
- 1【实战】手把手教你在 vscode 中写 markdown_vscode使用markdown
- 2基于Elasticsearch + Fluentd + Kibana(EFK)搭建日志收集管理系统_kibana fluentd
- 3微信小程序渲染图片报错:[渲染层网络层错误] Failed to load local image resource_[渲染层网络层错误] failed to load local image resource /st
- 4【K8S系列】深入解析k8s 网络插件—Antrea_antrea k8s
- 5【软件测试】简历中的项目经历可以怎么写?_软件测试的项目经历怎么写
- 6【Python】实现一个简单的区块链系统_python 区块链
- 7【漏洞复现】Apache Struts2 CVE-2023-50164_cve-2023-50164 复现
- 8手把手教你使用Flask框架构建Python接口以及如何请求该接口_flask 接口
- 9【区块链 | DID】白话数字身份_did技术
- 10利用OGG实现PostgreSQL实时同步
力扣 (LeetCode) 剑指 Offer(第 2 版)刷题(java)合集-01_剑指力扣题库java
赞
踩
力扣刷题合集
难度简单442
找出数组中重复的数字。
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
示例 1:
输入:
[2, 3, 1, 0, 2, 5, 3]
输出:2 或 3
- 1
- 2
- 3
方法一:遍历hashset
class Solution {
public int findRepeatNumber(int[] nums) {
Set<Integer> set = new HashSet<Integer>();
int repeat = -1;
for (int num : nums) {
if (!set.add(num)) {
repeat = num;
break;
}
}
return repeat;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
方法二:原地交换
class Solution:
def findRepeatNumber(self, nums: [int]) -> int:
i = 0
while i < len(nums):
if nums[i] == i:
i += 1
continue
if nums[nums[i]] == nums[i]: return nums[i]
nums[nums[i]], nums[i] = nums[i], nums[nums[i]]
return -1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
剑指 Offer 04. 二维数组中的查找
难度中等342
