
- 1whoosh全文检索_whoosh全文检索阈值范围
- 2CSS设置滚动样式, 鼠标离开时滚动条隐藏_css 获取焦点显示滚动条,失去焦点隐藏滚动条
- 3阿秀朋友先后折戟腾讯、字节、快手、网易、滴滴、深信服后,终于成功上岸了...
- 4【PyCharm安装和配置(超详细版本教程),可分享!!!】
- 53D-STMN论文阅读_tgnn
- 6mysql 查看表结构数据 语句_查看表结构的sql语句
- 7python数据分析实战12_python数据分析实战---用户行为分析
- 8机器学习——降维算法PCA和SVD(sklearn)
- 9VirtualBox中的Mac系统的使用心得_mac的virtualbox怎么设置
- 10Windows11系统Windows.UI.FileExplorer.dll文件丢失问题
【Flink】基于Docker下的Flink运行环境搭建(Mac)_flink docker
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
创建一个本地运行环境是提高开发效率和便捷进行代码调试的关键。我们将一起构建一个本地环境,专门用于执行Flink任务。
此环境以Flink 1.17.2版本为基础,采用Docker技术搭建而成。通过这种方式,我们能够模拟出一个接近实际生产环境的运行条件,帮助我们更好地测试和优化我们的Flink应用。
代码链接: flink_study_notes
一、环境搭建
选择flink版本
选择自己实际应用的flink版本,本次我选择1.17.2flink版本作为演示版本。
