
认识Retrieval Augmented Generation(RAG)
赞
踩
什么是RAG?
Retrieval-Augmented Generation (RAG) 是一种结合信息检索和生成式AI技术的框架。它通过从外部数据源检索信息,增强语言模型(如GPT-3)的生成能力,从而提供更加准确和相关的回答。
RAG的组成部分
信息检索模块(Retriever)
- 功能:从预先构建的知识库或文档库中检索与用户查询相关的信息。
- 技术:通常使用搜索引擎技术(如BM25、TF-IDF)或者基于深度学习的语义搜索模型(如BERT、DPR)。
生成式AI模块(Generator)
- 功能:根据检索到的信息和用户的查询生成自然语言的回答。
- 技术:使用生成式语言模型(如GPT-3、T5)来生成文本。
融合模块(Fusion)
- 功能:将检索到的信息与用户查询结合,并生成最终的回答。可以通过多种方式进行,如简单拼接、加权融合等。
- 技术:使用规则或机器学习方法将检索结果和生成结果进行整合。
为什么要使用RAG来改进LLM?举个例子
为了更好地展示什么是RAG以及该技术是如何工作的,让我们考虑一下当今许多企业面临的场景。
想象一下,你是一家销售智能手机和笔记本电脑等设备的电子公司的高管。您希望为您的公司创建一个客户支持聊天机器人,以回答与产品规格、故障排除、保修信息等相关的用户查询。
您希望使用LLM(如GPT-3或GPT-4)的功能为聊天机器人供电。
但是,大型语言模型有以下局限性,导致客户体验效率低下:
缺乏具体信息
语言模型仅限于基于其训练数据提供通用答案。如果用户要询问特定于您销售的软件的问题,或者他们对如何执行深入故障排除有疑问,传统的LLM可能无法提供准确的答案。
这是因为他们没有接受过特定于您组织的数据方面的培训。此外,这些模型的训练数据有一个截止日期,限制了它们提供最新响应的能力。
幻觉
LLM会“产生幻觉”,这意味着它们往往会根据想象中的事实自信地产生错误的反应。如果这些算法对用户的查询没有准确的答案,也会提供偏离主题的响应,从而导致糟糕的客户体验。
一般响应
语言模型通常提供不适合特定上下文的通用响应。这可能是客户支持场景中的一个主要缺点,因为通常需要个人用户偏好来促进个性化的客户体验。
RAG通过为您提供一种将LLM的一般知识库与访问特定信息(如产品数据库和用户手册中的数据)的能力相集成的方法,有效地弥补了这些差距。这种方法可以根据您组织的需求提供高度准确和可靠的响应。
RAG是如何工作的?
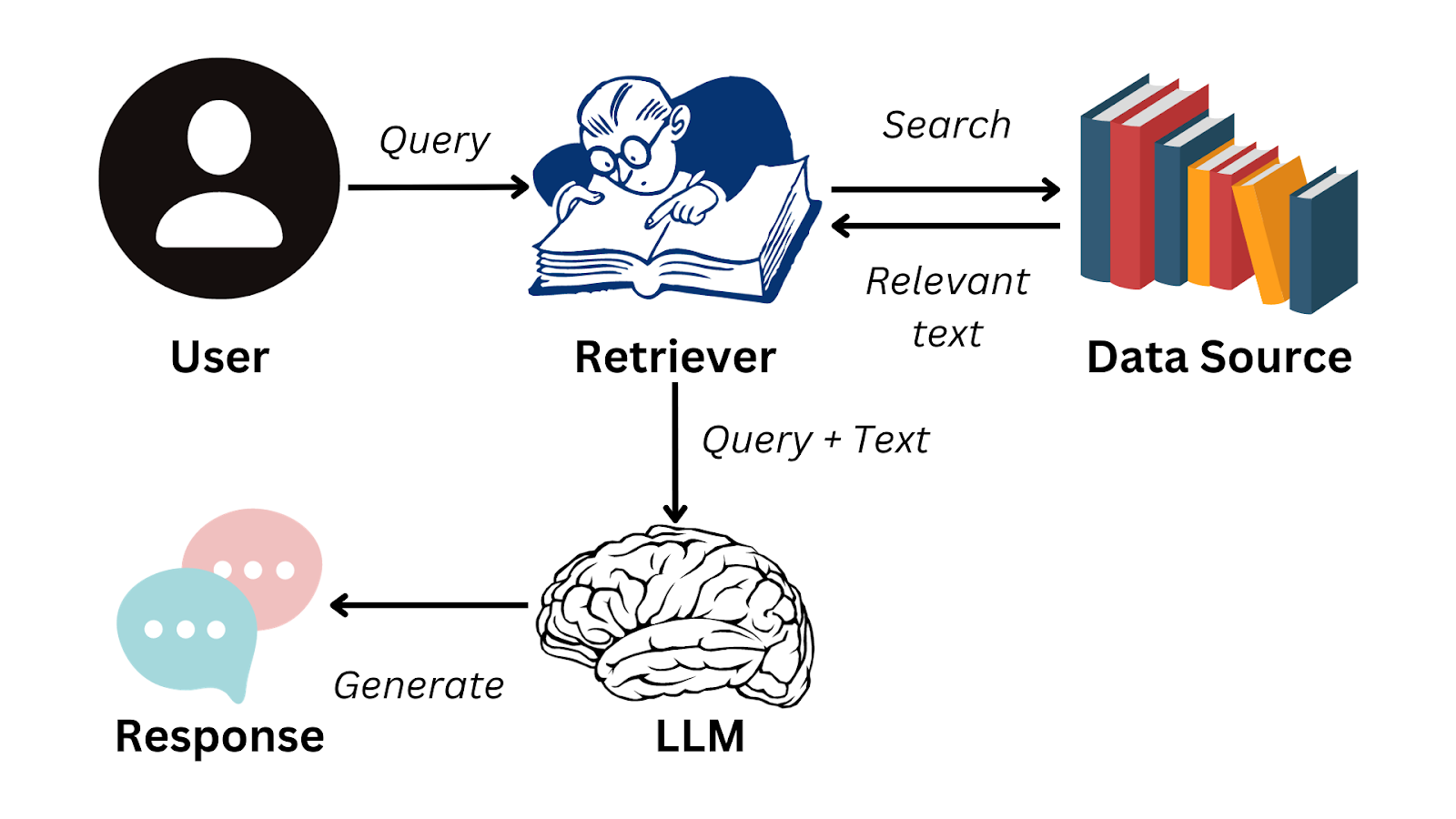
step1:数据收集(Data collection)
您必须首先收集应用程序所需的所有数据。如果是电子公司的客户支持聊天机器人,它可以包括用户手册、产品数据库和常见问题解答列表。
step2:数据分块(Data chunking)
数据分块是将数据分解为更小、更易于管理的部分的过程。例如,如果您有一份长达100页的用户手册,您可能会将其分解为不同的部分,每个部分都可能回答不同的客户问题。
