
- 1执子之手简约唯美的表白网站HTML源码_2022唯美执子之手表白网html源码
- 2【2022应届生看过来】一个无经验的大学毕业生,可以转行做软件测试吗?_软件测试应届没有经验
- 3[沫忘录]Golang基础类型与语法
- 4Pycharm基础——文件操作(IO)技术_pycharm文件操作
- 5智慧校园毕业管理:全面解读毕业批次功能
- 6关于高性能滤波器和普通型滤波器的区别说明
- 7【计算机网络】域名劫持无处遁形:基于HTTPDNS打造可靠且安全的域名解析体系_域名解析接口
- 8基于javaweb+mysql的ssm外卖订餐管理系统(java+ssm+jsp+jquery+ajax+mysql)_外卖系统的前后端开发技术
- 9python选择题_python:选择题系列01
- 10动态链接(ELF文件)_elf动态链接
Mysql一条查询语句的执行流程_mysql一条数据的查询过程
赞
踩
MySql一条查询语句的执行流程
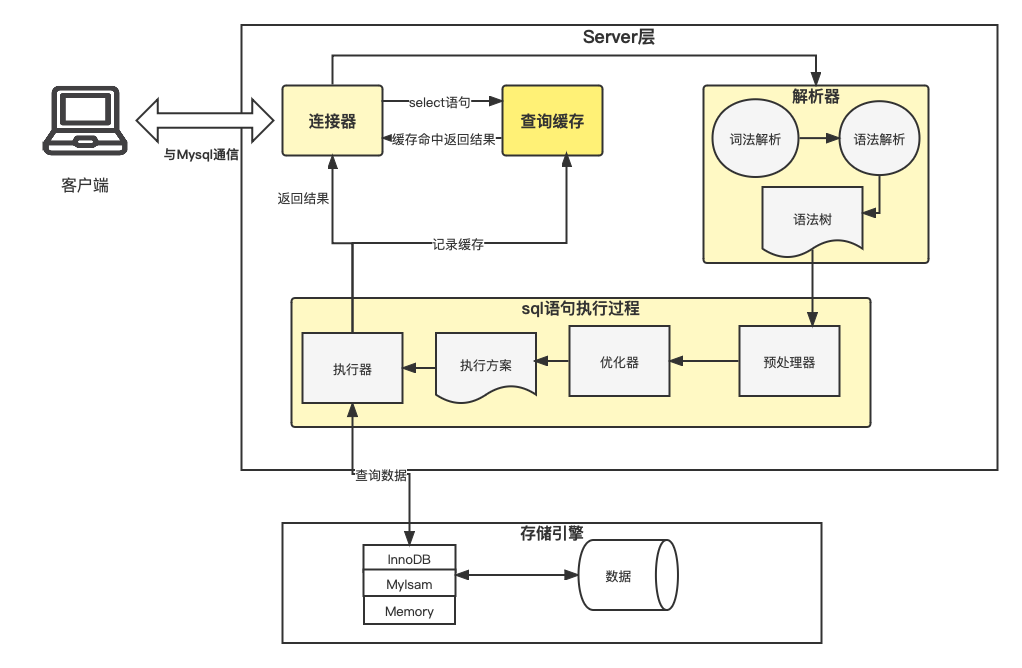
Mysql架构图
1. 连接服务器
在终端输入mysql -h服务器IP -u用户名 -p密码 连接服务器
该连接过程也是要经过HTTP协议以及TCP三次握手来与服务器建立连接
此时MySql服务器中的执行器就要验证用户名和密码来判断是否可以连接并查询用户的权限,此后的任何操作都会根据用户的权限来进行逻辑判断
(如果连接成功后服务端修改用户的权限并不会立即生效,要等到客户端下一次连接才能生效)
2. 查询缓存(query-cache)
连接成功后,因为我们执行的是一条select语句,MySql会先查询缓存,缓存中的数据是以键值的方式存储,键就是一条sql语句,值是这条sql查询出的数据。如果命中缓存则直接返回数据,如果没有命中则继续下一步操作,查询到结果后再将结果记录到缓存中
ps:看似通过缓存的方式会提高查询效率,其实不然,因为数据库每一次字段的更新都会刷新缓存。比如,有可能在把一次查询到比较大的数据放入缓存后,又数据库进行了更新那么该缓存数据就根本没有利用上,反而在这过程中增加了CPU和内存的负担。所以在MySql8.0后将查询缓存这一步删除掉了。
3. 解析sql
这一过程中解析器会根据sql语句先后进行词法分析和语法分析
词法分析: 解析器根据sql中的每个关键字生成一个语法树,便于后续操作获取该sql的种类,字段,表名,where条件等等
词法分析: 解析器会根据词法分析生成的语法树来判断该sql是否存在语法错误,比如关键词写错,子句的顺序错误等等,如果出现错误会直接返回

ps:词法分析不会判断sql语句中的表名或字段名是否存在
4.执行sql
1)预处理
预处理器有两个作用
把通配符*转换为对应的字段名
判断sql语句中的表名或字段名是否存在
2)优化sql
优化器的作用就是制定一个最优的查询方案,在有多个索引的情况下,选择执行效率最高的查询方式。
主要是对二级索引中覆盖索引问题的优化
比如有一张学生表 id是主键索引 name是二级索引
sql语句是 select id from student where id > 1 and name like ‘李%’
