
热门标签
热门文章
- 1AI智能降重软件大全,免费最新AI智能降重软件_能够降重ai的 app
- 2C语言代码示范与讲解+C语言编程规范及基础语法+编程实战_c语言编码规范 标准
- 3如何处理数据一致性和分布式锁
- 4Swift-UIScrollView使用详解_swiftui scrollview使用
- 5机器人感知专题之七:无人车行为预测_autoware behavior prediction
- 6Verilog语言快速入门(一)
- 7obs直播画面 清晰+流程 设置_obs直播画质清晰度
- 8【机器学习-17】数据变换---小波变换特征提取及应用案列介绍_基于小波变换的特征提取
- 9【ONLYOFFICE震撼8.1】ONLYOFFICE8.1版本桌面编辑器测评_onlyoffice pdf转word的api
- 10动态规划算法思想和应用_动态规划算法的基本思想
当前位置: article > 正文
图解Spark Transformation算子_agg算子
作者:一键难忘520 | 2024-06-19 12:24:49
赞
踩
agg算子
0. 写在前面
Spark总共有两类算子,分别是Transformation算子和Action算子。Transformation算子变换不触发提交作业,而Action算子会触发SparkContext提交Job作业,下面主要使用pySpark API来作为事例,图解Spark的Transformation算子。
1. join
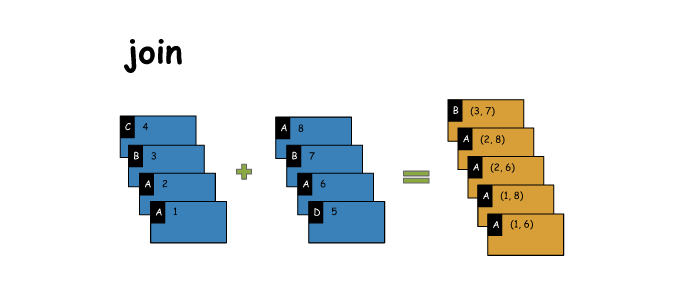
# join
x = sc.parallelize([('C',4),('B',3),('A',2),('A',1)])
y = sc.parallelize([('A',8),('B',7),('A',6),('D',5)])
z = x.join(y)
print(x.collect())
print(y.collect())
print(z.collect())
[('C', 4), ('B', 3), ('A', 2), ('A', 1)]
[('A', 8), ('B', 7), ('A', 6), ('D', 5)]
[('A', (2, 8)), ('A', (2, 6)), ('A', (1, 8)), ('A', (1, 6)), ('B', (3, 7))]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2. leftOuterJoin
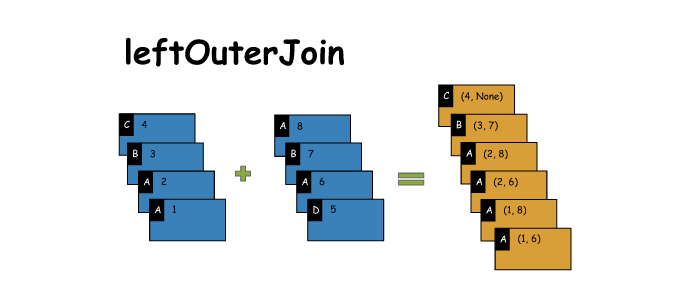
# leftOuterJoin
x = sc.parallelize([('C',4),('B',3),('A',2),('A',1)])
y = sc.parallelize([('A',8),('B',7),('A',6),('D',5)])
z = x.leftOuterJoin(y)
print(x.collect())
print(y.collect())
print(z.collect())
[('C', 4), ('B', 3), ('A', 2), ('A', 1)]
[('A', 8), ('B', 7), ('A', 6), ('D', 5)]
[('A', (2, 8)), ('A', (2, 6)), ('A', (1, 8)), ('A', (1, 6)), ('C', (4, None)), ('B', (3, 7))]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3. rightOuterJoin
