
- 1最全使用SQL Server创建、配置数据库的各种方法和注意细节_sql server如何建立数据库
- 2鸿蒙HarmonyOS NEXT入门,使用router跳转传值实现影片详情(八)_harmony next 参数跳转
- 3centos7搭建本地harbor仓库_centos7安装harbor
- 4Pandas数据分析一览-短期内快速学会数据分析指南(文末送书)
- 5C++高级面试题:解释 C++ 中的移位操作符重载(Shift Operator Overloading)_c++中关于operator的面试题
- 6震惊!京东T4大佬面试整整三个月,才写了两份java面试笔记_京东t4面试题
- 7Hadoop Pipes “Server failed to authenticate”错误及解决_failed to authenticate with server: spnegoerror (1
- 8CAD软件(AutoCAD2025)学习笔记_功能区菜单栏
- 9Android 10.0 Launcher3拖拽图标进入hotseat自适应布局功能实现三
- 10微信小游戏排行榜功能快速开发教程_微信小游戏能接入群排行吗
2024年最全【python】爬取4K壁纸保存到本地文件夹【附源码】(5),已拿意向书_python 4k修复
赞
踩
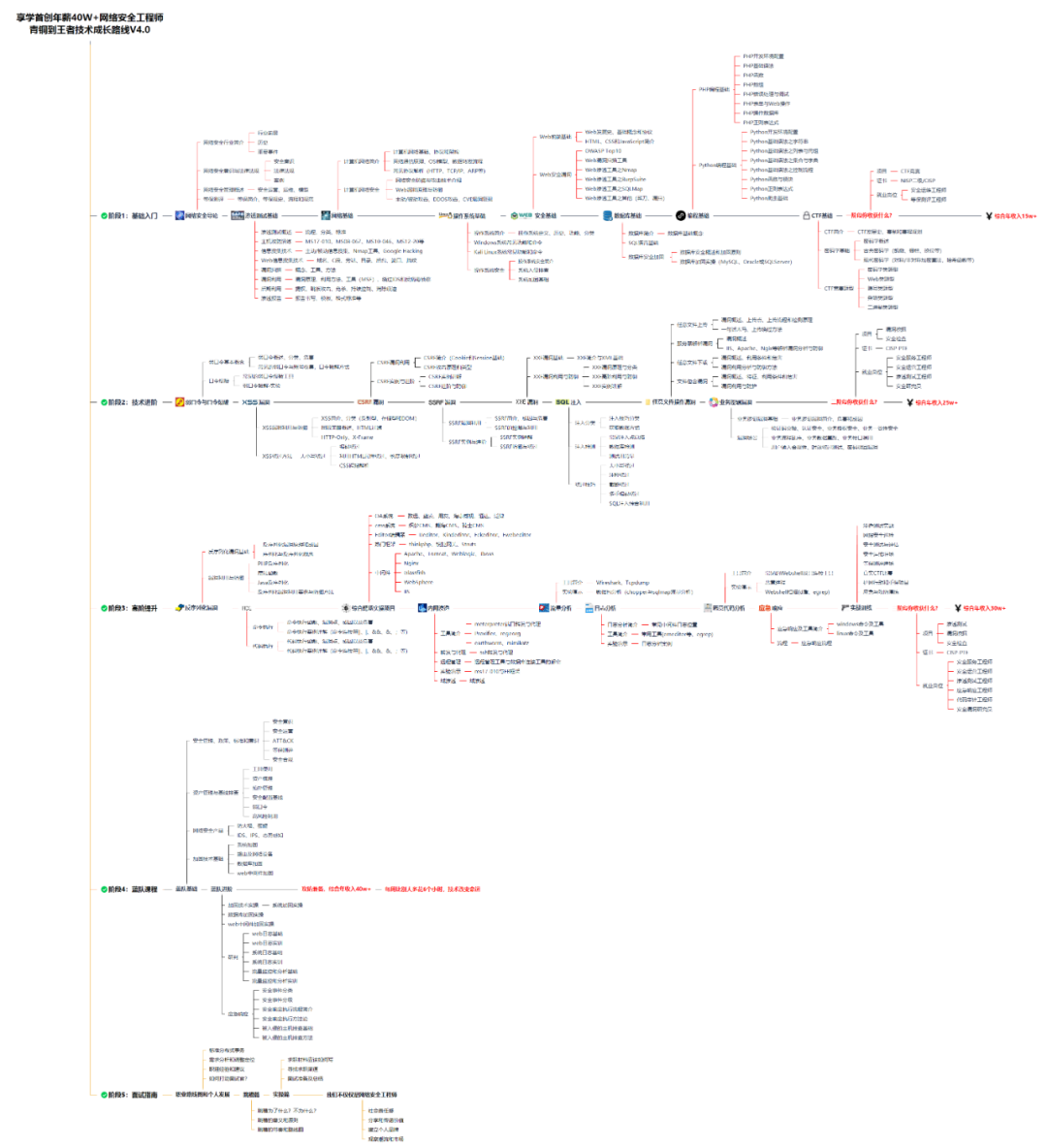
一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
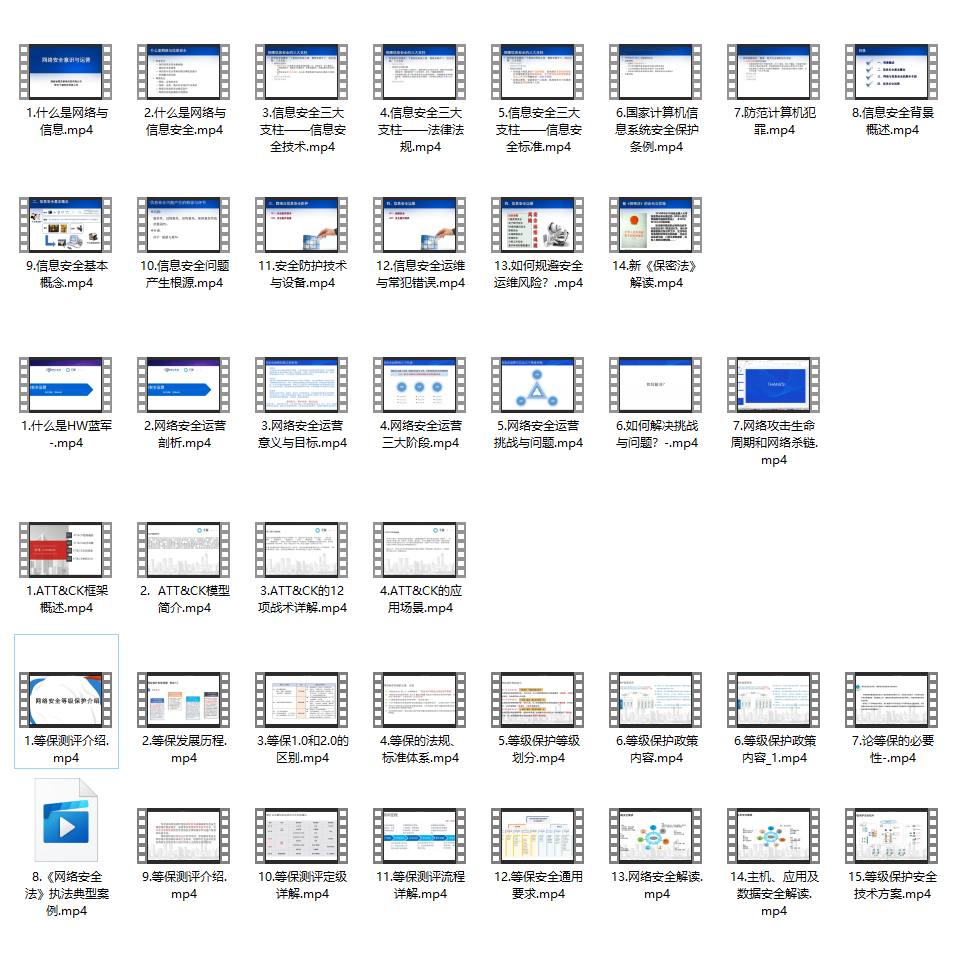
二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
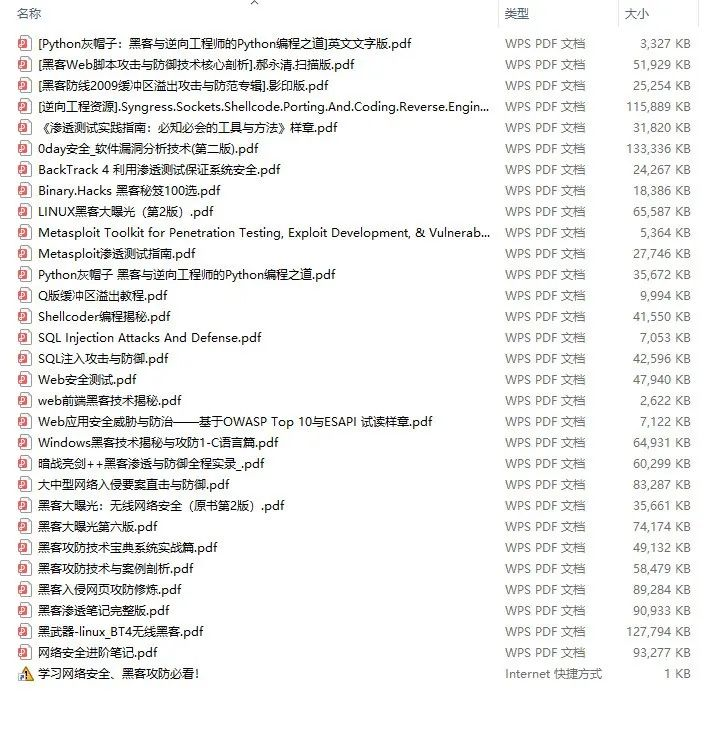
三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

