
- 1游戏服务器的架构演进、多进程架构通信
- 2Ubuntu20.04安装网易云音乐播放器_播放器lubuntu在线
- 3【Peewee】Python使用Peewee创建数据库_peewee python
- 4[Win32] python纯ctypes获取exe图标_python提取exe图标文件
- 5【项目小知识】JSP和HTML的区别_html和jsp的区别
- 6详细功能及代码快速帮您接入百度大脑人脸融合_百度照片融合功能在哪
- 7腾讯云幻兽帕鲁服务器使用Linux和Windows操作系统,对用户的技术要求有何不同?
- 8Java 从单核到多核的多线程(并发)_java用多核
- 9【最短路径算法】一文掌握Dijkstra算法,详解与应用示例+代码
- 10cka真题练习(十五)设置节点不可用调度所有pod_cka 真题
【C++进阶07】哈希表and哈希桶
赞
踩

一、哈希概念
顺序结构以及平衡树中
元素关键码与存储位置没有对应关系
因此查找一个元素
必须经过关键码的多次比较
顺序查找时间复杂度为O(N)
平衡树中为树的高度,即O( l o g 2 N log_2 N log2N)
搜索效率 = 搜索过程中元素的比较次数
理想的搜索方法:不经任何比较
一次直接从表中获取想要的元素
构造一种存储结构
通过某种函数(hashFunc)使元素的存储位置
与它的关键码之间建立一一映射的关系
就能在查找时通过该函数直接找到该元素
向该结构中:
插入元素:
根据待插入元素的关键码
以此函数计算出该元素的存储位置并按此位置
进行存放
搜索元素:
对元素的关键码进行同样的计算
把求得的函数值当做元素的存储位置
在结构中按此位置取元素比较
若关键码相等,则搜索成功
该方式即为:
哈希(散列)方法
哈希方法中使用的转换函数称为:
哈希(散列)函数
构造出来的结构称为:
哈希表(Hash Table)(或者称散列表)
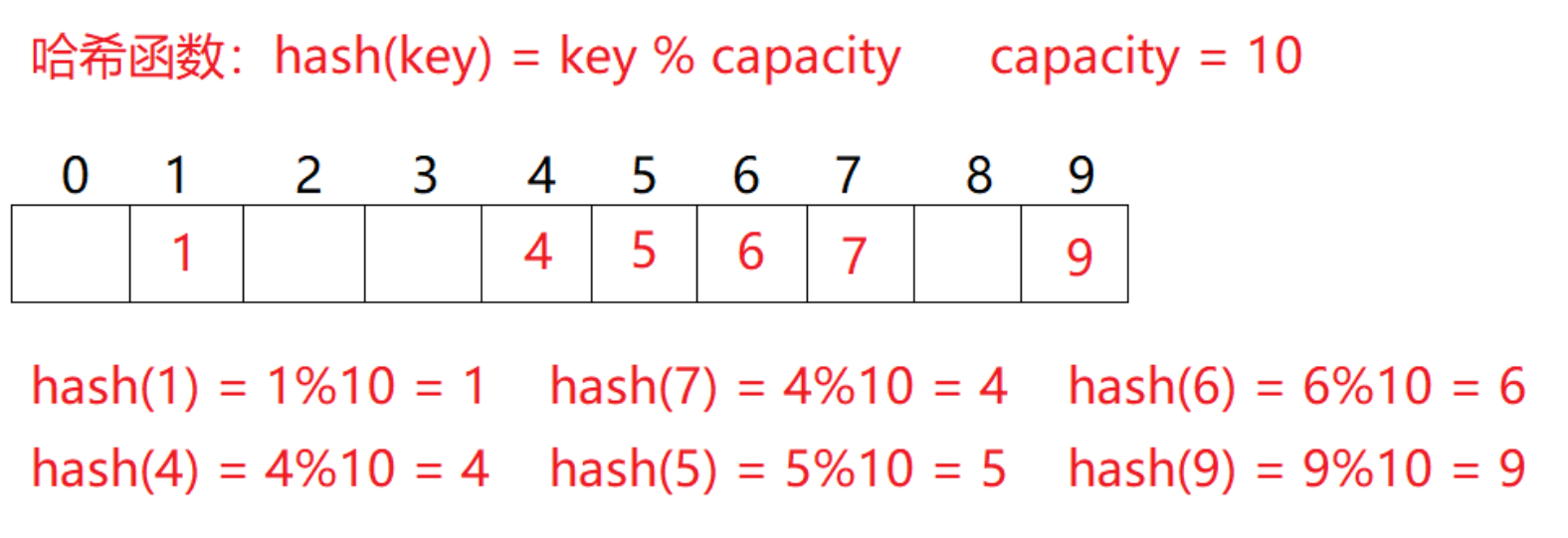
例如:
数据集合{1,7,6,4,5,9};
哈希函数设置为:
hash(key) = key % capacity;
capacity:
存储元素底层空间总的大小
二、哈希冲突
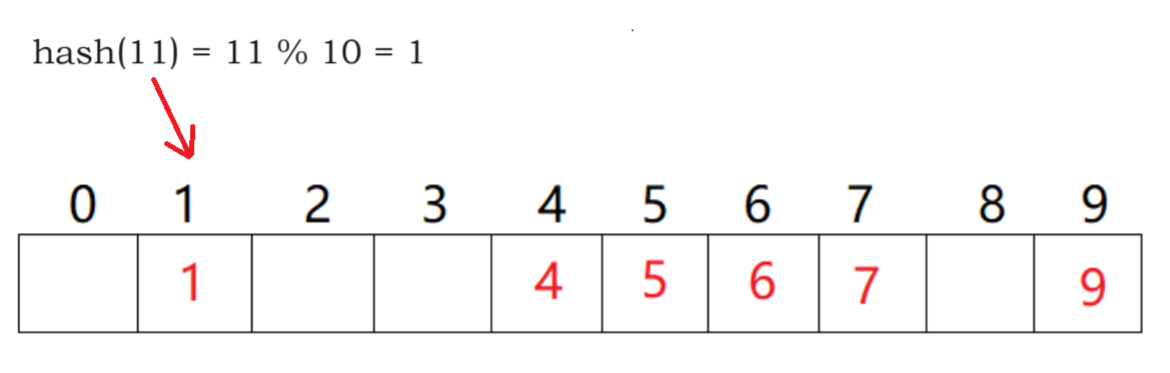
不同关键字通过相同的哈希函数
计算出相同的哈希地址
该种现象称为哈希冲突或哈希碰撞
把具有不同关键码
而具有相同哈希地址的数据元素称为“同义词”
11、21、31…数据经过哈希函数计算都为1
都插入在下标为1的地方便会冲突
三、哈希函数
引起哈希冲突的一个原因可能是:
哈希函数设计不够合理
哈希函数设计原则:
- 哈希函数的定义域必须包括
需要存储的全部关键码
而如果散列表允许有m个地址时
其值域必须在0到m-1之间 - 哈希函数计算出来的地址能均匀分布在
整个空间中 - 哈希函数应该比较简单
常用哈希函数:
-
直接定址法
取关键字的某个线性函数为散列地址:
Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
面试题:字符串中第一个只出现一次字符 -
除留余数法
设散列表中允许的地址数为m
取一个不大于m
但最接近或等于m的质数p作为除数
按照哈希函数:
Hash(key) = key% p(p<=m)
