
- 1字节跳动被爆猛料:海外审核部门一锅端,转岗“难于上青天”
- 2Linux MMC子系统 - 5.eMMC 5.1工作模式-引导模式_mmc的数据传输模式
- 3python2.7 print的用法,Python中print函数报错
- 4苹果电脑可以玩魔兽世界吗 魔兽世界有mac版本么 macbook 可以玩魔兽世界吗_mac玩魔兽世界
- 5进入AI领域做产品 —— 我的自学之路(CV-人脸识别)_人脸识别需要多少个像素点
- 6文本数据预处理_文本数据的预处理
- 7基于信号到达角度(AOA)的无线传感器网络定位——最大似然估计_最大似然估计到达角
- 8【网络协议】精讲DHCP协议!图解超赞超详细!!!_dhcp格式详解
- 9SAP PP学习笔记31 - 计划运行的步骤2 - Scheduling(日程计算),BOM Explosion(BOM展开)
- 10达梦 8 函数 —— 从常用函数到分析函数_达梦数据库常用函数
Python爬虫实战(六)——使用代理IP批量下载高清小姐姐图片(附上完整源码)_python 下载图片
赞
踩
文章目录
- 一、爬取目标
- 二、实现效果
- 三、准备工作
- 四、代理IP
-
- 4.1 使用代理的好处?
- 4.2 获取免费代理
- 4.3 获取代理
- 五、代理实战
-
- 5.1 导入模块
- 5.2 设置翻页
- 5.3 获取图片链接
- 5.4 下载图片
- 5.5 调用主函数
- 5.6 完整源码
一、爬取目标
本次爬取的目标是某网站4K高清小姐姐图片:

二、实现效果
实现批量下载指定关键词的图片,存放到指定文件夹中:

三、准备工作
Python:3.10
编辑器:PyCharm
第三方模块,自行安装:
pip install requests # 网页数据爬取
pip install lxml # 提取网页数据
- 1
- 2
- 3
四、代理IP
4.1 使用代理的好处?
使用代理IP可以带来以下好处:
- 匿名保护,保护隐私安全
- 安全采集公开数据信息
- 分散访问压力,提高爬取效率和稳定性。
- 收集不同地区或代理服务器上的数据,用于数据分析和对比。
博主经常写爬虫代码使用的是巨量IP家的高匿名代理IP,每天有1000个免费IP:点击免费试用

4.2 获取免费代理
1、打开巨量IP官网:巨量IP官网
2、输入账号信息进行注册:
3、这里需要进行实名认证,如果不会的可以看:个人注册实名教程:
4、进入会员中心,点击领取今日免费IP:
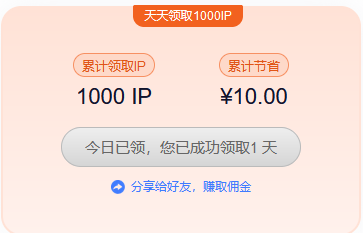
5、详细步骤看官方的教程文档:巨量HTTP—免费代理ip套餐领取教程,领取后如下图:

6、点击产品管理》动态代理(包时),可以看到我们刚才领取到的免费IP信息:
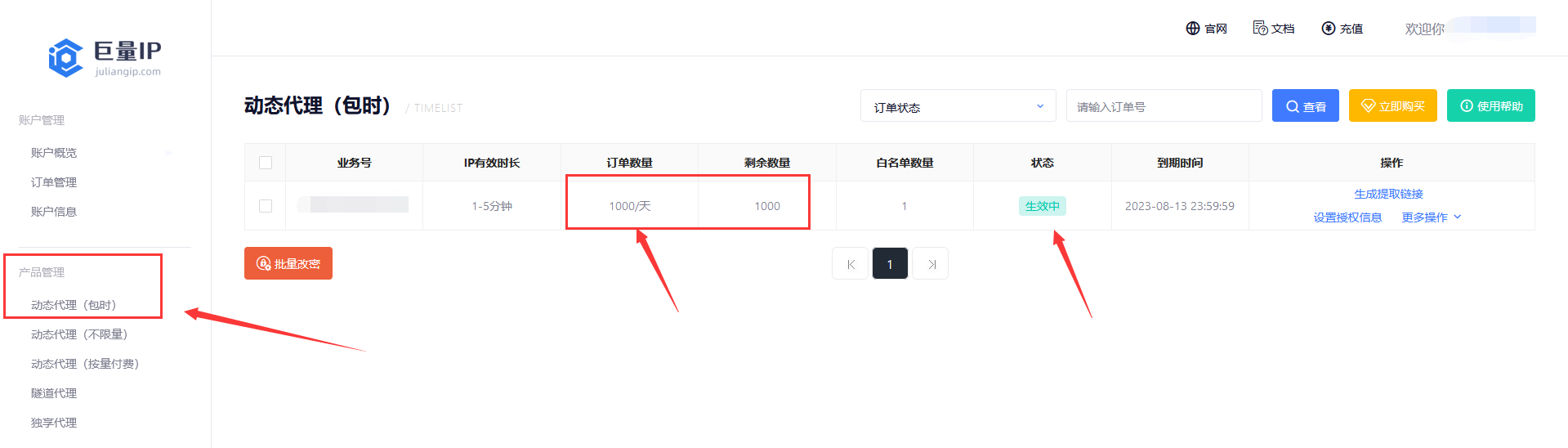
7、将自己电脑的IP添加为白名单能获取代理IP,点击授权信息:
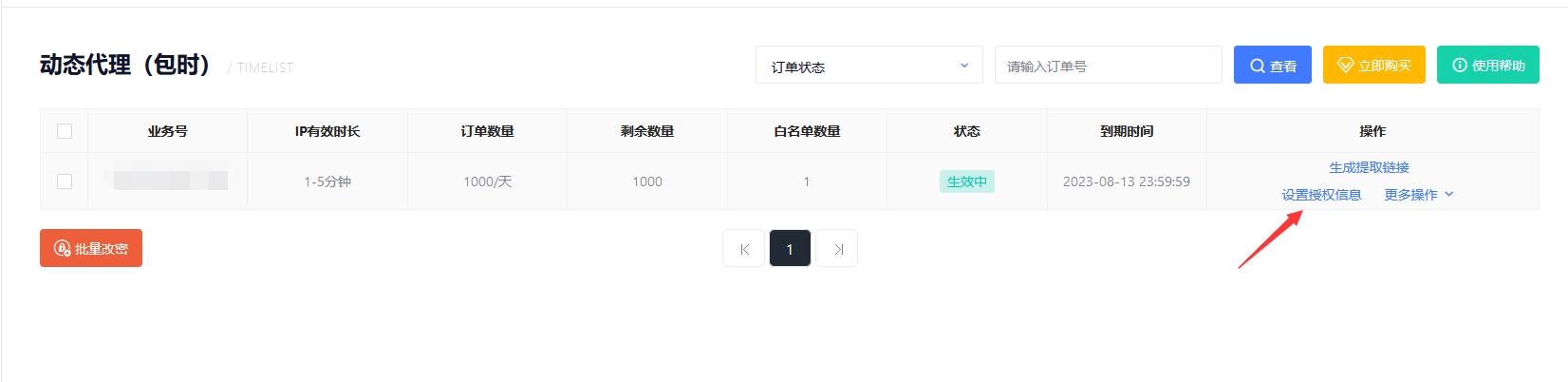
8、依次点击修改授权》快速添加》确定
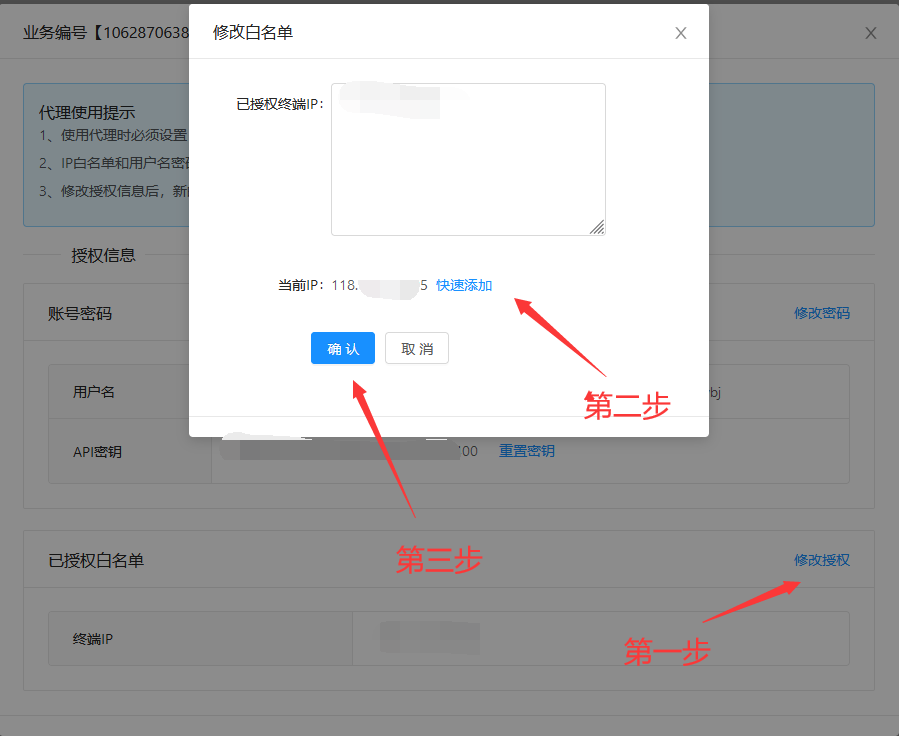
9、添加完成后,点击生成提取链接:

10、设置每次提取的数量,点击生成链接,并复制链接:
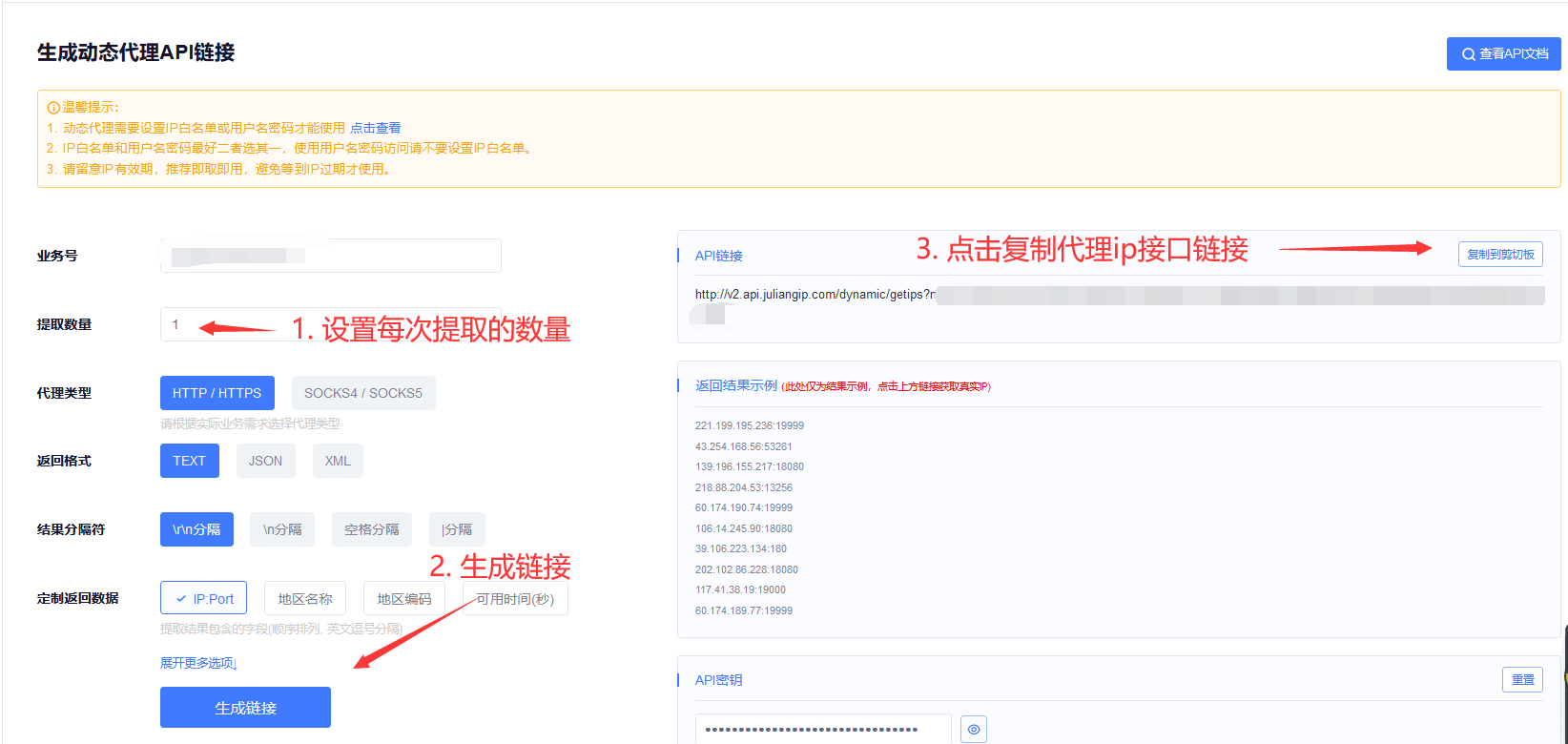
11、将复制链接,复制到地址栏就可以看到我们获取到的代理IP了:

4.3 获取代理
获取到图片链接后我们需要再次发送请求去下载图片,由于请求量一般会很大所以需要用到代理IP。上面我们已经手动获取到了代理IP,下面来看Python如何挂上代理IP发送请求:
1、通过爬虫去获取API接口的里面的代理IP(注意:下面代理URL,看4.2教程换成自己的API链接):
import requests import time import random def get_ip(): url = "这里放你自己的API链接" while 1: try: r = requests.get(url, timeout=10) except: continue ip = r.text.strip() if '请求过于频繁' in ip: print('IP请求频繁') time.sleep(1) continue break proxies = { 'https': '%s' % ip } return proxies if __name__ == '__main__': proxies = get_ip() print(proxies)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
运行结果,可以看到返回了接口中的代理IP:
2、接下来我们写爬虫代理的时候就可以挂上代理IP去发送请求了,只需要将proxies当成参数传给requests.get函数去请求其他网址:
requests.get(url, headers=headers, proxies=proxies)
- 1
- 2
五、代理实战
5.1 导入模块
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import time # 防止爬取过快可以睡眠一秒
import os # 创建文件
- 1
- 2
- 3
- 4
- 5
5.2 设置翻页
首先我们来分析一下网站的翻页,一共有62页:

第一页链接:
https://pic.netbian.com/4kmeinv/index.html
- 1
- 2
第二页链接:
https://pic.netbian.com/4kmeinv/index_2.html
- 1
- 2
第三页链接:
https://pic.netbian.com/4kmeinv/index_3.html
- 1
- 2
可以看出每页只有index后面从第二页开始依次加上_页码,所以用循环来构造所有网页链接:
if __name__ == '__main__':
# 页码
page_number = 1
# 循环构建每页的链接
for i in range(1,page_number+1):
# 第一页固定,后面页数拼接
if i ==1:
url = 'https://pic.netbian.com/4kmeinv/index.html'
else:
url = f'https://pic.netbian.com/4kmeinv/index_{i}.html'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5.3 获取图片链接
可以看到所有图片url都在 ul标签 > a标签 > img标签下:

我们创建一个get_imgurl_list(url)函数传入网页链接获取 网页源码,用xpath定位到每个图片的链接:
def get_imgurl_list(url,imgurl_list): """获取图片链接""" # 请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} # 发送请求 response = requests.get(url=url, headers=headers) # 获取网页源码 html_str = response.text # 将html字符串转换为etree对象方便后面使用xpath进行解析 html_data = etree.HTML(html_str) # 利用xpath取到所有的li标签 li_list = html_data.xpath("//ul[@class='clearfix']/li") # 打印一下li标签个数看是否和一页的电影个数对得上 print(len(li_list)) # 输出20,没有问题 for li in li_list: imgurl = li.xpath(".//a/img/@src")[0] # 拼接url imgurl = 'https://pic.netbian.com' +imgurl print(imgurl) # 写入列表 imgurl_list.append(imgurl)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
运行结果:

点开一个图片链接看看:

OK没问题!!!
5.4 下载图片
图片链接有了,代理IP也有了,下面我们就可以下载图片。定义一个get_down_img(img_url_list)函数,传入图片链接列表,然后遍历列表,每下载一个图片切换一次代理,将所有图片下载到指定文件夹:
def get_down_img(imgurl_list): # 在当前路径下生成存储图片的文件夹 os.mkdir("小姐姐") # 定义图片编号 n = 0 for img_url in imgurl_list: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} # 调用get_ip函数,获取代理IP proxies = get_ip() # 每次发送请求换代理IP,获取图片,防止被封 img_data = requests.get(url=img_url, headers=headers, proxies=proxies).content # 拼接图片存放地址和名字 img_path = './小姐姐/' + str(n) + '.jpg' # 将图片写入指定位置 with open(img_path, 'wb') as f: f.write(img_data) # 图片编号递增 n = n + 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
5.5 调用主函数
这里我们可以设置需要爬取的页码:
if __name__ == '__main__': # 1. 设置获取的页数 page_number = 63 imgurl_list = [] # 用于存储所有的图片链接 # 2. 循环构建每页的链接 for i in range(1,page_number+1): # 第一页固定,后面页数拼接 if i ==1: url = 'https://pic.netbian.com/4kmeinv/index.html' else: url = f'https://pic.netbian.com/4kmeinv/index_{i}.html' # 3. 获取图片链接 get_imgurl_list(url,imgurl_list) # 4. 下载图片 get_down_img(imgurl_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5.6 完整源码
注意:下面代理URL,看4.2教程换成自己的API链接:
import requests # python基础爬虫库 from lxml import etree # 可以将网页转换为Elements对象 import time # 防止爬取过快可以睡眠一秒 import os def get_ip(): url = "这里放你自己的API链接" while 1: try: r = requests.get(url, timeout=10) except: continue ip = r.text.strip() if '请求过于频繁' in ip: print('IP请求频繁') time.sleep(1) continue break proxies = { 'https': '%s' % ip } return proxies def get_imgurl_list(url,imgurl_list): """获取图片链接""" # 请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} # 发送请求 response = requests.get(url=url, headers=headers) # 获取网页源码 html_str = response.text # 将html字符串转换为etree对象方便后面使用xpath进行解析 html_data = etree.HTML(html_str) # 利用xpath取到所有的li标签 li_list = html_data.xpath("//ul[@class='clearfix']/li") # 打印一下li标签个数看是否和一页的电影个数对得上 print(len(li_list)) # 输出20,没有问题 for li in li_list: imgurl = li.xpath(".//a/img/@src")[0] # 拼接url imgurl = 'https://pic.netbian.com' +imgurl print(imgurl) # 写入列表 imgurl_list.append(imgurl) def get_down_img(imgurl_list): # 在当前路径下生成存储图片的文件夹 os.mkdir("小姐姐") # 定义图片编号 n = 0 for img_url in imgurl_list: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} # 调用get_ip函数,获取代理IP proxies = get_ip() # 每次发送请求换代理IP,获取图片,防止被封 img_data = requests.get(url=img_url, headers=headers, proxies=proxies).content # 拼接图片存放地址和名字 img_path = './小姐姐/' + str(n) + '.jpg' # 将图片写入指定位置 with open(img_path, 'wb') as f: f.write(img_data) # 图片编号递增 n = n + 1 if __name__ == '__main__': # 1. 设置获取的页数 page_number = 50 imgurl_list = [] # 用于存储所有的图片链接 # 2. 循环构建每页的链接 for i in range(1,page_number+1): # 第一页固定,后面页数拼接 if i ==1: url = 'https://pic.netbian.com/4kmeinv/index.html' else: url = f'https://pic.netbian.com/4kmeinv/index_{i}.html' # 3. 获取图片链接 get_imgurl_list(url,imgurl_list) # 4. 下载图片 get_down_img(imgurl_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
运行结果:

下载成功了没有报错,代理IP的质量还是不错的!!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/一键难忘520/article/detail/883569
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

