
- 1CSS 颜色代码_css浅蓝色
- 2shardingsphere 集成springboot【水平分表】
- 3Android WebView调用系统相册和相机,注入以及与H5的交互_webview 增加打开相机相册交互
- 4有关windows10修改C盘用户中文名文件夹相关问题的具体解决方案_win10修改c盘下用户的文件夹名会出问题吗
- 5关于UE4打包问题_编译模式_实例1_ue4打包后效果不一样
- 6uniapp+vue微信小程序的 健身房预约系统_uniapp 热量数据
- 7OpenSSL/GMSSL EVP接口说明——3.5 加密解密_evp_pkey_ctx_set_ec_sign_type( pkctx, nid_sm_schem
- 82023最新玩客云刷机armbian,部署docker并配置各种常用容器镜像_玩客云 armbian
- 9Unity接入Steam平台详细流程一_steammanager获取名字
- 10十五、进程&线程&协程_pool.map 怎么等待主线程执行完
PhotoMaker:高效个性化的文本生成逼真人物照片方法
赞
踩

近期在文本到图像生成领域取得的进展在合成具有逼真外貌的人物照片方面取得了显著的进展,这些照片是根据给定的文本提示条件生成的。然而,现有的个性化生成方法不能同时满足高效性、良好的身份(ID)保真度和灵活的文本可控性的要求。本文引入了 PhotoMaker,这是一种高效的个性化文本到图像生成方法,它主要将任意数量的输入 ID 图像编码成一个堆叠的 ID embedding,以保留 ID 信息。这样的embedding作为一个统一的 ID 表示,不仅可以全面地封装相同输入 ID 的特征,还可以容纳不同 ID 的特征,以便进行后续的集成。这为更有趣和实际有价值的应用打开了道路。此外,为了推动 PhotoMaker 的训练,提出了一个以 ID 为导向的数据构建流程来收集训练数据。在通过所提出的流程构建的数据集的加持下,PhotoMaker 展现出比基于测试时微调的方法更好的 ID 保留能力,同时提供了显著的速度改进、高质量的生成结果、强大的泛化能力以及广泛的应用范围。
引言
与人物相关的定制图像生成引起了相当大的关注,催生了许多应用,如个性化肖像照片、图像动画和虚拟试穿。早期的方法受到生成模型(即 GANs)能力的限制,只能定制面部区域的生成,导致生成的多样性、场景丰富性和可控性较低。得益于更大规模的文本-图像对训练数据集、更大的生成模型以及能够提供更强语义embedding的文本/视觉编码器,最近扩散式文本到图像生成模型不断发展。这种演变使它们能够生成越来越逼真的面部细节和丰富的场景。由于存在文本提示和结构引导,可控性也大大提高了。
同时,在强大的扩散文本到图像模型的加持下,许多基于扩散的定制生成算法出现,以满足用户对高质量定制结果的需求。在商业和社区应用中最广泛使用的是基于 DreamBooth 的方法。这些应用需要几十张相同身份(ID)的图像来微调模型参数。尽管生成的结果具有较高的 ID 保真度,但存在两个明显的缺点:一是每次用于微调的定制数据需要手动收集,因此非常耗时且费力;二是每个 ID 的定制需要 10-30 分钟,消耗大量的计算资源,尤其是当生成模型变得更大时。