链接: Docker-Hub-flink-1.17.2
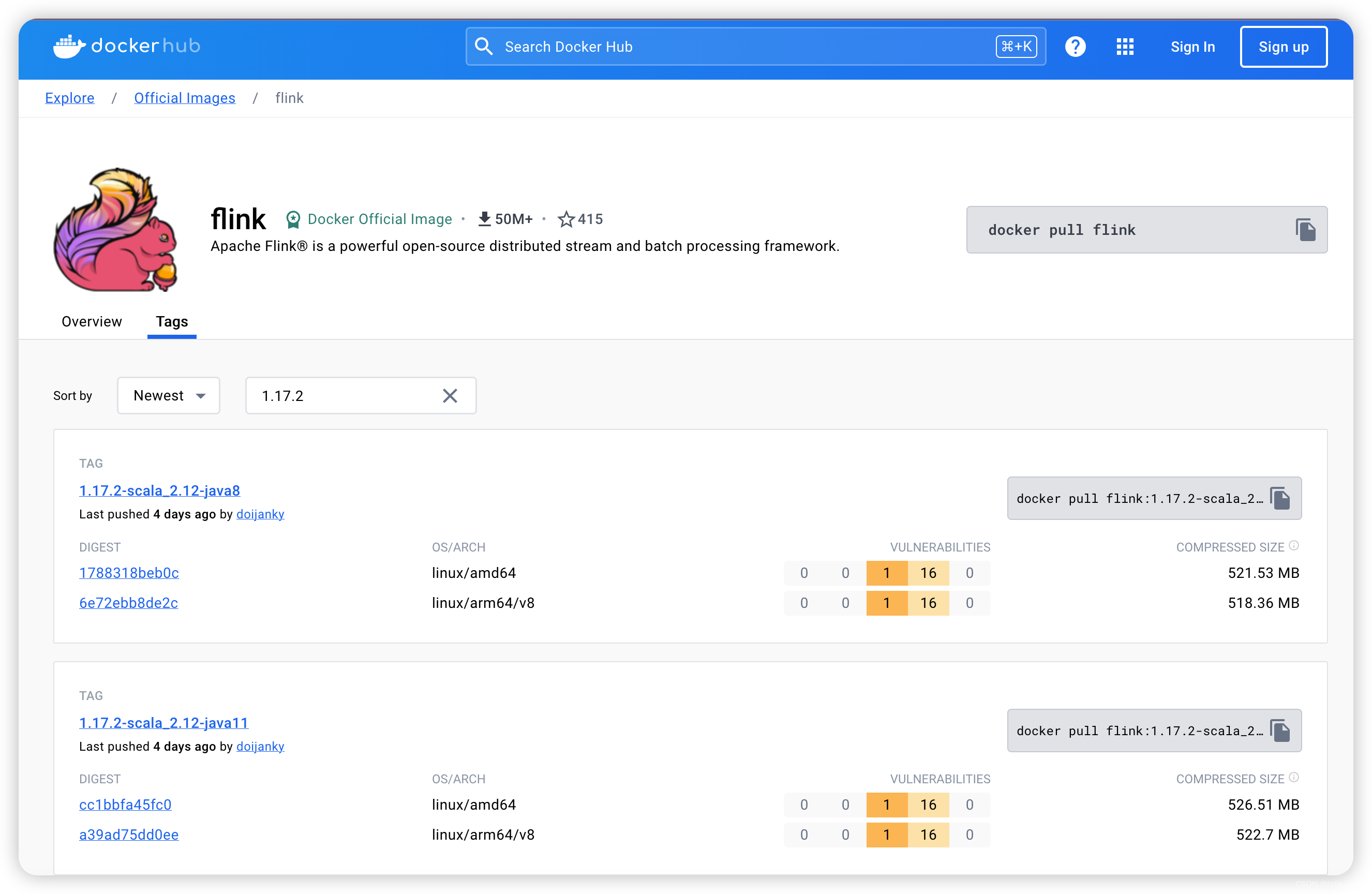
镜像说明::
- flink 1.13.0
- flink 内置 :scala 版本 2.12,Java 版本 8
配置文件准备
获取配置文件
为了轻松获得完整的配置设置,建议首先启动镜像,然后将内置的配置文件复制到外部。这一步骤将简化未来对配置的修改以及环境的快速部署。通过预先准备好配置文件,你可以避免从零开始的重复工作,并能够快速地调整和应用新的配置参数。
生成配置文件
为环境创建一个独立的网络1
使用Docker网络可以让你将多个容器连接在一起,允许容器间相互通信并组成一个隔离的网络环境,类似于在宿主机上创建一个虚拟子网。
docker network create flink-network
- 1
创建JobManager
docker run \
-itd \
--name=jobmanager \
--publish 8081:8081 \
--network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:1.17.2-scala_2.12-java8 jobmanager
- 1
- 2
- 3
- 4
- 5
- 6
- 7
创建 TaskManager
docker run \
-itd \
--name=taskmanager \
--network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:1.17.2-scala_2.12-java8 taskmanager
