
政安晨的机器学习笔记——浅谈机器学习的理论“小黑盒”:算法概念_机器学习建立黑盒
赞
踩
“机器学习”这个词受到人们的关注已经很久了。很多人们都对机器学习感兴趣,但是一遇到机器学习中的理论领域就望而却步了,确实挺遗憾。
虽然现在世界各地都有人在开发机器学习专用的程序库,方便又多样的数据集也能唾手可得。一个人即使不懂理论知识,只要准备好程序库和数据集,再写上几行代码就可以制作出有模有样的东西。机器学习的入门门槛确实降低了,我们可以一边自己动手写一些代码,一边学习机器学习。
但是,大家一直使用这类越来越多、且无法感知其中原理的“黑匣子”们,还是有一定的担忧吧。长此以往,对ML模型的感知力可能会越来越弱,这样开始的机器学习,我想很多程序员长久坚持或许会成为一种煎熬,因为不知内部做了啥总会稍稍感到不放心。
这篇笔记里,我们稍稍聊一下,看能不能建立起一个算法概念的全貌感知。
(一)机器学习的任务
无论是过去还是现在,计算机都特别擅长处理重复的任务。所以计算机能够比人类更高效地读取大量的数据、学习数据的特征并从中找出数据的模式,现在机器学习能做的事情更多了,一是因为具备了能够收集大量数据的环境,二是因为具备了能够处理大量数据的环境。
当我们打算用机器学习做什么事情的时候,首先需要的就是数据。因为机器学习就是从数据中找出特征和模式的技术。
咱们先看一看机器学习非常擅长的任务:回归(regression)、分类(classification)、聚类(clustering)。
1. 回归(regression):简单易懂地说,回归就是在处理连续数据如时间序列数据时使用的技术。比如:股价,如下图:
从这样的数据中学习它的趋势,求出“明天的股价会变为多少”“今后的趋势会怎样”的方法就是回归,它就是一种机器学习算法。
2.分类(classification):从给定的输入数据中区分不同的类别或标签,是一种监督学习的任务。比如:检查邮件是否为垃圾邮件,如下图:

鉴别垃圾邮件就可以归类为分类问题,就是根据邮件的内容,以及这封邮件是否属于垃圾邮件这些数据来进行学习。实际上机器学习中最麻烦的地方,就是收集数据。无论收集数据的环境变得多好,还是有很多需要人工介入的工作。
3.聚类(clustering):聚类与分类相似,却又有些不同。聚类是一种无监督学习方法,用于将数据集中的样本划分为不同的组,每个组内的样本具有相似的特征。
比如,聚类考虑的问题是:假设在有100名学生的学校进行摸底考试,然后根据考试成绩把100名学生分为几组,根据分组结果,我们能得出某组偏重理科、某组偏重文科这样有意义的结论。这里用来学习的数据就是每个学生的考试分数,如下表:

聚类与分类的区别在于数据带不带标签。也有人把标签称为正确答案数据。比如刚才的垃圾邮件鉴别问题,除了邮件内容以外,数据集中是不是还包含了标记邮件是否为垃圾邮件的数据?可这个考试分数的数据里并没有与分类有关的标签,仅仅包含了编号和分数的数据而已。
因此,我们知道:使用有标签的数据进行的学习称为有监督学习,与之相反,使用没有标签的数据进行的学习称为无监督学习。回归和分类是有监督学习,而聚类是无监督学习。
看起来很简单吧,如果只是学习机器学习的基础知识,并不需要太高深的数学知识。只要具备了大致的概念理解,碰到不明白的地方再去查资料。
(二)机器学习的模型
我们来看一个最简单的模型,如下图所示:
在f(x)=x2的函数图像中,使函数最小的x是什么呢?
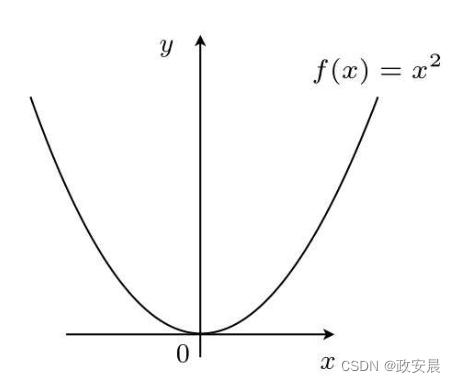
咱们很轻易地就能回答出来:x=0的时候最小。
好,我们在刚才的图像上乘以1/2,使函数最小的x是什么?