因此,为了简化和加速定制生成过程,最近的研究工作通过现有的以人为中心的数据集,已经训练了视觉编码器或hypernetworks来表示输入 ID 图像为embedding或 LoRA模型的权重。训练后,用户只需提供要定制的 ID 的图像,就可以通过少量的微调甚至无需任何调整过程来实现个性化生成。然而,这些方法定制的结果不能像 DreamBooth 那样同时具有 ID 保真度和生成多样性(见下图 3)。

这是因为:
-
在训练过程中,目标图像和从同一图像中采样的输入 ID 图像都是相同的。训练后的模型容易记住与 ID 无关的图像特征,如表情和视角,导致编辑性差
-
仅依赖于单个要生成的 ID 图像使得模型难以从其内部知识中辨别 ID 的特征,导致 ID 保真度不佳。
基于上述两点,受到 DreamBooth 的启发,本文旨在:1) 确保 ID 图像条件和目标图像在视角、面部表情和配饰方面存在差异,使模型不会记住与 ID 无关的信息;2) 在训练过程中为模型提供多个相同 ID 的不同图像,以更全面、准确地表示定制 ID 的特征。
因此,本文提出了一种简单而有效的前馈定制人物生成框架,可以接收多个输入 ID 图像,称为 PhotoMaker。为了更好地表示每个输入 ID 图像的 ID 信息,在语义级别上堆叠多个输入 ID 图像的编码,构建了一个堆叠的 ID embedding。这个embedding可以被看作是要生成的 ID 的统一表示,它的每个子部分对应一个输入 ID 图像。为了更好地将这个 ID 表示和文本embedding整合到网络中,将文本embedding的类别词(例如,男人和女人)替换为堆叠的 ID embedding。结果embedding同时表示了要定制的 ID 和要生成的上下文信息。通过这个设计,在网络中不需要添加额外的模块,生成模型自己的交叉注意力层可以自适应地整合堆叠的 ID embedding中包含的 ID 信息。
同时,堆叠的 ID embedding能够在推断过程中接受任意数量的 ID 图像作为输入,同时保持类似其他无调整方法的生成效率。具体而言,方法在接收四个 ID 图像时,大约需要 10 秒生成一张定制的人物照片,这比 DreamBooth 快约 130 倍。此外,由于堆叠 ID embedding可以更全面、准确地表示定制 ID,相比于最先进的无调整方法,我们的方法在 ID 保真度和生成多样性方面表现更好。与先前的方法相比,框架在可控性方面也有了很大的改进。它不仅可以执行常见的语境重构,还可以更改输入人物图像的属性(例如,配饰和表情),生成一个与输入 ID 的角度完全不同的人物照片,甚至可以修改输入 ID 的性别和年龄(见下图 1)。

值得注意的是,PhotoMaker 还为用户提供了许多生成定制人物照片的可能性。具体而言,尽管构建堆叠 ID embedding的图像来自训练过程中相同的 ID,但可以在推断期间使用不同的 ID 图像来形成堆叠 ID embedding,从而合并并创建一个新的定制 ID。合并后的新 ID 可以保留不同输入 ID 的特征。例如,可以生成类似埃隆·马斯克的斯嘉丽·约翰逊,或者混合一个人与一个知名的 IP 角色的定制 ID(见上面图 1(c))。