
- 1FastDFS原理介绍及集群搭建_fastdfs集群搭建原理
- 2Python基于循环神经网络的情感分类系统设计与实现,附源码_实现一个情感分类程序,源代码
- 3web前端——源码,大学生网页设计制作作业实例代码 (全网最全,建议收藏) HTML+CSS+JS (1)_web前端期末大作业源代码
- 4oracle硬盘亮黄灯,RH2288H V3服务器硬盘亮黄灯故障处理案例
- 5【启明智显分享】Model系列工业级HMI芯片:开源RISC-V+RTOS实时系统,开放!高效!
- 6IntelliJ IDEA 中文乱码,统一设置 UTF-8 解决方案,完美解决_idea utf-8
- 7kafka个人基础教程(三)java demo kafkaStream篇_kafka streams demo
- 8java分割等和子集(力扣Leetcode416)_java 分割等和子集
- 9【项目实战】基于STM32单片机的智能小车设计(有代码)_基于stm32的智能小车四轮驱动控制系统设计
- 10Mysql 事务与Spring事务_spring事物和mysql事务
kafka(三)springboot集成kafka(1)介绍(1),腾讯大数据开发开发岗_spring kafka同步发送与异步发送
赞
踩
发送给Kafka Broker的key/value 值对,producer将待发送的消息封装进ProducerRecord实例类。
2、发送消息分区策略
(1)指定了分区:
当发送时指定了partition就使用该partition。即kafka生产者发送的消息ProducerRecord(String topic, Integer partition, K key, V value)指定了发送到哪个具体的分区。

(2)轮询
如果kafka生产者发送的消息ProducerRecord(String topic, Integer partition, K key, V value)没有指定发送到哪个具体的分区,即partition=null(并且key也为空时,如果此时key不为空的话就会采用另一种分区策略key哈希分区策略),并且使用了默认的分区器,那么消息将被随机的发送到主题的各个可用分区上,分区器使用轮询的算法将消息均衡的分布到各个分区。

(3)key哈希分区策略
根据消息的key进行哈希计算,并将消息发送到对应的分区。保证相同key的消息始终被发送到同一个分区,确保消息的顺序性。

(4)自定义分区策略(即自定义Partitioner)
用户可以根据自己的需求实现自定义的分区策略,通过实现org.apache.kafka.clients.producer.Partitioner接口来自定义分区选择逻辑。
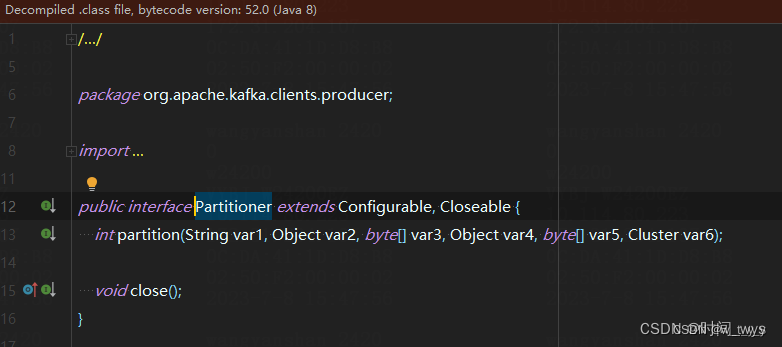
二、 KafkaConsumer
三、生产者发送消息应用
1、同步发送消息
同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回 ack。 由于 send 方法返回的是一个 Future 对象,根据 Futrue 对象的特点,我们也可以实现同 步发送的效果,只需在调用 Future 对象的 get 方发即可。
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; import java.util.concurrent.ExecutionException; public class CustomProducerSync { public static void main(String[] args) throws ExecutionException, InterruptedException { // 1. 创建kafka生产者的配置对象 Properties properties = new Properties(); // 2. 给kafka配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // key,value序列化(必须): properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // 3. 创建kafka生产者对象 KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String,String>(properties); // 4. 调用send方法,发送消息 for (int i = 0; i < 10; i++) { // 默认为异步发送 kafkaProducer.send(new ProducerRecord<>("first1", "atguigu" + i)); // 末尾加get为同步发送 kafkaProducer.send(new ProducerRecord<>("first1", "atguigu" + i)).get(); } // 5. 关闭资源 kafkaProducer.close(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2、异步发送消息
2.1、普通异步
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class CustomProducer { public static void main(String[] args) { // 1. 创建kafka生产者的配置对象 Properties properties = new Properties(); // 2. 给kafka配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // key,value序列化(必须): properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // 3. 创建kafka生产者对象 KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String,String>(properties); // 4. 调用send方法,发送消息 for (int i = 0; i < 10; i++) { kafkaProducer.send(new ProducerRecord<>("first", "wtyy")); } // 5. 关闭资源 kafkaProducer.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2.2、带回调函数的异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是 RecordMetadata 和 Exception,如果 Exception 为 null,说明消息发送成功,如果 Exception 不为 null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
import org.apache.kafka.clients.producer.*; import java.util.Properties; public class CustomProducerCallBack { public static void main(String[] args) { // 1. 创建kafka生产者的配置对象 Properties properties = new Properties(); // 2. 给kafka配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // key,value序列化(必须): // 序列化器的serialization是一个接口,找到他的实现类 // 我们一般都是使用String properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // 3. 创建kafka生产者对象 KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String,String>(properties); // 4. 调用send方法,发送消息 for (int i = 0; i < 10; i++) { kafkaProducer.send(new ProducerRecord<>("first1", "atguigu" + i), new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { //(1)消息发送成功 exception == null 接受到服务端ack消息 调用该方法 //(2)消息发送失败 exception != null 也会调用该方法 if (exception == null) { System.out.println(metadata);//使用打印演示 }else{ exception.printStackTrace();//打印异常信息 } } }); } // 5. 关闭资源 kafkaProducer.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
四、消费者接收消息应用
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; **自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。** **深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!** **因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**      **既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!** **由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新** **如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**  **一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!** 且后续会持续更新** **如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)** [外链图片转存中...(img-9LeQnEWk-1712979040660)] **一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36


