
基于Transformer的机器翻译,使用Pytorch深度学习框架实现和gradio实现一个小小的页面
赞
踩
声明:本文参考的内容在末尾给出,并且本文并不会对Transformer细节详解,可以看本文参考的原作者链接有视频详解。本文主要是在原作者实现的基础上拓展一些内容,比如英文到中文的翻译,包含数据集的处理以及实现一个小小的浏览器页面进行文本的翻译,在最后还给出了在三个数据集上训练之后的模型,可以参考Github链接,本文会给出一些需要注意并且容易被我们忽视的重要点。
目录
3.机器翻译中Transformer推理(或者验证阶段)流程(重点)
(2).Greedy搜索算法既然每一次都是选择预测的最大概率,为什么不能保证得到的整体是最优解呢?
(3).在线翻译系统难道是针对每一对语言之间的翻译都需要训练一个模型吗?(网上查询)
(4).如今的互联网非常的发达,新的名词不断出现,翻译系统怎么针对新的名词进行翻译呢?(网上查询)
1.Transformer结构
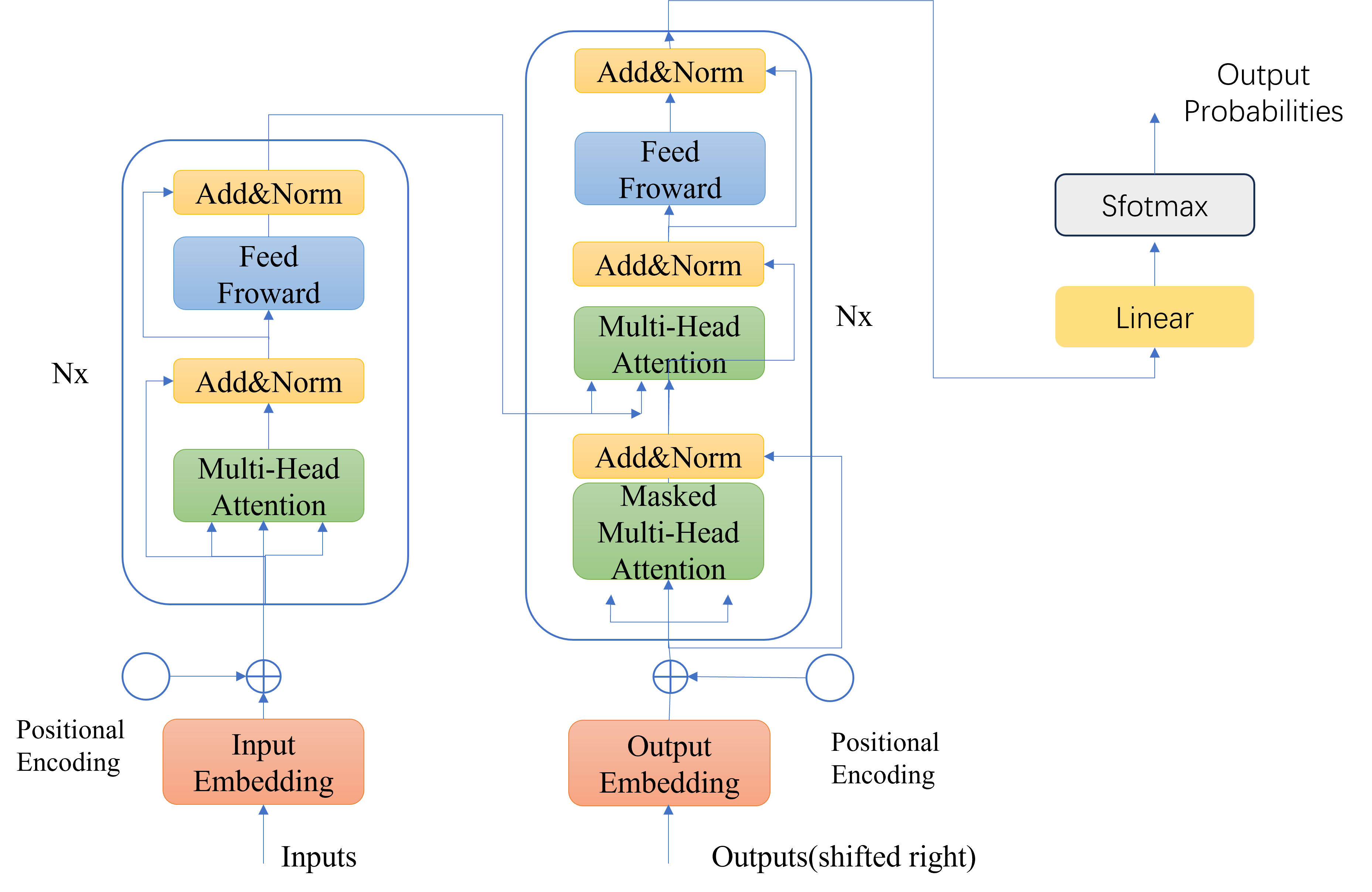
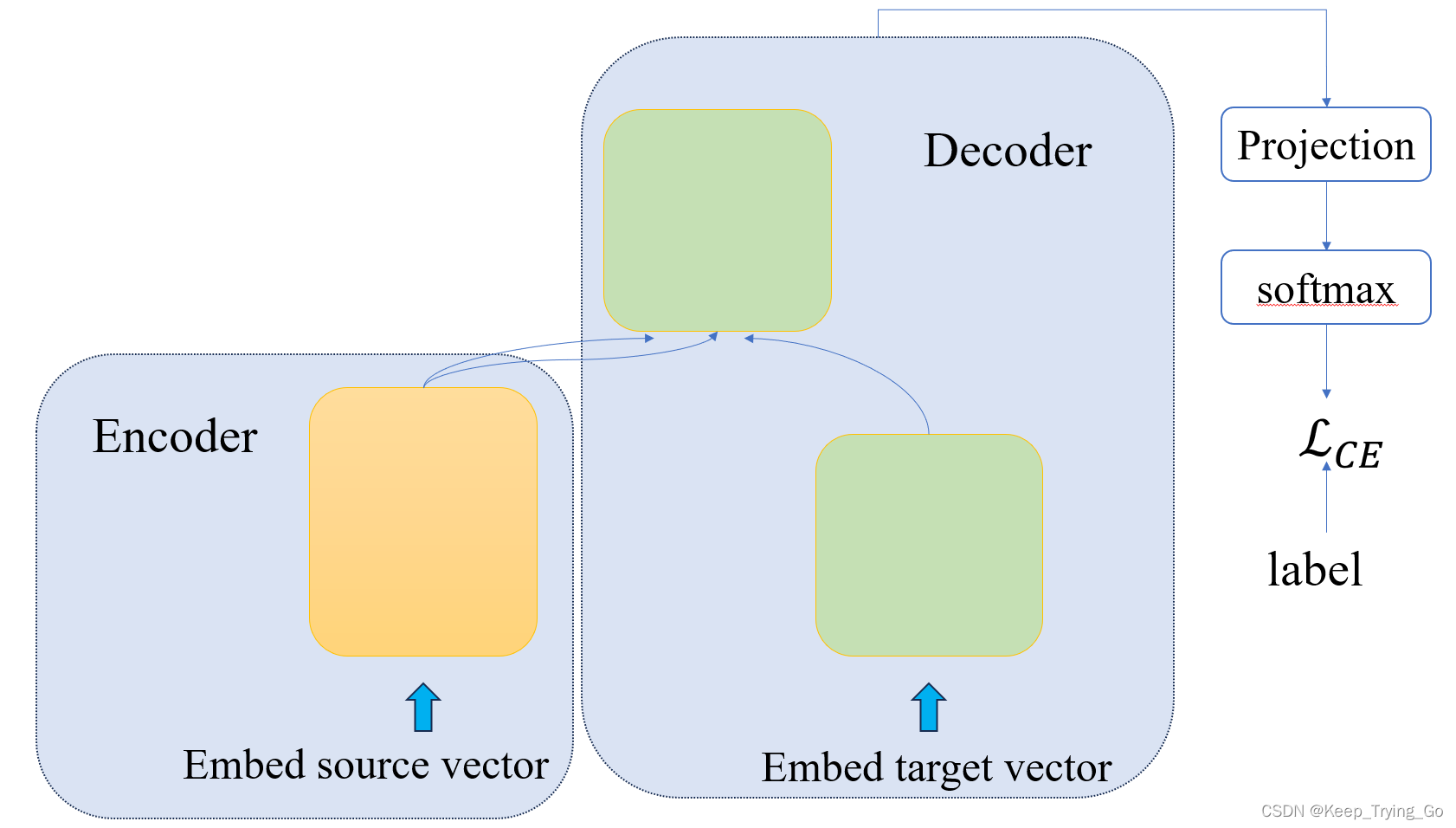
2.机器翻译中Transformer训练过程