同时,合并比例可以通过提示加权或通过更改输入图像池中不同 ID 图像的比例来简单调整,展示了框架的灵活性。PhotoMaker 在训练过程中需要同时输入多个相同 ID 的图像,因此需要支持以 ID 为导向的人物数据集。然而,现有的数据集要么不按 ID 分类,要么只关注面部而不包括其他上下文信息。因此,设计了一个自动化流程来构建一个与 ID 相关的数据集,以便促进 PhotoMaker 的训练。通过这个流程,可以构建一个包含大量 ID 的数据集,每个 ID 都有多个图像,具有不同的视角、属性和场景。同时,在这个流程中,可以自动生成每个图像的标题,标记出相应的类别词,以更好地适应框架的训练需求。
相关工作
「文本到图像扩散模型」 。扩散模型在文本条件下的图像生成方面取得了显著进展,近年来吸引了广泛关注。这些模型的显著性能可以归因于高质量的大规模文本-图像数据集、基础模型的持续升级、条件编码器的引入以及可控性的改善。由于这些进展,Podell 等人开发了目前最强大的开源生成模型 SDXL。鉴于其在生成人像方面的出色性能,基于这个模型构建了PhotoMaker。然而,我们的方法也可以扩展到其他文本到图像合成模型。
「扩散模型中的个性化」 。由于扩散模型具有强大的生成能力,越来越多的研究者尝试基于它们进行个性化生成。目前,主流的个性化合成方法主要分为两类。一种依赖于在测试阶段的额外优化,例如 DreamBooth 和 Textual Inversion 。鉴于这两个开创性的工作都需要大量的时间进行微调,一些研究试图通过减少微调所需的参数数量或通过使用大型数据集进行预训练来加速个性化定制的过程。尽管取得了这些进展,它们仍然需要对预训练模型进行大量的微调,使该过程耗时且受到应用的限制。最近,一些研究尝试使用单个图像进行单次前向传递的方式进行个性化生成,从而显著加速了个性化过程。这些方法要么利用个性化数据集进行训练,要么在语义空间中对图像进行编码。我们的方法专注于基于上述两种技术方法生成人像。具体而言,它不仅依赖于构建以 ID 为导向的个性化数据集,还依赖于获取在语义空间中表示人物 ID 的embedding。与先前基于embedding的方法不同,PhotoMaker 从多个 ID 图像中提取堆叠的 ID embedding。提供更好的 ID 表示的同时,所提出的方法可以保持与先前基于embedding的方法相同的高效性。
方法
概述
给定要定制的几个 ID 图像,PhotoMaker 的目标是生成一张新的逼真人像,保留输入 ID 的特征并在文本提示的控制下更改生成的 ID 的内容或属性。尽管像 DreamBooth 一样输入多个 ID 图像进行定制,但仍然享有与其他无微调方法相同的效率,通过单次前向传递完成定制,同时保持较好的 ID 保真度和文本可编辑性。此外,还可以混合多个输入 ID,生成的图像可以很好地保留不同 ID 的特征,释放更多应用的可能性。上述能力主要是通过我们提出的简单而有效的堆叠 ID embedding实现的,它可以提供输入 ID 的统一表示。此外,为了方便训练PhotoMaker,设计了一个数据构建流程来构建一个按 ID 分类的以人为中心的数据集。图 2(a)显示了所提出的 PhotoMaker 的概述。图 2(b)显示了我们的数据构建流程。
