
热门标签
热门文章
- 1V字形研发模式中的测试_v字测试流程
- 2项目管理工具git_git管理工具
- 3LVGL移植到ARM开发板(GEC6818)_gec6818移植lvgl
- 4LeetCode 算法:找到字符串中所有字母异位词c++
- 5《IT 领域准新生暑期预习指南:开启未来科技之旅》
- 6在Linux系统yum安装报错Cannot find a valid baseurl for repo解决方案_error: cannot find a valid baseurl for repo: livna
- 7谷粒商城--分布式基础篇(P1~P27)_谷粒商城分布式基础篇课件
- 8在ROS中用opencv订阅摄像头图像并显示_ros2查看订阅到的图片
- 9dockerfile更改docker镜像源(1)_dockerfile指定镜像源
- 10pycorrector训练自己的模型,pycharm如何训练模型_pycharm中基于keras的模型搭建
当前位置: article > 正文
Colly 爬虫学习笔记(三)——爬虫框架,抓取动态页面数据(上证A股动态数据抓取)_colly爬虫 翻页抓取
作者:weixin_40725706 | 2024-07-11 07:23:20
赞
踩
colly爬虫 翻页抓取
Colly 学习笔记(三)——爬虫框架,抓取动态页面(上证A股列表抓取)
Colly 学习笔记(一)——爬虫框架,抓取中金公司行业市盈率数据