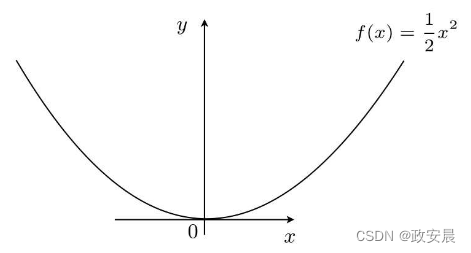
答案依旧简单,当然还是x=0的时候最小!
所以,我们得出结论:只要乘以正的常数,函数的形状就会被横向压扁或者纵向拉长,但函数本身取最小值的点是不变的。我们把这样的规律用算法来表示,就得到了模型。
机器学习的模型指的就是用于学习和预测任务的数学模型。
咱们赶快夹带点私货:机器学习模型可以分为有监督学习模型、无监督学习模型和强化学习模型。
-
有监督学习模型:有监督学习是指通过已有的输入数据和对应的输出数据,来训练模型。常见的有监督学习模型包括线性回归、逻辑回归、决策树、随机森林、支持向量机和神经网络等。
-
无监督学习模型:无监督学习是指在没有标记输出数据的情况下对数据进行学习和分析。常见的无监督学习模型包括聚类算法(如K均值聚类、层次聚类)、关联规则挖掘和降维算法(如主成分分析)等。
-
强化学习模型:强化学习是指通过与环境的交互学习来选择一系列动作以获得最大的回报。常见的强化学习模型包括马尔科夫决策过程(Markov Decision Processes,MDP)和强化学习算法(如Q-Learning和深度强化学习)等。
除了这些传统的模型,还有一些最新的模型如生成对抗网络(Generative Adversarial Networks,GAN)、变分自编码器(Variational Autoencoders,VAE)和深度强化学习模型(如深度Q网络)等也被广泛应用于机器学习任务中。不同的模型适用于不同的问题和数据类型,选择合适的模型是机器学习中的重要步骤。
突然之间看到这么多模型,是不是有点激动?但是,针对各类问题,这些模型应该是有强有弱的,应该怎么判断呢?这就涉及到模型评估了。
在机器学习领域,模型评估是用于评估机器学习模型性能和准确性的过程。模型评估可以帮助确定模型在现实世界中的表现,并帮助选择最佳的模型或参数配置。
模型评估通常包括以下一些步骤:
-
数据集划分:将标记好的数据集划分为训练集和测试集。训练集用于训练模型,测试集用于评估模型的性能和泛化能力。
-
模型训练:使用训练集对模型进行训练,通过学习数据集中的模式和关系来创建模型。
-
模型预测:使用训练好的模型对测试集中的样本进行预测,得到预测结果。
-
模型评估:将模型的预测结果与测试集中的真实标签进行比较,计算评估指标来衡量模型的性能。常用的评估指标包括准确率、精确率、召回率、F1-score等。
-
模型选择和调优:根据评估结果选择最佳的模型或参数配置。如果模型性能不满足要求,可以尝试调整超参数、改进特征工程等方法来提升模型性能。
模型评估是机器学习中重要的一步,它能够帮助评估模型的质量,并提供指导来改进和优化模型。我们只要知道,机器学习模型的精度是可以被定量地表示的就可以了。
那么,要怎么评估模型呢?
简单来说,就是:把获取的全部训练数据分成两份:一份用于测试,一份用于训练,然后用前者来评估模型。
比如说,现在咱们获得了1000个可以用于给模型训练的数据,这个时候先不要全部都拿来训练模型,拿出70%-80%的数据量来训练模型,剩下的20%-30%的数据先留着,等到模型训练好后,拿剩下的数据来测试,根据判断的结果来评估模型。
这里又要引入一个词:拟合度。
模型的拟合度指的是模型对训练数据的拟合程度,也称为模型的拟合优度、拟合度或拟合性。它是评估模型对已知数据的拟合程度的指标。当模型的拟合度较高时,说明模型能够很好地拟合训练数据,即能够较好地预测已知数据的结果。而当模型的拟合度较低时,说明模型不能很好地拟合训练数据,即不能很好地预测已知数据的结果。
在机器学习中,常用的拟合度指标包括均方误差(Mean Squared Error,MSE)、决定系数(R-squared)、对数似然函数(Log-Likelihood)等。
另外,模型只能拟合训练数据的状态被称为过拟合,英文是overfitting。过拟合不止在回归时出现,在分类时也经常发生,我们要时常留意它。
有几种方法可以避免过拟合。
1. 增加全部训练数据的数量;
2. 使用简单的模型;
3. 正则化首先,重要的是增加全部训练数据的数量。机器学习是从数据中学习的,所以数据最重要。另外,使用更简单的模型也有助于防止过拟合。
啥是正则化呢?