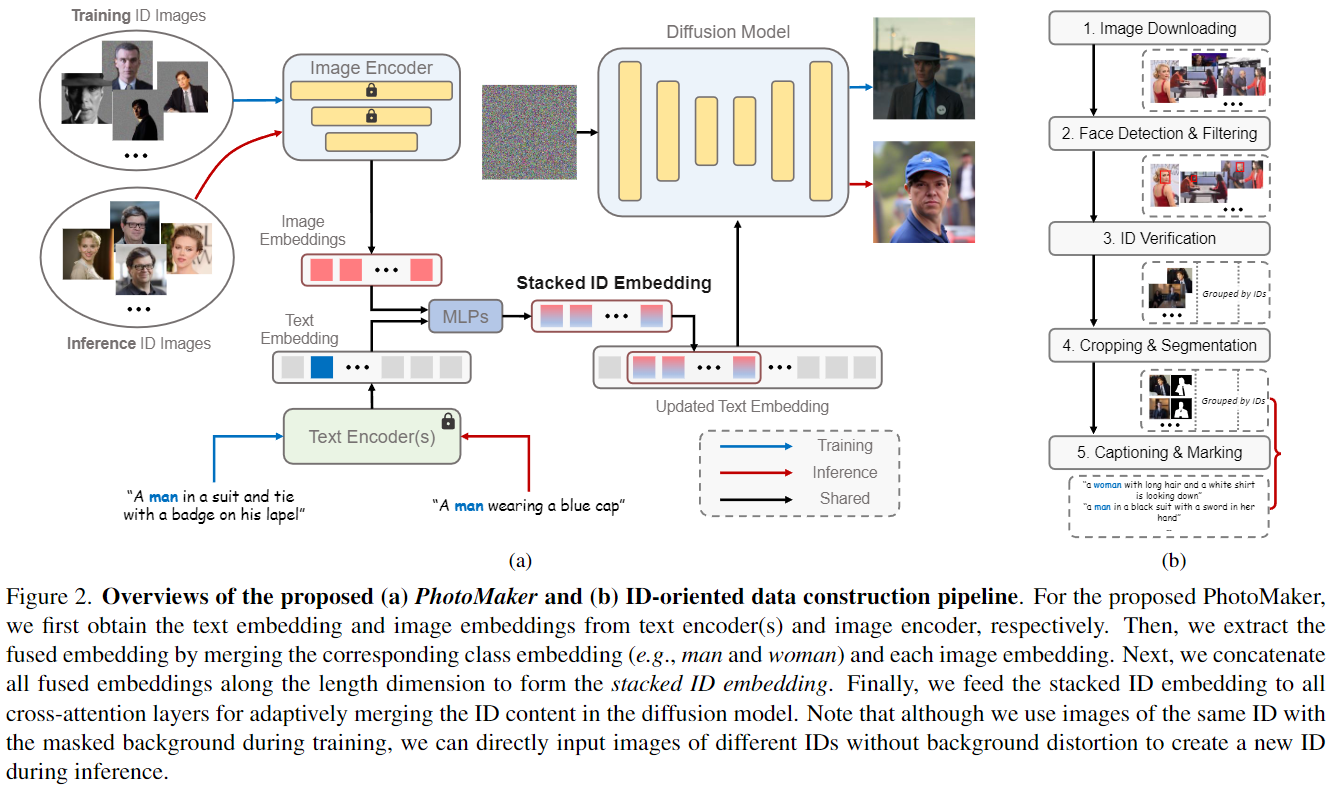
堆叠 ID embedding
「编码器」 。沿用最近的研究,我们使用 CLIP图像编码器 提取图像embedding,因为它与扩散模型中的原始文本表示空间对齐。在将每个输入图像馈送到图像编码器之前,填充了除特定 ID 的身体部分之外的图像区域,以随机噪声消除其他 ID 和背景的影响。由于用于训练原始 CLIP 图像编码器的数据主要由自然图像组成,为了更好地使模型能够从屏蔽的图像中提取与 ID 相关的embedding,在训练PhotoMaker 时微调了图像编码器中的一部分Transformer层。还引入了额外的可学习映射层,将从图像编码器中获取的embedding注入与文本embedding相同的维度。设表示从用户那里获得的 N 个输入 ID 图像,因此我们获得了提取的embeddings ,其中 D 表示映射维度。每个embedding对应于输入图像的 ID 信息。对于给定的文本提示 T,使用预训练的 CLIP 文本编码器 提取文本embedding ,其中 L 表示embedding的长度。
「堆叠」。最近的研究表明,在文本到图像的模型中,个性化的字符 ID 信息可以由一些唯一的标记表示。我们的方法也有类似的设计,以更好地表示输入人物图像的 ID 信息。具体而言,在输入标题中标记相应的类别词(例如,男人和女人)(见第后面章节)。然后,提取文本embedding中类别词位置的特征向量。这个特征向量将与每个图像embedding ei融合。我们使用两个 MLP 层执行这样的融合操作。融合后的embedding可以表示为。通过结合类别词的特征向量,此embedding可以更全面地表示当前输入的 ID 图像。此外,在推断阶段,这个融合操作还为定制生成过程提供了更强的语义可控性。例如,可以通过简单地替换类别词来定制人的年龄和性别。
在获得融合的embedding之后,沿长度维度将它们连接起来形成堆叠的 ID embedding:
![]()
这个堆叠的 ID embedding可以作为多个 ID 图像的统一表示,同时保留每个输入 ID 图像的原始表示。它可以接受任意数量的 ID 图像编码embedding,因此其长度 N 是可变的。与 DreamBooth-based 方法相比,该方法通过输入多个图像来微调模型以进行个性化定制,我们的方法本质上是同时向模型发送多个embedding。在将同一 ID 的多个图像打包成批作为图像编码器的输入之后,通过单次前向传递即可获得堆叠的 ID embedding,与基于微调的方法相比,这显著提高了效率。同时,与其他基于embedding的方法相比,这种统一的表示既可以保持良好的 ID 保真度和文本可控性,因为它包含更全面的 ID 信息。此外,值得注意的是,尽管在训练过程中只使用了同一 ID 的多个图像来构建这个堆叠的 ID embedding,但在推断阶段可以使用来自不同 ID 的图像来构建它。这种灵活性为许多有趣的应用打开了可能性。例如,可以混合现实中存在的两个人,或者混合一个人和一个著名的角色 IP。
