
- 12018年出生率 京沪津普降 东北垫底_2018年上海孩子出生率
- 2不同版本CUDA和cudnn下载安装并配置环境变量_cuda下载按照
- 3Pygame编程(3)draw模块_pygame中draw
- 4QT 实现放大镜跟随鼠标效果
- 5求职数据分析,项目经验该怎么写
- 62023年十四届蓝桥杯省赛大学B组真题(Java完整版)_说明 给你一个无向图,这个无向图有 n 如果你要连接 x,y,那么需要花费 ax+ay 的成
- 7jenkins部署后的操作将jar传入目标服务器并且运行jar包_jenkins 将jar发送到另一台机器
- 8python 科学计数法_Python编程基础篇>04格式化输出转义及input输入
- 9Flutter和Rust如何优雅的交互_flutter rust
- 10c#游戏辅助脚本教程——变量
Series和DataFrame的创建和pandas数据清洗和数据分析的常用操作_分别输出各个大洲的平均啤酒、烈酒和红酒的消费量;
赞
踩
一
(1)根据列表["Python","C","Scala","Java","GO","Scala","SQL","PHP","Python"]创建一个变量名为language的Series;
(2)创建一个由随机整型组成的Series,要求长度与language相同,变量名为score;
(3)根据language和score创建一个DataFrame;
(4)输出该DataFrame的前4行数据;
(5)输出该DataFrame中language字段为Python的行;
(6)将DataFrame按照score字段的值进行升序排序;
(7)统计language字段中每种编程语言出现的次数。
- import pandas as pd
- import numpy as np
- from pandas import DataFrame, Series
- language = Series(["Python","C","Scala","Java","GO","Scala","SQL","PHP","Python"])
- score = Series(np.random.randint(10, size = (9,)))
- df = DataFrame({'language':language, 'score':score})
- print('该DataFrame的前4行数据')
- print(df.head(4))
- print('输出该DataFrame中language字段为Python的行;')
- print(df[df.language == 'Python'])
- print('将DataFrame按照score字段的值进行升序排序')
- print(df.sort_values('score',inplace=True))
- print('统计language字段中每种编程语言出现的次数。')
- print(df.language.value_counts())
二. 酒类消费数据
给定一个某段时间内各个国家的酒类消费数据表drinks.csv,其中包含6个字段,表8-1给出了该表中的字段信息。
表8-1 酒类消费数据表的字段信息
| Country | 国家 |
| beer_servings | 啤酒消费量 |
| spirit_servings | 烈酒消费量 |
| wine_servings | 红酒消费量 |
| total_litres_of_pure_alcohol | 纯酒精消费总量 |
| Continent | 所在的大洲 |
完成以下的任务:
(1)用pandas将酒类消费数据表中的数据读取为DataFrame,输出包含缺失值的行;
(2)在使用read_csv函数读取酒类消费数据表时(除文件地址外不添加额外的参数),pandas将continent字段中的“NA”(代表北美洲,North American)自动识别为NaN。因此,需要将continent字段中的NaN全部替换为字符串NA。如果学有余力,可以自行在网络上调研如何在read_csv函数中添加参数使NA不被识别为NaN;
(3)分别输出各个大洲的平均啤酒、烈酒和红酒的消费量;
(4)分别
输出啤酒、烈酒和红酒消费量最高的国家。
-
- import pandas as pd
- df = pd.read_csv('drinks.csv')
-
- print("用pandas将酒类消费数据表中的数据读取为DataFrame,输出包含缺失值的行")
- print(df.loc[df.continent.isnull()].index)
- # 直接全部替换为’NA’
- df = df.fillna('NA')
- # 或者在读取数据时加入参数keep_default_na=False