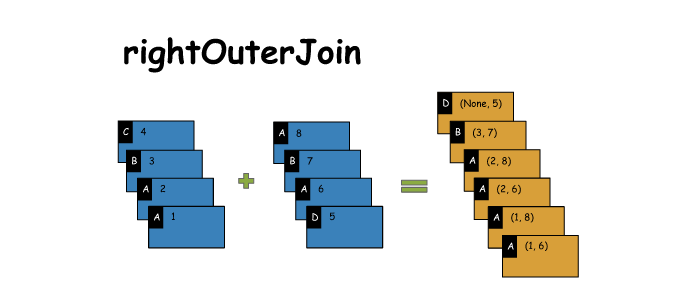
# rightOuterJoin
x = sc.parallelize([('C',4),('B',3),('A',2),('A',1)])
y = sc.parallelize([('A',8),('B',7),('A',6),('D',5)])
z = x.rightOuterJoin(y)
print(x.collect())
print(y.collect())
print(z.collect())
[('C', 4), ('B', 3), ('A', 2), ('A', 1)]
[('A', 8), ('B', 7), ('A', 6), ('D', 5)]
[('A', (2, 8)), ('A', (2, 6)), ('A', (1, 8)), ('A', (1, 6)), ('B', (3, 7)), ('D', (None, 5))]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4. partitionBy
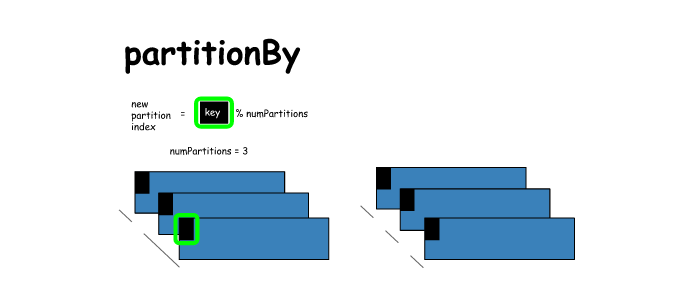
# partitionBy
x = sc.parallelize([(0,1),(1,2),(2,3)],2)
y = x.partitionBy(numPartitions = 3, partitionFunc = lambda x: x) # only key is passed to paritionFunc
print(x.glom().collect())
print(y.glom().collect())
[[(0, 1)], [(1, 2), (2, 3)]]
[[(0, 1)], [(1, 2)], [(2, 3)]]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5. combineByKey
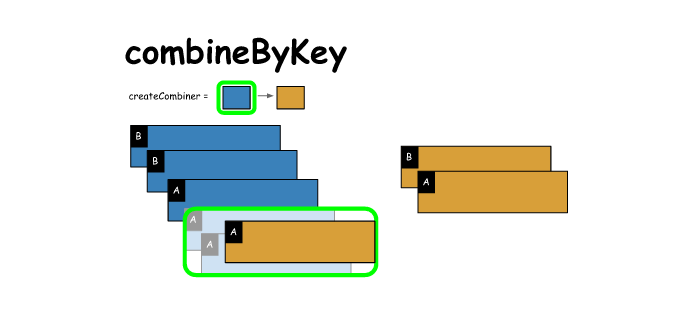
# combineByKey
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
createCombiner = (lambda el: [(el,el**2)])
mergeVal = (lambda aggregated, el: aggregated + [(el,el**2)]) # append to aggregated
mergeComb = (lambda agg1,agg2: agg1 + agg2 ) # append agg1 with agg2
y = x.combineByKey(createCombiner,mergeVal,mergeComb)
print(x.collect())
print(y.collect())
[('B', 1), ('B', 2), ('A', 3), ('A', 4), ('A', 5)]
[('A', [(3, 9), (4, 16), (5, 25)]), ('B', [(1, 1), (2, 4)])]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6. aggregateByKey
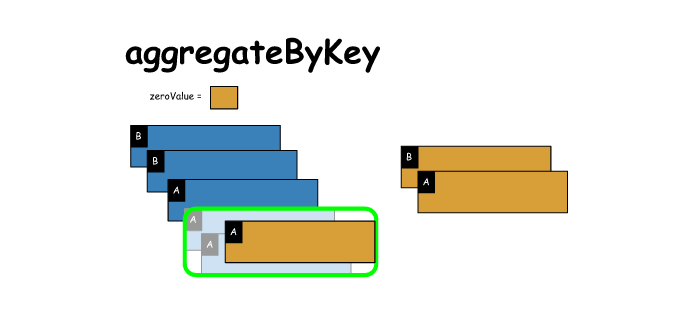