注意看以下两幅图,如果第一幅图看的不是很懂的话,看第二幅图应该很清楚训练的大致流程了,以及输入到编码器,解码器以及对应label应该是什么样的。

3.机器翻译中Transformer推理(或者验证阶段)流程(重点)
对于推理过程,这里使用一个PPT动画来解释,对于初学者更加的直观和容易理解。
机器翻译的推理过程
4.推理过程中Greedy和Beam搜索算法(重点)
(1)Greedy搜索算法


(2)Beam搜索算法



5.实验测试
代码以及训练好的模型:基于Transformer的机器翻译,和gradio实现简单的翻译页面
(1)实验数据集
| 数据集名称 | 训练集 | 验证集 | 源句子最大长度 | 目标句子最大长度 |
| Opus_books(英语-意大利语) | 29098 | 3233 | 309 | 274 |
| Opus_mt(英语-中文) | 25063 | 2784 | 38 | 12 |
| -(英语-中文) | 186249 | 20694 | 676 | 883 |
(2)实验环境及设备
| 设备:服务器 |
| NVIDIA显卡:GA102[GeForce RTX 3090] |
| 环境:Pyhon 3.6.13 Pytorch 1.9.0+cuda1.1.1 Tokenizers 0.12.1 Transformers 4.18.0 |
(3)系统运行展示
Opus_books(英语-意大利语)测试结果

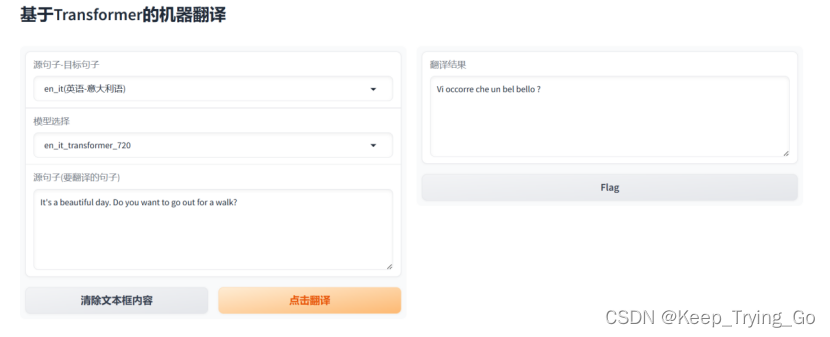
如图所示opus_books数据集训练模型测试结果
从图可以看到,在模型训练了720代之后,对于短的语句翻译是准确的,但是随着句子长度增加,翻译的效果越来越差,造成这样的原因不仅仅是因为模型,还有和数据集大小以及选择的解码搜索算法有关,但是最主要的原因还是数据集大小和模型。
Opus_mt(英语-中文)测试结果

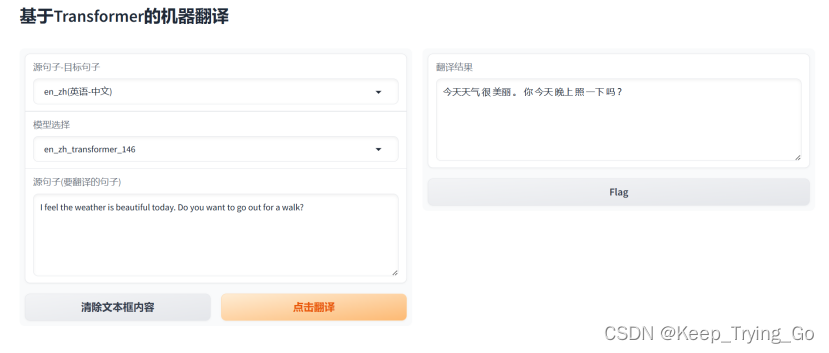
如图所示opus_mt数据集上训练的模型英语到中文测试结果
从图可以看到,对于第一个英语到中文的数据集,模型训练了146代之后,模型在较短的语句上翻译是正确的,随着翻译句子长度的增加,翻译的准确性降低,只能有一部分翻译正确。对于第二个英语到中文的数据集,虽然翻译的结果也是只是一部分正确,但是模型只训练了22代,需要强调的一点是数据集2比数据集1多一个数据量级。
6.思考总结
(1).什么是语法?什么是语义?