显然这条语句出现了覆盖索引 所以先查询二级索引找到符合条件的结点,由于二级索引的B+树的叶子结点存放的是id主键值,我们就根据二级索引树中符合条件的id来进行筛选,没有必要再进行回表了,因为查询主键索引的B+树的成本比查询二级索引B+树成本高,大大增加了查询效率
优化器就是对这一过程进行优化,判断查询哪颗索引树的查询效率最高
3)查询存储引擎
执行器就会根据优化器生成的执行方案到存储引擎中进行查询
有三种查询情况分别是
- 主键索引查询
- 全表扫描
- 索引下推
1 假如sql语句为 select * from student where id = 1
由于这是一条等值查询语句,并且主键不可能出现重复,所以优化器决定访问类型为const进行查询,通俗地说只会调用一次存储引擎的查询接口
2 假如sql语句为 select * from student where score > 80
score字段不是索引字段 那么查询器就会对student表进行while循环 调用存储引擎全表扫描的接口。每调用一次查询接口,存储引擎就会返回student表的一行记录,执行器判断该行记录的score是否大于 80如果符合条件直接返回客户端 并再次调用查询接口,直到查询到该表的最后一条记录。
3 假如sql 语句为 select * from student where age > 18 and score > 60
age和score为联合索引的情况下 由于遵循的最左前缀原则,只有age字段能利用到联合索引 score无法利用该索引
如果不使用索引下推流程如下
- 执行器调用查询接口 根据二级索引 由于最左前缀原则只会定位到符合 age > 18 的结点
- 根据二级索引查询到的ID值进行回表查询到主键索引树中的完整数据并返回
- 执行器判断该行数据中score是否大于60 如果符合条件则返回,否则跳过该记录
- 再次调用查询接口根据二级索引定位ID
- 直到读完所有记录
可以发现如果没有索引下推 二级索引中非叶子结点存储的score毫无用处,每次都要进行回表操作再将完整记录返回给执行器让执行器进行判断score是否符合条件
如果使用索引下推 判断score的过程就交给了存储引擎
- 执行器调用查询接口,根据二级索引树定位到第一个符合条件的结点,由于索引下推的规则,还会继续判断该结点中score是否大于60如果符合条件再进行回表,把完整数据返回给执行器。如果score不符合条件则跳过该结点继续查询二级索引树
可见如果使用了索引下推 虽然由于最左前缀无法使用联合索引查询,但是大大减少了回表的次数,增加了查询效率
总结
- 连接:与客户端建立连接,校验身份,管理连接
- 查询缓存:如果命中直接返回,否则继续执行下一步操作(Mysql8以后已删除该功能)
- 分析sql:进行词法分析和语法分析 构建语法树,方便后续模块读取sql类型,字段,表名等等
- 执行sql:
- 预处理器:预处理sql语句中的通配符,判断字段名和表名是否存在
- 优化器:选出最优的查询方案
- 执行器:根据优化方案循环调用存储引擎接口,对查询条件进行判断

