
- 1医生的黑匣子 - 医疗保健大模型&生成式人工智能(下一个前沿)_med palm2 房颤
- 2云端基于Docker的微服务与持续交付实践_docker 微服务 负载均衡
- 3大数据Hadoop之——部署hadoop+hive+Mysql环境(window11)_hadoop mysql_hive-site.xmlwenjian
- 4Oracle中的序列_oracle序列缓存与不缓存
- 5LeetCode第378题 有序矩阵中第K小的元素_有序矩阵寻找第k小
- 6从零开始:打造你的MySQL数据库环境_mysql本地搭建
- 7图像处理基本方法-c语言调用opencv实现人脸检测功能_c语言可以调openvc吗?
- 8github教程_git init 之后就位于分支master上
- 9【AI大模型】Prompt 提示词工程使用详解_大模型prompt 回车键怎么输入
- 10机器学习之特征提取 sklearn.feature_extraction_机器学习对数据进行特征提取
【Redis】Redis 初探:特性、应用场景与高并发架构演进之路
赞
踩
初识 Redis
- 盛赞 Redis
- Redis 特性
- Redis 使⽤场景
- ⽤好 Redis 的建议
- 正确安装启动 Redis
- Redis 重⼤版本
关于 Redis
Redis 是⼀种基于键值对(key-value)的 NoSQL 数据库,与很多键值对数据库不同的是,Redis中的值可以是由 string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)、Bitmaps(位图)、HyperLogLog、GEO(地理信息定位)等多种数据结构和算法组成,因此 Redis 可以满⾜很多的应⽤场景,⽽且因为 Redis 会将所有数据都存放再内存中,所以它的读写性能⾮常惊⼈。不仅如此,Redis 还可以将内存的数据利⽤快照和⽇志的形式保存到硬盘上,这样在发⽣类似断电或者机器故障的时候,内存中的数据不会“丢失”。除了上述功能以外,Redis 还提供了键过期、发布订阅、事务、流⽔线、Lua 脚本等附加功能。总之,如果在合适的场景使⽤好 Redis,它就会像⼀把瑞⼠军⼑⼀样所向披靡。
可以这么说,熟练使⽤和运维 Redis 已经成为开发运维⼈员的⼀个必备技能。
Redis 就是在内存中存储数据。既然这样,定义变量不也是在内存中存储数据吗?但 Redis 是在分布式系统中才能发挥威力,单机程序中就是使用变量即可。定义的变量是在当前服务器的进程内部空间,而进程具有隔离性。分布式系统势必有多个进程,Redis 就是为了突破这个进程的隔离性的问题,也就是用进程间通信,最常用的就是网络。这种方式可以让同个主机的多个进程间进行通信,也可以跨主机通信。Redis 就是基于网络把自己内存中的变量给别的进程甚至是别的主机的进程进行使用。
Redis 被运用于数据库、缓存、流式引擎、消息中间件等。
