
- 1ORB_SLAM3安装运行&性能测试对比_orbslam3 ros
- 2Neural Data-to-Text Generation with Dynamic Content Planning_neural pipeline for zero-shot data-to-text generat
- 3Python+Django+Mysql个性化小说推荐系统 小说网站推荐系统 基于用户、项目、内容的协同过滤推荐算法WebNovelCFRSPython python实现协同过滤推荐算法实现源代码下载_小说推荐系统算法 github.
- 4测试面试宝典(十)—— 请问测试开发需要哪些知识?需要具备什么能力?
- 5unity发布webGL压缩方式的gzip,使用nginx作为web服务器时的配置文件_unity gzip
- 6Hadoop-21 Sqoop 数据迁移工具 简介与环境配置 云服务器 ETL工具 MySQL与Hive数据互相迁移 导入导出
- 7NLP 文本分类_nlp文本分类算法
- 8pg无法启动
- 9Proteus仿真STM32的课设实例3——汽车倒车测距提示仪_stm32课设
- 10物体检测框架 RetinaNet 深度神经网络简介
数据关联规则:概述【频繁项集评估标准:支持度(support)、置信度(confidence)、提升度(lift)】【算法:Aprior、FP-Tree、GSP、CBA】
赞
踩
关联规则(Association Rules)是反映一个事物与其他事物之间的相互依存性和关联性,是数据挖掘的一个重要技术,用于从大量数据中挖掘出有价值的数据项之间的相关关系。
该过程通过发现顾客放人其购物篮中的不同商品之间的联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买,这种关联的发现可以帮助零售商制定营销策略。其他的应用还包括价目表设计、商品促销、商品的排放和基于购买模式的顾客划分。
可从数据库中关联分析出形如“由于某些事件的发生而引起另外一些事件的发生”之类的规则。
一、关联规则引入
下面用一个故事来引出关联规则:

二、关联规则相关概念介绍
1、样本、事务、项集、规则
关联规则中的数据集结构一般如下所示:
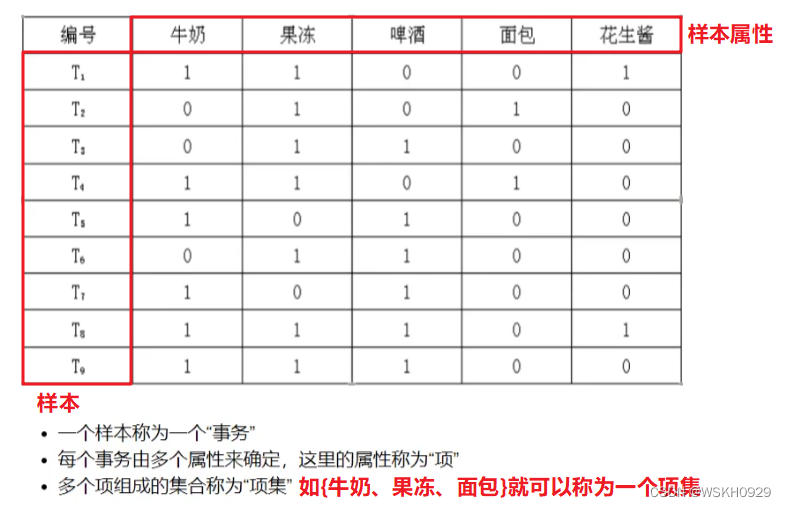
关于项集(多个项组成的集合):
- { 牛奶 } 是 1-项集
- { 牛奶,果冻 } 是 2-项集;
- { 啤酒,面包,牛奶 } 是 3-项集
X==>Y含义(规则):
- X和Y是项集
- X称为规则前项
- Y称为规则后项
事务:即样本,一个样本称为一个事务。事务仅包含其涉及到的项目,而不包含项目的具体信息
- 在超级市场的关联规则挖掘问题中事务是顾客一次购物所购买的商品,但事务中并不包括这些商品的具体信息,如商品的数量、价格等
2、频繁项集的评估标准
什么样的数据才是频繁项集呢?也许你会说,这还不简单,肉眼一扫,一起出现次数多的数据集就是频繁项集吗!的确,这也没有说错,但是有两个问题,第一是当数据量非常大的时候,我们没法直接肉眼发现频繁项集,这催生了关联规则挖掘的算法,比如Apriori, PrefixSpan, CBA。第二是我们缺乏一个频繁项集的标准。比如10条记录,里面A和B同时出现了三次,那么我们能不能说A和B一起构成频繁项集呢?因此我们需要一个评估频繁项集的标准。
常用的频繁项集的评估标准有支持度,置信度和提升度三个。
2.1 支持度
支持度(support):一个项集或者规则在所有事务中出现的频率,σ(X):表示项集X的支持度计数
- 项集X的支持度:s(X)=σ(X)÷N
- 规则X==>Y表示物品集X对物品集Y的支持度,也就是物品集X和物品集Y同时出现的概率
- 假设某天共有100个顾客到商场买东西,其中30个顾客同时购买了啤酒和尿布,那么上述的关联规则的支持度就是30%
支持度就是几个关联的数据在数据集中出现的次数占总数据集的比重。或者说几个数据关联出现的概率。如果我们有两个想分析关联性的数据X和Y,则对应的支持度为:

