
- 1腾讯EdgeOne产品测评体验——开启安全防护,保障数据无忧_edge one
- 2论文AI高风险怎么降:从7个方面为您的安全保驾护航_论文怎么降低ai辅写风险
- 3《深入理解计算机系统》实验三Attack Lab下载和官方文档机翻_深入理解计算机 attactlab 官网
- 4嘉为蓝鲸携手腾讯云亮相石油石化峰会,研运创新助力能源数字化转型_我司 出席 石油 信创 数字化转型 大会
- 5链表和队列的区别
- 6论文查重时AI辅写疑似度过高怎么办:七个实用技巧助你顺利过关_查重ai
- 7anaconda,jupyter打开某文件夹下的项目代码python_jupyter只能运行文件夹里的代码吗
- 8Canal——数据同步_canal数据同步
- 935岁之后软件测试工程师靠什么养家 【送外卖】我还能继续做测试吗_50多岁还能做软件测试吗
- 10MYSQL数据库第七次作业---视图_数据库视图的创建含分组和排序
创新实训大模型篇2——《融合外接知识库以增强ChatGLM3-6B的问答能力》_chatglm neo4j
赞
踩
融合外接知识库以增强ChatGLM3-6B的问答能力
引言
外接知识库在问答系统中的重要性不言而喻。知识库通过提供结构化和关联的数据,可以显著提高问答系统的准确性和上下文理解能力。对于ChatGLM3-6B这样的大型语言模型(LLM),融合外接知识库如知识图谱,可以帮助其在复杂问题上的表现更加出色。本文将介绍如何在ChatGLM3-6B中融合外接知识库,特别是知识图谱,以增强其问答能力,并结合LangChain相关代码进行实现。

知识库选择
知识库可以分为多种类型,包括知识图谱、文本数据库等。不同类型的知识库各有优缺点:
-
知识图谱:通过节点和边的结构化形式表示实体及其关系,适合处理复杂的关系和推理任务。知识图谱能够捕捉上下文关系和多跳推理,是增强LLM的理想选择。
-
文本数据库:存储大规模的未结构化文本,适用于简单的信息检索任务,但在处理复杂推理时可能表现欠佳。
知识图谱在提供结构化信息和上下文理解方面具有明显优势,使其成为增强问答系统的首选。
系统架构设计
要将知识库与ChatGLM3-6B模型集成,需要设计一个高效的系统架构。该架构包括以下几个主要组件:
-
知识图谱数据库:使用Neo4j或NebulaGraph等图数据库存储和管理知识图谱。
-
检索机制:结合向量相似性搜索和图遍历算法,实现高效的信息检索。
-
大语言模型(LLM):使用ChatGLM3-6B生成自然语言响应。
-
查询处理组件:处理用户查询并协调各个组件之间的交互。
这种架构设计能够充分利用知识图谱的结构化信息和LLM的语言生成能力,实现高效的问答系统。
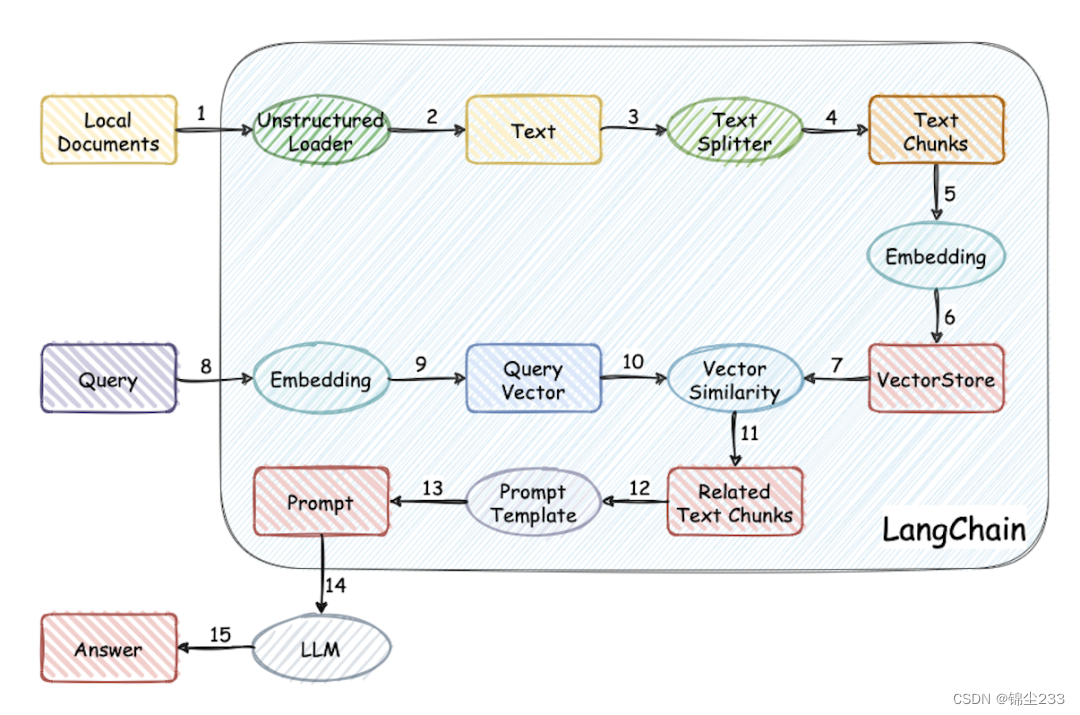
数据接口设计
为了确保模型能够访问和利用知识库信息,需要设计和实现数据接口。以下是一些关键步骤:
-
数据转换:将知识图谱数据转换为LLM可以处理的格式。例如,可以使用Neo4j的Cypher查询语言从图数据库中检索信息,然后将结果转换为文本或其他合适的格式。
-
接口实现:编写接口代码,使得ChatGLM3-6B可以调用知识库中的数据。可以使用Python编写RESTful API,通过HTTP请求获取知识图谱中的相关信息。
-
数据嵌入:在模型生成响应时,将检索到的知识图谱数据嵌入到生成过程中,以提供上下文和准确的信息。
融合方法
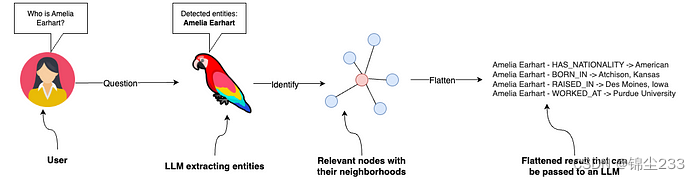
RAG(Retrieval-Augmented Generation)是一种将信息检索与生成模型结合的方法,具体融合步骤如下:
-
初始检索:使用向量嵌入进行初步检索,快速找到潜在相关的节点。
-
图遍历和上下文精炼:通过图遍历算法(如广度优先搜索、深度优先搜索)进一步精炼检索结果,考虑节点之间的关系和上下文。