- 数据库:常见的比如 MySQL,有个大问题就是访问速度较慢。而 Redis 也可以作为数据库使用,优点就是比 MySQL 这种快很多,因为是用内存存储的,而 MySQL 是用硬盘存储的。
和 MySQL 相比最大的劣势是存储空间有限
- 缓存:经常访问的数据用 Redis 存储,比较少访问的用 MySQL 存储。用这种方式的代价是系统的复杂程度提升了,还有 Redis 和 MySQL 之间数据同步问题。
- 流式引擎:
- 消息中间件:Redis 的初心,最初是用来作为一个消息中间件的,分布式系统下的生产者消费者模型(但业界内有更多更专业的消息中间件使用)
服务端高并发分布式结构演进之路
概述
在进⾏技术学习过程中,由于⼤部分读者没有经历过⼀些中⼤型系统的实际经验,导致⽆法从全局理解⼀些概念,所以本⽂以⼀个 “电⼦商务” 应⽤为例,介绍从⼀百个到千万级并发情况下服务端的架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让⼤家对架构的演进有⼀个整体的认知,⽅便⼤家对后续知识做深⼊学习时有⼀定的整体视野。
常⻅概念
在正式引⼊架构演进之前,为避免读者对架构中的概念完全不了解导致低效沟通,优先对其中⼀些⽐较重要的概念做前置介绍:
基本概念
应⽤(Application)/ 系统(System)
为了完成⼀整套服务的⼀个程序或者⼀组相互配合的程序群。⽣活例⼦类⽐:为了完成⼀项任务,⽽搭建的由⼀个⼈或者⼀群相互配的⼈组成的团队。
一个应用就是一个/一组服务器程序
模块(Module)/ 组件(Component)
当应⽤较复杂时,为了分离职责,将其中具有清晰职责的、内聚性强的部分,抽象出概念,便于理解。⽣活例⼦类⽐:军队中为了进⾏某据点的攻克,将⼈员分为突击⼩组、爆破⼩组、掩护⼩组、通信⼩组等。
分布式(Distributed)
一台主机的硬件资源是有限的,包括但不限于:
- CPU
- 内存
- 硬盘
- 网络
- …
系统中的多个模块被部署于不同服务器之上,即可以将该系统称为分布式系统。如 Web 服务器与数据库分别⼯作在不同的服务器上,或者多台 Web 服务器被分别部署在不同服务器上。⽣活例⼦类⽐:为了更好的满⾜现实需要,⼀个在同⼀个办公场地的⼯作⼩组被分散到多个城市的不同⼯作场地中进⾏远程配合⼯作完成⽬标。跨主机之间的模块之间的通信基本要借助⽹络⽀撑完成。
引入分布式是万不得已,系统复杂性会大大提高,出现 bug 的概率越高。能一台主机搞定最好
集群(Cluster)
被部署于多台服务器上的、为了实现特定⽬标的⼀个/组特定的组件,整个整体被称为集群。⽐如多个 MySQL ⼯作在不同服务器上,共同提供数据库服务⽬标,可以被称为⼀组数据库集群。⽣活例⼦类⽐:为了解决军队攻克防守坚固的⼤城市的作战⽬标,指挥部将⼤批炮兵部队集中起来形成⼀个炮兵打击集群。
分布式 vs 集群。通常不⽤太严格区分两者的细微概念,细究的话,分布式强调的是物理形态,即⼯作在不同服务器上并且通过⽹络通信配合完成任务;⽽集群更在意逻辑形态,即是否为了完成特定服务⽬标。