在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个高效的函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
示例:
现有矩阵 matrix 如下:
[
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
给定 target = 5,返回 true。
给定 target = 20,返回 false。
解法: 类似二叉搜索树
如下图所示,我们将矩阵逆时针旋转 45° ,并将其转化为图形式,发现其类似于 二叉搜索树 ,即对于每个元素,其左分支元素更小、右分支元素更大。因此,通过从 “根节点” 开始搜索,遇到比 target 大的元素就向左,反之向右,即可找到目标值 target 。
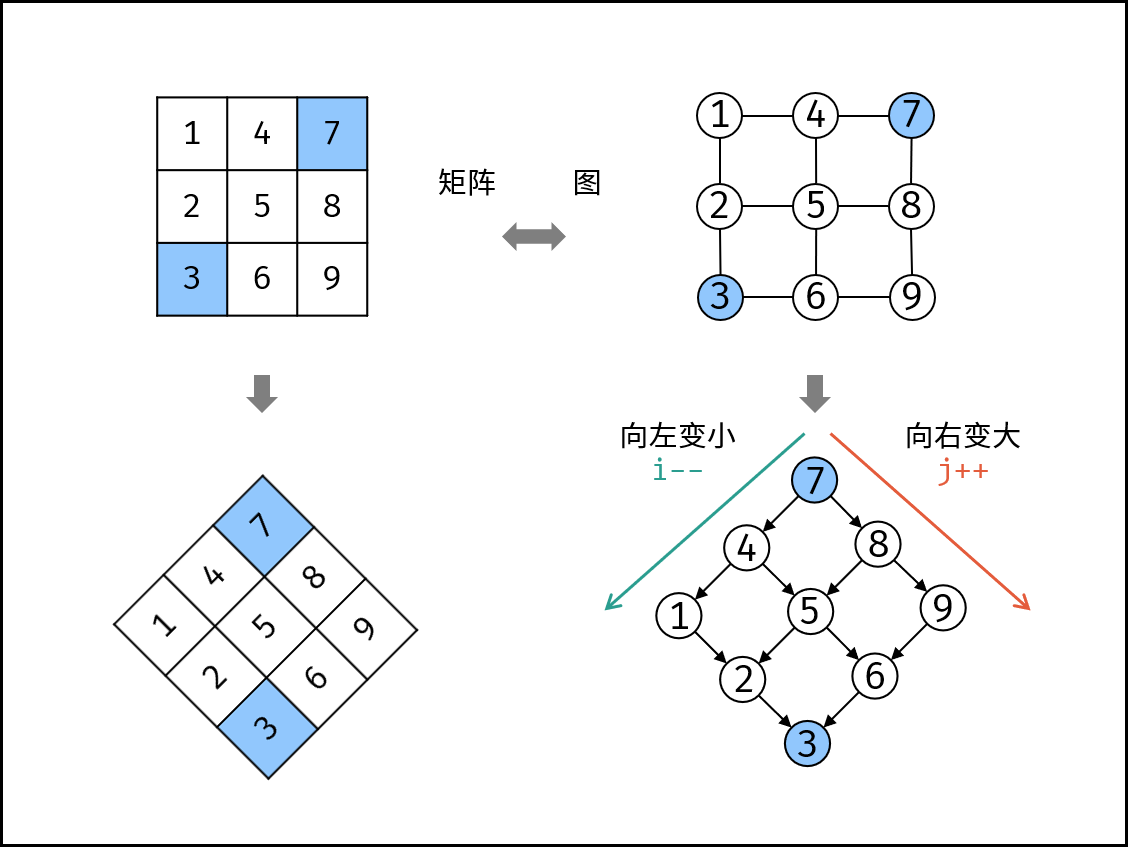
“根节点” 对应的是矩阵的 “左下角” 和 “右上角” 元素,本文称之为 标志数 ,以 matrix 中的 左下角元素 为标志数 flag ,则有:
若 flag > target ,则 target 一定在 flag 所在 行的上方 ,即 flag 所在行可被消去。
若 flag < target ,则 target 一定在 flag 所在 列的右方 ,即 flag 所在列可被消去。
算法流程:
从矩阵 matrix 左下角元素(索引设为 (i, j) )开始遍历,并与目标值对比:
当 matrix [i][j] > target 时,执行 i-- ,即消去第 i 行元素;
当 matrix [i][j] < target 时,执行 j++ ,即消去第 j 列元素;
当 matrix [i][j] = target 时,返回 true ,代表找到目标值。
若行索引或列索引越界,则代表矩阵中无目标值,返回 false 。
每轮 i 或 j 移动后,相当于生成了“消去一行(列)的新矩阵”, 索引(i,j) 指向新矩阵的左下角元素(标志数),因此可重复使用以上性质消去行(列)。
class Solution {
public boolean findNumberIn2DArray(int[][] matrix, int target) {
int i = matrix.length - 1, j = 0;
while(i >= 0 && j < matrix[0].length)
{
if(matrix[i][j] > target) i--;
else if(matrix[i][j] < target) j++;
else return true;
}
return false;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
剑指 Offer 05. 替换空格
难度简单122
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1:
输入:s = "We are happy."
输出:"We%20are%20happy."
