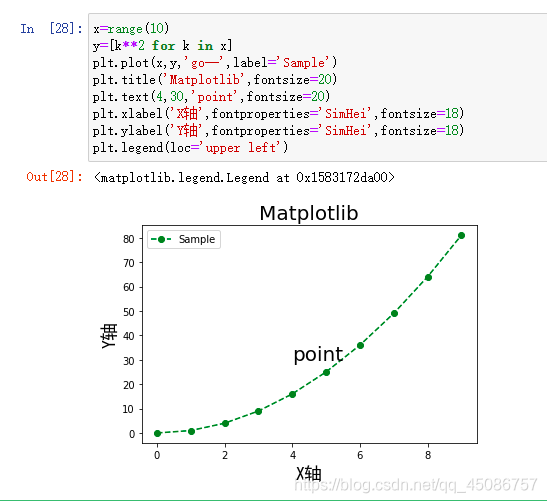
-
多线绘制
(1)plot([x],y,[fmt],[x2],y2,[fmt2],…,**kwargs)
X,x轴数据,可省略
Y,y轴数据,不可省略
fmt格式控制字符,可省略
多组数据
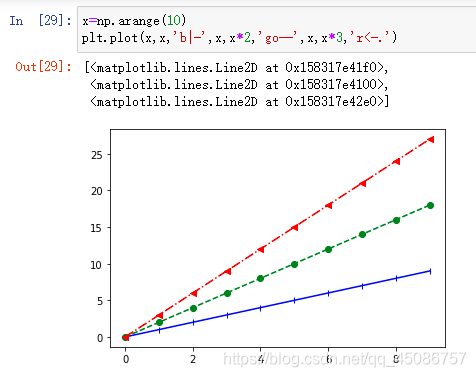
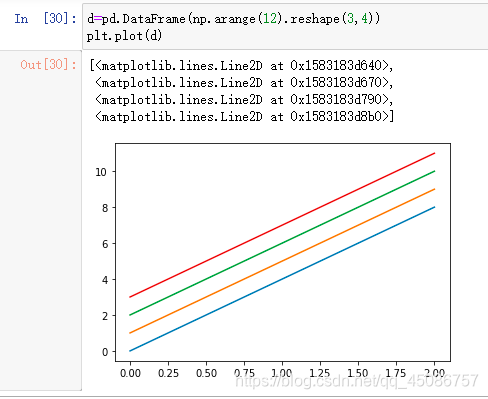
-
多子图绘制subplot
(1)plt.subplot(rows,cols,number)
(2)行列和当前正在绘制的编号
(3)编号从左到右,从上到下,行优先(可以看到右图的Y轴范围并不止限制于实数,所以说Matplotlib非常强大)
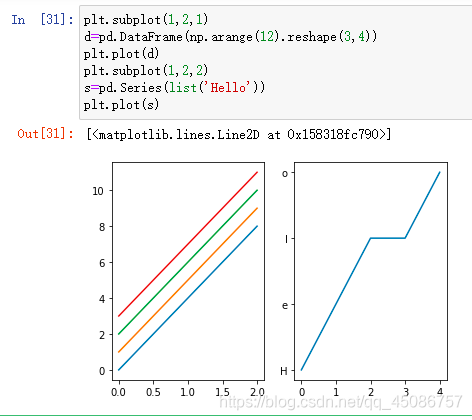
-
多子图绘制subplots
(1)使用subplots进行多图绘制
(2)fig,ax=subplots(rows,cols)
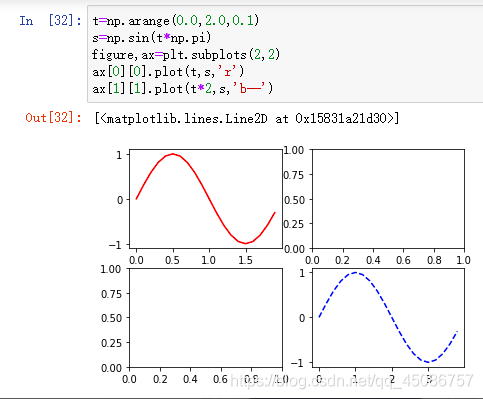
-
不同绘图风格
(1)饼状图、柱状图、散点图……
(2)箱线图、直方图、雷达图……
(3)举例饼状图