- 1
- 2
- 3
- 4
- 5
- 6
运行结果

命令与参数解析
这条命令在flink-network网络下以后台模式运行一个新的Flink
TaskManager容器,容器名称为taskmanager,并将作业管理器的RPC地址设置为同网络中的jobmanager容器。
- –network flink-network: 将容器连接到预先创建的网络flink-network,容器将使用该网络的配置与其他容器通信。
- –env FLINK_PROPERTIES=“jobmanager.rpc.address: jobmanager”: 设置环境变量FLINK_PROPERTIES。该变量定义了Apache
Flink的配置,jobmanager.rpc.address是指明连接到的JobManager的地址,在这里被设置为容器名称jobmanager,表示TaskManager将会连接到同一Docker网络内名为jobmanager的容器。
文件拷贝至本地
#本地创建目录
mkdir -p ~/app/flink/
#进入目录
cd ~/app/flink/
# jobmanager 容器
docker cp jobmanager:/opt/flink/conf ./JobManager/
# taskmanager 容器
docker cp taskmanager:/opt/flink/conf ./TaskManager/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
命令说明:
该命令会将名为jobmanager|taskmanager的容器的/opt/flink/conf目录中的内容复制到当前工作目录下的JobManager|TaskManager文件夹中。这样做的目的是为了方便修改Flink的配置文件。
删除容器
docker rm -f taskmanager
docker rm -f jobmanager
- 1
- 2
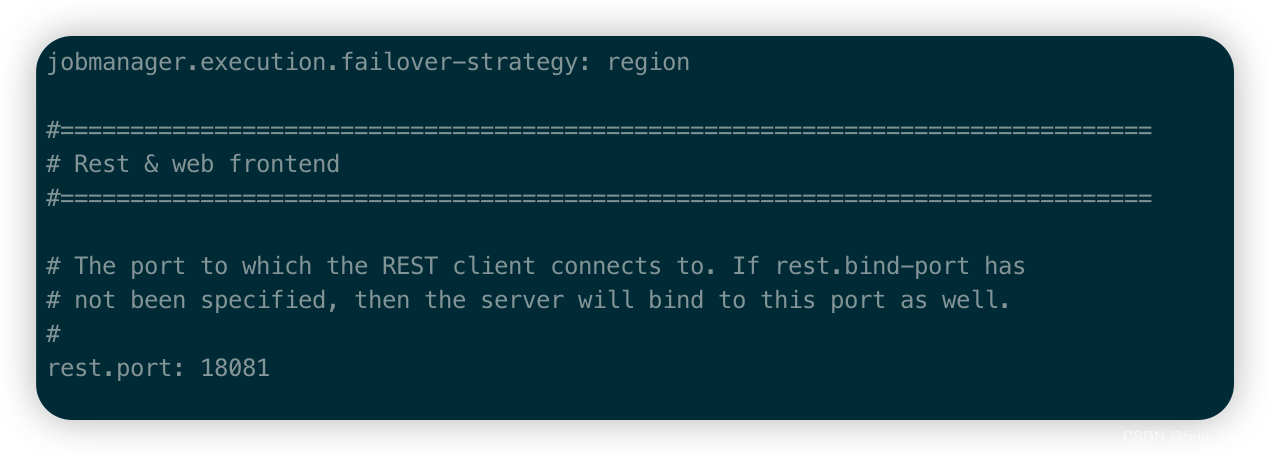
修改配置
#修改 JobManager/flink-conf.yaml web 端口号为 18081
rest.port: 18081
- 1
- 2
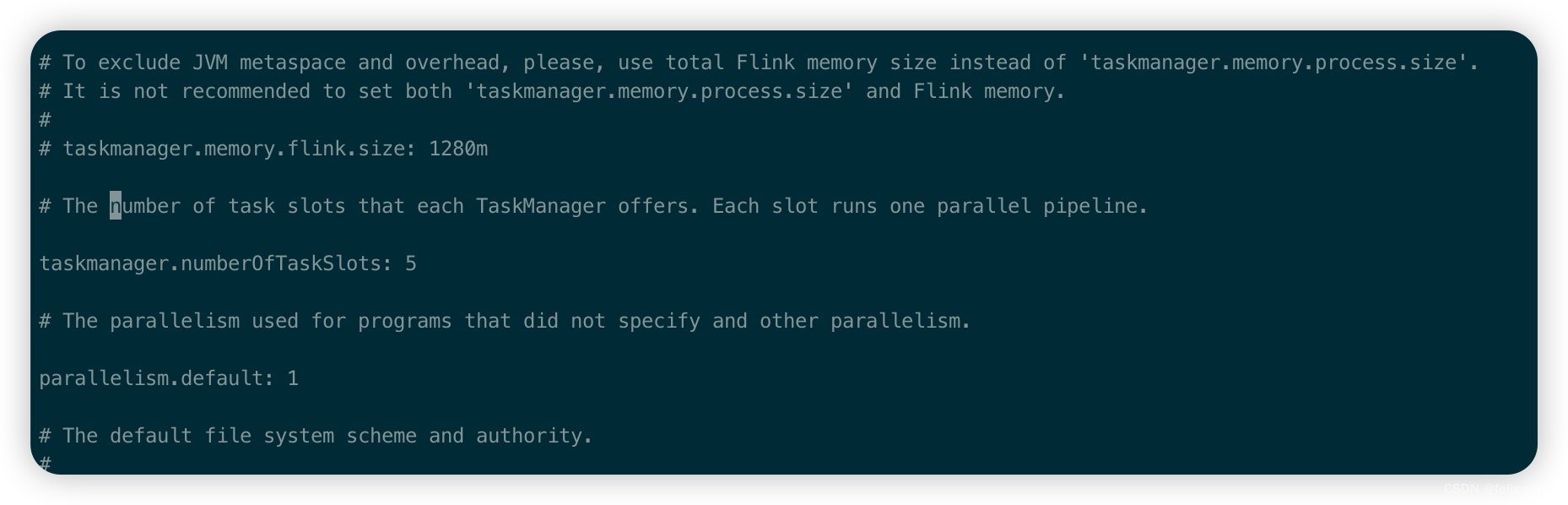
#修改 TaskManager/flink-conf.yaml 容器任务槽为 5
taskmanager.numberOfTaskSlots: 5
- 1
- 2
重新挂载并创建容器
启动 jobmanager
docker run \
-itd \
-v ~/app/flink/JobManager/:/opt/flink/conf/ \
--name=jobmanager \
--publish 18081:18081 \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
--network flink-network flink:1.17.2-scala_2.12-java8 jobmanager
- 1
- 2