# aggregateByKey
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
zeroValue = [] # empty list is 'zero value' for append operation
mergeVal = (lambda aggregated, el: aggregated + [(el,el**2)])
mergeComb = (lambda agg1,agg2: agg1 + agg2 )
y = x.aggregateByKey(zeroValue,mergeVal,mergeComb)
print(x.collect())
print(y.collect())
[('B', 1), ('B', 2), ('A', 3), ('A', 4), ('A', 5)]
[('A', [(3, 9), (4, 16), (5, 25)]), ('B', [(1, 1), (2, 4)])]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
7. foldByKey
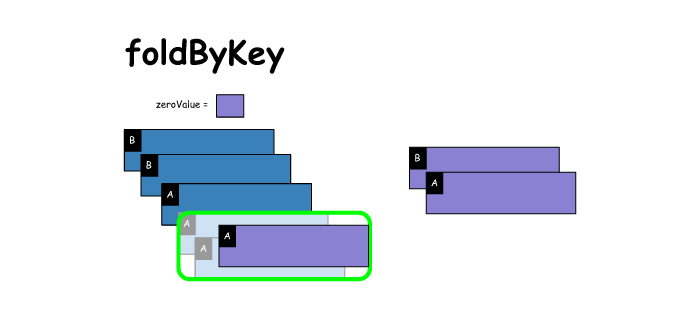
# foldByKey
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
zeroValue = 1 # one is 'zero value' for multiplication
y = x.foldByKey(zeroValue,lambda agg,x: agg*x ) # computes cumulative product within each key
print(x.collect())
print(y.collect())
[('B', 1), ('B', 2), ('A', 3), ('A', 4), ('A', 5)]
[('A', 60), ('B', 2)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
8. groupByKey
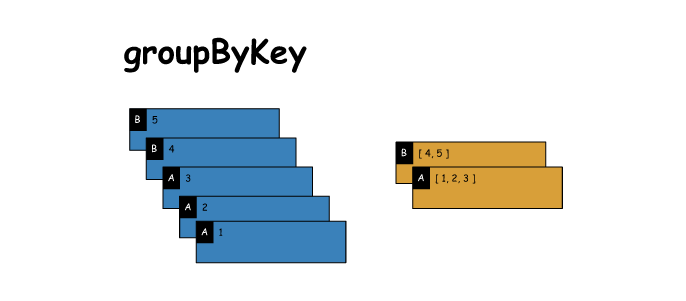
# groupByKey
x = sc.parallelize([('B',5),('B',4),('A',3),('A',2),('A',1)])
y = x.groupByKey()
print(x.collect())
print([(j[0],[i for i in j[1]]) for j in y.collect()])
[('B', 5), ('B', 4), ('A', 3), ('A', 2), ('A', 1)]
[('A', [3, 2, 1]), ('B', [5, 4])]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
9. flatMapValues
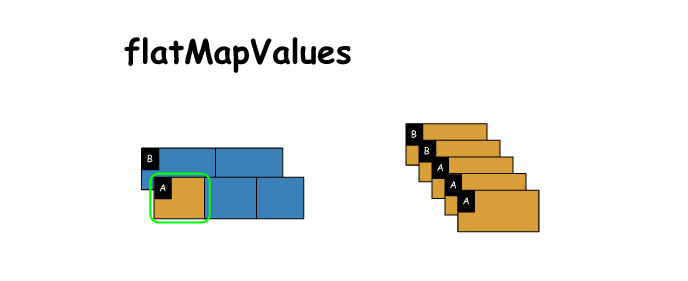
# flatMapValues
x = sc.parallelize([('A',(1,2,3)),('B',(4,5))])
y = x.flatMapValues(lambda x: [i**2 for i in x]) # function is applied to entire value, then result is flattened
print(x.collect())
print(y.collect())
[('A', (1, 2, 3)), ('B', (4, 5))]
