
- 1Perl语言入门学习
- 2关于AIGC发展历程的研究报告(原创文章)
- 3IDEA git 实际场景中的试用_idea git merge实际使用
- 42024年最新前端安全——最新:lodash原型漏洞从发现到修复全过程_lodash 4,2024年最新字节大牛教你手撕网络安全学习_lodash 漏洞
- 5[网鼎杯 2020 青龙组]bang 复现--frida-dexdump安卓脱壳工具的使用
- 6深入浅出vsomeip:打造高效车载通信系统_vsomeip 多对多
- 7Ubuntu安装Hbase数据库
- 8Python报UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xad in position的解决办法_unicodedecodeerror: 'gbk' codec can't decode byte
- 9split()用法注意事项_split()函数的注意事项
- 10林子雨大数据技术原理与运用期末复习_大数据技术原理与应用林子雨期末考试
Diffusion 和Stable Diffusion的数学和工作原理详细解释_stable difusion和difusion
赞
踩
扩散模型的兴起可以被视为人工智能生成艺术领域最近取得突破的主要因素。而稳定扩散模型的发展使得我们可以通过一个文本提示轻松地创建美妙的艺术插图。所以在本文中,我将解释它们是如何工作的。
扩散模型 Diffusion
扩散模型的训练可以分为两部分:
-
正向扩散→在图像中添加噪声。
-
反向扩散过程→去除图像中的噪声。
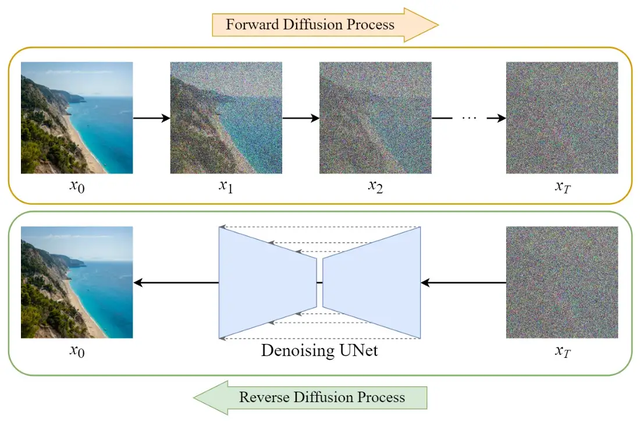
正向扩散过程

正向扩散过程逐步对输入图像 x₀ 加入高斯噪声,一共有 T 步。 该过程将产生一系列噪声图像样本 x₁, …, x_T。
当 T → ∞ 时,最终的结果将变成一张完包含噪声的图像,就像从各向同性高斯分布中采样一样。
但是我们可以使用一个封闭形式的公式在特定的时间步长 t 直接对有噪声的图像进行采样,而不是设计一种算法来迭代地向图像添加噪声。
封闭公式
封闭形式的抽样公式可以通过重新参数化技巧得到。

通过这个技巧,我们可以将采样图像xₜ表示为:
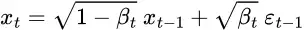
然后我们可以递归展开它,最终得到闭式公式:

这里的ε 是 i.i.d. (独立同分布)标准正态随机变量。使用不同的符号和下标区分它们很重要,因为它们是独立的并且它们的值在采样后可能不同。
但是,上面公式是如何从第4行跳到第5行呢?
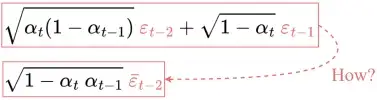
有些人觉得这一步很难理解。下面我详细介绍如何工作的:

让我们用 X 和 Y 来表示这两项。它们可以被视为来自两个不同正态分布的样本。 即 X ~ N(0, αₜ(1-αₜ₋₁)I) 和 Y ~ N(0, (1-αₜ)I)。
两个正态分布(独立)随机变量的总和也是正态分布的。 即如果 Z = X + Y,则 Z ~ N(0, σ²ₓ+σ²ᵧ)。因此我们可以将它们合并在一起并以重新以参数化的形式表示合并后的正态分布。
重复这些步骤将为得到只与输入图像 x₀ 相关的公式:
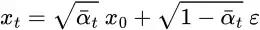
现在我们可以使用这个公式在任何时间步骤直接对xₜ进行采样,这使得向前的过程更快。
反向扩散过程
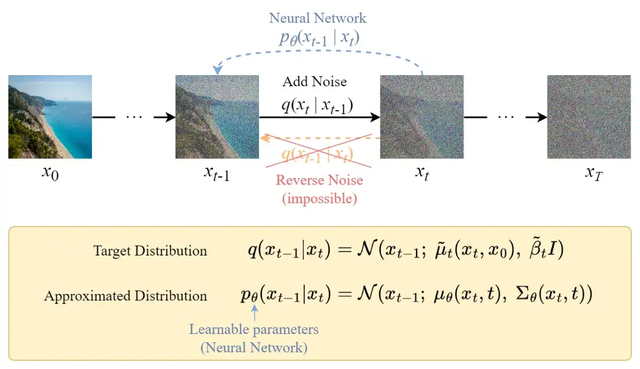
与正向过程不同,不能使用q(xₜ₋₁|xₜ)来反转噪声,因为它是难以处理的(无法计算)。所以我们需要训练神经网络pθ(xₜ₋₁|xₜ)来近似q(xₜ₋₁|xₜ)。近似pθ(xₜ₋₁|xₜ)服从正态分布,其均值和方差设置如下:

损失函数
损失定义为负对数似然:
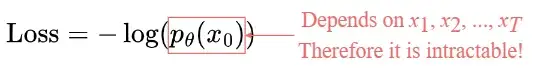
这个设置与VAE中的设置非常相似。我们可以优化变分的下界,而不是优化损失函数本身。
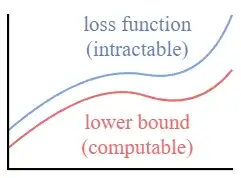
通过优化一个可计算的下界,我们可以间接优化不可处理的损失函数。

通过展开,我们发现它可以用以下三项表示:
1、L_T:常数项
由于 q 没有可学习的参数,p 只是一个高斯噪声概率,因此这一项在训练期间将是一个常数,因此可以忽略。
2、Lₜ₋₁:逐步去噪项
这一项是比较目标去噪步骤 q 和近似去噪步骤 pθ。通过以 x₀ 为条件,q(xₜ₋₁|xₜ, x₀) 变得易于处理。

经过一系列推导,上图为q(xₜ₋₁|xₜ,x₀)的平均值μ′ₜ。为了近似目标去噪步骤q,我们只需要使用神经网络近似其均值。所以我们将近似均值 μθ 设置为与目标均值 μ̃ₜ 相同的形式(使用可学习的神经网络 εθ):
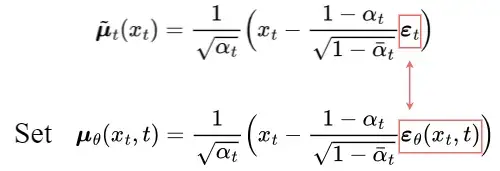
目标均值和近似值之间的比较可以使用均方误差(MSE)进行:

经过实验,通过忽略加权项并简单地将目标噪声和预测噪声与 MSE 进行比较,可以获得更好的结果。所以为了逼近所需的去噪步骤 q,我们只需要使用神经网络 εθ 来逼近噪声 εₜ。
3、L₀:重构项
这是最后一步去噪的重建损失,在训练过程中可以忽略,因为:
-
可以使用 Lₜ₋₁ 中的相同神经网络对其进行近似。
-
忽略它会使样本质量更好,并更易于实施。
所以最终简化的训练目标如下:
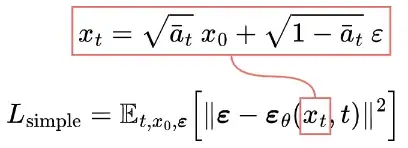
我们发现在真实变分界上训练我们的模型比在简化目标上训练产生更好的码长,正如预期的那样,但后者产生了最好的样本质量。[2]
通过测试在变分边界上训练模型比在简化目标上训练会减少代码的长度,但后者产生最好的样本质量。 [2]
U-Net模型
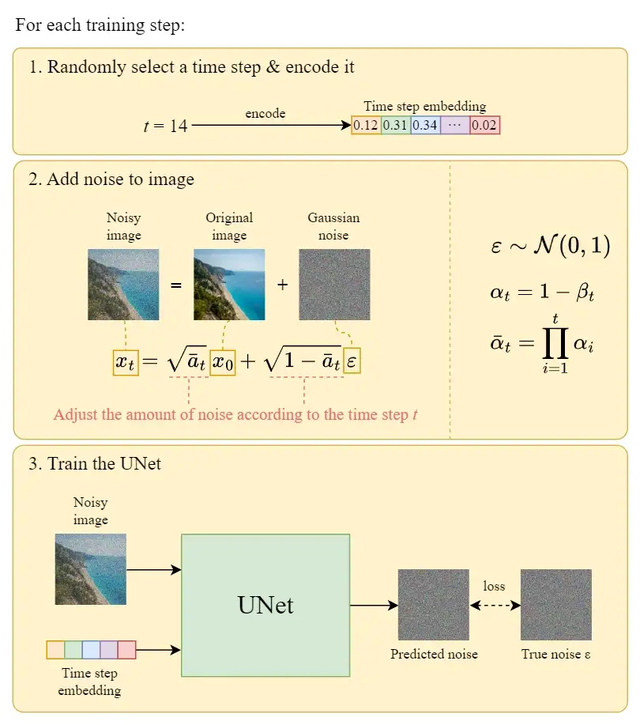
在每一个训练轮次
-
每个训练样本(图像)随机选择一个时间步长t。
-
对每个图像应用高斯噪声(对应于t)。
-
将时间步长转换为嵌入(向量)。
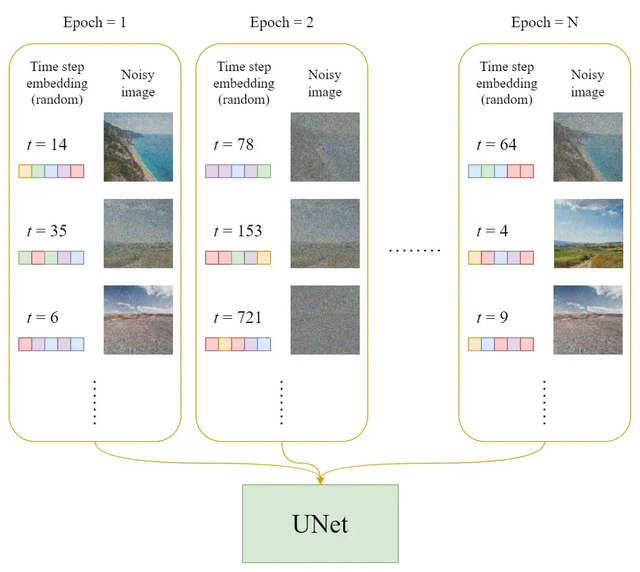
训练过程的伪代码

官方的训练算法如上所示,下图是训练步骤如何工作的说明:
反向扩散

我们可以使用上述算法从噪声中生成图像。下面的图表说明了这一点:
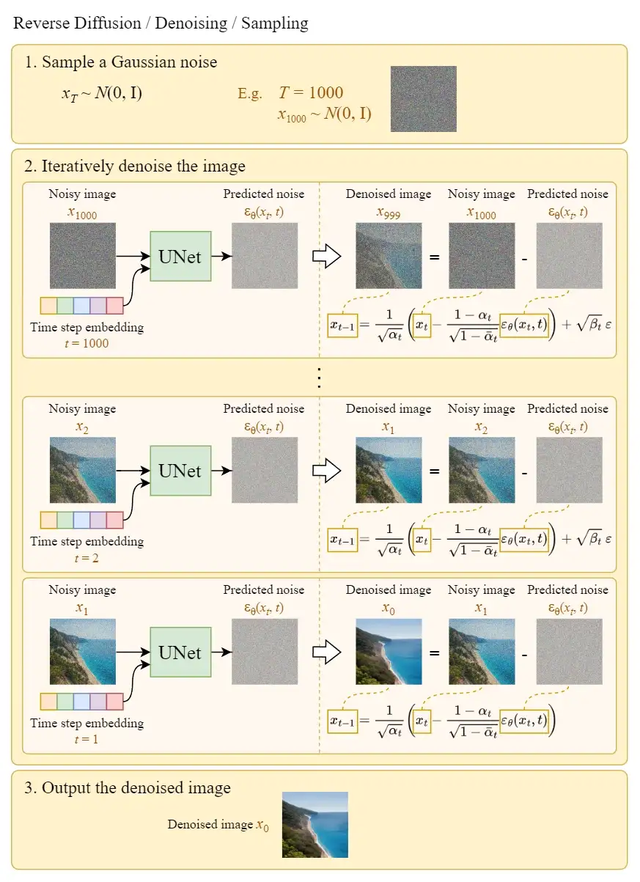
在最后一步中,只是输出学习的平均值μθ(x₁,1),而没有添加噪声。反向扩散就是我们说的采样过程,也就是从高斯噪声中绘制图像的过程。
扩散模型的速度问题
扩散(采样)过程会迭代地向U-Net提供完整尺寸的图像获得最终结果。这使得纯扩散模型在总扩散步数T和图像大小较大时极其缓慢。
稳定扩散就是为了解决这一问题而设计的。
稳定扩散 Stable Diffusion
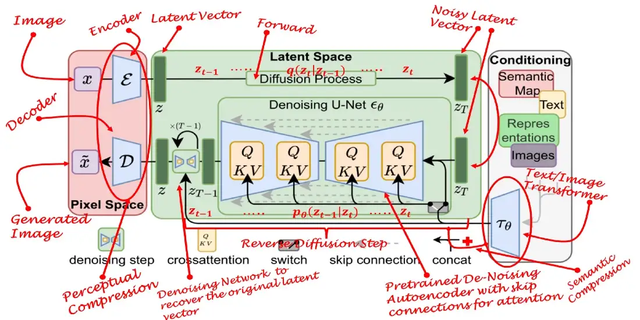
稳定扩散模型的原名是潜扩散模型(Latent Diffusion Model, LDM)。正如它的名字所指出的那样,扩散过程发生在潜在空间中。这就是为什么它比纯扩散模型更快。
潜在空间