- 3
- 4
- 5
- 6
- 7
启动 taskmanager
docker run \
-itd \
-v ~/app/flink/TaskManager/:/opt/flink/conf/ \
--name=taskmanager --network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:1.17.2-scala_2.12-java8 taskmanager
- 1
- 2
- 3
- 4
- 5
- 6
容器启动成功

链接: 访问地址
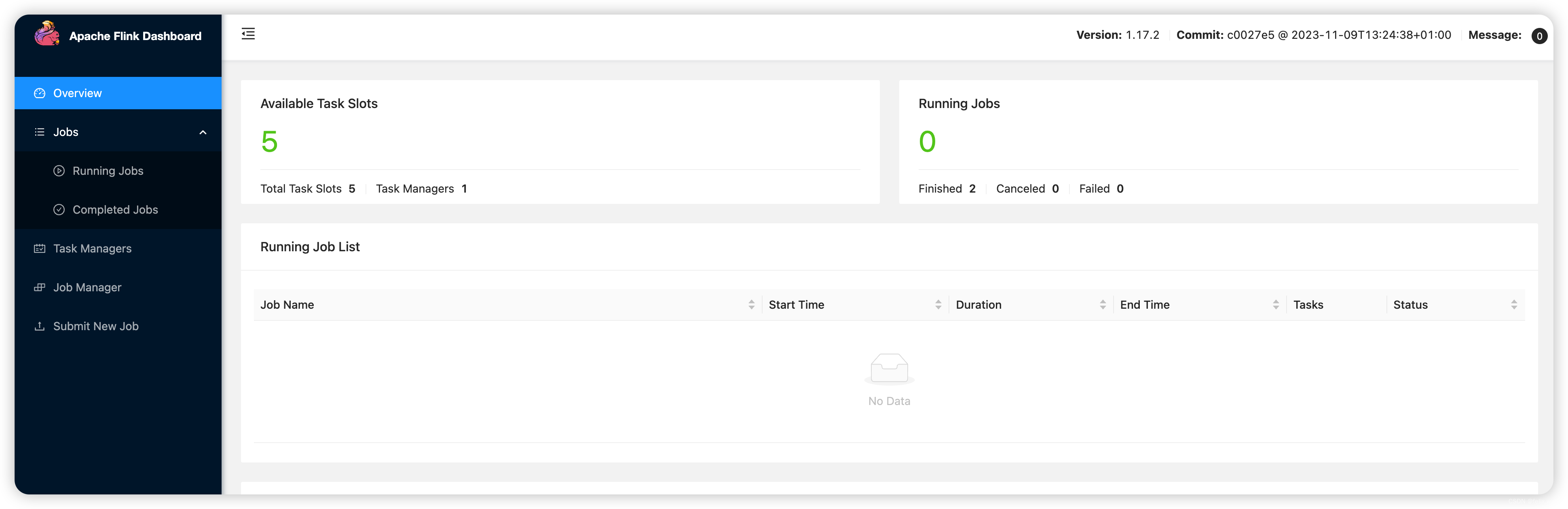
二、Flink example
官网地址: 项目配置
创建项目脚手架
maven命令:根据自己实际情况修改
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.17.2 \
-DgroupId=cn.demo \
-DartifactId=flink_study_notes \
-Dversion=0.1 \
-Dpackage=cn.demo \
-DinteractiveMode=false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
命令解释:
这个命令的功能是创建一个新的Maven项目,项目类型是Apache Flink的Java快速开始项目,项目的groupId是cn.demo,artifactId是flink_study_notes,版本号是0.1,最终项目的包路径也是cn.demo。并且在指定这些参数后,禁用了交互,所以该命令可以自动完成所有操作无需任何用户交互。
