
热门标签
热门文章
- 1如何自学Python,全网最全Python攻略,看完这一篇就够了_python自学教程
- 2python对list列表进行排序方法总结_python list 排序
- 3【Linux】Linux之间如何互传文件(详细讲解)_linux把文件传到另一个linux
- 4Flask Web开发 博客实例(二)模板_flask web开发案例
- 5内网渗透系列之mimikatz的使用以及后门植入
- 6WPF 使用 fontawesome_wpf fontawesom
- 7Zookeeper命令行zkCli.sh&zkServer.sh的使用(四)
- 8C语言中常用的六大输入输出函数_c定参输出函数
- 9LINGO结果窗口内容解读与灵敏度分析_lingo敏感性分析在哪看
- 10Spring Boot 实战 | Spring Boot整合JPA常见问题解决方案_dependency 'org.springframework.boot:spring-boot-s
当前位置: article > 正文
使用flume收集文件数据传输至kafka_flume读取excel
作者:weixin_40725706 | 2024-02-16 00:39:25
赞
踩
flume读取excel
不做过多介绍 直接实现目的
kafka和flume的包就自行百度即可,kafka的安装教程:https://blog.csdn.net/qq_41594146/article/details/100153434
flume的话直接下载后解压即可用
直接上解释的配置文件:
- #agent name :a1 #给代理取的名字
- a1.sources = r1 #sources认定下方带r1
- a1.sinks = k1 #理解同上
- a1.channels = c1 #理解同上
-
- # Flume source
- a1.sources.r1.type = exec #监听的类型
- a1.sources.r1.command = tail -f /home/testdata.txt #监听时使用的指令 这个可自行修改成你需要的指令 加 |grep 可实现过滤效果
- a1.sources.r1.shell=/bin/sh -c
- a1.sources.r1.batchSize = 1000
- a1.sources.r1.batchTimeout = 3000
- a1.sources.r1.channels = c1
-
- # Flume channel
- a1.channels.c1.type = memory
- a1.channels.c1.capacity = 1000000
- a1.channels.c1.transactionCapacity = 100000
- a1.channels.c1.byteCapacityBufferPercentage = 10
- #a1.channels.c1.byteCapacity = 800000
-
- # Flume sink
- a1.sinks.k1.channel = c1
- a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
- a1.sinks.k1.topic = test
- a1.sinks.k1.brokerList = 192.168.79.137:9092 #kafka的配置 如果是集群 用逗号隔开
- a1.sinks.k1.requiredAcks = 1
- a1.sinks.k1.batchSize = 2000

运行flume:
- nohup bin/flume-ng agent -c conf -f conf/flume2kafka.properties -n a1 -Dflume.root.logger=INFO,console &
-
- # -f后带的是指定的配置文件名 -n 后面带的是代理的名字 上方的配置文件用的是a1所以这里用a1 再后面带的是运行时的jvm参数
效果:
模拟文件写入情况:
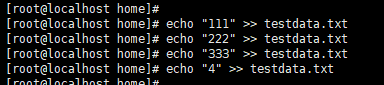
java程序消费情况:

如果能可以帮到各位 可以点个赞或者关注
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/88910
推荐阅读
相关标签