首先训练一个自编码器,学习将图像数据压缩为低维表示。
通过使用训练过的编码器E,可以将全尺寸图像编码为低维潜在数据(压缩数据)。然后通过使用经过训练的解码器D,将潜在数据解码回图像。
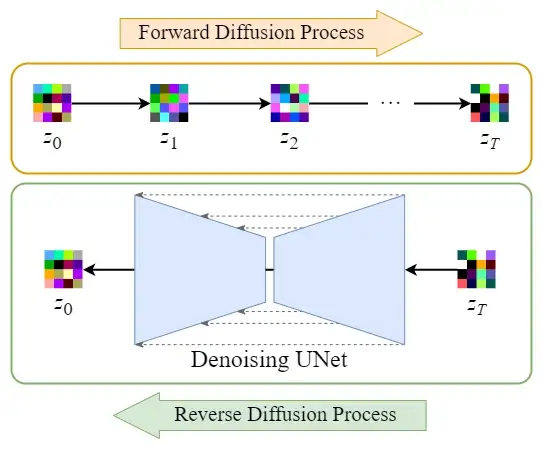
潜在空间的扩散
将图像编码后,在潜在空间中进行正向扩散和反向扩散过程。
-
正向扩散过程→向潜在数据中添加噪声
-
反向扩散过程→从潜在数据中去除噪声
条件作用/调节
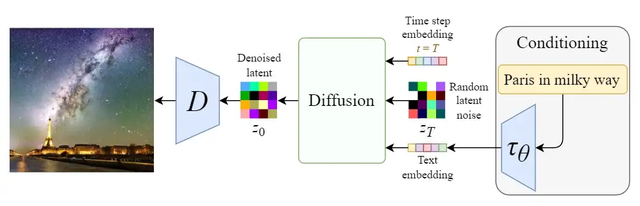
稳定扩散模型的真正强大之处在于它可以从文本提示生成图像。这是通过修改内部扩散模型来接受条件输入来完成的。
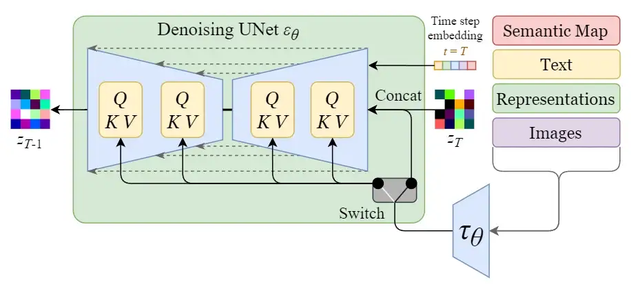
通过使用交叉注意机制增强其去噪 U-Net,将内部扩散模型转变为条件图像生成器。
上图中的开关用于在不同类型的调节输入之间进行控制:
- 对于文本输入,首先使用语言模型
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