主(Master)/ 从(Slave)
集群中,通常有⼀个程序需要承担更多的职责,被称为主;其他承担附属职责的被称为从。⽐如MySQL 集群中,只有其中⼀台服务器上数据库允许进⾏数据的写⼊(增/删/改),其他数据库的数据修改全部要从这台数据库同步⽽来,则把那台数据库称为主库,其他数据库称为从库。
中间件(Middleware)
⼀类提供不同应⽤程序⽤于相互通信的软件,即处于不同技术、⼯具和数据库之间的桥梁。⽣活例⼦类⽐:⼀家饭店开始时,会每天去市场挑选买菜,但随着饭店业务量变⼤,成⽴⼀个采购部,由采购部专职于采买业务,称为厨房和菜市场之间的桥梁。
中间件是和业务无关的服务(功能更通用的服务)
- 数据库
- 缓存
- 消息队列
- …
评价指标(Metric)
可⽤性(Availability)
考察单位时间段内,系统可以正常提供服务的概率/期望。例如: 年化系统可⽤性 = 系统正常提供服务时⻓ / ⼀年总时⻓。这⾥暗含着⼀个指标,即如何评价系统提供⽆法是否正常,我们就不深⼊了。平时我们常说的 4 个 9 即系统可以提供 99.99% 的可⽤性,5 个 9 是 99.999% 的可⽤性,以此类推。我们平时只是⽤⾼可⽤(High Availability HA)这个⾮量化⽬标简要表达我们系统的追求。
系统可用的时间
响应时⻓(Response Time RT)
指⽤⼾完成输⼊到系统给出⽤⼾反应的时⻓。例如点外卖业务的响应时⻓ = 拿到外卖的时刻 - 完成点单的时刻。通常我们需要衡量的是最⻓响应时⻓、平均响应时⻓和中位数响应时⻓。这个指标原则上是越⼩越好,但很多情况下由于实现的限制,需要根据实际情况具体判断
衡量服务器性能
吞吐(Throughput)vs 并发(Concurrent)
吞吐考察单位时间段内,系统可以成功处理的请求的数量。并发指系统同⼀时刻⽀持的请求最⾼量。例如⼀条辆⻋道⾼速公路,⼀分钟可以通过 20 辆⻋,则并发是 2,⼀分钟的吞吐量是 20。实践中,并发量往往⽆法直接获取,很多时候都是⽤极短的时间段(⽐如 1 秒)的吞吐量做代替。我们平时⽤⾼并发(Hight Concurrnet)这个⾮量化⽬标简要表达系统的追求。
衡量系统的处理请求的能力,也是衡量性能的一种方式
架构演进
单机架构
初期,我们需要利⽤我们精⼲的技术团队,快速将业务系统投⼊市场进⾏检验,并且可以迅速响应变化要求。但好在前期⽤⼾访问量很少,没有对我们的性能、安全等提出很⾼的要求,⽽且系统架构简单,⽆需专业的运维团队,所以选择单机架构是合适的。

其实大部分公司的产品都是这种单机架构。
现在的计算机硬件性能很好,哪怕只有一台主机,也能支持非常高的并发、非常大的数据存储
⽤⼾在浏览器中输⼊ www.bit.com,⾸先经过 DNS 服务将域名解析成 IP 地址 10.102.41.1,随后浏览器访问该 IP 对应的应⽤服务。
相关软件
Web 服务器软件:Tomcat、Netty、Nginx、Apache 等
数据库软件:MySQL、Oracle、PostgreSQL、SQL Server 等