这样,每个数据块都集中在一个特定的主题上。当从源数据集中检索一条信息时,它更有可能直接适用于用户的查询,因为我们避免包含整个文档中的不相关信息。
这也提高了效率,因为该系统可以快速获得最相关的信息,而不是处理整个文档。
step3:文本嵌入(Document embeddings)
既然源数据已经分解成更小的部分,就需要将其转换为向量表示。这涉及到将文本数据转换为嵌入,嵌入是捕捉文本背后语义的数字表示。
简而言之,文档嵌入允许系统理解用户查询,并根据文本的含义将其与源数据集中的相关信息进行匹配,而不是简单的逐字比较。此方法确保响应是相关的,并与用户的查询保持一致。
如果您想了解更多关于如何将文本数据转换为向量表示的信息,我们建议您探索我们关于使用OpenAI API进行文本嵌入的教程。
step4:处理用户查询(Handling user queries)
当用户查询进入系统时,还必须将其转换为嵌入或矢量表示。文档和查询嵌入必须使用相同的模型,以确保两者之间的一致性。
一旦将查询转换为嵌入,系统就会将查询嵌入与文档嵌入进行比较。它使用余弦相似性和欧几里得距离等度量来识别和检索嵌入与查询嵌入最相似的块。
这些块被认为是与用户的查询最相关的。
step5:使用LLM生成响应(Generating responses with an LLM)
检索到的文本块与初始用户查询一起被馈送到语言模型中。该算法将使用这些信息通过聊天界面生成对用户问题的连贯响应。
RAG的实际应用
文本摘要:
RAG可以利用外部数据源生成精确的摘要,节省大量时间。例如,经理和高管可以快速获取重要信息,而无需通读冗长的报告。
个性化推荐:
RAG系统可以分析客户数据,如过去的购买记录和评论,生成产品推荐,提高用户体验。例如,在流媒体平台上,根据用户的观看历史推荐电影。
商业智能:
企业通过监控竞争对手行为和分析市场趋势来做出商业决策。RAG可以高效地从商业报告、财务报表和市场研究文档中提取有意义的见解,提高市场研究过程的效率。
实现RAG系统的挑战
集成复杂性:
将检索系统与语言模型集成可能非常复杂,尤其是当外部数据源格式各异时。解决方案是为不同数据源设计独立模块,确保数据一致性。
可扩展性:
随着数据量的增加,维护RAG系统的效率变得更加困难。解决方案包括分布计算负载和投资强大的硬件基础设施,以及使用向量数据库以处理嵌入。
数据质量:
RAG系统的效果高度依赖于输入数据的质量。建议企业进行严格的数据源筛选和优化,必要时聘请专家审核数据。
总结
RAG 是利用大型语言模型并结合专门数据库的最佳技术之一。虽然存在输入数据质量依赖等限制,但通过谨慎的数据管理和专家知识的融合,可以确保系统的可靠性和有效性。
:::info
参考:
https://www.datacamp.com/blog/what-is-retrieval-augmented-generation-rag
ChatGPT-4o
:::