打开工程
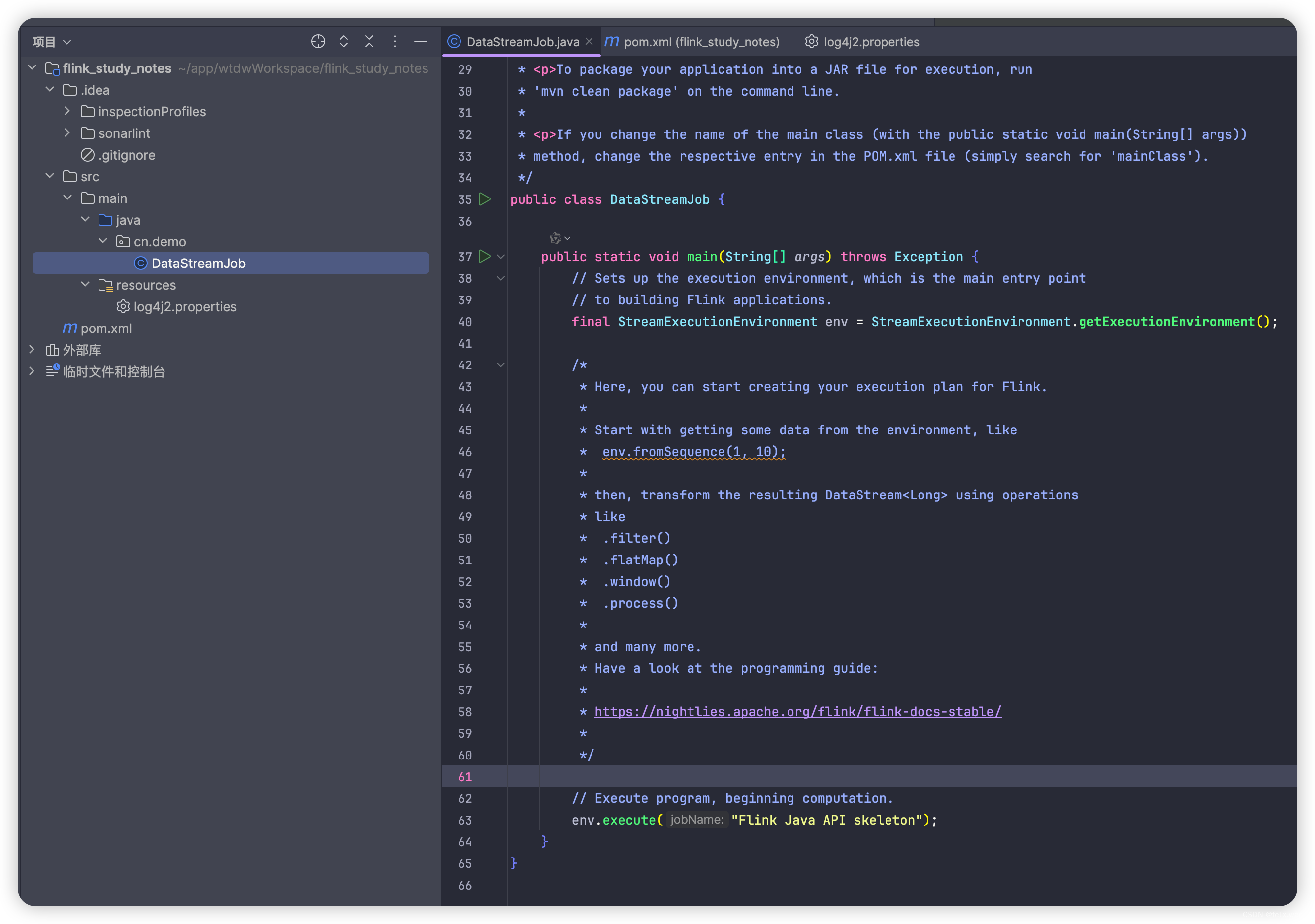
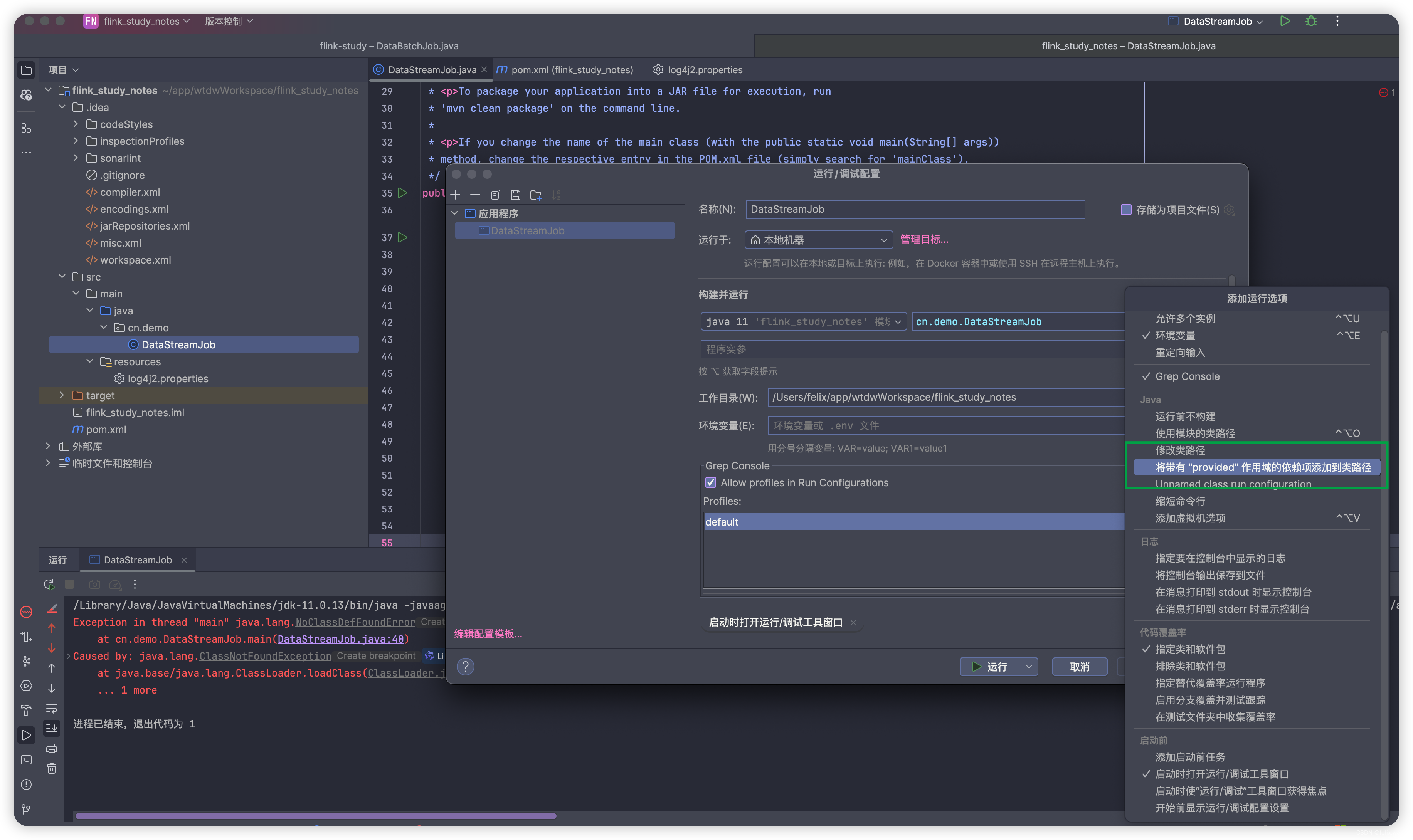
provided: 项目中provided作为默认参数,可以让你更加精确地管理你的依赖关系,在你的项目环境中提供所需的资源,而在实际运行环境中,则由运行平台或者容器来提供。但是在本地ide中运行时会有如下错误:

为了解决这个问题,我们需要在ide appliation运行配置中进行如下设置:
批处理示例
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class DataBatchJob { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> streamSource = env.fromElements("world count", "hello world", "hello flink", "flink", "hello", "hello world", "hello flink", "flink", "hello", "world"); SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String value, org.apache.flink.util.Collector<Tuple2<String, Integer>> out) throws