
- 1AI绘画火爆,到现在还只是冰山一角?AIGC掀起当代新艺术浪潮_aigc 冰山
- 2使用wget下载KITTI数据集_小一点的数据集下载
- 3Dubbo高级应用-分布式服务化_dubbo.consumer.check=false
- 4Linux学习笔记之一:tar命令:打包czvf,解压xzvf_tar-zcvf压缩命令
- 5YOLOV5_yolov5是什么东西
- 6yum安装时报RPM-GPG-KEY错
- 7C#之WPF学习之路(4)
- 8ffmpeg系列-视频旋转角度实现_mediacodec-auto-rotate
- 9Python 利用Turtle模块绘制国际象棋棋盘_用海龟编辑器画一个象棋棋盘的代码怎么做
- 10CSDN规则详解(一)
基于CU,PO,RD,IPO矩阵图分析数据资产-自创_po矩阵 rd ipo cu
赞
踩
术语
数据资产:数据资产是具有价值的数据资源。没有价值的数据资源,通过采集,整理,汇总等加工后,也可以成为具有直接或间接价值的数据资产。传统企业逐渐数字化转型,尤其是互联网企业,都十分重视企业的的数据资产。这些数据通过大数据处理,提供给商业智能化,或人工智能等使用,会给公司带来直接或间接的经济效益。这些数据资产通常的表现形式,诸如关系型数据库数据库,如mysql,oracle等的结构化库表数据,也包括大数据,数仓如hive,hbase,hudi,mongodb,es等结构化与半结构化的数据。
CU矩阵: CU矩阵中的C指create创建,U指use使用的意思。可以用来标记一个数据相关联的重要的两个属性。例如Hive表数据的创建者,以及Hive表的使用者。创建者可以是多个,使用者也可以是多个,创建者和使用者可以相同,也可以不同。
PO矩阵:PO矩阵中的P是指过程,例如数据的生产过程,O是指组织,如企业内部的某个部门或某个小组。PO矩阵,可以用数据在生产过程中经过哪些组织,与哪些组织产生关系。
RD矩阵:RD矩阵中的R是指resource资源,D指data数据。RD矩阵可以指出在生产,使用数据过程中要是用到哪些资源。这样可以对数据的生产成本,使用成本可以进行评估。
IPO图:在企业业务团队,使用数据进行生产任务的过程中,分析每个过程的输入数据类,输出数据类。并且与RD矩阵进行调整。最后总结出整个生产链条,涉及系统的数据类。形成一张链路图。可以对重点任务,重点数据类进行标记。
背景技术
随着传统行业积极主动的向数字化转型,以及互联网行业的业务不断拓展。像金融,社交媒体,视频网站,电商零售,传统房地产,车联网企业,制造业,工业互联网等每天都产生大量的数据,这些数据就像水一样,处理的好会成为一种力量能源,帮助公司的业务能够朝着正确的方向,更好更快的前进;处理不好也会像洪水那样成为一种泛滥灾难,会给个人,企业甚至社会,国家制造巨大的损失。
既然数据是一把双刃剑,怎么样,收集,处理,用好这些数据。使其真正成为企业的数据资产,而不是负债。就需要一套完整,系统的方法,对现有的数据进行价值分析,评价的方法,甚至形成一套系统的,自动化的进行数据资产的分析方法与系统工具。进而更好的管理数据,利用数据,为企业创造更大的价值。
在进行数据资产管理的时候,很多场景都需要明确知道数据的生产者,使用者。以及数据的生产过程,涉及的部门,数据生产与使用成本。数据资产管理,涉及对数据的复用,生产,数据资产成本分析,数据资产评级等,形成系统化的功能后,可以总结,并开发出数据资产管理相关的系统或产品。