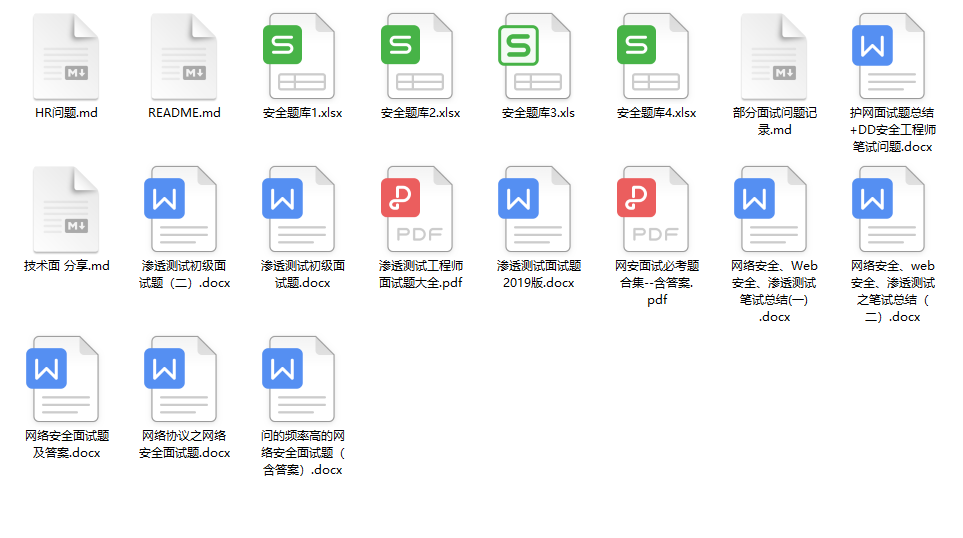
五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
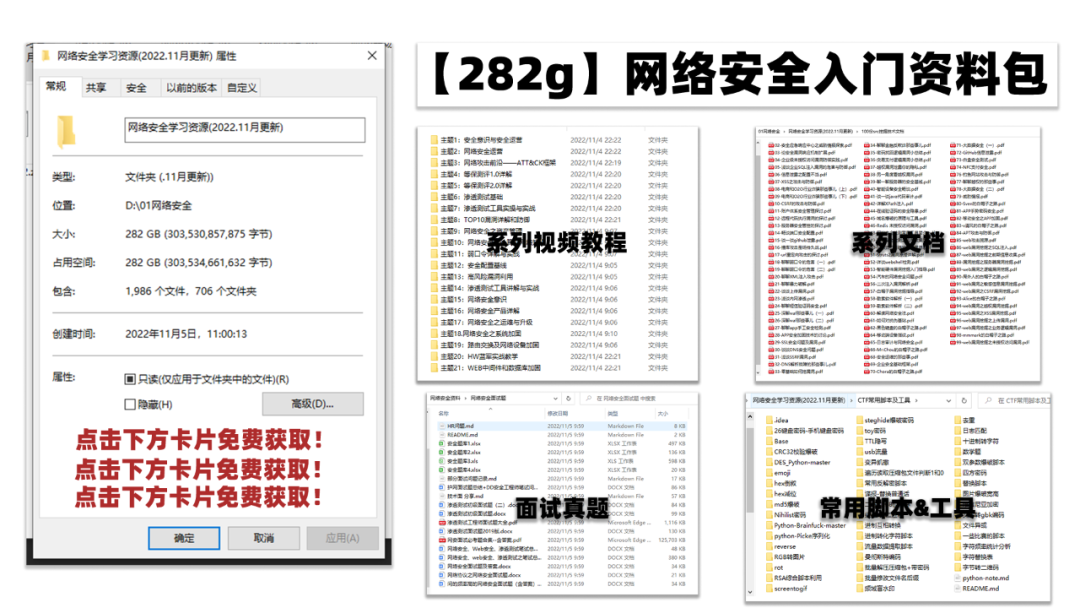
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
进入控制台输入:建议使用国内镜像源
pip install 模块名称 -i https://mirrors.aliyun.com/pypi/simple
- 1
- 2
我大致罗列了以下几种国内镜像源:
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple 阿里云 https://mirrors.aliyun.com/pypi/simple/ 豆瓣 https://pypi.douban.com/simple/ 百度云 https://mirror.baidu.com/pypi/simple/ 中科大 https://pypi.mirrors.ustc.edu.cn/simple/ 华为云 https://mirrors.huaweicloud.com/repository/pypi/simple/ 腾讯云 https://mirrors.cloud.tencent.com/pypi/simple/

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
效果图:
代码详解:
get_imgurl_list(url, imgurl_list)函数用来获取指定页面中的图片链接,并将这些链接存储在imgurl_list列表中。
- 使用
requests.get(url=url, headers=headers)发起请求获取页面内容。- 使用
etree.HTML(html_str)将页面内容转换为 etree 对象,方便后续使用 XPath 进行解析。- 通过 XPath 定位到图片链接,并添加到
imgurl_list中。