⽬前的训练⼤多针对该阶段的业务系统,包括本科毕业设计的系统实现。
应⽤数据分离架构
随着系统的上线,我们不出意外地获得了成功。市场上出现了⼀批忠实于我们的⽤⼾,使得系统的访问量逐步上升,逐渐逼近了硬件资源的极限,同时团队也在此期间积累了对业务流程的⼀批经验。⾯对当前的性能压⼒,我们需要未⾬绸缪去进⾏系统重构、架构挑战,以提升系统的承载能⼒。但由于预算仍然很紧张,我们选择了将应⽤和数据分离的做法,可以最⼩代价的提升系统的承载能⼒。
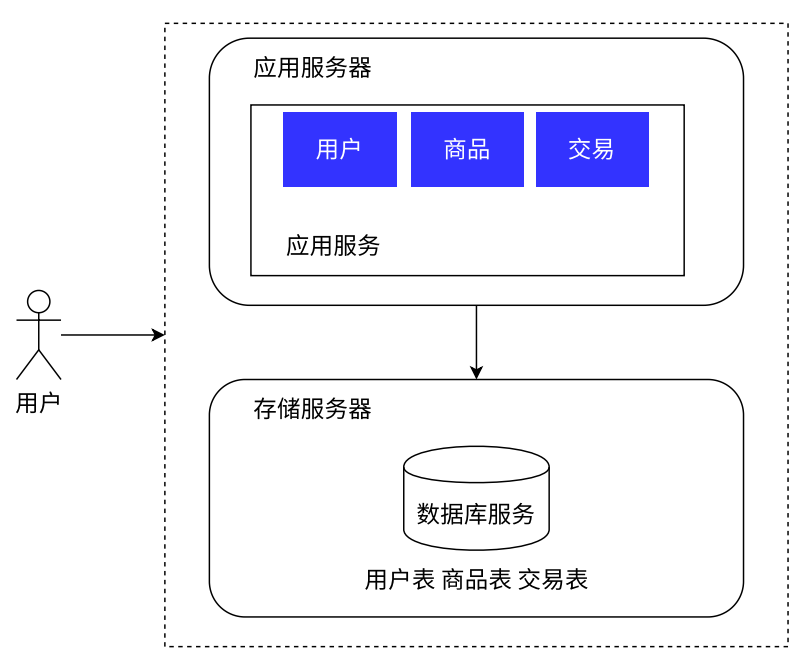
应用服务器里面可能业务逻辑比较多,比较吃 CPU 和内存。而数据库服务器是需要更大的存储空间和更快的数据访问速度,可以配置更大硬盘的服务器,甚至可以上 SSD(固态硬盘)。
- 机械硬盘,便宜,慢
- 固态硬盘,贵,快
和之前架构的主要区别在于将数据库服务独⽴部署在同⼀个数据中⼼的其他服务器上,应⽤服务通过⽹络访问数据。
应⽤服务集群架构
我们的系统受到了⽤⼾的欢迎,并且出现了爆款,单台应⽤服务器已经⽆法满⾜需求了。我们的单机应⽤服务器⾸先遇到了瓶颈,摆在我们技术团队⾯前的有两种⽅案,⼤家针对⽅案的优劣展⽰了热烈的讨论:
- 垂直扩展 / 纵向扩展 Scale Up。通过购买性能更优、价格更⾼的应⽤服务器来应对更多的流量。这种⽅案的优势在于完全不需要对系统软件做任何的调整;但劣势也很明显:硬件性能和价格的增⻓关系是⾮线性的,意味着选择性能 2 倍的硬件可能需要花费超过 4 倍的价格,其次硬件性能提升是有明显上限的。
- ⽔平扩展 / 横向扩展 Scale Out。通过调整软件架构,增加应⽤层硬件,将⽤⼾流量分担到不同的应⽤层服务器上,来提升系统的承载能⼒。这种⽅案的优势在于成本相对较低,并且提升的上限空间也很⼤。但劣势是带给系统更多的复杂性,需要技术团队有更丰富的经验。
经过团队的学习、调研和讨论,最终选择了⽔平扩展的⽅案,来解决该问题,但这需要引⼊⼀个新的组件⸺负载均衡:为了解决⽤⼾流量向哪台应⽤服务器分发的问题,需要⼀个专⻔的系统组件做流量分发。实际中负载均衡不仅仅指的是⼯作在应⽤层的,甚⾄可能是其他的⽹络层之中。同时流量调度算法也有很多种,这⾥简单介绍⼏种较为常⻅的:
- Round-Robin 轮询算法。即⾮常公平地将请求依次分给不同的应⽤服务器。
- Weight-Round-Robin 轮询算法。为不同的服务器(⽐如性能不同)赋予不同的权重(weight),能者多劳。
- ⼀致哈希散列算法。通过计算⽤⼾的特征值(⽐如 IP 地址)得到哈希值,根据哈希结果做分发,优点是确保来⾃相同⽤⼾的请求总是被分给指定的服务器。也就是我们平时遇到的专项客⼾经理服务。

负载均衡这个组件这么看起来不是也是直接承担了这多个应用服务器的请求吗?它能顶得住吗?
负载均衡对于请求的承载能力远超过应用服务器,负载均衡是负责分配工作(领导),应用服务器是负责执行任务(组员)。
可能出现请求量大到负载均衡也承担不住呢?
当然可能,只能再引入更多的负载均衡。