「合并」。使用扩散模型中固有的跨注意力机制来自适应地合并堆叠的 ID embedding中包含的 ID 信息。首先用堆叠的 ID embedding替换原始文本embedding t 中与类词对应的位置上的特征向量,得到更新的文本embedding 。然后,跨注意操作可以表示为:
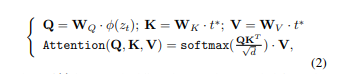
在这个公式中,ϕ(·) 是可以从输入潜在表示中由 UNet 降噪器编码得到的embedding。 是映射矩阵。此外,通过 prompt 加权 [3, 21],我们可以调整一个输入 ID 图像在生成新的定制 ID 时的参与程度,展示了PhotoMaker 的灵活性。最近的研究发现,通过简单地调整注意力层的权重,可以实现良好的 ID 定制性能。为了使原始的扩散模型更好地感知堆叠的 ID embedding中包含的 ID 信息,我们还额外训练了注意力层中矩阵的 LoRA 残差。
基于 ID 的人物数据构建
由于PhotoMaker 在训练过程中需要采样同一 ID 的多张图像来构建堆叠的 ID embedding,因此需要使用按 ID 分类的数据集来推动PhotoMaker 的训练过程。然而,现有的人物数据集要么没有标注 ID 信息,要么它们包含的场景丰富度非常有限(即,它们只关注脸部区域)。因此,在本节中,将介绍一种构建以不同 ID 分类的人物文本-图像数据集的流程。图 2(b)说明了提出的流程。通过这个流程,可以收集一个以 ID 为导向的数据集,其中包含大量的 ID,每个 ID 都有多张图像,包括不同的表情、属性、场景等。这个数据集不仅有助于PhotoMaker 的训练过程,还可能激发未来潜在的基于 ID 的研究。数据集的统计信息在附录中显示。
「图像下载:」 首先,列出了一份名人名单,可以从 VoxCeleb1 和 VGGFace2获得。根据名单在搜索引擎中搜索并爬取数据。每个名字下载了大约 100 张图像。在下载过程中,为了生成更高质量的肖像图像,过滤掉了最短边分辨率小于 512 的图像。
「人脸检测和筛选:」 首先使用RetinaNet检测脸部边界框,并过滤掉检测到的尺寸较小的边界框(小于256 × 256)。如果一张图像不包含任何满足要求的边界框,将过滤掉该图像。然后,对剩余的图像进行ID验证。
「ID验证:」 由于一张图像可能包含多张脸,需要首先确定哪张脸属于当前的身份组。具体而言,将当前身份组的所有脸部区域发送到ArcFace中,以提取身份embedding并计算每对脸部的L2相似度。将每个身份embedding计算得到的相似度与所有其他embedding相加,以得到每个边界框的分数。选择具有多张脸的每个图像的分数最高的边界框。在选择边界框后,重新计算每个剩余边界框的分数。通过ID组计算分数的标准差δ。经验性地使用8δ作为阈值,以过滤掉不一致ID的图像。
「裁剪和分割:」 首先根据检测到的脸部区域使用更大的正方形框裁剪图像,同时确保在裁剪后脸部区域能够占据图像的超过10%。由于需要在将其发送到图像编码器之前从输入ID图像中去除不相关的背景和ID,因此需要为指定的ID生成掩码。具体来说,使用Mask2Former 执行“人”类别的全景分割。保留与与ID相对应的脸部边界框具有最高重叠的掩码。此外,选择丢弃mask未被检测到的图像,以及在边界框和掩码区域之间没有重叠的图像。