将关键码转换成哈希地址
四、哈希冲突解决
解决哈希冲突两种常见方法:
闭散列和开散列
4.1 闭散列
闭散列:也叫开放定址法
当发生哈希冲突时
如果哈希表未被装满
说明哈希表中必然还有空位置
那么可以把key存放到
冲突位置的“下一个” 空位置中去
那如何寻找下一个空位置呢?
- 线性探测
从发生冲突的位置开始
依次向后探测
直到寻找到下一个空位置为止
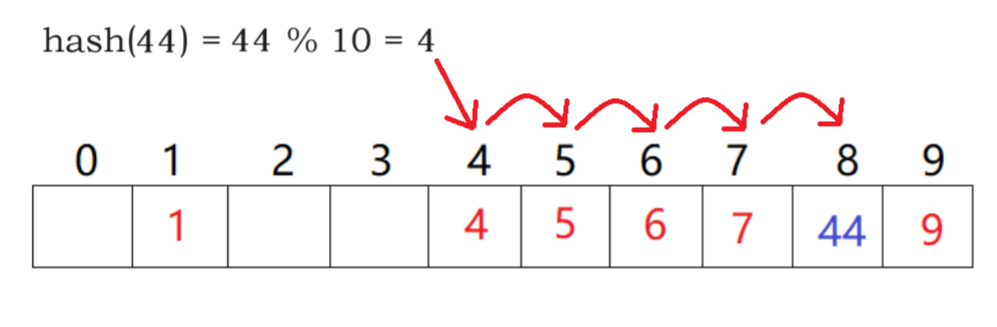
线性探测优点:实现简单
线性探测缺点:一旦发生哈希冲突
所有的冲突连在一起,容易产生数据“堆积”
即:不同关键码占据了可利用的空位置
使得寻找某关键码的位置需要许多次比较
导致搜索效率降低
- 二次探测
线性探测的缺陷是
产生冲突的数据堆积在一块
这与其找下一个空位置有关系
因为找空位置的方式就是挨着往后逐个去找
因此二次探测为了避免该问题
找下一个空位置的方法为:
H
i
H_i
Hi = (
H
0
H_0
H0 +
i
2
i^2
i2 )% m
或者:
H
i
H_i
Hi = (
H
0
H_0
H0 -
i
2
i^2
i2 )% m
其中:i = 1,2,3…,
H
0
H_0
H0是通过
散列函数Hash(x)对元素的关键码 key
进行计算得到的位置,m是表的大小
研究表明:当表的长度为质数且表装载因子
a不超过0.5时,新的表项一定能够插入
而且任何一个位置都不会被探查两次
因此只要表中有一半的空位置
就不会存在表满的问题
在搜索时可以不考虑表装满的情况
但在插入时必须确保表的装载因子a不超过
0.5,如果超出必须考虑增容
因此:比散列最大的缺陷就是空间利用率
比较低,这也是哈希的缺陷
4.2 开散列
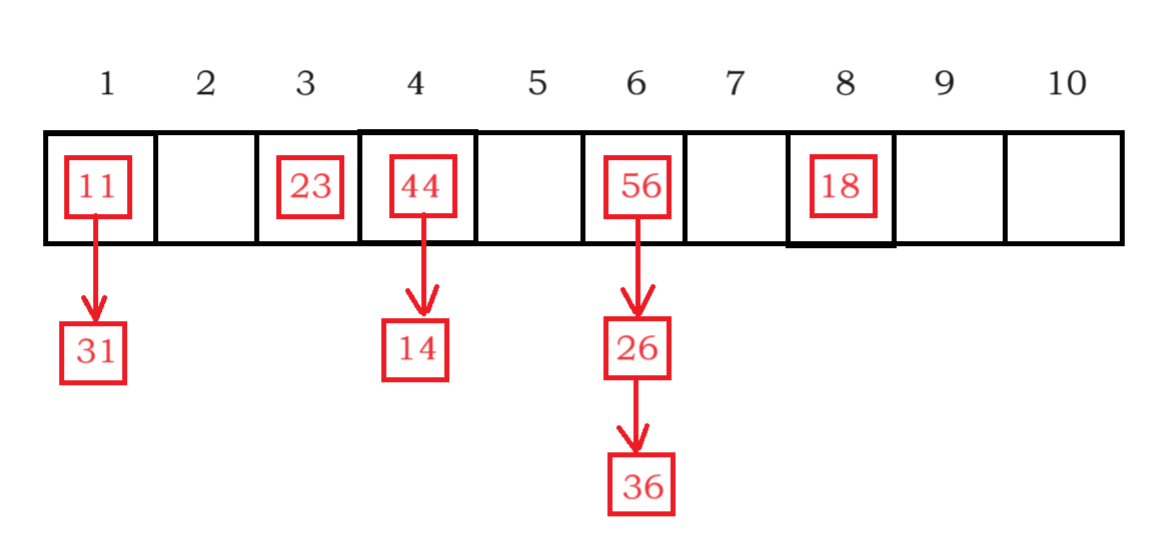
开散列法又叫链地址法(开链法)
首先对关键码集合用散列函数计算散列地址
具有相同地址的关键码归于同一子集合
每一个子集合称为一个桶
各个桶中的元素通过一个单链表链
接起来,各链表的头结点存储在哈希表中
如图:
将哈希地址相同的元素链接在同一个桶下面
在实际应用中
开散列比闭散列更实用
- 哈希桶负载因子更大
空间利用率高 - 极端情况也有解决方案
哈希桶极端情况:
所有元素在同一个桶
为了避免这种情况
当桶超过一定高度
将该桶转换为红黑树结构
五、哈希桶的模拟实现
5.1 基本框架
namespace HashBucket // 哈希桶 { template <class K, class V> struct HashNode { pair<K, V> _kv; HashNode<K, V>* _next; // 单链表的方式链接 HashNode(const pair<K, V>& kv) : _next(nullptr) , _kv(kv) {} }; template <class K, class V> class HashTable { typedef HashNode<K, V> Node; public: private: vector<Node*> _tables; size_t _n = 0; // 存储的有效数据个数 }; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
5.2 插入元素
哈希桶的增容
若哈希表的大小为0