相关软件
负载均衡软件:Nginx、HAProxy、LVS、F5 等
读写分离 / 主从分离架构
上面提到,我们把⽤⼾的请求通过负载均衡分发到不同的应⽤服务器之后,可以并⾏处理了,并且可以随着业务的增⻓,可以动态扩张服务器的数量来缓解压⼒。但是现在的架构⾥,⽆论扩展多少台服务器,这些请求最终都会从数据库读写数据,到⼀定程度之后,数据的压⼒称为系统承载能⼒的瓶颈点。我们可以像扩展应⽤服务器⼀样扩展数据库服务器么?答案是否定的,因为数据库服务有其特殊性:如果将数据分散到各台服务器之后,数据的⼀致性将⽆法得到保障。所谓数据的⼀致性,此处是指:针对同⼀个系统,⽆论何时何地,我们都应该看到⼀个始终维持统⼀的数据。想象⼀下,银⾏管理的账⼾⾦额,如果收到⼀笔转账之后,⼀份数据库的数据修改了,但另外的数据库没有修改,则⽤⼾得到的存款⾦额将是错误的。
我们采⽤的解决办法是这样的,保留⼀个主要的数据库作为写⼊数据库,其他的数据库作为从属数据库。从库的所有数据全部来⾃主库的数据,经过同步后,从库可以维护着与主库⼀致的数据。然后为了分担数据库的压⼒,我们可以将写数据请求全部交给主库处理,但读请求分散到各个从库中。由于⼤部分的系统中,读写请求都是不成⽐例的,例如 100 次读 1 次写,所以只要将读请求由各个从库分担之后,数据库的压⼒就没有那么⼤了。当然这个过程不是⽆代价的,主库到从库的数据同步其实是由时间成本的,但这个问题我们暂时不做进⼀步探讨。

应⽤中需要对读写请求做分离处理,所以可以利⽤⼀些数据库中间件,将请求分离的职责托管出去。
相关软件
MyCat、TDDL、Amoeba、Cobar 等类似数据库中间件等
引⼊缓存⸺冷热分离架构
随着访问量继续增加,发现业务中⼀些数据的读取频率远⼤于其他数据的读取频率。我们把这部分数据称为热点数据,与之相对应的是冷数据。针对热数据,为了提升其读取的响应时间,可以增加本地缓存,并在外部增加分布式缓存,缓存热⻔商品信息或热⻔商品的 html ⻚⾯等。通过缓存能把绝⼤多数请求在读写数据库前拦截掉,大大降低数据库压⼒。其中涉及的技术包括:使⽤ memcached 作为本地缓存,使⽤ Redis 作为分布式缓存,还会涉及缓存⼀致性、缓存穿透/击穿、缓存雪崩、热点数据集中失效等问题。
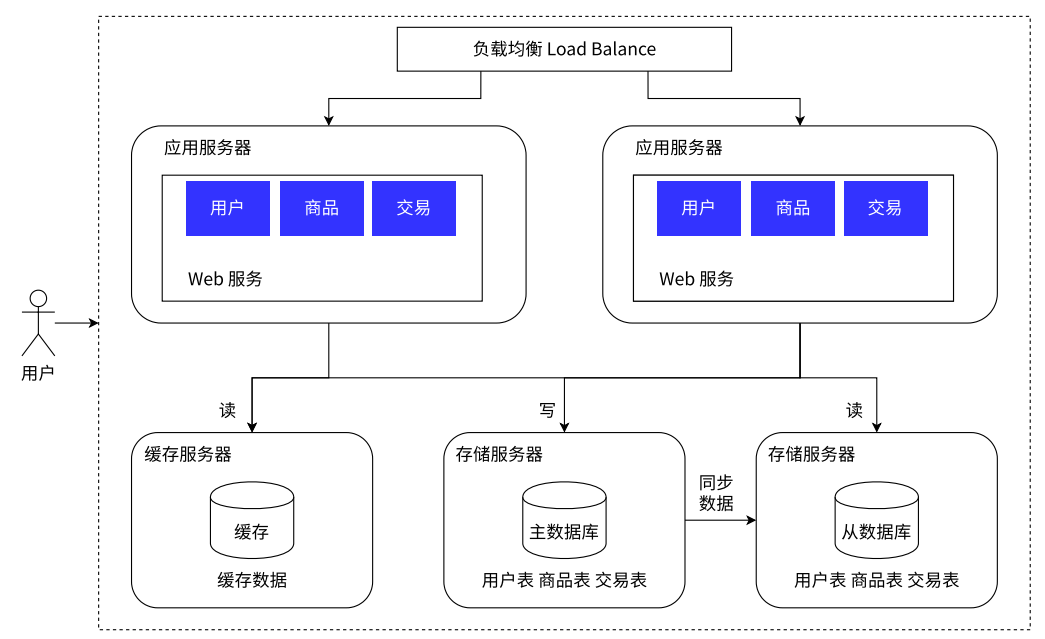
引入的问题:数据库和缓存的数据一致性的问题
相关软件
Memcached、Redis 等缓存软件
垂直分库
随着业务的数据量增⼤,⼤量的数据存储在同⼀个库中已经显得有些⼒不从⼼了,所以可以按照业务,将数据分别存储。⽐如针对评论数据,可按照商品ID进⾏hash,路由到对应的表中存储;针对⽀付记录,可按照⼩时创建表,每个⼩时表继续拆分为⼩表,使⽤⽤⼾ID或记录编号来路由数据。只要实时操作的表数据量⾜够⼩,请求能够⾜够均匀的分发到多台服务器上的⼩表,那数据库就能通过⽔平扩展的⽅式来提⾼性能。其中前⾯提到的 Mycat 也⽀持在⼤表拆分为⼩表情况下的访问控制。这种做法显著的增加了数据库运维的难度,对 DBA 的要求较⾼。数据库设计到这种结构时,已经可以称为分布式数据库,但是这只是⼀个逻辑的数据库整体,数据库⾥不同的组成部分是由不同的组件单独来实现的,如分库分表的管理和请求分发,由 Mycat 实现,SQL 的解析由单机的数据库实现,读写分离可能由⽹关和消息队列来实现,查询结果的汇总可能由数据库接⼝层来实现等等,这种架构其实是 MPP(⼤规模并⾏处理)架构的⼀类实现。