[('A', 1), ('A', 4), ('A', 9), ('B', 16), ('B', 25)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
10. mapValues
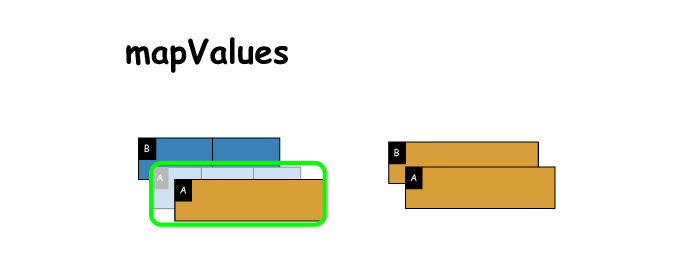
# mapValues
x = sc.parallelize([('A',(1,2,3)),('B',(4,5))])
y = x.mapValues(lambda x: [i**2 for i in x]) # function is applied to entire value
print(x.collect())
print(y.collect())
[('A', (1, 2, 3)), ('B', (4, 5))]
[('A', [1, 4, 9]), ('B', [16, 25])]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
11. groupWith
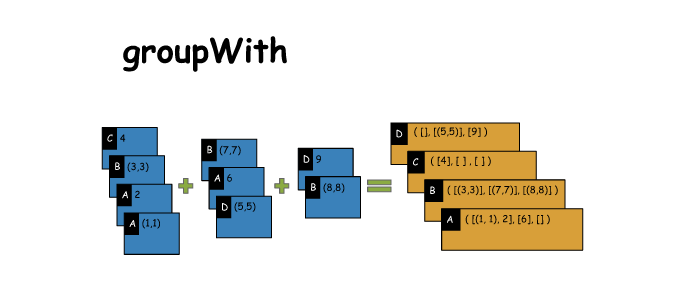
# groupWith
x = sc.parallelize([('C',4),('B',(3,3)),('A',2),('A',(1,1))])
y = sc.parallelize([('B',(7,7)),('A',6),('D',(5,5))])
z = sc.parallelize([('D',9),('B',(8,8))])
a = x.groupWith(y,z)
print(x.collect())
print(y.collect())
print(z.collect())
print("Result:")
for key,val in list(a.collect()):
print(key, [list(i) for i in val])
[('C', 4), ('B', (3, 3)), ('A', 2), ('A', (1, 1))]
[('B', (7, 7)), ('A', 6), ('D', (5, 5))]
[('D', 9), ('B', (8, 8))]
Result:
D [[], [(5, 5)], [9]]
C [[4], [], []]
B [[(3, 3)], [(7, 7)], [(8, 8)]]
A [[2, (1, 1)], [6], []]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
12. cogroup
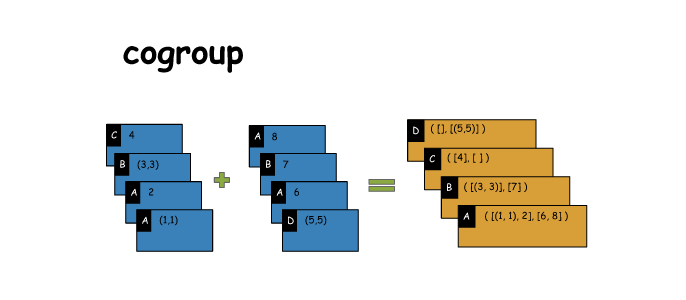
# cogroup
x = sc.parallelize([('C',4),('B',(3,3)),('A',2),('A',(1,1))])
y = sc.parallelize([('A',8),('B',7),('A',6),('D',(5,5))])
z = x.cogroup(y)
print(x.collect())
print(y.collect())
for key,val in list(z.collect()):
print(key, [list(i) for i in val])
[('C', 4), ('B', (3, 3)), ('A', 2), ('A', (1, 1))]
[('A', 8), ('B', 7), ('A', 6), ('D', (5, 5))]
A [[2, (1, 1)], [8, 6]]
C [[4], []]