「字幕和标记:」 使用BLIP2 为每个裁剪图像生成字幕。由于需要标记类别词(例如,男人、女人和男孩)以促进文本和图像embedding的融合,使用BLIP2的随机模式重新生成不包含任何类别词的字幕,直到出现一个类别词为止。在获得字幕之后,将字幕中的类别词单数化,以便专注于单个ID。接下来,需要标记与当前ID相对应的类别词的位置。只包含一个类别词的字幕可以直接标注。对于包含多个类别词的字幕,计算每个身份组的字幕中包含的类别词的数量。出现次数最多的类别词将成为当前身份组的类别词。然后,使用每个身份组的类别词来匹配并标记该身份组中的每个字幕。对于不包含与相应身份组的类别词匹配的类别词的字幕,使用依赖解析模型根据不同的类别词对字幕进行分割。通过SentenceFormer 计算分割后的子字幕与图像中特定ID区域之间的CLIP分数。此外,通过SentenceFormer 计算当前段的类别词与当前身份组的类别词之间的标签相似度。选择标记与CLIP分数和标签相似度的乘积最大的类别词。
实验
设置
「实现细节:」 为了生成更逼真的人物肖像,采用 SDXL 模型 (stable-diffusion-xl-base-1.0)作为文本到图像综合模型。相应地,训练数据的分辨率被调整为 1024 × 1024。采用 CLIP ViT-L/14 和一个额外的映射层来获取初始图像embedding 。对于文本embedding,保留 SDXL 中原有的两个文本编码器进行提取。整体框架在 8 个 NVIDIA A100 GPU 上使用 Adam进行优化,持续两周,batch size大小为 48。设置 LoRA 权重的学习率为 ,其他可训练模块的学习率为 。在训练期间,随机采样与当前目标 ID 图像相同 ID 的 1-4 张图像,形成一个堆叠的 ID embedding。此外,为了通过使用无分类器引导来提高生成性能,有 10% 的概率使用空文本embedding来替换原始更新的文本embedding 。还使用了 50% 的概率的mask扩散损失 ,以鼓励模型生成更忠实于 ID 的区域。在推断阶段,使用延迟主题调节来解决文本和 ID 条件之间的冲突。使用 50 epoch的 DDIM 采样器。无分类器引导的尺度设置为 5。
「评估指标:」 与 DreamBooth一样,使用 DINO和 CLIP-I指标来衡量 ID 的保真度,并使用 CLIP-T指标来衡量提示的保真度。为了进行更全面的评估,还计算了生成图像与具有相同 ID 的真实图像之间的面部相似性,通过检测和裁剪面部区域。使用 RetinaFace 作为检测模型,面部embedding是由 FaceNet 提取的。为了评估生成的图像的质量,使用 FID 指标。重要的是,由于大多数基于embedding的方法往往将面部姿势和表情纳入表示中,生成的图像在面部区域缺乏变化。因此,我们提出了一个指标,名为面部多样性,用于衡量生成的面部区域的多样性。具体而言,我们首先检测和裁剪每个生成图像中的面部区域。接下来,计算所有生成图像的所有面部区域对之间的 LPIPS 分数,并取平均值。这个值越大,生成的面部区域的多样性就越高。
