
- 1超全地牢场景unity3d模型素材网站整理_unity 免费3d游戏场景
- 2NsPack 3.7
- 3我的Android进阶之旅------>经典的大客推荐(排名不分先后)!!
- 4机器学习系列(13)_PCA对图像数据集的降维_02_图片 pca降维
- 5人工智能专业python论文毕设方向推荐
- 6Dubbo分布式zookeeper应用错误——监听启动失败或服务器接口冲突报错_zookeeper+dubbo 20880端口未监听
- 7七年程序员职业规划:北京、上海、硅谷工作经历分享_进入硅谷大厂怎么做职业规划
- 8基于微信天津二手物品交易小程序系统设计与实现 研究背景和意义、国内外现状
- 9Hyper-V 3 虚拟机快照_hyper-v 正在合并
- 10网络安全--安全攻防概述
YOLOv5-Lite:Repvgg重参化对YOLO工业落地的实验和思考_yolov5-lite知乎ppog
赞
踩

QQ交流群:993965802
本文版权属于GiantPandaCV,未经允许请勿转载
这一次的实验主要借鉴repvgg重参化的思想,将原有的3×3conv替换成Repvgg Block,为原有的YOLO模型涨点。
前言: 之前做了一次shufflenetv2与yolov5的组合,目的是为了适配arm系列芯片,让yolov5在端侧设备上也能达到实时。但在gpu或者npu方面也一直在尝试着实验,对此类实验的目的很明确,要求也不高,主要还是希望yolov5在保持原有精度的同时能够提速。
实验
这一次的模型主要还是借鉴repvgg重参化的思想,将原有的3×3conv替换成repvgg block,在训练过程中,使用的是一个多分支模型,而在部署和推理的时候,用的是多分支转化为单路的模型。

类比repvgg在论文中阐述的观点,这里的baseline选定的是yolov5s,对yolov5s的3×3conv进行重构,分出一条1×1conv的旁支。

在推理时,将旁支融合到3×3的卷积中,此时的模型和原先的yolov5s模型无二致

在次之前,采用的是最直接的方式对yolov5s进行魔改,也就是直接替换backbone的方式,但发现参数量和FLOPs较高,复现精度最接近yolov5s的是repvgg-A1,如下backbone替换为A1的yolov5s:

而后,为了抑制Flops和参数的增加,采取使用repvgg block替换yolov5s的3×3conv的方式。

两者之间相差的Flops比和参数比约为2.75和1.85.
性能
通过消融实验,得出的yolov5s和融合repvgg block的yolov5s性能差异如下:

这里评估的yolov5s在map指标上和官网有所出入,测试两次后均为55.8和35.8,不过这个测试结果和https://github.com/midasklr/yolov5prune 以及Issue #3168 · ultralytics/yolov5大致相同。使用repvgg block重构yolov5s的3×3卷积,在map@0.5和@.5:.95指标上均能至少提升一个点。
训练结束后的repyolov5s需要进行convert,将旁支的1×1conv进行融合,否则在推理时会比原yolov5s慢20%。
使用convert.py对repvgg block进行重参化,主要代码如下,参考https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py:
# --------------------------repvgg refuse--------------------------------- def reparam conv(self): # fuse model Conv2d() + BatchNorm2d() layers """ :param rbr_dense: 3×3卷积模块 :param rbr_1x1: 1×1旁支inception :param _pad_1x1_to_3x3_tensor: 对1×1的inception进行扩充 :return: """ print('Reparam and Fusing Block... ') for m in self.model.modules(): # print(m) if type(m) is RepVGGBlock: if hasattr(m, 'rbr_1x1'): # print(m) kernel, bias = m.get_equivalent_kernel_bias() conv_reparam = nn.Conv2d(in_channels=m.rbr_dense.conv.in_channels, out_channels=m.rbr_dense.conv.out_channels, kernel_size=m.rbr_dense.conv.kernel_size, stride=m.rbr_dense.conv.stride, padding=m.rbr_dense.conv.padding, dilation=m.rbr_dense.conv.dilation, groups=m.rbr_dense.conv.groups, bias=True) conv_reparam.weight.data = kernel conv_reparam.bias.data = bias for para in self.parameters(): para.detach_() m.rbr_dense = conv_reparam # m.__delattr__('rbr_dense') m.__delattr__('rbr_1x1') m.deploy = True m.forward = m.fusevggforward # update forward continue # print(m) if type(m) is Conv and hasattr(m, 'bn'): # print(m) m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv delattr(m, 'bn') # remove batchnorm m.forward = m.fuseforward # update forward self.info() return self

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
我们可以通过调用onnx模型对convert前后的模型进行可视化:

推理
map指标只是参考的一部分,还有一部分是关于reparam和fuse后的yolov5s会不会因为repvgg block的植入而变慢。在理论上,reparam后的repvgg block等价于3×3卷积,不过该卷积因为融合比普通3×3卷积更加紧凑。
在测试三次coco val2017数据集后(5000张并进行单张推理),得出repyolov5s的单张推测时间为14/14/14(ms)、yolov5s为16/16/16(ms),这里和白神讨论了一下,白神认为两者极度接近的推理时间可能存在着测试误差,无任何说服性。
不过可以肯定的是convert后的yolov5s推理速度不会因为repvgg block植入而变慢。为了避免偶然性和测算误差,这里使用了500/5000/64115/118287张图片进行了推理测试:

测试后的结果如下:
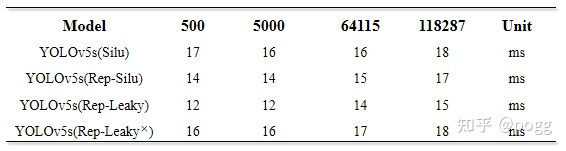
测试
检测效果应该也是大家关心的一个指标,使用以上两个模型,保证其他参数均一致,对图片进行检测,效果如下:


总结
使用repvgg block对yolov5s进行改进,通过消融实验,总结出以下几点:
- 融合repvgg block的yolov5s在大小尺度目标上均能涨点; 使用融合repvgg
- block和leakyrelu的yolov5s比原yolov5s在map上降低了0.5个百分点,但是速度可以提升15%(主要是替换了Silu函数起的作用);
- 如果不做convert,个人感觉这个融合实验毫无意义,旁生的支路会严重影响模型的运行速度;
- C3 Block和Repvgg Block在cpu上使用性价比低,在gpu和npu上使用才能带来最大增益
- 使用重参化的yolov5是有代价的,代价损耗均在训练方面,会多占用显卡大约5-10%的显存,训练时间也会增多
- 可以考虑使用repvgg block对yolov3-spp和yolov4的3×3卷积进行重构
代码和预训练模型后续会放到本人仓库上:
https://github.com/ppogg/YOLOv5-Lite