以此类推,如果我们有三个想分析关联性的数据X,Y和Z,则对应的支持度为:

一般来说,支持度高的数据不一定构成频繁项集,但是支持度太低的数据肯定不构成频繁项集。
2.2 置信度
置信度(confidence):确定Y在包含X的事务中出现的频繁程度。c(X⟶Y)=σ(X∪Y)÷σ(X)
- 条件概率公式:P(Y∣X)=P(XY)÷P(X)
- 置信度反映了关联规则的可信度,即购买了项目集X中的商品的顾客同时也购买了Y中商品的概率
- 假设购买薯片的顾客中有50%也购买了可乐,则置信度为50%
置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。如果我们有两个想分析关联性的数据X和Y,X对Y的置信度为
![]()
也可以以此类推到多个数据的关联置信度,比如对于三个数据X,Y,Z,则X对于Y和Z的置信度为:
![]()
举个例子,在购物数据中,纸巾对应鸡爪的置信度为40%,支持度为1%。则意味着在购物数据中,总共有1%的用户既买鸡爪又买纸巾;同时买鸡爪的用户中有40%的用户购买纸巾。
2.3 提升度
提升度(lift):物品集A的出现对物品集B的出现概率发生了多大的变化
- lift(A==>B)=confidence(A==>B)÷support(B)=P(B∣A)÷P(B)
- 假设现在有1000个顾客,其中500人买了茶叶,买茶叶的500人中有450人还买了咖啡。那么可以计算得confidence(茶叶==>咖啡)=450÷500=90%,由此,可能会认为喜欢喝茶的人往往喜欢喝咖啡。但是,如果另外没有购买茶叶的500人中也有450人买了咖啡,同样可以算出置信度90%,得到的结论是不爱喝茶的人往往喜欢喝咖啡。这与前面的结论矛盾了,由此看来,实际上顾客喜不喜欢喝咖啡和他喜不喜欢喝茶几乎没有关系,两者是相互独立的。此时,我们就有提升度这一指标来描述这一现象。
在这个例子中,lift(茶叶==>咖啡)=confidence(茶叶==>咖啡)÷support(咖啡)=90%÷[(450+450)÷1000]=1 - 由此可见,提升度弥补了置信度的这一缺憾,如果提升都等于1,那么X与Y独立,X对Y的出现的可能性没有提升作用。提升度越大(lift > 1),则表明X对Y的提升程度越大,也表明X与Y的关联性越强。
提升度表示含有Y的条件下,同时含有X的概率,与X总体发生的概率之比,即:
![]()
提升度体先了X和Y之间的关联关系, 提升度大于1则X⇐Y是有效的强关联规则, 提升度小于等于1则X⇐Y是无效的强关联规则 。一个特殊的情况,如果X和Y独立,则有Lift(X⇐Y)=1,因为此时P(X|Y)=P(X)。
一般来说,要选择一个数据集合中的频繁数据集,则需要自定义评估标准。最常用的评估标准是用自定义的支持度,或者是自定义支持度和置信度的一个组合。
三、案例
下面举一个例子,来更深层次的理解支持度和置信度:

计算 A==>C 的支持度和置信度:
- 支持度:即同时购买了商品A和C的顾客的比率 = 2 ÷ 4 = 50 %
- 置信度:即在购买了商品A的顾客中,购买了商品C的比率 = 2 ÷ 3 = 66.7 %
计算 C==>A 的支持度和置信度:
- 支持度:即同时购买了商品C和A的顾客的比率(其实和A==>C的支持度是一样的) = 2 ÷ 4 = 50 %
- 置信度:即在购买了商品C的顾客中,购买了商品A的比率 = 2 ÷ 2 = 100 %
我们一般可以用 X==>Y(支持度,置信度)的格式表示规则的支持度和置信度,具体如下所示:
- A==>C(50%,66.7%)
- C==>A(50%,100%)
一般地,我们会定义最小支持度(minsupport)和最小置信度(minconfidence),若规则X==>Y的支持度分别大于等于我们定义的最小支持度和最小置信度,则称关联规则X==>Y为强关联规则,否则称为弱关联规则。我们通常会把注意力放在强关联规则上。
四、所有指标的公式