「评测数据集:」 评估数据集包括 25 个 ID,其中包括来自 Mystyle的 9 个 ID,以及自己收集的额外的 16 个 ID。请注意,这些 ID 不会出现在训练集中,以评估模型的泛化能力。为了进行更全面的评估,还准备了 40 个提示,涵盖了各种表情、属性、装饰、动作和背景。对于每个 ID 的每个提示,生成了 4 张图像进行评估。更多细节请参见附录。
应用场景
在这一部分,将详细介绍PhotoMaker 能够赋予的各种应用。对于每个应用,我们选择与相应设置最适合的比较方法。比较方法将从 DreamBooth、Textual Inversion 、FastComposer 和 IPAdapter中选择。优先使用每种方法提供的官方模型。对于 DreamBooth 和 IPAdapter,使用它们的 SDXL 版本进行公平比较。对于所有应用,选择了四个输入 ID 图像来形成PhotoMaker 中的堆叠 ID embedding。还公平地使用四张图像来训练需要测试时优化的方法。在附录中为每个应用提供了更多的样本。
「重构语境」
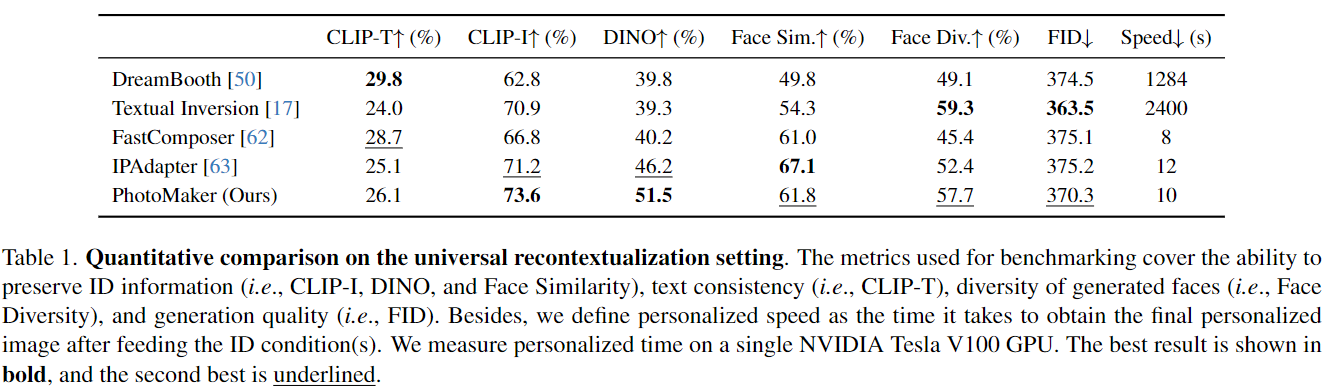
首先,展示了对简单情境更改的结果,例如修改头发颜色和服装,或基于基本提示控制生成背景。由于所有方法都能够适应这种应用,对生成的结果进行了定量和定性比较(见下表 1 和上图 3)。结果表明,我们的方法能够满足生成高质量图像的能力,同时确保高 ID 保真度(具有最大的 CLIP-T 和 DINO 分数,以及第二高的面部相似度)。与大多数方法相比,我们的方法生成了更高质量的图像,生成的面部区域展现出更大的多样性。同时,我们的方法可以保持与基于embedding的方法一致的高效性。为了进行更全面的比较,在附录 B 中展示了用户研究结果。
「将艺术作品/老照片中的人物带入现实:」 通过将艺术绘画、雕塑或过去的照片作为输入,PhotoMaker 可以将上个世纪甚至古代的人物带到现在为他们“拍照”。下图 4(a) 展示了结果。与我们的方法相比,Dreambooth 和 SDXL 都难以生成现实中没有出现过的逼真人物图像。此外,由于 DreamBooth 过度依赖于定制图像的质量和分辨率,当使用旧照片进行定制生成时,DreamBooth 很难生成高质量的结果。

「改变年龄或性别:」 通过简单地替换类别词(例如男人和女人),我们的方法可以实现对性别和年龄的改变。图4(b)展示了结果。虽然SDXL和DreamBooth在进行提示工程后也可以实现相应的效果,但由于堆叠IDembedding的作用,我们的方法更容易捕捉字符的特征信息。因此,我们的结果显示出更高的ID保真度。
「身份混合:」 如果用户提供不同ID的图像作为输入,PhotoMaker可以很好地整合不同ID的特征形成新的ID。从下图5中,可以看到DreamBooth和SDXL都不能实现身份混合。相反,我们的方法可以在生成的新ID上很好地保留不同ID的特征,无论输入是动漫IP还是真实人物,无论性别如何。此外,可以通过控制相应ID的输入数量或提示加权来控制新生成的ID中该ID的比例。在附录的图10-11中展示了这种能力。

「风格化:」 在下图6中,展示了我们方法的风格化能力。可以看到,在生成的图像中,PhotoMaker不仅保持了良好的ID保真度,而且有效展现了输入提示的风格信息。这展示了我们的方法推动更多应用的潜力。在附录的图12中展示了更多的结果。