- df = pd.read_csv('drinks.csv', keep_default_na=False)
-
- print('分别输出各个大洲的平均啤酒、烈酒和红酒的消费量;')
- print(df.groupby('continent')[['beer_servings', 'spirit_servings', 'wine_servings']].mean())
-
- print("输出啤酒消费量最高的国家")
- print(df.iloc[df.beer_servings.argmax(), 0])
-
- print("输出烈酒消费量最高的国家")
- print(df.iloc[df.spirit_servings.argmax(), 0])
-
- print("输出红酒消费量最高的国家")
- print(df.iloc[df.wine_servings.argmax(), 0])
-
-

三. 狗狗币的历史价格
狗狗币(Dogecoin)是世界上用户数量仅次于比特币的第二大虚拟货币。给定一个狗狗币2014年9月17日至2021年3月1日的历史价格表DOGE-USD.csv,里面包含了6个字段,表8-2给出了该表中的字段信息。
表8-2 历史价格表的字段信息
| Date | 日期 |
| Open | 当天的开盘价格 |
| High | 当天的最高价格 |
| Low | 当天的最低价格 |
| Close | 当天的收盘价格 |
| Volume | 当天的成交量 |
完成以下的任务:
(1)用pandas将历史价格表中的数据读取为DataFrame,并查看各个列的数据类型。在读取数据时,pandas是否将表中的日期字段自动读取为日期类型?若否,则将其转换为日期类型;
(2)该DataFrame中是否存在缺失值?若是,则输出数据缺失的日期,并用前一交易日的数据填充缺失值;
(3)分别输出狗狗币价格的最高值与最低值,并分别输出达到最高值与最低值的日期;
(4)画出狗狗币每天最高价格的折线图(横轴为日期);
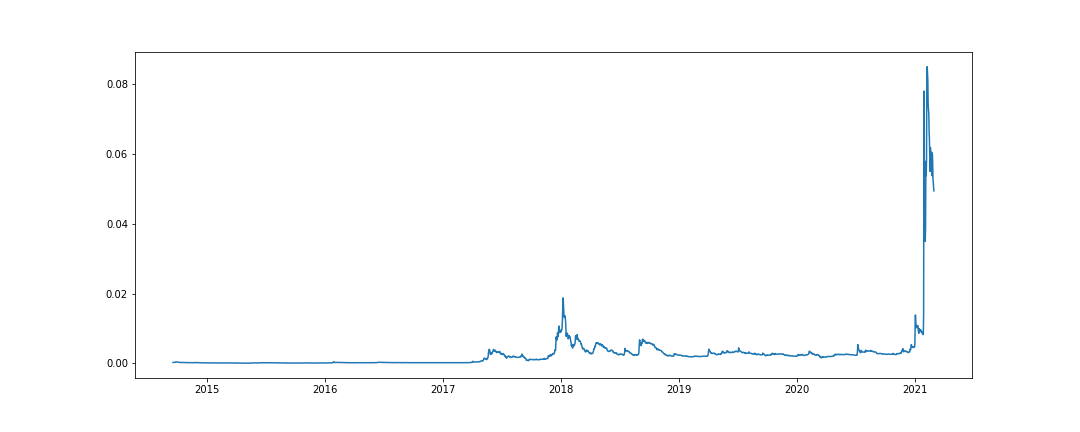
图8-1 狗狗币每天最高价格折线图
(5)画出狗狗币成交量的折线图(横轴为日期)。由于成交量字段中的数据数量级变化较大,直接画图无法直观地观察出其变化趋势,尝试画出更直观的成交量折线图(提示:取对数)。
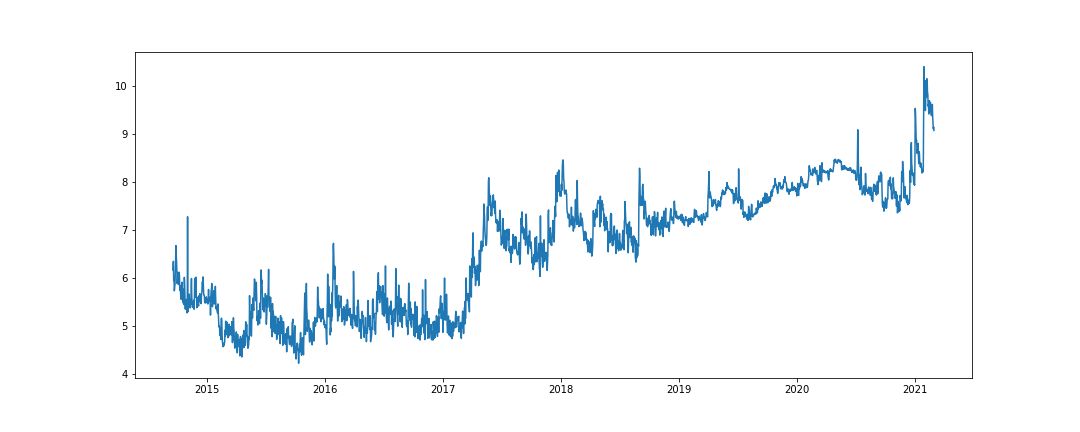
图8-2狗狗币每日成交量折线图
-
- import pandas as pd
- import matplotlib.pyplot as plt
- import numpy as np
-
- df = pd.read_csv('DOGE-USD.csv')
- print('查看各个列的数据类型')
- print(df.dtypes)
-
- # 可见Date字段不是日期类型
- df.Date = pd.to_datetime(df.Date)
- print('查看各个列的数据类型')
- print(df.dtypes)
-
- print('查看否存在缺失值')
- print(df.info())
-
- # 可见除了Date字段外,其余字段都存在缺失值
- df['Date'].loc[df['Open'].isnull()]
-
-
- df['Date'].loc[df['Close'].isnull()]
-
-
- df['Date'].loc[df['High'].isnull()]
-
-
- df['Date'].loc[df['Low'].isnull()]
-
-
- df['Date'].loc[df['Volume'].isnull()]
-
- # 可见存在缺失值的日期有四个
- df = df.fillna(method='pad')
-
- print('输出狗狗币价格的最高值')
- print(df.High.max())
-
- print('输出狗狗币价格的最低值')
- print(df.High.max())
-
- print('输出达到最高值与最低值的日期')
- print(df['Date'].loc[df['High'].argmax()])
-
- print('输出达到最高值与最低值的日期')
- print(df['Date'].loc[df['Low'].argmin()])
-
- #画出狗狗币每天最高价格的折线图(横轴为日期)
- plt.plot(df.Date, df.High)
- plt.show()
-
- #画出狗狗币成交量的折线图(横轴为日期)。
- plt.plot(df.Date, np.log10(df.Volume))
- plt.show()
-
-
注意:cvs文件和python代码放于同一目录下,或更改路径。