将哈希表的初始值设置为10
若哈希表的负载因子等于1
创建一个新表,大小是原表的两倍
用新表的哈希函数计算旧表的每个
元素在新表的映射位置
将旧表的每个元素头插进新表
bool Insert(const pair<K, V>& kv) { // 去重, 插入之前先查找有没有相同的元素 if (Find(kv.first)) return false; // 负载因子 == 1时扩容 if (_n == _tables.size()) { // 哈希表大小为0,将哈希表初始值设为10 size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2; vector<Node*> newtables(newsize, nullptr); for (auto& cur : _tables) { while (cur) // current不为空, 把挂着的数据一个一个移到新表 { Node* next = cur->_next; size_t hashi = cur->_kv.first % newtables.size(); // 头插到新表 cur->_next = newtables[hashi]; newtables[hashi] = cur; cur = next; } } _tables.swap(newtables); } size_t hashi = kv.first % _tables.size(); // 头插 Node* newnode = new Node(kv); newnode->_next = _tables[hashi]; _tables[hashi] = newnode; ++_n; return true; } Node* Find(const K& key) { if (_tables.size() == 0) return nullptr; size_t hashi = key % _tables.size(); Node* cur = _tables[hashi]; while (cur) { if (cur->_kv.first == key) { return cur; } cur = cur->_next; } return nullptr; } bool Erase(const K& key) { size_t hashi = key % _tables.size(); Node* prev = nullptr; Node* cur = _tables[hashi]; while (cur) { if (cur->_kv.first == key) { if (prev == nullptr) { _tables[hashi] = cur->_next; } else { prev->_next = cur->_next; } delete cur; return true; } else { prev = cur; cur = cur->_next; } } return false; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
✨✨✨✨✨✨✨✨
本篇博客完,感谢阅读
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

