
- 15年测试面试要20K,面试三个问题把我打发走了···_requests中sign签名与token
- 2idea中添加单元测试@Test注解引入_idea添加test注解
- 3android jni Log
- 4ML - 决策树 Code_ml code give away
- 5区块链白皮书:基础建设见成效,国产自主生态正发展壮大
- 6数据库系统概论期末考试卷【详解】_数据库系统概论 试卷
- 7迁移学习:如何为您的机器学习问题选择正确的预训练模型_使用预训练模型 结构必须一样吗
- 8postman接口测试,1个参数有好几个值的时候如何测试比较简单快速?_postman一个参数多个值
- 9AutoCAD 2020绿色破解版|Autodesk AutoCAD 2020绿色便携免安装版下载_autocad绿色便携版
- 10【数学建模】—【Python库】—【Numpy】—【学习】
Super Point 笔记(一)_superpoint训练教程
赞
踩
Super Point 笔记
Abstract
论文地址:https://arxiv.org/pdf/1712.07629.pdf
论文代码:https://github.com/rpautrat/SuperPoint
- 1
- 2

本篇文章展示了一种针对计算机视觉中多视角几何变换问题的特征点提取及描述的自监督架构。与基于patch的方法不同,本文的全卷积模型在全尺寸图像上运行,并在一次前向传播中共同计算像素级关键点位置和相关描述符。本文引入了单应性自适应(Homographic Adaption),一种多尺度、多单应性的方法来提高特征点检测的重复性和执行跨域自适应。我们的模型,当训练在MS-COCO通用图像数据集使用单应性与原始的预适应深度模型和其他传统的角点检测器相比,该算法能够反复检测出更丰富的特征点集。与LIFT,SIFT和ORB相比,该方法在HPatches数据集上取得了最佳的单应性预测结果。
基础框架

如图所示,superpoint的训练可以分为以上三个步骤。
1.特征点的预训练(Interest Point Pre-Training)
这个部分其实来源于Magic Leap公司的上一个作品,Toward Geometric Deep SLAM (Magic Point)。由于现存的图像特征点数据集有限,在Magic Point 中,作者想到了利用合成场景来进制作图像关键点的方法。

MagicPoint的训练数据集通过制作一些三维物体饼对这些物体进行一个视角的图片截取得到二维图像。在这些图像中,所有的特征点的真值(Ground Truth)是已知的,可以用于网络训练。因此,在Superpoint的网络训练过程中,先利用这些合成三维物体作为数据集,训练网络(Base Detector)去提取角点作为关键点。
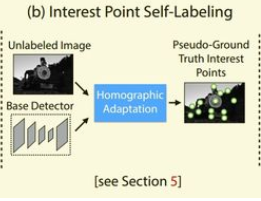
2.特征点自标注(Interest Point Self-Labeling)
作者采用MS-COCO数据集,作为该部分的训练和测试集。在上一部分,我们使用了合成场景进行训练得到了一个BaseDetector网络,在这一部分,利用BaseDetector网络在MS-COCO数据集上进行特征点的提取,这一部分被称为特征点自标注。同时,作者对每张图片进行了旋转缩放等操作,类似于数据增强。
3 联合训练(Joint Training)
针对上一部分使用的图片进行几何变换,这样就可以得到图片对,将两张图片输入网络,提取特征点和描述子,进行联合训练。