这个数据库指的是逻辑上的数据库,create database 创建的那个东西
相关软件
Greenplum、TiDB、Postgresql XC、HAWQ等,商⽤的如南⼤通⽤的GBase、睿帆科技的雪球DB、华为的LibrA 等
业务拆分⸺微服务
随着⼈员增加,业务发展,我们将业务分给不同的开发团队去维护,每个团队独⽴实现⾃⼰的微服务,然后互相之间对数据的直接访问进⾏隔离,可以利⽤ Gateway、消息总线等技术,实现相互之间的调⽤关联。甚⾄可以把⼀些类似⽤⼾管理、安全管理、数据采集等业务提成公共服务。
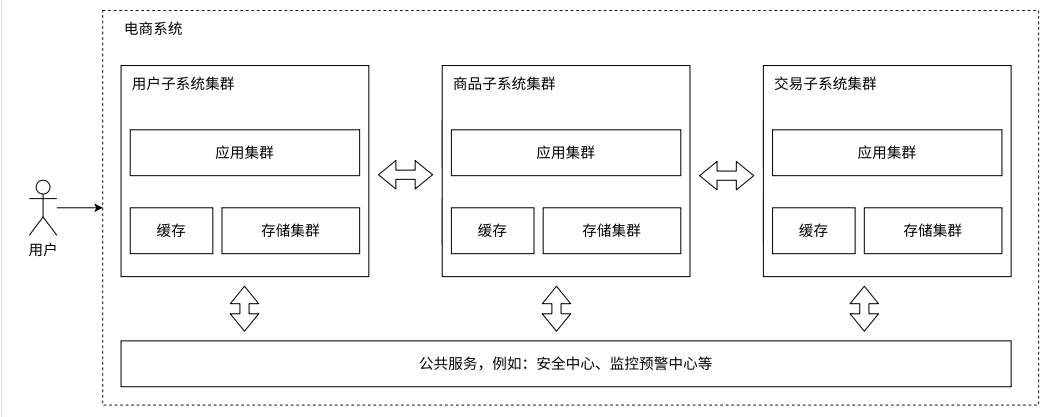
微服务的问题:
- 系统的性能下降,拆出来更多的服务,多个功能之间就更依赖网络通信,可能会比硬盘还慢的,要想保证性能不下降太多只能引入更多的机器、硬件资源。(千兆网卡会比硬盘慢,万兆网卡就可以比硬盘快了)
- 系统复杂程度提高,可用性受到影响,出现 bug 的概率就大了,就需要一系列可用手段来保证系统的可用性(更丰富的监控报警,以及配套的运维人员)
微服务的优势:
- 方便管理
- 方便功能的复用
- 可以给不同的服务进行不同的部署
尾声
⾄此,⼀个还算合理的⾼可⽤、⾼并发系统的基本雏形已显。注意,以上所说的架构演变顺序只是针对某个侧⾯进⾏单独的改进,在实际场景中,可能同⼀时间会有⼏个问题需要解决,或者可能先达到瓶颈的是另外的⽅⾯,这时候就应该按照实际问题实际解决。如在政府类的并发量可能不⼤,但业务可能很丰富的场景,⾼并发就不是重点解决的问题,此时优先需要的可能会是丰富需求的解决⽅案。
对于单次实施并且性能指标明确的系统,架构设计到能够⽀持系统的性能指标要求就⾜够了,但要留有扩展架构的接⼝以便不备之需。对于不断发展的系统,如电商平台,应设计到能满⾜下⼀阶段⽤⼾量和性能指标要求的程度,并根据业务的增⻓不断的迭代升级架构,以⽀持更⾼的并发和更丰富的业务。
所谓的“⼤数据”其实是海量数据采集清洗转换、数据存储、数据分析、数据服务等场景解决⽅案的⼀个统称,在每⼀个场景都包含了多种可选的技术,如数据采集有Flume、Sqoop、Kettle等,数据存储有分布式⽂件系统HDFS、FastDFS,NoSQL数据库HBase、MongoDB等,数据分析有Spark技术栈、机器学习算法等。总的来说⼤数据架构就是根据业务的需求,整合各种⼤数据组件组合⽽成的架构,⼀般会提供分布式存储、分布式计算、多维分析、数据仓库、机器学习算法等能⼒。⽽服务端架构更多指的是应⽤组织层⾯的架构,底层能⼒往往是由⼤数据架构来提供。