- 1
- 2
限制:
0 <= s 的长度 <= 10000
- 1
解法:暴力法
class Solution {
public String replaceSpace(String s) {
StringBuilder stringBuilder=new StringBuilder();
for (int i=0;i<s.length();i++){
if (s.charAt(i)==' ')
stringBuilder.append("%20");
else stringBuilder.append(s.charAt(i));
}
return stringBuilder.toString();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
剑指 Offer 06. 从尾到头打印链表
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
示例 1:
输入:head = [1,3,2]
输出:[2,3,1]
限制:
0 <= 链表长度 <= 10000
方法一:辅助栈法
算法流程:
入栈: 遍历链表,将各节点值 push 入栈。(Python 使用 append() 方法,Java借助 LinkedList 的addLast()方法)。
出栈: 将各节点值 pop 出栈,存储于数组并返回。(Python 直接返回 stack 的倒序列表,Java 新建一个数组,通过 popLast() 方法将各元素存入数组,实现倒序输出)。
class Solution {
public int[] reversePrint(ListNode head) {
LinkedList<Integer> stack = new LinkedList<Integer>();
while(head != null) {
stack.addLast(head.val);
head = head.next;
}
int[] res = new int[stack.size()];
for(int i = 0; i < res.length; i++)
res[i] = stack.removeLast();
return res;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
方法二:递归法
Java 算法流程:
递推阶段: 每次传入 head.next ,以 head == null(即走过链表尾部节点)为递归终止条件,此时直接返回。
点睛之笔:回溯阶段: 层层回溯时,将当前节点值加入列表,即tmp.add(head.val)。
最终,将列表 tmp 转化为数组 res ,并返回即可。**
class Solution {
ArrayList<Integer> tmp = new ArrayList<Integer>();
public int[] reversePrint(ListNode head) {
recur(head);
int[] res = new int[tmp.size()];
for(int i = 0; i < res.length; i++)
res[i] = tmp.get(i);
return res;
}
void recur(ListNode head) {
if(head == null) return;
recur(head.next);
tmp.add(head.val);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
*递归输出:对于编程小白,反转链表到list,很高级~
public void recur(ListNode head){
if (head==null)
return;
recur(head.next);
arrayList.add(head.val);
}
- 1
- 2
- 3
- 4
- 5
- 6
剑指 Offer 07. 重建二叉树
难度中等465
输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
例如,给出
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
- 1
- 2
返回如下的二叉树:
3
/ \
9 20
/ \
15 7
- 1
- 2
- 3
- 4
- 5
限制:
0 <= 节点个数 <= 5000
- 1
解法:递归法——最容易理解的
前序遍历性质: 节点按照 [ 根节点 | 左子树 | 右子树 ] 排序。
中序遍历性质: 节点按照 [ 左子树 | 根节点 | 右子树 ] 排序。
以题目示例为例:
前序遍历划分 [ 3 | 9 | 20 15 7 ]
中序遍历划分 [ 9 | 3 | 15 20 7 ]
根据以上性质,可得出以下推论:
前序遍历的首元素 为 树的根节点 node 的值。
在中序遍历中搜索根节点 node 的索引 ,可将 中序遍历 划分为 [ 左子树 | 根节点 | 右子树 ] 。
根据中序遍历中的左 / 右子树的节点数量,可将 前序遍历 划分为 [ 根节点 | 左子树 | 右子树 ] 。
分治算法解析:
递推参数: 根节点在前序遍历的索引 root 、子树在中序遍历的左边界 left 、子树在中序遍历的右边界 right ;
终止条件: 当 left > right ,代表已经越过叶节点,此时返回 null;
递推工作:
建立根节点 node : 节点值为 preorder[root] ;
划分左右子树: 查找根节点在中序遍历 inorder 中的索引 i ;
为了提升效率,本文使用哈希表 dic 存储中序遍历的值与索引的映射,查找操作的时间复杂度为 O(1)
构建左右子树: 开启左右子树递归;
根节点索引 中序遍历左边界 中序遍历右边界
左子树: root + 1 left i - 1
右子树: i - left + root + 1 i + 1 right
- 1
- 2
i - left + root + 1含义为 根节点索引 + 左子树长度 + 1
返回值: 回溯返回 node ,作为上一层递归中根节点的左 / 右子节点;
class Solution {
int[] preorder;
HashMap<Integer, Integer> dic = new HashMap<>(); //hashSet存储了inOder的对应序号,用的很好;