Colly 学习笔记(二)——爬虫框架,抓取下载数据(上证A股数据下载)
Colly 学习笔记(三)——爬虫框架,抓取动态页面数据(上证A股动态数据抓取)
前两章节主要讨论静态数据的抓取,我们只需要把网页地址栏中的url传到get请求中就可以轻松地获取到网页的数据,但是有的网页是动态页面,我们通过网页源代码无法找到数据,翻页时URL也没有改变。此时就无法抓取数据。比如 http://www.sse.com.cn/assortment/stock/list/share/ 如下图所示,通过开发者工具和查看网页源代码发现,虽然相同的URL但是内容却不一样。此时就要找到动态页面对应的URL,才可以抓取数据。
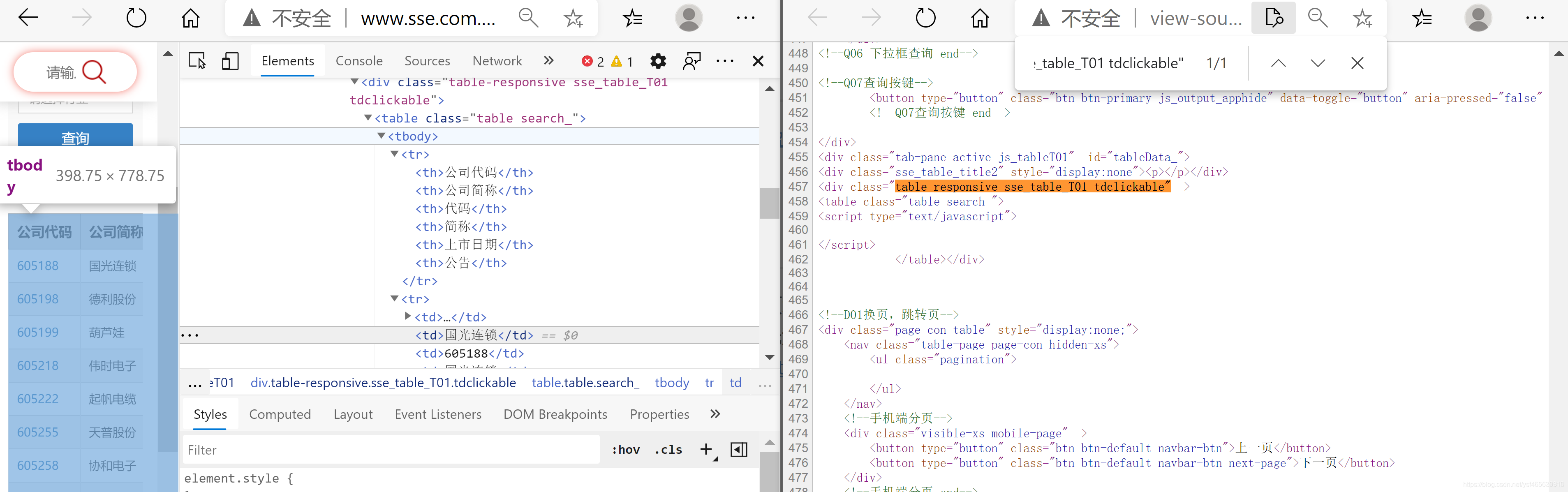
查看页面的真实URL方法如下:
- 找到通过点击分页按钮,找到对应的URL(具体步骤如图所示)
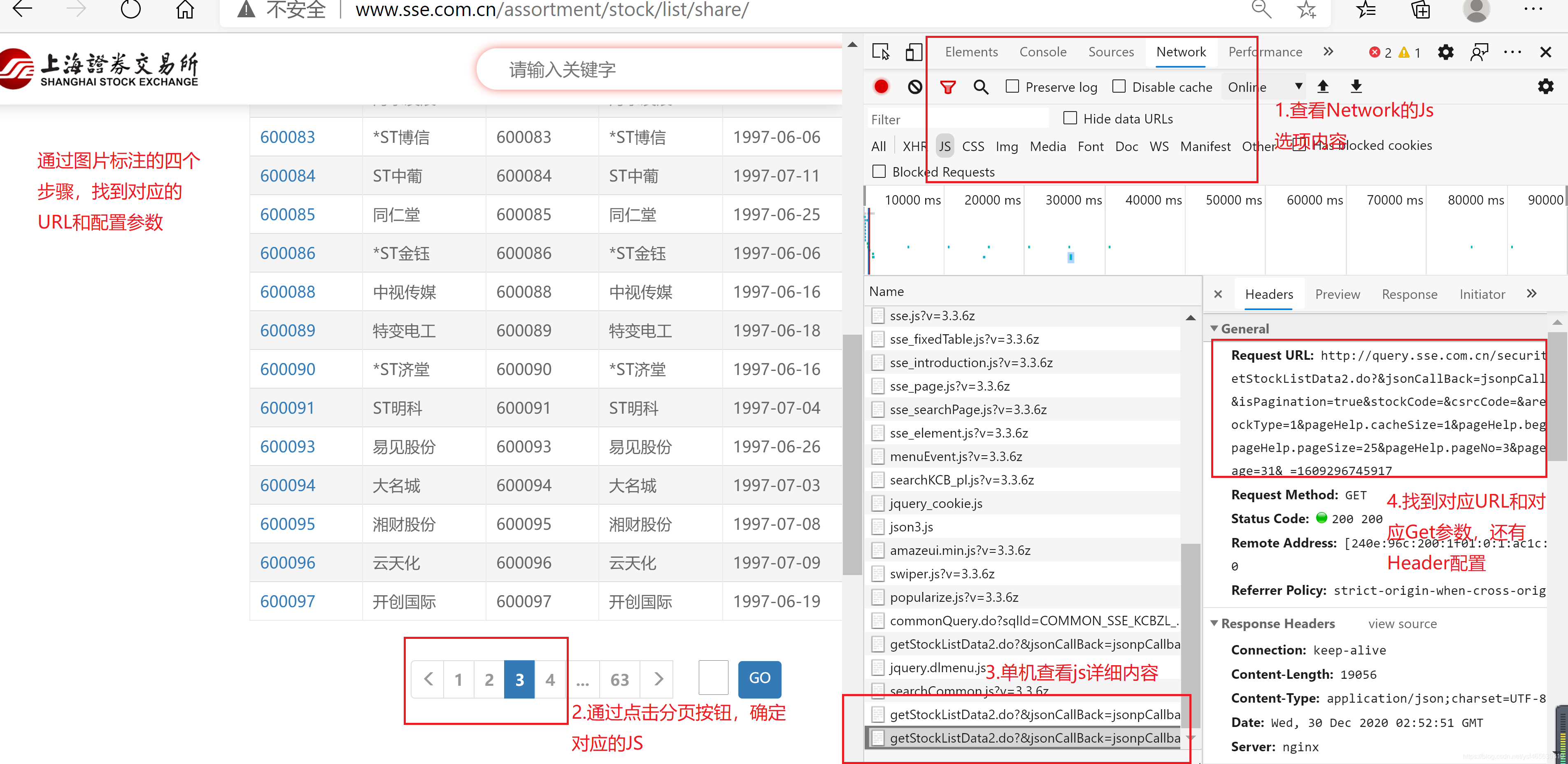
-
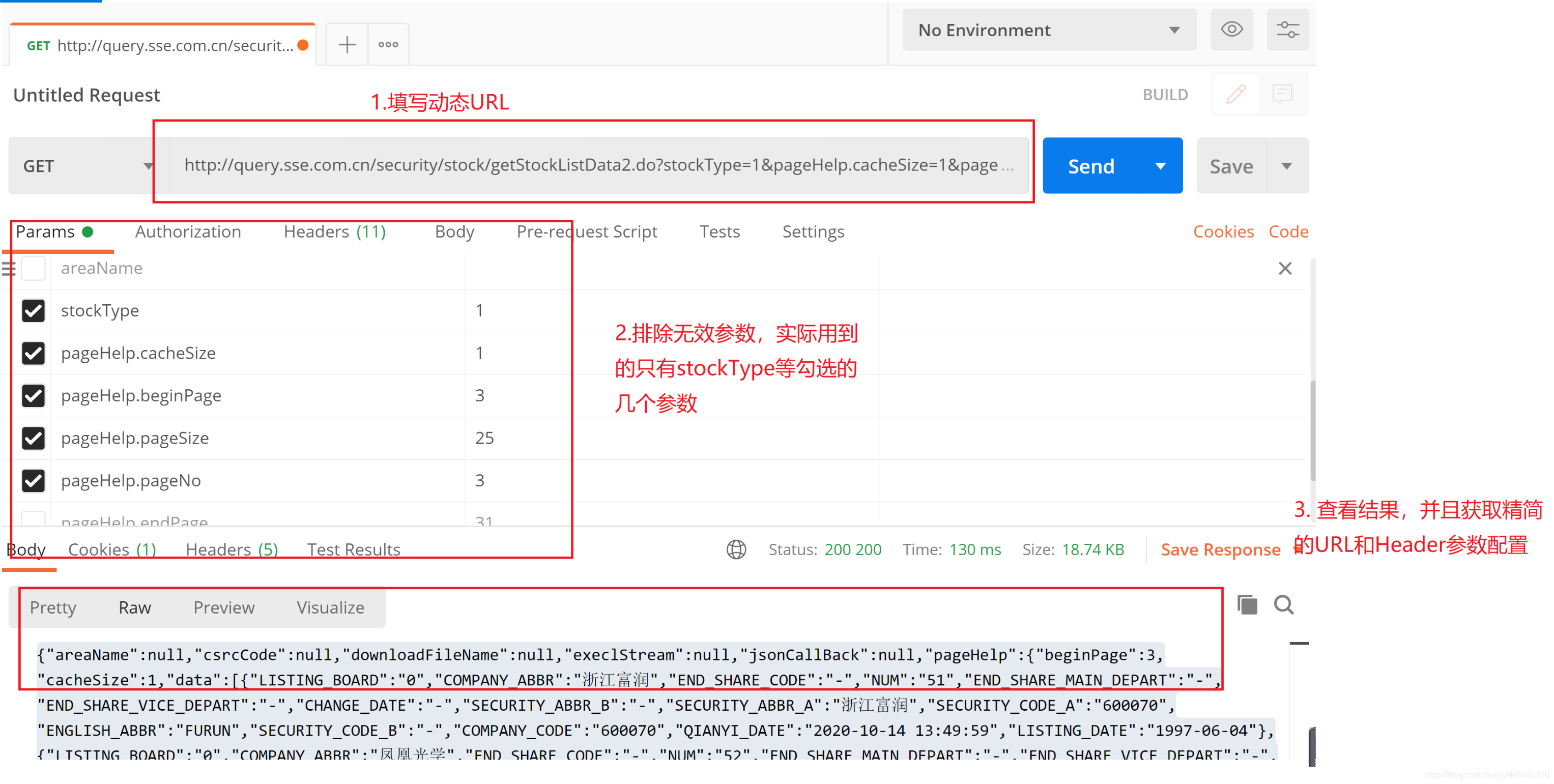
通过postman查看并排除无效参数
#动态URL原始参数 http://query.sse.com.cn/security/stock/getStockListData2.do?&jsonCallBack=jsonpCallback49711&isPagination=true&stockCode=&csrcCode=&areaName=&stockType=1&pageHelp.cacheSize=1&pageHelp.beginPage=3&pageHelp.pageSize=25&pageHelp.pageNo=3&pageHelp.endPage=31&_=1609296745917 #postman调试优化后的参数 http://query.sse.com.cn/security/stock/getStockListData2.do?stockType=1&pageHelp.cacheSize=1&pageHelp.beginPage=3&pageHelp.pageSize=25&pageHelp.pageNo=3- 1
- 2
- 3
- 4
postman查看如下图所示
- 编写colly代码抓取过程
//finish
c.OnScraped(func(r *colly.Response) {
//解析Json
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{
"err":err,"res":string(r.Body)}).Error("Receive Error ")
//若返回系统繁忙,则等一段时间重新访问- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/809196
推荐阅读
相关标签