消融研究
将总训练迭代次数缩短了八倍,以进行每个变体的消融研究。
关于输入ID图像数量的影响。探讨了通过提供不同数量的ID图像形成所提出的堆叠ID embedding的影响。在图7中,通过不同的指标可视化了这种影响。得出结论,使用更多图像来形成堆叠ID embedding可以改善与ID真实性相关的指标。当将输入图像的数量从一个增加到两个时,这种改善特别明显。随着输入ID图像数量的增加,与ID相关的指标的值增长速率明显减缓。此外,观察到 CLIP-T 指标呈线性下降。这表明在文本可控性和ID真实性之间可能存在权衡。
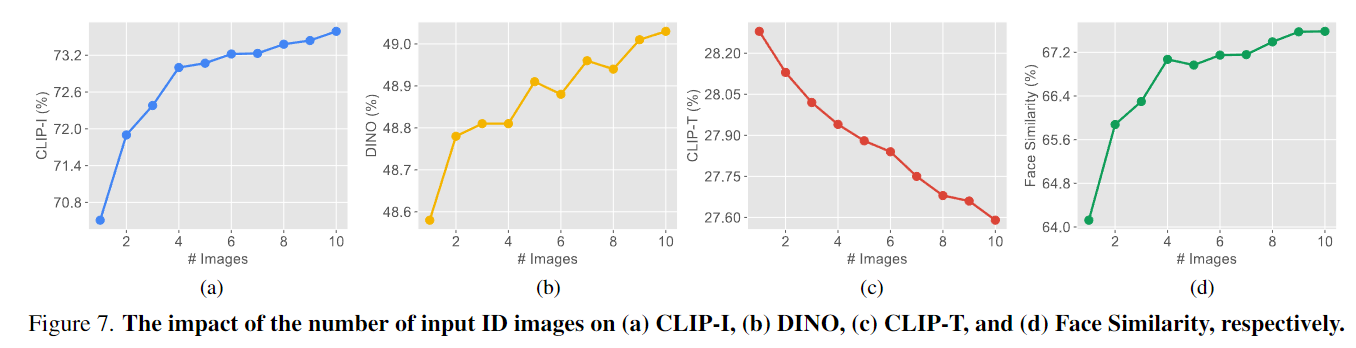
从下图8中,可以看到增加输入图像的数量可以增强ID的相似性。因此,使用更多ID图像来形成堆叠ID embedding可以帮助模型感知更全面的ID信息,从而更准确地表示ID以生成图像。此外,正如德韦恩·约翰逊的例子所示,性别编辑能力下降,模型更容易生成原始ID性别的图像。

「多个embedding组合的选择」。探讨了三种组合ID embedding的方法,包括平均图像embedding、通过线性层自适应映射embedding以及我们的堆叠方式。从表2a中,我们看到堆叠方式在确保生成的面部多样性的同时具有最高的ID真实性,表明其有效性。此外,这种方式比其他方式具有更大的灵活性,包括接受任意数量的图像并更好地控制不同ID混合过程。
「在训练期间多个embedding的好处」。探讨了另外两种训练数据采样策略,以证明在训练期间输入具有变化的多个图像是必要的。第一种是选择仅一个图像,它可以与目标图像不同,以形成IDembedding(参见表2b中的“单一embedding”)。多重embedding方式在ID真实性方面具有优势。第二种采样策略是将目标图像视为输入ID图像(以模拟大多数基于embedding的方法的训练方式)。基于该图像使用不同的数据增强方法生成多个图像,并提取相应的多个embedding。在表2b中,由于模型可以轻松记住输入图像的其他不相关特征,生成的面部区域缺乏足够的变化(多样性低)。

结论
本文提出了一种高效的个性化文本到图像生成方法,称为PhotoMaker,专注于生成逼真的人物照片。本文的方法利用了一种简单而有效的表示方式,即堆叠ID embedding,以更好地保留ID信息。实验证明,与其他方法相比,PhotoMaker能够同时满足高质量和多样性的生成能力,具有良好的可编辑性、高推理效率和强大的ID真实性。此外,还发现本文的方法能够赋予许多有趣的应用,这是以前的方法难以实现的,例如改变年龄或性别,将老照片或艺术作品中的人物带回现实,并进行身份混合。





参考文献
[1] photo maker:Customizing Realistic Human Photos via Stacked ID Embedding
链接:https://arxiv.org/pdf/2312.04461
开源链接:https://photo-maker.github.io/
更多精彩内容,请关注公众号:AI生成未来