public TreeNode buildTree(int[] preorder, int[] inorder) {
this.preorder = preorder;
for(int i = 0; i < inorder.length; i++)
dic.put(inorder[i], i);
return recur(0, 0, inorder.length - 1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
以下的这个递归法 注意最后返回的是node,注意退出迭代的条件和迭代的return条件。
TreeNode recur(int root, int left, int right) {
if(left > right) return null; // 递归终止
TreeNode node = new TreeNode(preorder[root]); // 建立根节点
int i = dic.get(preorder[root]); // 划分根节点、左子树、右子树
node.left = recur(root + 1, left, i - 1); // 开启左子树递归
node.right = recur(root + i - left + 1, i + 1, right); // 开启右子树递归
return node; // 回溯返回根节点
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
指 Offer 09. 用两个栈实现队列
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
示例 1:
输入:
["CQueue","appendTail","deleteHead","deleteHead"]
[[],[3],[],[]]
输出:[null,null,3,-1]
- 1
- 2
- 3
- 4
示例 2:
输入:
["CQueue","deleteHead","appendTail","appendTail","deleteHead","deleteHead"]
[[],[],[5],[2],[],[]]
输出:[null,-1,null,null,5,2]
- 1
- 2
- 3
- 4
提示:
1 <= values <= 10000最多会对 appendTail、deleteHead 进行 10000 次调用
方法一:双栈
思路和算法
维护两个栈,第一个栈支持插入操作,第二个栈支持删除操作。
根据栈先进后出的特性,我们每次往第一个栈里插入元素后,第一个栈的底部元素是最后插入的元素,第一个栈的顶部元素是下一个待删除的元素。为了维护队列先进先出的特性,我们引入第二个栈,用第二个栈维护待删除的元素,在执行删除操作的时候我们首先看下第二个栈是否为空。如果为空,我们将第一个栈里的元素一个个弹出插入到第二个栈里,这样第二个栈里元素的顺序就是待删除的元素的顺序,要执行删除操作的时候我们直接弹出第二个栈的元素返回即可。
成员变量
维护两个栈 stack1 和 stack2,其中 stack1 支持插入操作,stack2 支持删除操作
构造方法
初始化 stack1 和 stack2 为空
插入元素
插入元素对应方法 appendTail、stack1 直接插入元素
删除元素
删除元素对应方法 deleteHead
如果 stack2 为空,则将 stack1 里的所有元素弹出插入到 stack2 里
如果 stack2 仍为空,则返回 -1,否则从 stack2 弹出一个元素并返回
class CQueue { Deque<Integer> stack1; Deque<Integer> stack2; public CQueue() { stack1 = new LinkedList<Integer>(); stack2 = new LinkedList<Integer>(); } public void appendTail(int value) { stack1.push(value); } public int deleteHead() { // 如果第二个栈为空 if (stack2.isEmpty()) { while (!stack1.isEmpty()) { stack2.push(stack1.pop()); } } if (stack2.isEmpty()) { return -1; } else { int deleteItem = stack2.pop(); return deleteItem; } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
剑指 Offer 10- I. 斐波那契数列
难度简单149
写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项(即 F(N))。斐波那契数列的定义如下:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
- 1
- 2
斐波那契数列由 0 和 1 开始,之后的斐波那契数就是由之前的两数相加而得出。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
示例 1:
输入:n = 2
输出:1
- 1
- 2
示例 2:
输入:n = 5
输出:5
- 1
- 2
提示:
0 <= n <= 100
方法一:递归法——直接超出时间限制
public int fib(int n){
if (n==0)
return 0;
if (n==1)
return 1;
return fib(n-1)+fib(n-2);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
原理: 把 f(n)f(n) 问题的计算拆分成 f(n-1)f(n−1) 和 f(n-2)f(n−2) 两个子问题的计算,并递归,以 f(0)f(0) 和 f(1)f(1) 为终止条件。
缺点: 大量重复的递归计算,例如 f(n)f(n) 和 f(n - 1)f(n−1) 两者向下递归需要 各自计算 f(n - 2)f(n−2) 的值。
记忆化递归法:
原理: 在递归法的基础上,新建一个长度为 n 的数组,用于在递归时存储 f(0)至 f(n) 的数字值,重复遇到某数字则直接从数组取用,避免了重复的递归计算。
缺点: 记忆化存储需要使用 O(N)的额外空间。
动态规划:
原理: 以斐波那契数列性质 f(n + 1) = f(n) + f(n - 1) 为转移方程。
从计算效率、空间复杂度上看,动态规划是本题的最佳解法。
class Solution {
public int fib(int n) {
int a = 0, b = 1, sum;
for(int i = 0; i < n; i++){
sum = (a + b) % 1000000007;
a = b;
b = sum;
}
return a;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
剑指 Offer 10- II. 青蛙跳台阶问题
一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
示例 1:
输入:n = 2
输出:2
- 1
- 2
示例 2:
输入:n = 7
输出:21
- 1
- 2
示例 3:
输入:n = 0
输出:1
- 1
- 2
提示:
0 <= n <= 100
与斐波拉契数列解法一样~
剑指 Offer 11. 旋转数组的最小数字
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。
示例 1:
输入:[3,4,5,1,2]
输出:1
- 1
- 2
示例 2:
输入:[2,2,2,0,1]
输出:0
- 1
- 2
官方解答:一步到位,简单
class Solution {
public int minArray(int[] numbers) {
int i = 0, j = numbers.length - 1;
while (i < j) {
int m = (i + j) / 2;
if (numbers[m] > numbers[j]) i = m + 1;
else if (numbers[m] < numbers[j]) j = m;
else j--;
}
return numbers[i];
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
剑指 Offer 12. 矩阵中的路径
难度中等
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
例如,在下面的 3×4 的矩阵中包含单词 “ABCCED”(单词中的字母已标出)。
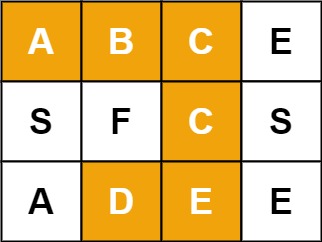
示例 1:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
- 1
- 2
示例 2:
输入:board = [["a","b"],["c","d"]], word = "abcd"
输出:false
- 1
- 2
提示:
1 <= board.length <= 2001 <= board[i].length <= 200board和word仅由大小写英文字母组成
解题思路:
本问题是典型的矩阵搜索问题,可使用 深度优先搜索(DFS)+ 剪枝 解决。
深度优先搜索: 可以理解为暴力法遍历矩阵中所有字符串可能性。DFS 通过递归,先朝一个方向搜到底,再回溯至上个节点,沿另一个方向搜索,以此类推。
剪枝: 在搜索中,遇到 这条路不可能和目标字符串匹配成功 的情况(例如:此矩阵元素和目标字符不同、此元素已被访问),则应立即返回,称之为 可行性剪枝 。
DFS 解析:
递归参数: 当前元素在矩阵 board 中的行列索引 i 和 j ,当前目标字符在 word 中的索引 k 。
终止条件:
返回 false : (1) 行或列索引越界 或 (2) 当前矩阵元素与目标字符不同 或 (3) 当前矩阵元素已访问过 ( (3) 可合并至 (2) ) 。
返回 true: k = len(word) - 1 ,即字符串 word 已全部匹配。
class Solution { public boolean exist(char[][] board, String word) { char[] words = word.toCharArray(); for(int i = 0; i < board.length; i++) { for(int j = 0; j < board[0].length; j++) { if(dfs(board, words, i, j, 0)) return true; } } return false; } boolean dfs(char[][] board, char[] word, int i, int j, int k) { if(i >= board.length || i < 0 || j >= board[0].length || j < 0 || board[i][j] != word[k]) return false; if(k == word.length - 1) return true; board[i][j] = '\0'; boolean res = dfs(board, word, i + 1, j, k + 1) || dfs(board, word, i - 1, j, k + 1) || dfs(board, word, i, j + 1, k + 1) || dfs(board, word, i , j - 1, k + 1); board[i][j] = word[k]; return res; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
剑指 Offer 13. 机器人的运动范围
难度中等
地上有一个m行n列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] 。一个机器人从坐标 [0, 0]的格子开始移动,它每次可以向左、右、上、下移动一格(不能移动到方格外),也不能进入行坐标和列坐标的数位之和大于k的格子。例如,当k为18时,机器人能够进入方格 [35, 37] ,因为3+5+3+7=18。但它不能进入方格 [35, 38],因为3+5+3+8=19。请问该机器人能够到达多少个格子?