get_down_img(imgurl_list)函数用来下载图片到本地存储。
- 创建名为 “美女” 的文件夹用于存储下载的图片。
- 遍历
imgurl_list中的图片链接,逐个下载图片并保存到本地文件夹中。
- 在
if __name__ == '__main__':部分:
- 设置需要爬取的页数
page_number = 10。- 循环构建每一页的链接,如
https://www.moyublog.com/95-2-2-{i}.html。- 调用
get_imgurl_list()函数获取图片链接。- 调用
get_down_img()函数下载图片到本地。
代码流程:
- 导入必要的库和模块:
import requests # 用于发送HTTP请求
from lxml import etree # 用于解析HTML页面
import time # 用于控制爬取速度
import os # 用于文件操作
- 1
- 2
- 3
- 4
- 5
- 定义函数
get_imgurl_list(url, imgurl_list)用于获取图片链接:
def get_imgurl_list(url, imgurl_list):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
html_str = response.text
html_data = etree.HTML(html_str)
li_list = html_data.xpath("//ul[@class='clearfix']/li")
for li in li_list:
imgurl = li.xpath(".//a/img/@data-original")[0]
imgurl_list.append(imgurl)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 发送GET请求获取网页内容。
- 将网页内容转换为etree对象以便后续使用xpath进行解析。
- 使用xpath定位所有的li标签,并遍历每个li标签获取图片链接,将链接添加到
imgurl_list列表中。
- 定义函数
get_down_img(imgurl_list)用于下载图片:
def get_down_img(imgurl_list):
os.mkdir("美女")
n = 0
for img_url in imgurl_list:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
img_data = requests.get(url=img_url, headers=headers).content
img_path = './美女/' + str(n) + '.jpg'
with open(img_path, 'wb') as f:
f.write(img_data)
n += 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 创建名为"美女"的目录用于存放下载的图片。
- 遍历图片链接列表,逐个发送GET请求下载图片数据,并将图片写入本地文件。每张图片以数字编号命名。
- 主程序部分:
if __name__ == '__main__':
page_number = 10 # 爬取页数
imgurl_list = [] # 存放图片链接
for i in range(0, page_number + 1):
url = f'https://www.moyublog.com/95-2-2-{i}.html'
print(url)
get_imgurl_list(url, imgurl_list)
get_down_img(imgurl_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 设定要爬取的页数
page_number为10。- 初始化存放图片链接的列表
imgurl_list。
给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