B [[(3, 3)], [7]]
D [[], [(5, 5)]]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
13. sampleByKey
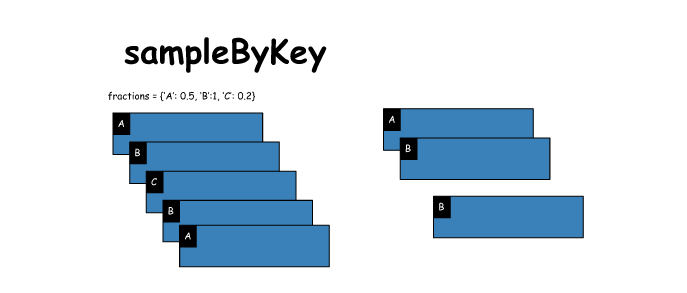
# sampleByKey
x = sc.parallelize([('A',1),('B',2),('C',3),('B',4),('A',5)])
y = x.sampleByKey(withReplacement=False, fractions={'A':0.5, 'B':1, 'C':0.2})
print(x.collect())
print(y.collect())
[('A', 1), ('B', 2), ('C', 3), ('B', 4), ('A', 5)]
[('B', 2), ('C', 3), ('B', 4)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
14. subtractByKey
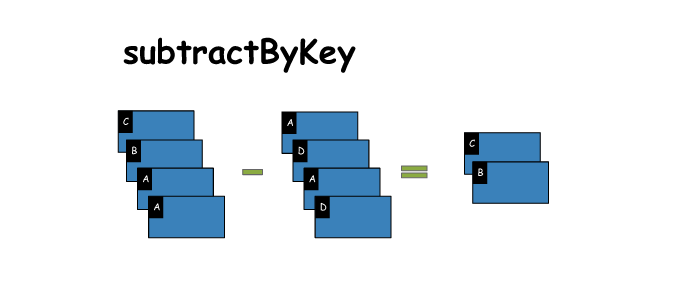
# subtractByKey
x = sc.parallelize([('C',1),('B',2),('A',3),('A',4)])
y = sc.parallelize([('A',5),('D',6),('A',7),('D',8)])
z = x.subtractByKey(y)
print(x.collect())
print(y.collect())
print(z.collect())
[('C', 1), ('B', 2), ('A', 3), ('A', 4)]
[('A', 5), ('D', 6), ('A', 7), ('D', 8)]
[('C', 1), ('B', 2)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
15. subtract
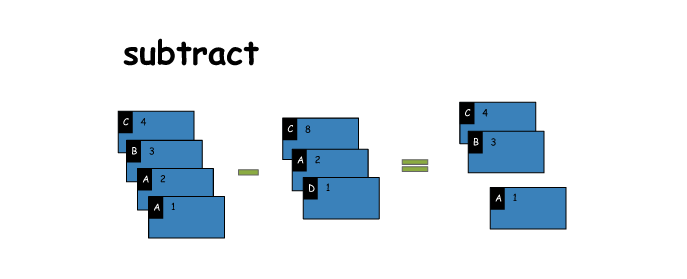
# subtract
x = sc.parallelize([('C',4),('B',3),('A',2),('A',1)])
y = sc.parallelize([('C',8),('A',2),('D',1)])
z = x.subtract(y)
print(x.collect())
print(y.collect())
print(z.collect())
[('C', 4), ('B', 3), ('A', 2), ('A', 1)]
[('C', 8), ('A', 2), ('D', 1)]
[('A', 1), ('C', 4), ('B', 3)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
16. keyBy
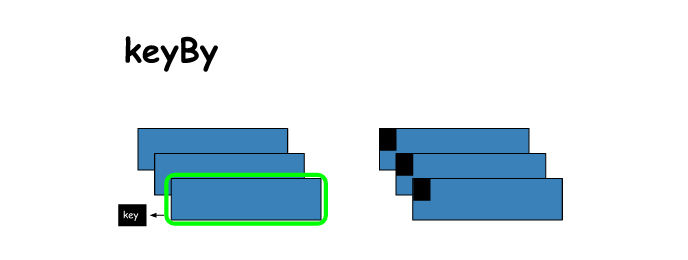
# keyBy
x = sc.parallelize([1,2,3])
y = x.keyBy(lambda x: x**2)
print(x.collect())
print(y.collect())
[1, 2, 3]
[(1, 1), (4, 2), (9, 3)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
17. repartition