在机器学习中,正则化是一种通过增加额外的约束来限制模型复杂度的技术。正则化的目的是防止模型过度拟合训练数据,从而提高其在测试数据上的泛化能力。正则化可以通过在损失函数中引入惩罚项来实现。常见的正则化方法有L1正则化和L2正则化。
L1正则化通过在损失函数中增加模型参数的绝对值之和,以使得模型参数向稀疏解靠拢。L1正则化可以促使模型选择少量重要特征,从而提高模型的解释性。
L2正则化通过在损失函数中增加模型参数的平方和,以使得模型参数趋向于较小的值。L2正则化可以使得模型参数更加均衡并减小参数间的相关性,从而提高模型的泛化能力。
正则化的选择可以根据具体问题和数据集的特点来进行调整。较大的正则化参数会增加对模型复杂度的限制,从而更加倾向于简单的模型;而较小的正则化参数则会对模型的限制较小,更容易过拟合数据。
还有,我们聊了过拟合的话题,而且还有一种叫作欠拟合的状态,用英文说是underfitting。
什么是欠拟合呢?
在机器学习中,欠拟合(underfitting)指的是模型无法对训练数据集以外的数据进行准确预测的情况。欠拟合通常发生在模型过于简单或者对训练数据过度约束的情况下。
当模型欠拟合时,它无法捕捉到数据中的复杂关系和模式,导致模型在训练数据上的性能较差,并且不能很好地泛化到新数据。
欠拟合的一些常见原因包括:
- 模型过于简单:模型的复杂度不足以对数据中的复杂关系进行建模。
- 数据量不足:训练数据太少,无法覆盖整个数据分布的特征。
- 特征选择不当:选取的特征不足以描述数据中的关键信息。
- 过度正则化:引入的正则化项过强,限制了模型的灵活性。
解决欠拟合问题的方法包括增加模型的复杂度、增加训练数据量、改进特征选择、调整正则化参数等。
这样一来,大家会问了:过拟合也不好,欠拟合也不好,“刚刚好”是不是最好?其实,在机器学习领域,模型要做到“刚刚好”的话,是非常困难的。
(三)结论
理解机器学习算法的概念在机器学习领域中非常重要,这对于以下几个方面具有重要性:
-
选择适当的算法:了解不同的机器学习算法以及它们的特点和应用场景,可以帮助我们选择最适合解决特定问题的算法。每个算法都有其自身的优缺点和适用性,因此了解这些概念可以帮助我们做出更明智的选择。
-
特征选择和工程:在机器学习中,特征的选择和工程是非常重要的步骤。理解算法的概念可以帮助我们理解特征的影响和选择。例如,在决策树算法中,我们可以通过理解节点的分割准则来选择最重要的特征,而在神经网络中,我们可以通过理解激活函数来选择适当的特征工程方法。
-
调整参数和优化性能:许多机器学习算法都有一些超参数需要调整,以获得最佳的性能。理解算法的概念可以帮助我们理解这些超参数的作用和相互关系,从而能够更好地调整参数以优化模型的性能。
-
解释模型结果:理解算法的概念可以帮助我们解释模型的结果和决策过程。例如,在深度学习中,理解卷积神经网络的概念可以帮助我们理解网络对图像中不同特征的提取方式,从而更好地理解模型的预测过程。
综上所述,理解机器学习算法的概念对于选择适当的算法、进行特征选择和工程、调整参数和优化性能以及解释模型结果都非常重要。它可以帮助我们更好地理解和利用机器学习算法,从而取得更好的结果。