现在企业做做数据资产管理的时候,大多会集成到数据中台。数据中台可能会存有有整个公司的业务数据。会有数仓相关建设。数据收集,清洗,加工。然后存到Hive,hbase,hudi,或kafka等hadoop相关生态系统,大数据体系。数据中台提供存储,计算,相关平台。给业务,BI,人工智能等相关部门使用。在对数据资产进行管理的时候,往往需要集中的元数据管理系统。但是元数据管理系统不能仅仅只局限与采集,展示一些基本信息,如mysql,Hive的库表列,分区等信息,以及表的血缘,字段的血缘。元数据还应该展示关联更多业务相关,打通与业务元数据,操作元数据之间的关系。提供丰富,有意义的数据资产相关的一些图形化展示,api查询,数据分析流程等相关能。
在分析数据资产,进行数据治理的时候,可以借助开源软件,例如Atlas通过采集元数据相关信息,建了数据的血缘关系图。通过分析血缘关系,来分析数据资产,以及进行数据治理等工作。
在系统化的分析数据资产的时候,我们可以借助信息系统规划中的各种矩阵。如:CU矩阵图,RD矩阵图,PO矩阵图,IPO矩阵图等工具,来分析数据资产。
现有技术
- Atlas等开源软件采集hive,hbase等表的血缘关系图,展示数据的表与表的关系。
现有技术实现方案
- Atlas等开源软件,提供了表的血缘关系图,这些血缘,记录了表与表的关系。下游表关联了上游表。
- Atlas的血缘关系图,以信息节点的方式,展示数据流转路线。数据流转的线路,在血缘图中,经过节点从左到右。一个数据节点可能有多个父节点,父节点上游表示输入。可以有多个下游,表示数据的使用。
- Atlas的血缘关系图对数据溯源,数据价值评估,数据质量评估,数据的归档或销毁提供参考。
- Atlas提供统一数据模板,将按模板导入的数据,构建可视化的血缘关系图。
现有技术缺点
- Atlas血缘关系图,信息节点,展示了数据与数据之间的应用关系,没有完全识别数据的生产者消费者。这种关系图一般只能一次直观的查看一个表数据的上下游关联关系。
- Atlas血缘关系图,对数据的加工过程,涉及到的组织部门没有进行分析展示。
- Atlas血缘关系图,对数据的输入,处理工程,输出的展示是信息节点,具体就是到表,但是具体的输入,怎么处理没有明确的标识。
- Atlas对数据价值,数据质量的评估,还比较粗略。不能通过成本分析,使用的重要性,关联组织部门等维度进行进一步确认分析。而且在做数据成本计算,并将数据成本分别计算分摊到使用人员,以及使用部门的时候,找不到相关组织部门。
- 进行数据治理的时候,Atlas血缘关系图只能提供数据的上下游是否有节点,下游是否有在使用。但是无法关联使用者,数
- 据的重要程度,数据的加工逻辑。
作者自研技术方案
设计方案框图

如上图所示为本发明的设计方框图,需要注意的是,这里只列举了整个设计的大致流程图。
先分别采集数据资产相关元数据,如数仓Hive,或者mysql等的库表列,存储,CPU耗时,带宽,流量等元数据;以及数据的加工过程,涉及业务组织部门,输入,输出报表等业务元数据存到Mysql。然后计算数据资产的CU矩阵图,RD矩阵图,PO矩阵图和IPO矩阵图。然后分别计算数据资产的:可靠度,使用权重,成本值,部门关联度,过程复杂度,输入,产出值等指标。进而可以对数据进行:数据归属的溯源,数据流转路线分析,数据价值评估,数据质量评估,数据归档销毁参考等数据相关的治理。