-
生成响应:将检索到的上下文信息传递给ChatGLM3-6B,生成最终的自然语言响应。
这种方法结合了向量检索的高效性和知识图谱的结构化信息,可以显著提升问答系统的性能。
性能提升
通过融合知识图谱,问答系统在多方面性能提升显著:
-
准确性:知识图谱提供的结构化信息帮助模型生成更准确的回答,减少错误和模糊回答。
-
上下文理解:通过知识图谱的多跳推理能力,模型能够更好地理解复杂问题和长尾问题。
-
响应速度:虽然引入了图遍历等步骤,但合理的缓存策略和高效的图数据库可以保持响应速度在可接受范围内。
具体性能对比可以通过实验验证。在融合知识图谱前后,测量系统在准确率、响应时间和用户满意度等方面的表现。
使用LangChain进行实现
下面是结合LangChain和Neo4j进行知识图谱查询和回答生成的示例代码:
环境配置
-
安装必要的库:
pip install langchain neo4j
-
设置Neo4j连接:
from neo4j import GraphDatabase uri = "bolt://localhost:7687" driver = GraphDatabase.driver(uri, auth=("neo4j", "password")) def get_knowledge_graph_data(query): with driver.session() as session: result = session.run(query) return [record.data() for record in result] cypher_query = "MATCH (n:Person)-[r:KNOWS]->(m) RETURN n, r, m LIMIT 25" data = get_knowledge_graph_data(cypher_query) print(data)
使用LangChain进行查询处理
from langchain.llms import ChatGLM3
from langchain.chains import RetrievalQA
# 初始化ChatGLM3模型
llm = ChatGLM3(model_name="THUDM/chatglm3-6b")
# 定义数据检索函数
def retrieve_data_from_kg(question):
cypher_query = f"MATCH (n)-[r]->(m) WHERE n.name CONTAINS '{question}' RETURN n, r, m LIMIT 5"
return get_knowledge_graph_data(cypher_query)
# 定义回答生成函数
def generate_answer(question):
retrieved_data = retrieve_data_from_kg(question)
context = " ".join([str(item) for item in retrieved_data])
response = llm.generate(question, context)
return response
# 处理用户输入
question = "Who are the friends of Li Bai?"
answer = generate_answer(question)
print(f"Question: {question}\nAnswer: {answer}")
结论
通过本指南,您可以了解如何在ChatGLM3-6B中融合知识图谱,以增强其问答能力。结合LangChain和Neo4j,可以实现高效的检索增强生成(RAG),提升问答系统的性能和用户体验。在实际应用中,这种方法不仅提高了用户体验,还拓展了LLM在复杂任务中的应用潜力。希望本文能够为您的项目提供有价值的参考。