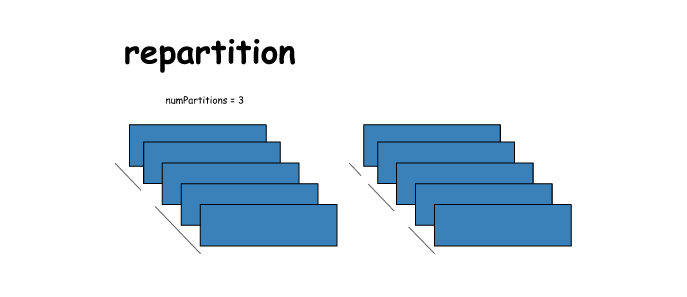
# repartition
x = sc.parallelize([1,2,3,4,5],2)
y = x.repartition(numPartitions=3)
print(x.glom().collect())
print(y.glom().collect())
[[1, 2], [3, 4, 5]]
[[], [1, 2, 3, 4], [5]]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
18. coalesce
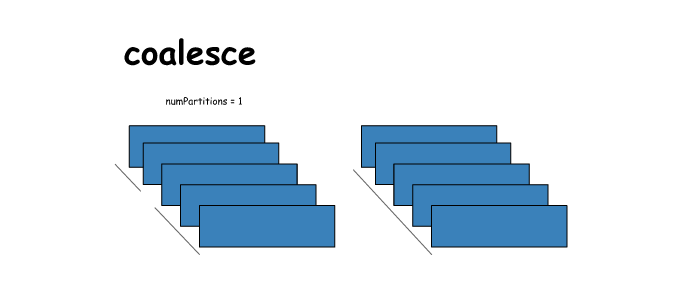
# coalesce
x = sc.parallelize([1,2,3,4,5],2)
y = x.coalesce(numPartitions=1)
print(x.glom().collect())
print(y.glom().collect())
[[1, 2], [3, 4, 5]]
[[1, 2, 3, 4, 5]]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
19. zip
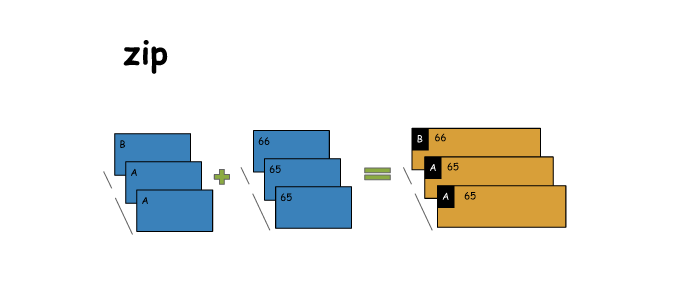
# zip
x = sc.parallelize(['B','A','A'])
# zip expects x and y to have same #partitions and #elements/partition
y = x.map(lambda x: ord(x))
z = x.zip(y)
print(x.collect())
print(y.collect())
print(z.collect())
['B', 'A', 'A']
[66, 65, 65]
[('B', 66), ('A', 65), ('A', 65)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
20. zipWithIndex
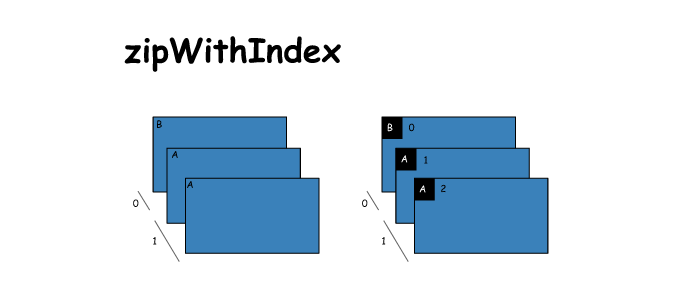
# zipWithIndex
x = sc.parallelize(['B','A','A'],2)
y = x.zipWithIndex()
print(x.glom().collect())
print(y.collect())
[['B'], ['A', 'A']]
[('B', 0), ('A', 1), ('A', 2)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
21. zipWithUniqueId
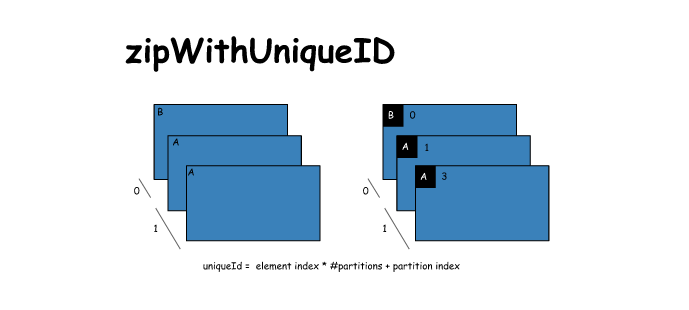
# zipWithUniqueId
x = sc.parallelize(['B','A','A'],2)
y = x.zipWithUniqueId()
print(x.glom().collect())
print(y.collect())
[['B'], ['A', 'A']]
[('B', 0), ('A', 1), ('A', 3)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
【完】
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/一键难忘520/article/detail/736433
推荐阅读
相关标签