Exception { String[] split = value.split(" "); for (String s : split) { out.collect(Tuple2.of(s, 1)); } } }); streamOperator.keyBy(value -> value.f0).sum(1).print(); env.execute("count the number of times a word appears"); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
流处理示例
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class DataStreamJob { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(3); DataStreamSource<String> socketDS = env.socketTextStream("127.0.0.1", 7777); SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS .flatMap( (String value, Collector<Tuple2<String, Integer>> out) -> { String[] words = value.split(" "); for (String word : words) { out.collect(Tuple2.of(word, 1)); } } ) .setParallelism(2) .returns(Types.TUPLE(Types.STRING, Types.INT)) .keyBy(value -> value.f0) .sum(1); sum.print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
运行结果:

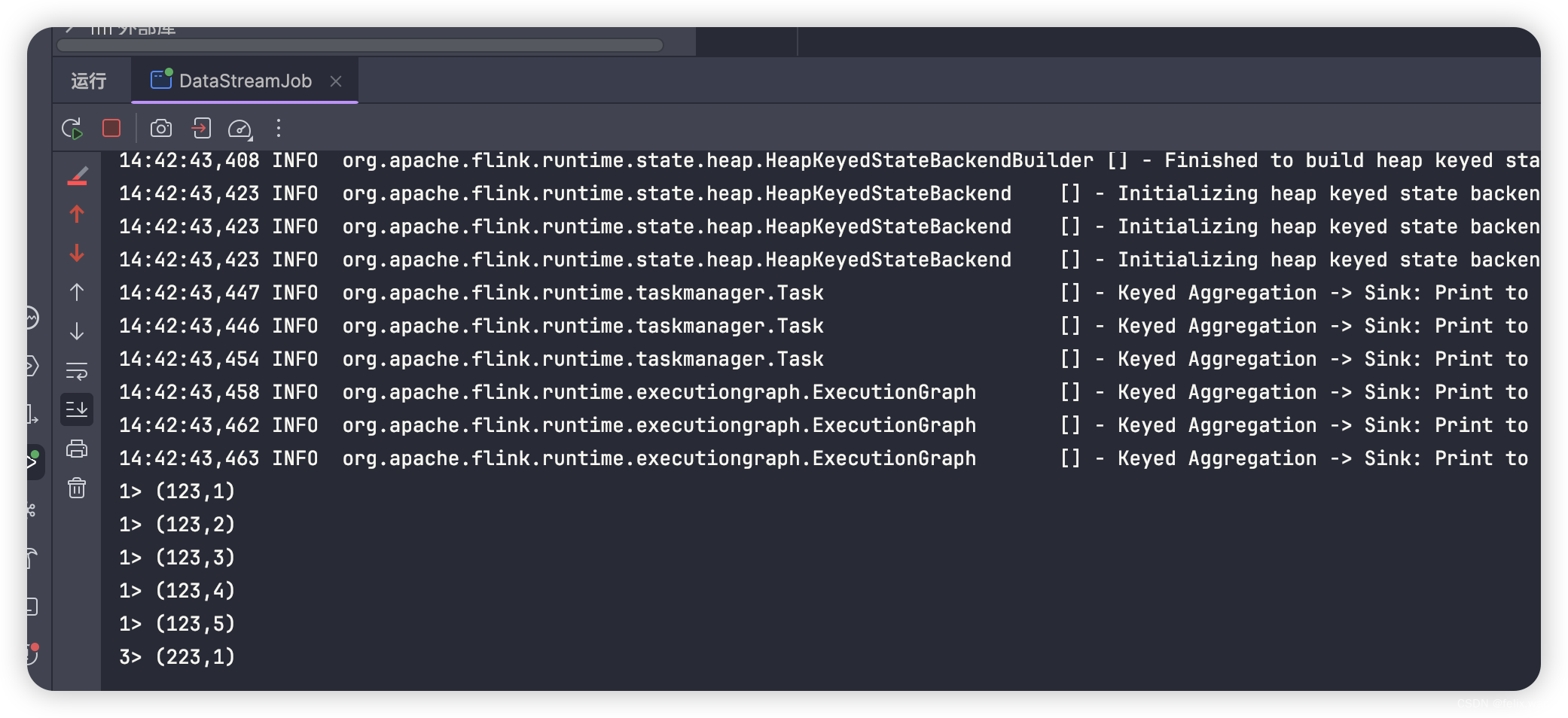
jar包上传flink集群运行
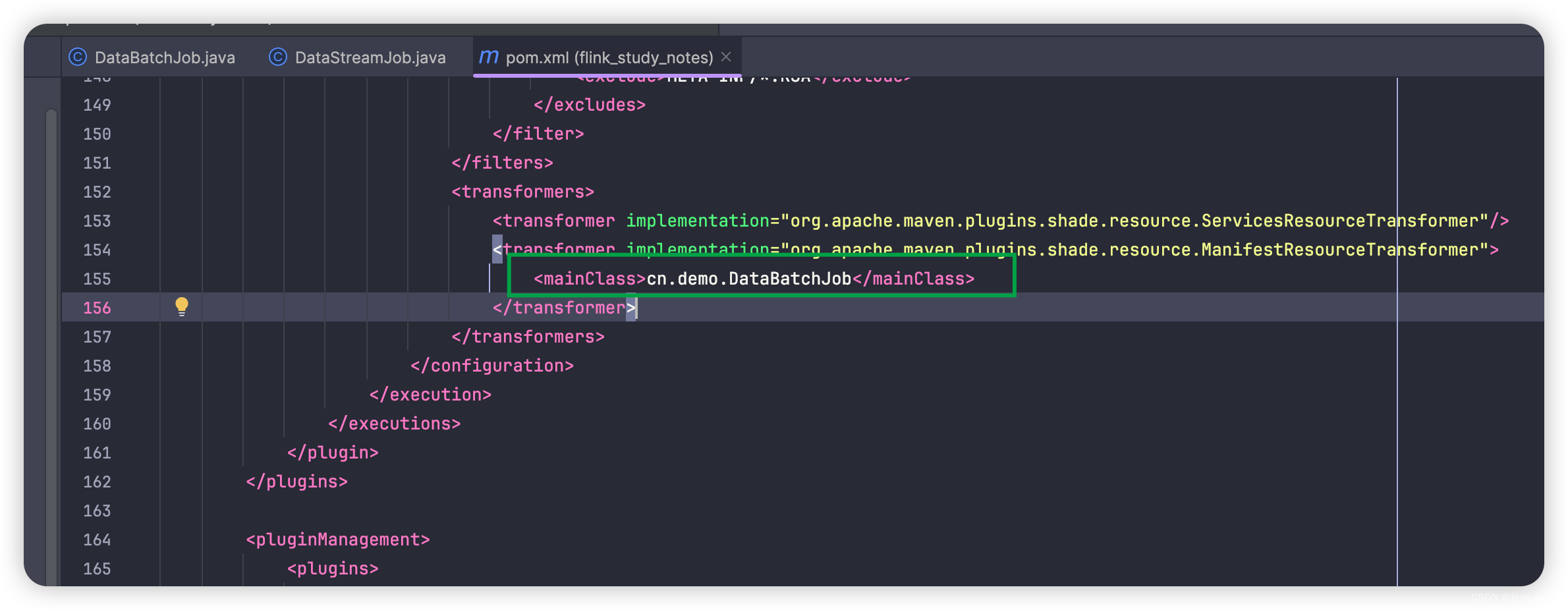
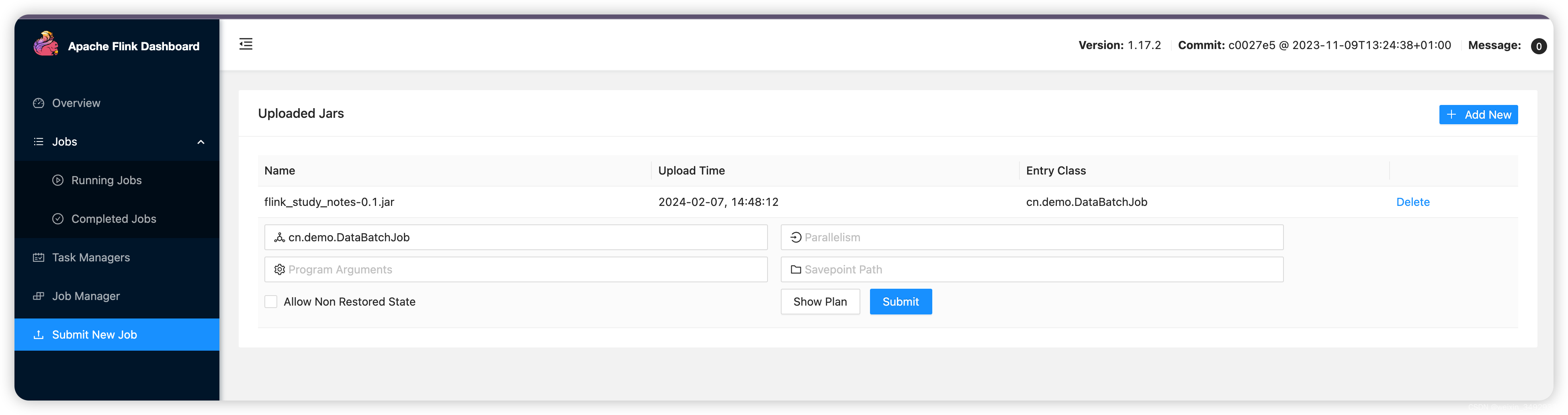
方式一:界面提交
方式二: 命令提交
#提交任务
flink run -m 127.0.0.1:18081 -c cn.demo.DataBatchJob -p 2 flink_study_notes-0.1.jar
#取消任务
flink cancle <JobID>
- 1
- 2
- 3
- 4
界面效果
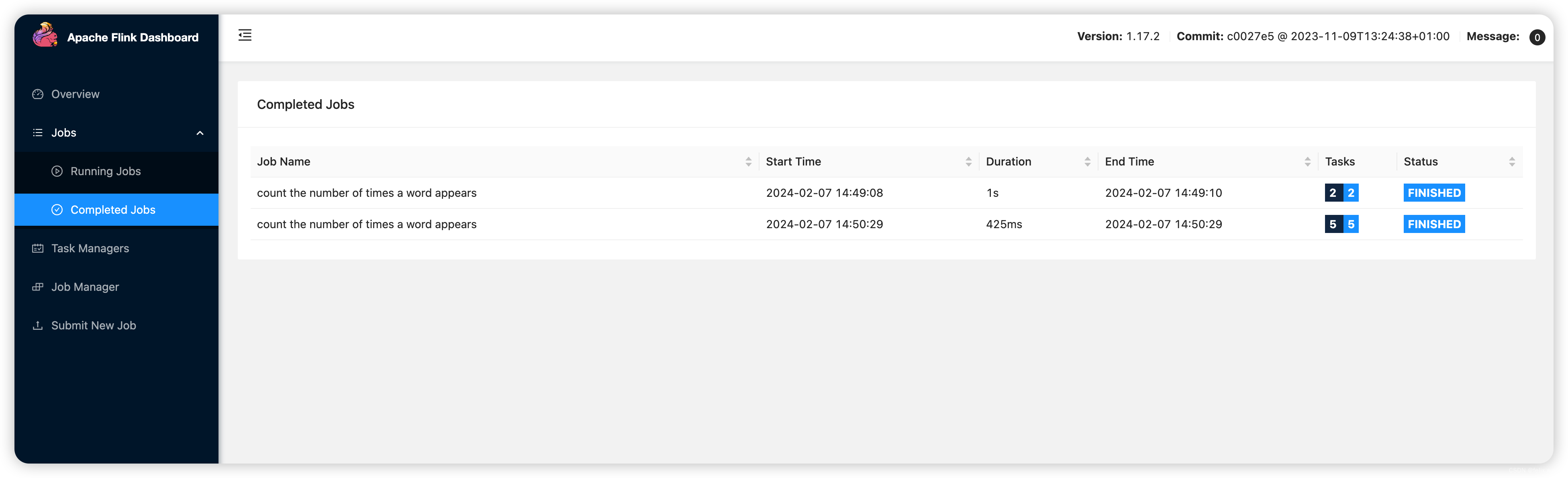
当你创建了一个如
flink-network的自定义网络后,你可以在启动Docker容器时使用--network标志将容器附加到这个网络上,例如docker run --network flink-network your-image。这使得容器能够以更细粒度的网络设置进行通信,并且比默认的桥接网络提供更好的安全性和灵活性。 ↩︎