示例 1:
输入:m = 2, n = 3, k = 1
输出:3
- 1
- 2
示例 2:
输入:m = 3, n = 1, k = 0
输出:1
- 1
- 2
提示:
1 <= n,m <= 1000 <= k <= 20
方法一:深度优先遍历 DFS
深度优先搜索: 可以理解为暴力法模拟机器人在矩阵中的所有路径。DFS 通过递归,先朝一个方向搜到底,再回溯至上个节点,沿另一个方向搜索,以此类推。
剪枝: 在搜索中,遇到数位和超出目标值、此元素已访问,则应立即返回,称之为 可行性剪枝 。
算法解析:
递归参数: 当前元素在矩阵中的行列索引 i 和 j ,两者的数位和 si, sj 。
终止条件: 当 ① 行列索引越界 或 ② 数位和超出目标值 k 或 ③ 当前元素已访问过 时,返回 00 ,代表不计入可达解。
递推工作:
标记当前单元格 :将索引 (i, j) 存入 Set visited 中,代表此单元格已被访问过。
搜索下一单元格: 计算当前元素的 下、右 两个方向元素的数位和,并开启下层递归 。
回溯返回值: 返回 1 + 右方搜索的可达解总数 + 下方搜索的可达解总数,代表从本单元格递归搜索的可达解总数。
数位和增量公式:
class Solution {
int m, n, k;
boolean[][] visited;
public int movingCount(int m, int n, int k) {
this.m = m; this.n = n; this.k = k;
this.visited = new boolean[m][n];
return dfs(0, 0, 0, 0);
}
public int dfs(int i, int j, int si, int sj) {
if(i >= m || j >= n || k < si + sj || visited[i][j]) return 0;
visited[i][j] = true;
return 1 + dfs(i + 1, j, (i + 1) % 10 != 0 ? si + 1 : si - 8, sj) + dfs(i, j + 1, si, (j + 1) % 10 != 0 ? sj + 1 : sj - 8);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
方法二:广度优先遍历 BFS
BFS/DFS : 两者目标都是遍历整个矩阵,不同点在于搜索顺序不同。DFS 是朝一个方向走到底,再回退,以此类推;BFS 则是按照“平推”的方式向前搜索。
BFS 实现: 通常利用队列实现广度优先遍历。
算法解析:
初始化: 将机器人初始点 (0, 0)(0,0) 加入队列 queue ;
迭代终止条件: queue 为空。代表已遍历完所有可达解。
迭代工作:
单元格出队: 将队首单元格的 索引、数位和 弹出,作为当前搜索单元格。
判断是否跳过: 若 ① 行列索引越界 或 ② 数位和超出目标值 k 或 ③ 当前元素已访问过 时,执行 continue 。
标记当前单元格 :将单元格索引 (i, j) 存入 Set visited 中,代表此单元格 已被访问过 。
单元格入队: 将当前元素的 下方、右方 单元格的 索引、数位和 加入 queue 。
返回值: Set visited 的长度 len(visited) ,即可达解的数量。
class Solution { public int movingCount(int m, int n, int k) { boolean[][] visited = new boolean[m][n]; int res = 0; Queue<int[]> queue= new LinkedList<int[]>(); queue.add(new int[] { 0, 0, 0, 0 }); while(queue.size() > 0) { int[] x = queue.poll(); int i = x[0], j = x[1], si = x[2], sj = x[3]; if(i >= m || j >= n || k < si + sj || visited[i][j]) continue; visited[i][j] = true; res ++; queue.add(new int[] { i + 1, j, (i + 1) % 10 != 0 ? si + 1 : si - 8, sj }); queue.add(new int[] { i, j + 1, si, (j + 1) % 10 != 0 ? sj + 1 : sj - 8 }); } return res; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
剑指 Offer 14- I. 剪绳子
难度中等
给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]...k[m-1] 。请问 k[0]*k[1]*...*k[m-1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
示例 1:
输入: 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1
- 1
- 2
- 3
示例 2:
输入: 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36
- 1
- 2
- 3
提示:
2 <= n <= 58
切分规则:
最优: 3。把绳子尽可能切为多个长度为 3的片段,留下的最后一段绳子的长度可能为 0,1,2 三种情况。
次优: 2 。若最后一段绳子长度为 2;则保留,不再拆为 1+1。
最差: 1 。若最后一段绳子长度为 1 ;则应把一份 3 + 1 替换为 2 + 2,因为2×2>3×1。
解法:贪心思路:
class Solution {
public int cuttingRope(int n) {
if(n <= 3) return n - 1;
int a = n / 3, b = n % 3;
if(b == 0) return (int)Math.pow(3, a);
if(b == 1) return (int)Math.pow(3, a - 1) * 4;
return (int)Math.pow(3, a) * 2;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
剑指 Offer 14- II. 剪绳子 II
难度中等
给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]...k[m - 1] 。请问 k[0]*k[1]*...*k[m - 1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
示例 1:
输入: 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1
- 1
- 2
- 3
示例 2:
输入: 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36
- 1
- 2
- 3
提示:
2 <= n <= 1000
解法:和上题一样,只不过加入了循环取余
class Solution { public int cuttingRope(int n) { long ans=1; if (n>3) { long res = 1; for (int i=1;i<n/3;i++) res=res%1000000007*3; if (n%3== 2) ans = res * 6%1000000007; else if (n%3 == 1) ans = res * 4%1000000007; else ans=res*3%1000000007; return (int)ans; } else return n-1; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
注意:这里的循环必须是n/3-1次,否则报错,应该是超出限制界限;
为了综合考虑n/3==0,1, 2的情况,是可以考虑循环取余后再乘以6,4,3;
注意这里思考,3越多越好,要是余数为1,可以提出一个4;
剑指 Offer 15. 二进制中1的个数
难度简单
请实现一个函数,输入一个整数(以二进制串形式),输出该数二进制表示中 1 的个数。例如,把 9 表示成二进制是 1001,有 2 位是 1。因此,如果输入 9,则该函数输出 2。
示例 1:
输入:00000000000000000000000000001011
输出:3
解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
- 1
- 2
- 3
示例 2:
输入:00000000000000000000000010000000
输出:1
解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。
- 1
- 2
- 3
示例 3:
输入:11111111111111111111111111111101
输出:31
解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。
- 1
- 2
- 3
方法一:逐位判断
根据 与运算 定义,设二进制数字 n ,则有:
若 n & 1 = 0 ,则 n 二进制 最右一位 为 0;
若 n & 1 = 1 ,则 n 二进制 最右一位 为 1 。
根据以上特点,考虑以下 循环判断 :
判断 n 最右一位是否为 1 ,根据结果计数。
将 n 右移一位(本题要求把数字 n 看作无符号数,因此使用 无符号右移 操作)。
算法流程:
初始化数量统计变量 res = 0 。
循环逐位判断: 当 n = 0 时跳出。
res += n & 1 : 若 n & 1 = 1 ,则统计数 res 加一。
n >>>= 1 : 将二进制数字 n 无符号右移一位( Java 中无符号右移为 “>>>” ) 。
返回统计数量 res。
public class Solution {
public int hammingWeight(int n) {
int res = 0;
while(n != 0) {
res += n & 1;
n >>>= 1;
}
return res;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这些代码来源于力扣官网和一些大神的解答,如若侵权,本人定删。