个人解释:语法是一种逻辑结构,一种规则,只有当句子有了正确的语法,该句子才可能是通顺的,符合要求的。然而语义是一种更加抽象的东西,有了正确的语法并不代表就能正确的理解语义,语义是一种词与词,短语与短语,句子与句子,段落与段落,文章与文章之间的一种潜在的联系,比如一个句子“我的理想是当一名科学家,然而现在的我可能还需继续努力”,从语法是上是符合要求的,但是要真正的理解句子的本义,并不能简单的通过词和词之间靠的很近来理解它们之间的关系,比如“科学家”与“继续努力”是有很大的关系,然而它们在句子中却隔的有一定的距离,因此,要理解这整句话,必须要理解其中的语义相关性(关于这一点我不能确定自己的理解是否正确,只作为一个小小的参考)。
(2).Greedy搜索算法既然每一次都是选择预测的最大概率,为什么不能保证得到的整体是最优解呢?
个人解释:从算法设计的角度去考虑,贪心算法确实只是在考虑局部的最优解,并不能保证得到的是全局最优解,然而在解码的过程中虽然在使用greedy搜索算法的过程每次选取的是当前最大条件概率,看似是全局最优解,实际上翻译的结果并不能保证完全匹配目标句子,比如:同一个意思,可以使用多句话表示,但是哪一个是最佳的,需要从中进行选择,然而贪婪搜索算法虽然选取的是最大条件概率,但是不能保证搜索的结果就一定是最佳的匹配。也就是机器翻译并不是要得到一个固定或者标准的答案,而是要翻译出来的语言让人能够去理解即可,因此这里的“最佳”也不是指标准答案,而是翻译出来的语句,语法是正确的,语义上是可以理解的。
然而Greedy搜索算法相比于Beam搜索算法可以候选的更窄,因为贪婪搜索算法只能选择当前预测条件概率最大,对于Beam搜索算法来说,可以搜索的宽度根据设置的束宽来决定,那么当前预测的结果,作为下一个输入时,可输入到解码器中的选择有K个,预测到最后选择预测条件概率最大的即可,也就是Beam搜索算法相比于Greedy搜索算法更加的“soft”。
(3).在线翻译系统难道是针对每一对语言之间的翻译都需要训练一个模型吗?(网上查询)
世界上不同的语言数量是非常多的,虽然很多的语言并不常用,但是比较常用的语言数量也不少,那么在线翻译系统针对每一对语言都要训练一个模型吗?这个问题的答案在查询了网上的资料之后得到以下结论:
- 如今的语言模型非常的多,针对多语言模型也相继提出,可以支持多种语言的输入和输出。
- 针对某些语言差异很大和有限的资源,采用训练独立的语言模型。
- 不管是在自然语言处理,还是在计算机视觉,当我们不能直接使用大模型时,可以采用迁移学习和微调,针对不同的下游任务针对性的解决问题。
- 可以使用不同模型之间的“信息传递”,比如英语到中文的翻译,中文到俄语的翻译,那么可以利用两个模型从英语到俄语的翻译。
(4).如今的互联网非常的发达,新的名词不断出现,翻译系统怎么针对新的名词进行翻译呢?(网上查询)
针对这个问题,在自然语言处理其他任务中也存在该问题,但是很多论文也提出了相关的算法去缓解这个问题,其中包含的方法主要有以下几点:
- 基于语料库的翻译库,针对新的名词,可以从语料库中查找类似的词汇或短语,从而推断“未登录词”。
- 上下文分析,可以通过句子的上下文进行分析,从而推断“未登录词”的含义。
- 针对特定领域的方向新名词,翻译系统可以集成专业词典和术语库,可以通过集成之前的词来推断集成之后的词。
- 让翻译系统实时的更新和学习,定期的从网上爬取新名词和新词汇进行学习。
现在的很多模型都采用集成的方法,因此,针对翻译系统也可以如此,首先通过语料库和上下分析翻译,其次结合专业词典和术语库信息进行翻译。
7.结果演示
结果演示
参考文献(推荐阅读)
- Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
- Graves A, Graves A. Long short-term memory[J]. Supervised sequence labelling with recurrent neural networks, 2012: 37-45.
- Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[J]. Advances in neural information processing systems, 2014, 27.
- Luong M T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation[J]. arXiv preprint arXiv:1508.04025, 2015.
- Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
- Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014.
- Liu X, Duh K, Liu L, et al. Very deep transformers for neural machine translation[J]. arXiv preprint arXiv:2008.07772, 2020.