设计方案流程
-
数据采集
数据采集有很多种方式,很多途径,也有很多数据源。包括数仓的Hive,hbase,kafka等元数据,包括库表字段,存储等元信息。还需要采集业务相关的元数据,如数据的加工过程,涉及到的部门组织,数据的输入,输出。创建者,使用者等归属信息。
对于hive元数据的采集可以用Hive-metastore相关接口,或编写hive-metastore-listener监听器,批量采集或实时的监听采集Hive元数据。或者hive-hook采集hive执行的sql建立表与表的血缘关系数据。或人工批量维护导入的方式进行采集。
对于hbase的元数据,可以分析hbase的zookeeper数据,或者使用hbase的Admin的相关api进行采集。也可以人工进行维护导入。
Kafka的元数据采集可以使用kafka提供的管理相关的api进行采集,或者人工维护导入。
对于业务元数据的采集则需要各个业务部门提供相关的API进行业务元数据的采集。最终将业务元数据也数据资产元数据进行关联。
-
数据计算与输出展现方式
元数据采集完毕,将数据资产元数据与业务资产元数据进行关联。计算得到数据资产相关的CU矩阵图,RD矩阵图,PO矩阵图,以及IPO矩阵图相关数据。
这些数据可以存到hbase,例如存放表与表的血缘数据,业务过程与业务过程的血缘数据。或者存到mysql,例如数据的归属信息,使用者信息,过程相关的组织部门信息,数据的CPU,存储,网络流量,带宽,人力成本等相关信息。
可以分别通过,数据的CU矩阵图计算,可靠度,使用权重指标;通过数据的RD矩阵图计算,成本值指标;通过PO矩阵图计算,部门关联度,过程复杂度指标;以及通过IPO图计算输入,产出值,过程复杂度等指标。
提供按照不同维度,不同指标,不同排序方式等查询统计的相关API接口,可以供页面或其他第三方调用。根据相关指标,对数据资产进行全方位,精准化分析。方便的数据进行管理,与更好的利用数据产生价值。
其中具体的数据计算与展示方式,列举如下:
数据的CU矩阵展示

如上图所示展示了SYS库下18张表的CU矩阵的可视化图。每个表格是一个表对象。红色部分表示创建者,蓝色表示使用者。当创建者越多,红色的颜色就越深。使用者越多,蓝色的颜色就越深。当鼠标移动到表格上自动展示表的一些元信息,如表名,创建者,使用者。其他信息。在整个矩阵可视化展示中,我们可以按照颜色的深浅,由浅到深,从左上角到右下角排序展示。这样可以快速直观的找到一些使用较多,创建者较多等,比较重要的表。可以直观,快速的可视化查找。
数据可靠度计算方法
基于CU矩阵,数据的可靠性假设取值为R,R=COUNT(U)-COUNT(C)。即,数据可靠度等使用者数量-创建者数量。理论上当R值越大,我们觉得可靠性越大。当使用者越多的时候,数据的价值越大。在考虑数据归档下线的时候,也可以考虑该值是否造成很大影响。
除了标记创建者,使用者我们还可以通过创建者使用找到对应的部门。标记创建者的个数,使用者的个数外,还可建立表的血缘关系。

如上图所示,标记数据创建是否有来源表,以及下游使用该表数据的表。该图展示了数据表与表的血缘关系的血缘C/U矩阵图,表sys.user_info的来源表有2个,关联的下游表有6个。
数据使用权重计算方法
基于CU矩阵,数据使用权重:DW=下游表个数+上游表个数。权重值越大,说明与数据的关联越多。当下游越多的时候,数据的价值越大。在考虑数据归档下线的时候,也可以考虑该值是否造成很大影响。
数据的PO矩阵展示方法

如上图所示,展示了表ods.user_ops的PO矩阵图。该数据涉及到4个过程,分别是用户填写生产,风控审批验证,存入业务系统,采集ETL到数仓。涉及的部门分别有业务综合部门,营销研发部,风控研发部,大数据研发部。其中每个部门对应到自己所对该数据的处理过程、有关联则打勾。
数据部门关联度的计算方法
基于数据的PO矩阵,计算数据的关联度,R=有关联过程的部门个数相加。可能一个过程关联多个部门,也可能一个部门。当R值越大,说明关联度越大。这种数据需要引起高度重视,也是十分重要的数据资产。
数据过程复杂度的计算方法
基于数据的PO矩阵,计算数据的关联度,R=过程数*有关联过程的部门个数相加。当复杂度越高。说明处理过程越多,则这种数据资产流转部门越多。
数据的RD矩阵展示方法
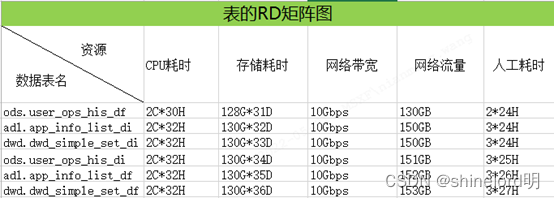
如上图所示,展示6张表RD矩阵图,可以按照成本细化进行排序。对CPU耗时,存储耗时(数据是有生命周期的就耗时值数据存在多长时间,暂用了多少存储),网络带宽,网络流量,人工耗时。这些成本以后可以用不同的单位对成本进行统计。
数据成本值的计算方法
基于数据RD矩阵,最终数据的成本我们假设为P,计算公式如下:P=C*cu+S*su+B*bu+F*fu+M*mu(其中我们把P定为总成本价格,C为cpu耗时,cu为cpu耗时单价;S为存储耗时,su为存储单价;B为网络单宽,bu为带宽单价;F为网络流量,fu为流量单价;M为人工耗时,mu为人力单价)。
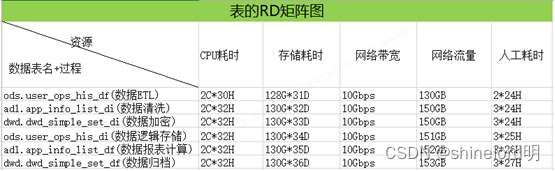
如上图所示,RD矩阵图还支持按每个加工过程进行细化。其中加工过程可以关联PO矩阵图,找到对用的部门组织,进而可以将数据的成本分摊到部门组织。数据成本值P=C*cu+S*su+B*bu+F*fu+M*mu
数据的IPO图展示方法
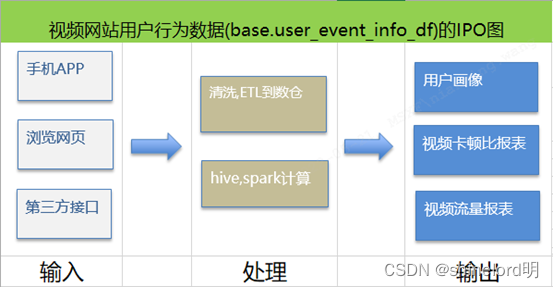
如上图所示,展示了视频网站用户行为数据user_event_info_df数据的IPO矩阵图。其中数据的输入有三个渠道,处理大致有两种处理加工逻辑,最终输出有3种数据。其中处理过程可以关联PO矩阵图,找到对用的部门组织。
数据产出值计算方法
假设数据产出值O,则O=输出数据的个数(如表的个数,数据的种类)
数据处理复杂度计算方法
数据处理复杂度=处理加工涉及的过程的数量
- 计算结果分析
通过计算出的数据资产的可靠度,使用权重指标,可以对数据是否有下游使用,使用的重要程度,对数据是否可以归档或则销毁作为参考,以及对数据的价值,质量具有一定参考意义。通过数据的RD矩阵图计算,成本值指标,可以将数据的相关成本细化,进而也可以关联数据使用的部门,对数据产生的成本进行分摊计算。通过PO矩阵图计算,部门关联度,过程复杂度指标,可以让用户对数据属性,复杂度有一定了解。以及通过IPO图计算输入,产出值,过程复杂度等指标,可以让用户再使用数据时,进行溯源,输入,加工逻辑,输出成功有个全方位的认识。

